python爬取网易云音乐,并下载,拿来可以直接用 |
您所在的位置:网站首页 › 网易云音乐的优点有哪些 › python爬取网易云音乐,并下载,拿来可以直接用 |
python爬取网易云音乐,并下载,拿来可以直接用
|
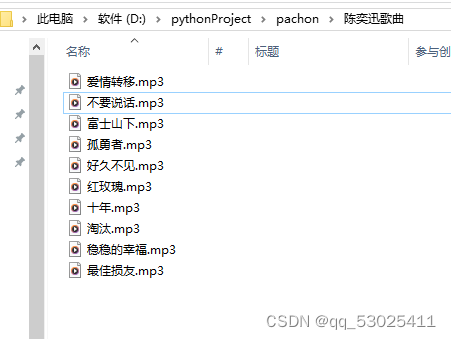
自己搞了一个,也不是很好,新学的 编写一个爬取网易云音乐的程序涉及多个步骤,包括网络请求、HTML解析、文件下载等。以下是一个基本的Python脚本示例,它使用requests和BeautifulSoup库来爬取网易云音乐的歌曲,并使用os库来管理下载的文件。 请注意,网易云音乐的网站结构和服务条款可能会随时更改,因此这个脚本可能需要根据实际情况进行调整。在使用爬虫时,务必遵守网站的robots.txt文件和相关服务条款。 首先,确保安装了必要的库: pip install requests beautifulsoup4爬虫下载音乐的好处有以下几点: 方便快捷:使用爬虫下载音乐可以快速获取想要的音乐文件,无需通过其他渠道或购买,节省了时间和金钱。 大量资源:互联网上存在大量的音乐资源,通过爬虫可以一次性获取大量的音乐文件,满足用户的需求。 自由选择:通过爬虫下载音乐可以自由选择想要的歌曲、专辑或艺术家,无需受限于特定平台或服务的限制。 离线收听:将音乐文件下载到本地后,可以在没有网络连接的情况下随时随地收听,提供了离线收听的方便性。 高质量音乐:通过爬虫可以获取到高质量的音乐文件,无需担心音质问题。 然而,需要注意的是,爬虫下载音乐也存在一些问题,比如版权侵权、法律风险等,因此在使用爬虫下载音乐时需要尊重版权和法律规定。 要获取网易云音乐中歌手的ID,可以按照以下步骤操作: 打开网易云音乐的官网(https://music.163.com/)并登录账号。在搜索栏中搜索目标歌手的名称,并选择相应的搜索结果。进入歌手的个人页,可以在浏览器的地址栏中找到歌手的ID。通常,ID是以 /artist?id= 开头,后面跟着一串数字。例如:/artist?id=6452。将获取到的ID保存下来,以便后续使用。另外,你也可以尝试使用网易云音乐的开放API来获取歌手的ID。具体的API文档和接口使用方法可以参考网易云音乐开放平台的官方文档。 废话不多说,直接上代码,复制直接可以用,希望拿了可以点个赞i👍 # - coding: utf-8 -*- import requests import json import os # 设置请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 获取指定歌手的歌曲信息 def get_artist_songs(artist_id): url = 'https://music.163.com/api/v1/artist/songs' ## 歌手歌曲信息api的url params = { 'id': artist_id, # 歌手id 'offset': 0, # 偏移量 'total': True, # 是否获取全部歌曲信息 'limit': 1000 # 获取歌曲数量 } response = requests.get(url, headers=headers, params=params) # 使用requests模块发送get请求 if response.status_code == 200: # 如果请求成功 result = json.loads(response.text) # 将response的文本内容转为json格式 songs = result['songs'] # 获取歌曲列表 return songs else: print('请求出错:', response.status_code) # 如果请求失败 return None # 下载歌曲 def download_song(song_name, song_url, save_dir): if not os.path.exists(save_dir): # 如果保存目录不存在,则创建目录 os.makedirs(save_dir) save_path = os.path.join(save_dir, '{}.mp3'.format(song_name)) # 拼接保存路径和文件名 if os.path.exists(save_path): # 如果文件已存在,则跳过下载 print('{} 已存在,跳过下载!'.format(song_name)) return response = requests.get(song_url, headers=headers) # 使用requests模块发送get请求 if response.status_code == 200: with open(save_path, 'wb') as f: # 以二进制写入模式打开文件 f.write(response.content) print('{} 下载完成!'.format(song_name)) #下载情况打印 else: print('{} 下载失败!'.format(song_name)) # 获取歌曲名称和播放链接 def get_song_info(song): song_name = song['name'] # 歌曲名称 song_id = song['id'] # 歌曲id url = 'https://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id) # 歌曲播放链接 return song_name, url # 主函数 if __name__ == '__main__': artist_id = '2116' # 歌手ID,这里以陈奕迅为例,歌手id可以在网易云音乐上搜索歌手,进入歌手的主页,查看url中的id参数即为该歌手的id。 num_songs = 10 # 下载歌曲数量 songs = get_artist_songs(artist_id) # 获取歌手的歌曲信息 if songs: save_dir = '陈奕迅歌曲' # 保存目录 for i, song in enumerate(songs): if i >= num_songs: break song_name, song_url = get_song_info(song) # 获取歌曲名称和播放链接 download_song(song_name, song_url, save_dir) # 下载歌曲 else: print('获取歌曲信息失败!') # 如果获取歌曲信息失败最后结果
|
【本文地址】
今日新闻 |
推荐新闻 |