【转】浅谈Pytorch中的显存利用问题(附完善显存跟踪代码) |
您所在的位置:网站首页 › 网络监控代码 › 【转】浅谈Pytorch中的显存利用问题(附完善显存跟踪代码) |
【转】浅谈Pytorch中的显存利用问题(附完善显存跟踪代码)
|
前言
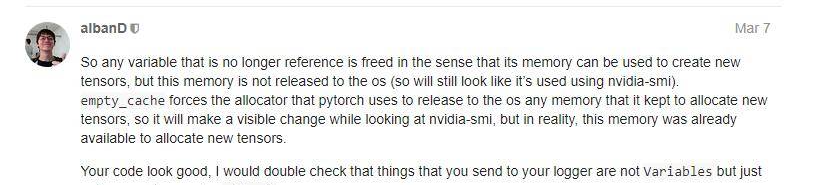
之前在浅谈深度学习:如何计算模型以及中间变量的显存占用大小和如何在Pytorch中精细化利用显存中我们已经谈论过了平时使用中显存的占用来自于哪里,以及如何在Pytorch中更好地使用显存。在这篇文章中,我们借用Pytorch-Memory-Utils这个工具来检测我们在训练过程中关于显存的变化情况,分析出我们如何正确释放多余的显存。 在深度探究前先了解下我们的输出信息,通过Pytorch-Memory-Utils工具,我们在使用显存的代码中间插入检测函数(如何使用见工具github页面和下文部分),就可以输出类似于下面的信息,At __main__ : line 13 Total Used Memory:696.5 Mb表示在当前行代码时所占用的显存,即在我们的代码中执行到13行的时候所占显存为695.5Mb。At __main__ : line 15 Total Used Memory:1142.0 Mb表示程序执行到15行时所占的显存为1142.0Mb。两条数据之间表示所占显存的tensor变量。 # 12-Sep-18-21:48:45-gpu_mem_track.txt GPU Memory Track | 12-Sep-18-21:48:45 | Total Used Memory:696.5 Mb At __main__ : line 13 Total Used Memory:696.5 Mb + | 7 * Size:(512, 512, 3, 3) | Memory: 66.060 M | + | 1 * Size:(512, 256, 3, 3) | Memory: 4.7185 M | + | 1 * Size:(64, 64, 3, 3) | Memory: 0.1474 M | + | 1 * Size:(128, 64, 3, 3) | Memory: 0.2949 M | + | 1 * Size:(128, 128, 3, 3) | Memory: 0.5898 M | + | 8 * Size:(512,) | Memory: 0.0163 M | + | 3 * Size:(256, 256, 3, 3) | Memory: 7.0778 M | + | 1 * Size:(256, 128, 3, 3) | Memory: 1.1796 M | + | 2 * Size:(64,) | Memory: 0.0005 M | + | 4 * Size:(256,) | Memory: 0.0040 M | + | 2 * Size:(128,) | Memory: 0.0010 M | + | 1 * Size:(64, 3, 3, 3) | Memory: 0.0069 M | At __main__ : line 15 Total Used Memory:1142.0 Mb + | 1 * Size:(60, 3, 512, 512) | Memory: 188.74 M | + | 1 * Size:(30, 3, 512, 512) | Memory: 94.371 M | + | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | At __main__ : line 21 Total Used Memory:1550.9 Mb + | 1 * Size:(120, 3, 512, 512) | Memory: 377.48 M | + | 1 * Size:(80, 3, 512, 512) | Memory: 251.65 M | At __main__ : line 26 Total Used Memory:2180.1 Mb - | 1 * Size:(120, 3, 512, 512) | Memory: 377.48 M | - | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | At __main__ : line 32 Total Used Memory:1676.8 Mb使用Pytorch-Memory-Utils得到的显存跟踪结果。 当然这个检测工具不仅适用于Pytorch,其他的深度学习框架也同样可以使用,不过需要注意下静态图和动态图在实际运行过程中的区别。 正文了解了Pytorch-Memory-Utils工具如何使用后,接下来我们通过若干段程序代码来演示在Pytorch训练中: 平时的显存是如何变化的,到底是什么占用了显存。如何去释放不需要的显存。首先,我们在下段代码中导入我们需要的库,随后开始我们的显存检测程序。 import torch import inspect from torchvision import models from gpu_mem_track import MemTracker # 引用显存跟踪代码 device = torch.device('cuda:0') frame = inspect.currentframe() gpu_tracker = MemTracker(frame) # 创建显存检测对象 gpu_tracker.track() # 开始检测 预训练权重模型首先我们检测一下神经网络模型权重所占用的显存信息,下面代码中我们尝试加载VGG19这个经典的网络模型,并且导入预训练好的权重。 gpu_tracker.track() cnn = models.vgg19(pretrained=True).to(device) # 导入VGG19模型并且将数据转到显存中 gpu_tracker.track()然后可以发现程序运行过程中的显存变化(第一行是载入前的显存,最后一行是载入后的显存): At __main__ : line 13 Total Used Memory:472.2 Mb + | 1 * Size:(128, 64, 3, 3) | Memory: 0.2949 M | + | 1 * Size:(256, 128, 3, 3) | Memory: 1.1796 M | + | 1 * Size:(64, 64, 3, 3) | Memory: 0.1474 M | + | 2 * Size:(4096,) | Memory: 0.0327 M | + | 1 * Size:(512, 256, 3, 3) | Memory: 4.7185 M | + | 2 * Size:(128,) | Memory: 0.0010 M | + | 1 * Size:(1000, 4096) | Memory: 16.384 M | + | 6 * Size:(512,) | Memory: 0.0122 M | + | 1 * Size:(64, 3, 3, 3) | Memory: 0.0069 M | + | 1 * Size:(4096, 25088) | Memory: 411.04 M | + | 1 * Size:(4096, 4096) | Memory: 67.108 M | + | 5 * Size:(512, 512, 3, 3) | Memory: 47.185 M | + | 2 * Size:(64,) | Memory: 0.0005 M | + | 3 * Size:(256,) | Memory: 0.0030 M | + | 1 * Size:(128, 128, 3, 3) | Memory: 0.5898 M | + | 2 * Size:(256, 256, 3, 3) | Memory: 4.7185 M | + | 1 * Size:(1000,) | Memory: 0.004 M | At __main__ : line 15 Total Used Memory:1387.5 Mb通过上面的报告,很容易发现一个问题。 首先我们知道VGG19所有层的权重大小加起来大约是548M(这个数值来源于Pytorch官方提供的VGG19权重文件大小),我们将上面报告打印的Tensor-Memory也都加起来算下来也差不多551.8Mb。但是,我们算了两次打印的显存实际占用中:1387.5 – 472.2 = 915.3 MB。 唉,怎么多用了差不多400Mb呢?是不是报告出什么问题了。 这样,我们再加点Tensor试一下。 gpu_tracker.track() cnn = models.vgg19(pretrained=True).to(device) gpu_tracker.track() # 上方为之前的代码 # 新增加的tensor dummy_tensor_1 = torch.randn(30, 3, 512, 512).float().to(device) # 30*3*512*512*4/1000/1000 = 94.37M dummy_tensor_2 = torch.randn(40, 3, 512, 512).float().to(device) # 40*3*512*512*4/1000/1000 = 125.82M dummy_tensor_3 = torch.randn(60, 3, 512, 512).float().to(device) # 60*3*512*512*4/1000/1000 = 188.74M gpu_tracker.track() # 再次打印如上面的代码,我们又加入了三个Tensor,全部放到显存中。报告如下: At __main__ : line 15 Total Used Memory:1387.5 Mb + | 1 * Size:(30, 3, 512, 512) | Memory: 94.371 M | + | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | + | 1 * Size:(60, 3, 512, 512) | Memory: 188.74 M | At __main__ : line 21 Total Used Memory:1807.0 Mb上面的报告就比较正常了:94.3 + 125.8 + 188.7 = 408.8 约等于 1807.0 – 1387.5 = 419.5,误差可以忽略,因为肯定会存在一些开销使用的显存。 那之前是什么情况?是不是模型的权重信息占得显存就稍微多一点? 这样,我们将载入VGG19模型的代码注释掉,只对后面的三个Tensor进行检测。 gpu_tracker.track() # cnn = models.vgg19(pretrained=True).to(device) 注释掉读权重代码 gpu_tracker.track()可以发现: GPU Memory Track | 15-Sep-18-13:59:03 | Total Used Memory:513.3 Mb At __main__ : line 13 Total Used Memory:513.3 Mb At __main__ : line 15 Total Used Memory:513.3 Mb At __main__ : line 18 Total Used Memory:513.3 Mb + | 1 * Size:(60, 3, 512, 512) | Memory: 188.74 M | + | 1 * Size:(30, 3, 512, 512) | Memory: 94.371 M | + | 1 * Size:(40, 3, 512, 512) | Memory: 125.82 M | At __main__ : line 24 Total Used Memory:1271.3 Mb同样,显存占用比所列出来的Tensor占用大,我们暂时将次归结为Pytorch在开始运行程序时需要额外的显存开销,这种额外的显存开销与我们实际使用的模型权重显存大小无关。 Pytorch使用的显存策略Pytorch已经可以自动回收我们“不用的”显存,类似于python的引用机制,当某一内存内的数据不再有任何变量引用时,这部分的内存便会被释放。但有一点需要注意,当我们有一部分显存不再使用的时候,这部分释放的显存通过Nvidia-smi命令是看不到的,举个例子: device = torch.device('cuda:0') # 定义两个tensor dummy_tensor_4 = torch.randn(120, 3, 512, 512).float().to(device) # 120*3*512*512*4/1000/1000 = 377.48M dummy_tensor_5 = torch.randn(80, 3, 512, 512).float().to(device) # 80*3*512*512*4/1000/1000 = 251.64M # 然后释放 dummy_tensor_4 = dummy_tensor_4.cpu() dummy_tensor_2 = dummy_tensor_2.cpu() # 这里虽然将上面的显存释放了,但是我们通过Nvidia-smi命令看到显存依然在占用 torch.cuda.empty_cache() # 只有执行完上面这句,显存才会在Nvidia-smi中释放Pytorch的开发者也对此进行说明了,这部分释放后的显存可以用,只不过不在Nvidia-smi中显示罢了。 torch.no_grad()是Pytorch-0.4版本时候更新的功能,在此语句的作用域下,所有的tensor运算不会保存梯度值,特别适合在inference的时候使用,代替旧版本的volatile。 用一段代码演示下,这里我们根据VGG19网络构造一个特征提取器,分别提取content_image和style_image的特征图,然后将提取的特征图存在两个list中,我们使用了with torch.no_grad()语句(在没使用no_grad之前占用的显存更多,不过这里不进行展示了): gpu_tracker.track() layers = ['relu_1', 'relu_3', 'relu_5', 'relu_9'] # 提取的层数 layerIdx = 0 content_image = torch.randn(1, 3, 500, 500).float().to(device) style_image = torch.randn(1, 3, 500, 500).float().to(device) feature_extractor = nn.Sequential().to(device) # 特征提取器 cnn = models.vgg19(pretrained=True).features.to(device) # 采取VGG19 input_features = [] # 保存提取出的features target_features = [] # 保存提取出的features i = 0 # 如果不加下面这一句,那么显存的占用提升,因为保存了中间计算的梯度值 with torch.no_grad(): for layer in cnn.children(): if layerIdx < len(layers): if isinstance(layer, nn.Conv2d): i += 1 name = "conv_" + str(i) feature_extractor.add_module(name, layer) elif isinstance(layer, nn.MaxPool2d): name = "pool_" + str(i) feature_extractor.add_module(name, layer) elif isinstance(layer, nn.ReLU): name = "relu_" + str(i) feature_extractor.add_module(name, nn.ReLU(inplace=True)) if name == layers[layerIdx]: input = feature_extractor(content_image) gpu_tracker.track() target = feature_extractor(style_image) gpu_tracker.track() input_features.append(input) target_features.append(target) del input del target layerIdx += 1 gpu_tracker.track()进行GPU跟踪后,观察下显存变化: At __main__ : line 33 Total Used Memory:1313.3 Mb + | 2 * Size:(64,) | Memory: 0.0005 M | + | 2 * Size:(1, 3, 500, 500) | Memory: 6.0 M | + | 1 * Size:(64, 64, 3, 3) | Memory: 0.1474 M | + | 1 * Size:(128, 64, 3, 3) | Memory: 0.2949 M | + | 2 * Size:(128,) | Memory: 0.0010 M | + | 2 * Size:(1, 256, 125, 125) | Memory: 32.0 M | + | 1 * Size:(128, 128, 3, 3) | Memory: 0.5898 M | + | 7 * Size:(512, 512, 3, 3) | Memory: 66.060 M | + | 3 * Size:(256, 256, 3, 3) | Memory: 7.0778 M | + | 2 * Size:(1, 512, 62, 62) | Memory: 15.745 M | + | 1 * Size:(64, 3, 3, 3) | Memory: 0.0069 M | + | 2 * Size:(1, 128, 250, 250) | Memory: 64.0 M | + | 8 * Size:(512,) | Memory: 0.0163 M | + | 4 * Size:(256,) | Memory: 0.0040 M | + | 1 * Size:(256, 128, 3, 3) | Memory: 1.1796 M | + | 1 * Size:(512, 256, 3, 3) | Memory: 4.7185 M | + | 2 * Size:(1, 64, 500, 500) | Memory: 128.0 M | At __main__ : line 76 Total Used Memory:1932.0 Mb上表中4*2个是提取出的特征图,其他的则是模型的权重值,但是发现,所有的值加起来,与总显存变化又不同,那究竟多了哪些占用显存的东西? 其实原因很简单,除了在程序运行时的一些额外显存开销,另外一个占用显存的东西就是我们在计算时候的临时缓冲值,这些零零总总也会占用一部分显存,并且这些缓冲值通过Python的垃圾收集是收集不到的。 Asynchronous execution做过并行计算或者操作系统的同学可能知道,GPU的计算方式一般是异步的。异步运算不像同步运算那样是按照顺序一步一步来,异步是同时进行的,异步计算中,两种不一样的操作可能会发生同时触发的情况,这是处理两者间的前后关系、依赖关系或者冲突关系就比较重要了。 有一个众所周知的小技巧,在执行训练程序的时候将环境变量CUDA_LAUNCH_BLOCKING=1设为1(强制同步)可以准确定位观察到我们显存操作的错误代码行数。 后记暂时就说这些,Pytorch的显存优化除了以上这些,更多的应该交给底层处理了,期待一下Pytorch的再次更新吧——另外,Pytorch-1.0的dev版已经出来,大家可以尝尝鲜了! 如果想进一步了解: https://discuss.pytorch.org/t/understanding-gpu-memory-usage/7160 https://pypi.org/project/nvidia-ml-py/ https://discuss.pytorch.org/t/best-practices-for-maximum-gpu-utilization/13863/5 https://pytorch.org/docs/master/notes/faq.html#my-model-reports-cuda-runtime-error-2-out-of-memory https://pytorch.org/docs/master/notes/cuda.html#memory-management https://pythonhosted.org/nvidia-ml-py/ 源链接:https://oldpan.me/archives/pytorch-gpu-memory-usage-track |
【本文地址】
今日新闻 |
推荐新闻 |