【GPU】Nvidia CUDA 编程基础教程 |
您所在的位置:网站首页 › 编程玩具数据分析怎么写 › 【GPU】Nvidia CUDA 编程基础教程 |
【GPU】Nvidia CUDA 编程基础教程
|
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客内容主要围绕: 5G/6G协议讲解 算力网络讲解(云计算,边缘计算,端计算) 高级C语言讲解 Rust语言讲解 Nvidia CUDA编程基础教程
无论是从出色的性能还是易用性来看,CUDA 计算平台均是加速计算的制胜法宝。CUDA 提供一种可扩展 C、C++、Python 和 Fortran 等语言的编码范式,能够在世界上性能超强劲的并行处理器 NVIDIA GPU 上运行大量经加速的并行代码。CUDA 可以毫不费力地大幅加速应用程序,具有适用于 DNN、BLAS、图形分析 和 FFT 等的高度优化库生态系统,并且还附带功能强大的 命令行 和 可视化分析器。 CUDA 支持以下领域的许多(即便不是大多数)世界上性能超强劲的应用程序:计算流体动力学、分子动力学、量子化学、物理学 和高性能计算 (HPC)。 学习 CUDA 将能助您加速自己的应用程序。加速应用程序的执行速度远远超过 CPU 应用程序,并且可以执行 CPU 应用程序受限于其性能而无法执行的计算。在本实验中, 您将学习使用 CUDA C/C++ 为加速应用程序编程的入门知识,这些入门知识足以让您开始加速自己的 CPU 应用程序以获得性能提升并助您迈入全新的计算领域。 如何安装编译和运行环境,可以参考官方指导 GPU 加速应用程序与 CPU 应用程序对比在 CPU 应用程序中,数据在 CPU 上进行分配,并且所有工作均在 CPU 上执行👇 CUDA 为许多常用编程语言提供扩展,例如 C、C++、Python 和 Fortran 等语言。CUDA 加速程序的文件扩展名是.cu。 以下是一个 .cu 文件。其中包含两个函数,第一个函数将在 CPU 上运行,第二个将在 GPU 上运行。 void CPUFunction() { printf("This function is defined to run on the CPU.\n"); } __global__ void GPUFunction() { printf("This function is defined to run on the GPU.\n"); } int main() { CPUFunction(); GPUFunction(); cudaDeviceSynchronize(); }以下是一些需要特别注意的重要代码行,以及加速计算中使用的一些其他常用术语: __global__ void GPUFunction() __global__ 关键字表明以下函数将在 GPU 上运行并可全局调用;常,我们将在 CPU 上执行的代码称为主机代码,而将在 GPU 上运行的代码称为设备代码;注意返回类型为 void。使用 __global__ 关键字定义的函数需要返回 void 类型。GPUFunction(); 通常,当调用要在 GPU 上运行的函数时,我们将此种函数称为已启动的核函数;启动核函数时,我们必须提供执行配置,即在向核函数传递任何预期参数之前使用 > 语法完成的配置;在宏观层面,程序员可通过执行配置为核函数启动指定线程层次结构,从而定义线程组(称为线程块)的数量,以及要在每个线程块中执行的线程数量。cudaDeviceSynchronize(); 与许多 C/C++ 代码不同,核函数启动方式为异步:CPU 代码将继续执行而无需等待核函数完成启动;调用 CUDA 运行时提供的函数 cudaDeviceSynchronize 将导致主机 (CPU) 代码暂作等待,直至设备 (GPU) 代码执行完成,才能在 CPU 上恢复执行。 编译并运行加速后的CUDA代码CUDA 平台附带 NVIDIA CUDA 编译器 nvcc,可以编译 CUDA 加速应用程序,其中包含主机和设备代码。就本实验而言,nvcc 的讨论范围将根据我们的迫切需求据实确定。完成本实验学习后,有意深究 nvcc 的所有用户均可从 文档 开始入手。 曾使用过 gcc 的用户会对 nvcc 感到非常熟悉。例如,编译 some-CUDA.cu 文件就很简单: nvcc -arch=sm_70 -o out some-CUDA.cu -run 含义如下: nvcc 是使用 nvcc 编译器的命令行命令;将 some-CUDA.cu 作为文件传递以进行编译;o 标志用于指定编译程序的输出文件;arch 标志表示该文件必须编译为哪个架构类型;run 标志将执行已成功编译的二进制文件。 CUDA的线程层次结构GPU 可并行执行工作,GPU 在线程中执行工作,多个线程并行运行,如下图👇 程序员可通过执行配置指定有关如何启动核函数以在多个 GPU 线程中并行运行的详细信息。更准确地说,程序员可通过执行配置指定线程组(称为线程块或简称为块)数量以及其希望每个线程块所包含的线程数量。执行配置的语法如下: > 启动核函数时,核函数代码由每个已配置的线程块中的每个线程执行。 因此,如果假设已定义一个名为 someKernel 的核函数,则下列情况为真: someKernel |
 加速计算正在取代 CPU 计算,成为最佳计算做法。加速计算带来的层出不穷的突破性进展、对加速应用程序日益增长的需求、轻松编写加速计算的编程规范以及支持加速计算的硬件的不断改进,所有这一切都在推动计算方式必然会过渡到加速计算。
加速计算正在取代 CPU 计算,成为最佳计算做法。加速计算带来的层出不穷的突破性进展、对加速应用程序日益增长的需求、轻松编写加速计算的编程规范以及支持加速计算的硬件的不断改进,所有这一切都在推动计算方式必然会过渡到加速计算。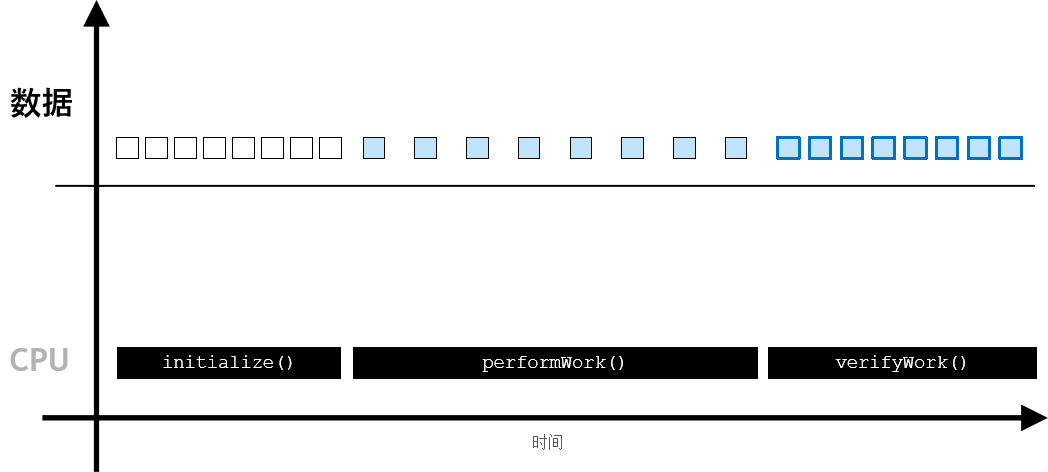 而在加速应用程序中,则可使用 cudaMallocManaged()分配数据,其数据可由 CPU 进行访问和处理,并能自动迁移至可执行并行工作的 GPU👇
而在加速应用程序中,则可使用 cudaMallocManaged()分配数据,其数据可由 CPU 进行访问和处理,并能自动迁移至可执行并行工作的 GPU👇  GPU 异步执行工作,与此同时CPU可执行它的工作,通过 cudaDeviceSynchronize(),CPU 代码可与异步 GPU 工作实现同步,并等待后者完成👇
GPU 异步执行工作,与此同时CPU可执行它的工作,通过 cudaDeviceSynchronize(),CPU 代码可与异步 GPU 工作实现同步,并等待后者完成👇 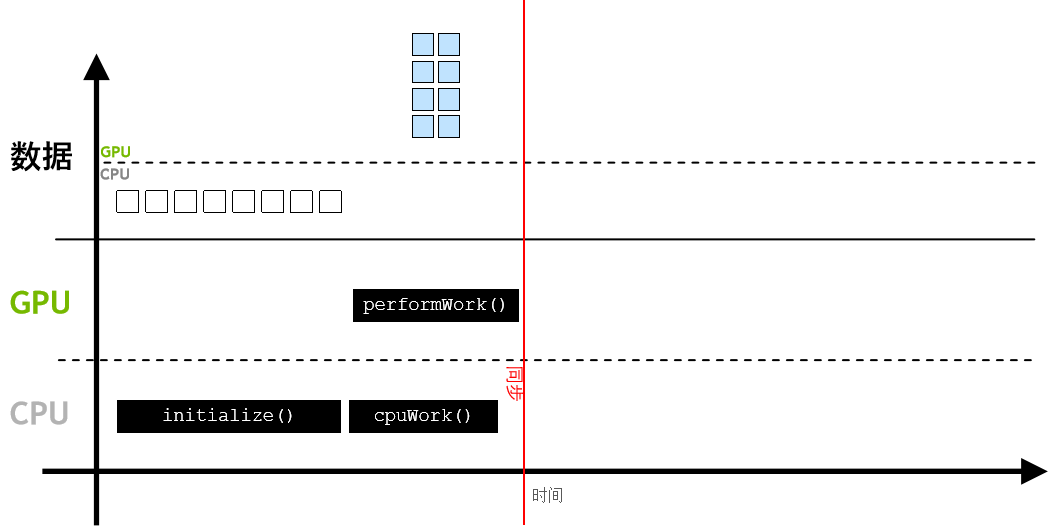 经 CPU 访问的数据将会自动迁移👇
经 CPU 访问的数据将会自动迁移👇 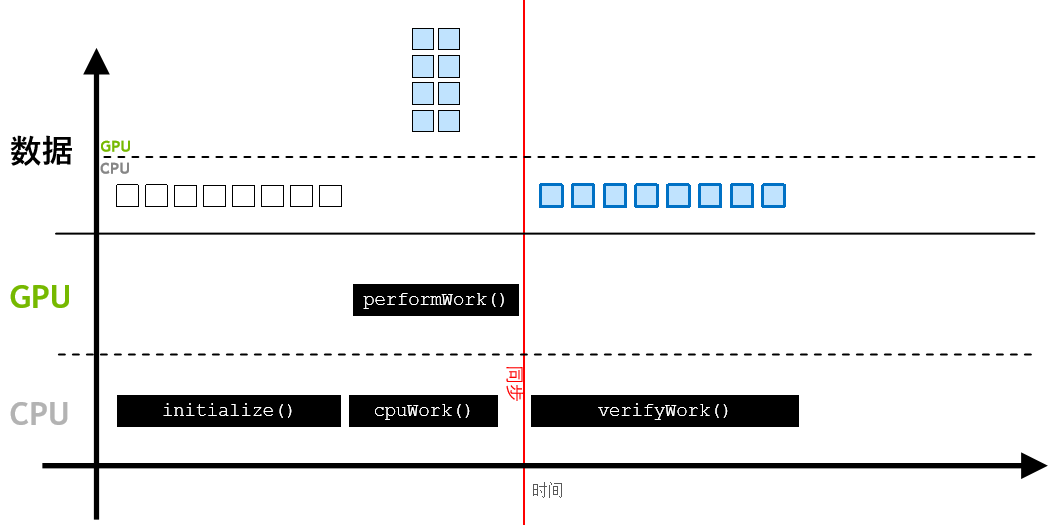
 线程的集合称为块,块的数量很多,如下图👇
线程的集合称为块,块的数量很多,如下图👇 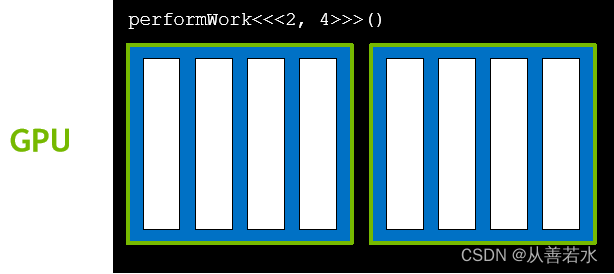 与给定核函数启动相关联的块的集合称为网格,如下图👇
与给定核函数启动相关联的块的集合称为网格,如下图👇  GPU 函数称为核函数,核函数通过执行配置启动,执行配置定义了网格中的块数以及每个块中的线程数,网格中的每个块均包含相同数量的线程。
GPU 函数称为核函数,核函数通过执行配置启动,执行配置定义了网格中的块数以及每个块中的线程数,网格中的每个块均包含相同数量的线程。【本文地址】