彻底弄懂base64的编码与解码原理 |
您所在的位置:网站首页 › 编码方式选择怎么弄出来 › 彻底弄懂base64的编码与解码原理 |
彻底弄懂base64的编码与解码原理
|
背景
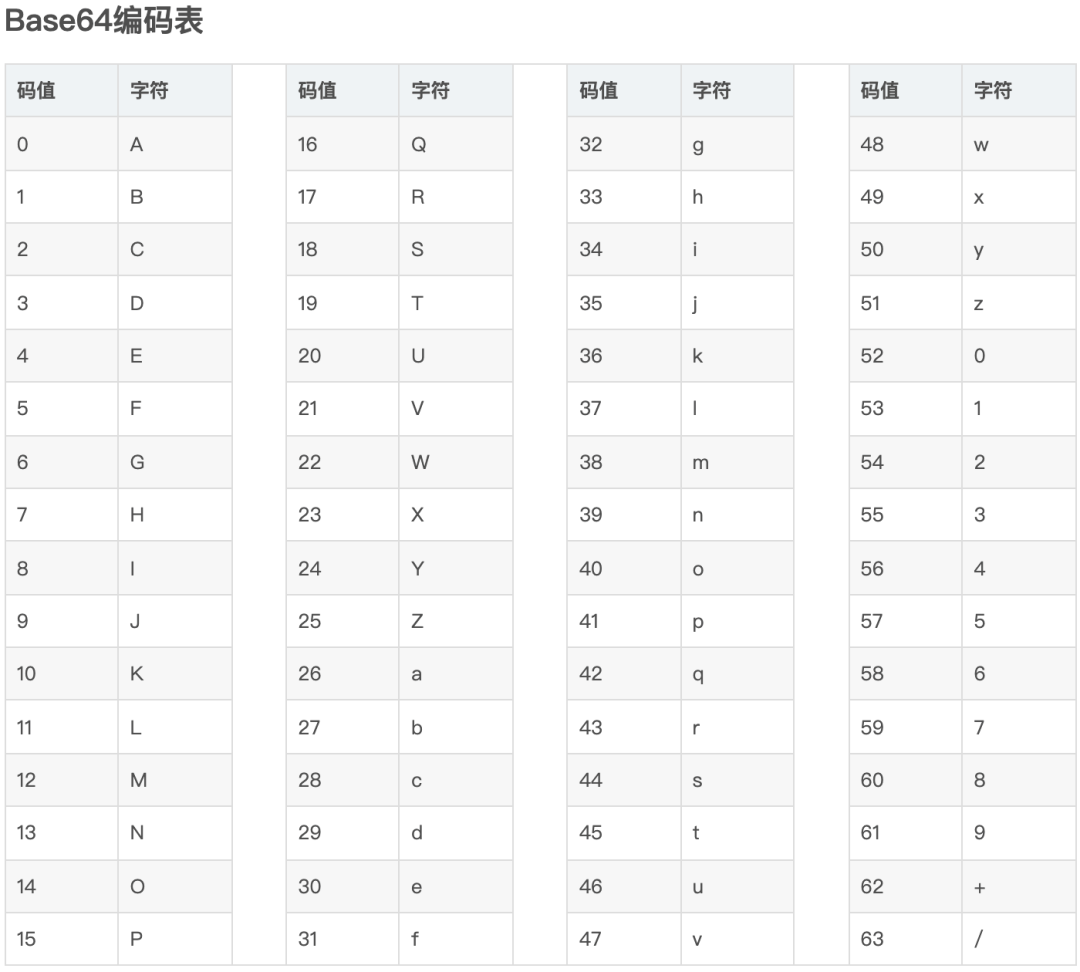
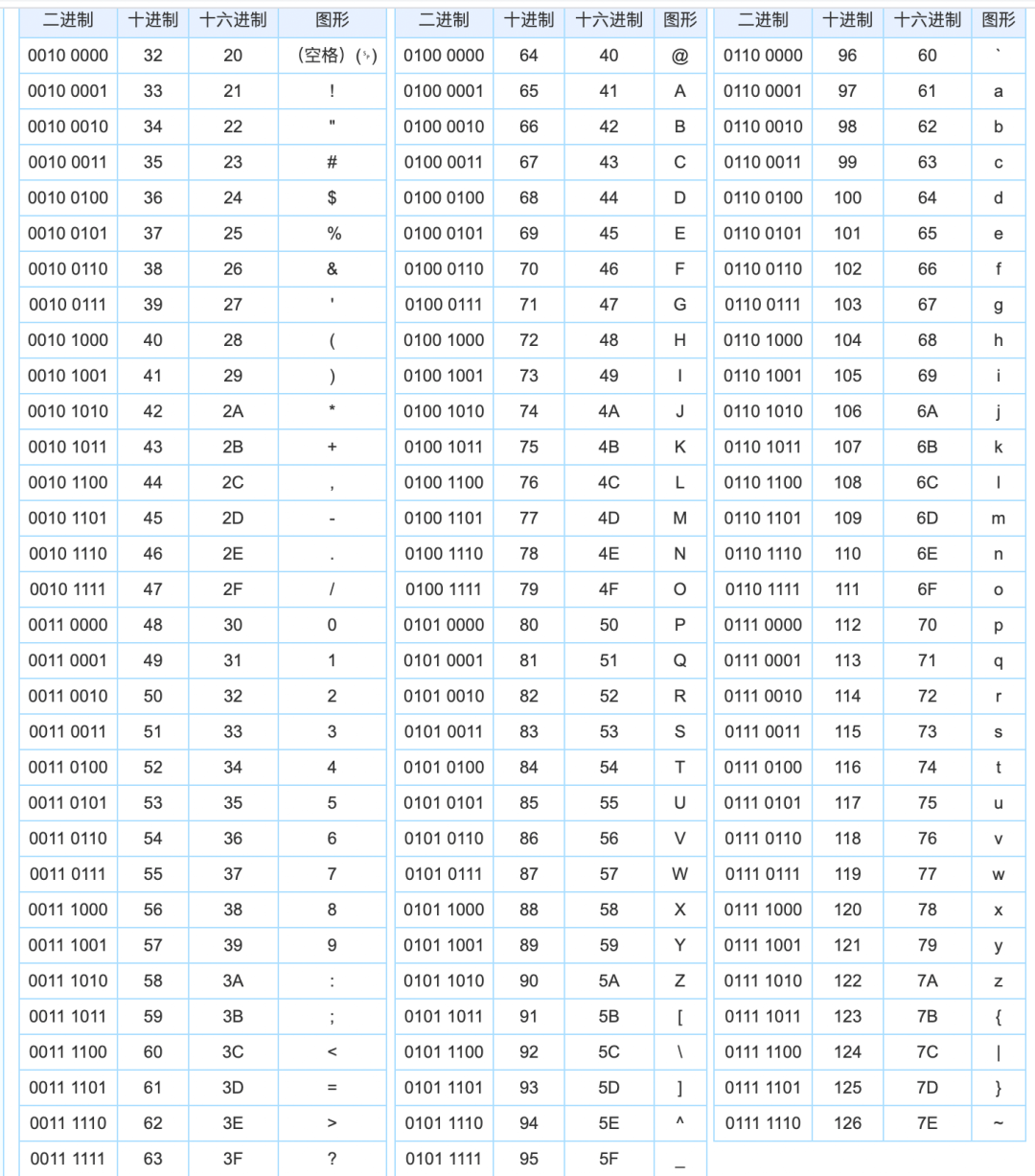
base64的编码原理网上讲解较多,但解码原理讲解较少,并且没有对其中的内部实现原理进行剖析。想要彻底了解base64的编码与解码原理,请耐心看完此文,你一定会有所收获。 涉及算法与逻辑运算概念在探究base64编码原理和解码原理的过程中,我们首先需要了解下面会用到的算法和逻辑运算的概念,这样才能真正的吃透base64的编码原理和解码原理,体会到其中算法的精妙,甚至是在思考的过程中得到意想不到的收获。不清楚base64编码表和ascII编码表的同学可直接前往文末查看。 短除法短除法运算方法是先用一个除数除以能被它除尽的一个质数,以此类推,除到商是质数为止。 通过短除法,十进制数可以不断除以2得到多个余数。最后,将余数从下到上进行排列组合,得到二进制数,我们以字符n对应的ascII编码110为例。 110 / 2 = 55...0 55 / 2 = 27...1 27 / 2 = 13...1 13 / 2 = 6...1 6 / 2 = 3...0 3 / 2 = 1...1 1 / 2 = 0...1将余数从下到上进行排列组合,得到字符n对应的ascII编码110转二进制为1101110,因为一字节对应8位(bit), 所以需要向前补0补足8位,得到01101110。其余字符同理可得。 按权展开求和按权展开求和, 8位二进制数从右到左,次数是0到7依次递增, 基数*底数次数,从左到右依次累加,相加结果为对应十进制数。我们以二进制数01101110转10进制为例: (01101110)2 = 0 * 20 + 1 * 21 + 1 * 22 + 1 * 23 + 0 * 24 + 1 * 25 + 1 * 26 + 0 * 27 位概念二进制数系统中,每个0或1就是一个位(bit,比特),也叫存储单元,位是数据存储的最小单位。其中8bit就称为一个字节(Byte)。 移位运算符移位运算符在程序设计中,是位操作运算符的一种。移位运算符可以在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:(带符号右移)和>>>(无符号右移)。我们在base64的编码和解码过程中操作的又是正数,所以仅使用(带符号右移)两种运算符。 左移运算:是将一个二进制位的操作数按指定移动的位数向左移动,移出位被丢弃,右边移出的空位一律补0。 右移运算:是将一个二进制位的操作数按指定移动的位数向右移动,移出位被丢弃,左边移出的空位一律补0,或者补符号位,这由不同的机器而定。在使用补码作为机器数的机器中,正数的符号位为0,负数的符号位为1。 我们用大白话来描述左移位,一共有8个座位,坐了8个人,在8个座位不动的情况下,现在我让这8个人往左挪2个座位,于是最左边的两个人站了起来,没有座位坐,而最右边空出来了两个座位。移位操作就相当于站起来的人出局,留出来的空位补0. // 左移 01101000 10100000(右侧空位一律补0) // 右移 01101000 >> 2 -> 011010(右侧移出位被丢弃) -> 00011010(左侧空位一律补0) 与运算、或运算与运算、或运算都是计算机中一种基本的逻辑运算方式。 与运算:符号表示为&。运算规则:两位同时为“1”,结果才为“1”,否则为0 或运算:符号表示为|。运算规则:两位只要有一位为“1”,结果就为“1”,否则为0 什么是base64编码Base64编码是将字符串以每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节(6比特有效字节,最左边两个永远为0,其实也是8比特的字节)子序列,再将得到的子序列查找Base64的编码索引表,得到对应的字符拼接成新的字符串的一种编码方式。 每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节的拆分过程如下图所示:
base64 为什么base64编码后的大小是原来的4/3倍因为6和8的最大公倍数是24,所以3个8比特的字节刚好可以拆分成4个6比特的字节,38 = 64。计算机中,因为一个字节需要8个存储单元存储,所以我们要把6个比特往前面补两位0,补足8个比特。如下图所示:
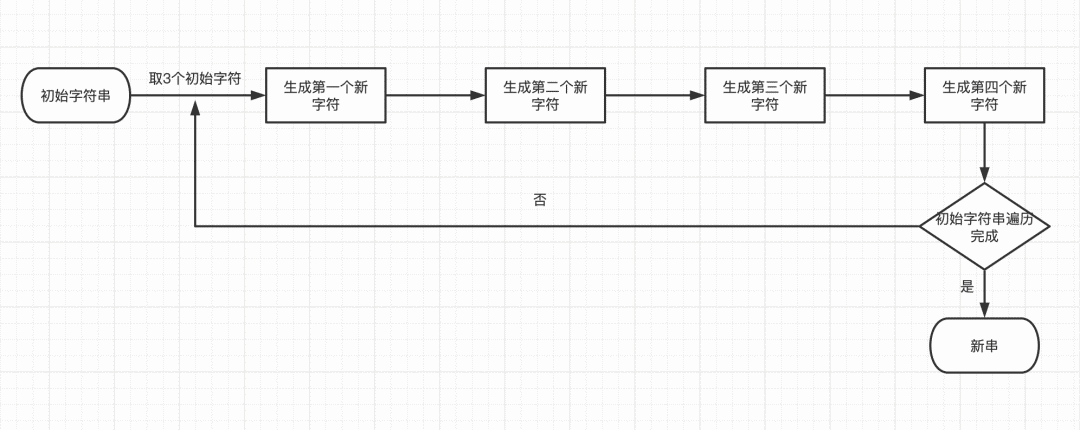
很明显,补足后所需的存储单元为32个,是原来所需的24个的4/3倍。现在大家明白为什么base64编码后的大小是原来的4/3倍了吧。 为什么命名为base64呢?因为6位(bit)的二进制数有2的6次方个,也就是二进制数(00000000-00111111)之间的代表0-63的64个二进制数。 不是说一个字节是用8位二进制表示的吗,为什么不是2的8次方?因为我们得到的8位二进制数的前两位永远是0,真正的有效位只有6位,所以我们所能够得到的二进制数只有2的6次方个。 Base64字符是哪64个?Base64的编码索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符来代表(00000000-00111111)这64个二进制数。即 let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' 编码原理我们不妨自己先思考一下,要把3个字节拆分成4个字节可以怎么做?你的实现思路和我的实现思路有哪个不同,我们之间又会碰出怎样的火花? 流程图
流程图 思路分析映射关系:abc -> xyzi。我们从高位到低位添加索引来分析这个过程 x: (前面补两个0)a的前六位 => 00a7a6a5a4a3a2 y: (前面补两个0)a的后两位 + b的前四位 => 00a1a0b7b6b5b4 z: (前面补两个0)b的后四位 + c的前两位 => 00b3b2b1b0c7c6 i: (前面补两个0)c的后六位 => 00c5c4c3c2c1c0通过上述的映射关系,我们很容易得到下面的实现思路: 将字符对应的ascII编码转为8位二进制数 将每三个8位二进制数进行以下操作 将第一个数右移位2位,得到第一个6位有效位二进制数 将第一个数 & 0x3之后左移位4位,得到第二个6位有效位二进制数的第一个和第二个有效位,将第二个数 & 0xf0之后右移位4位,得到第二个6位有效位二进制数的后四位有效位,两者取且得到第二个6位有效位二进制 将第二个数 & 0xf之后左移位2位,得到第三个6位有效位二进制数的前四位有效位,将第三个数 & 0xC0之后右移位6位,得到第三个6位有效位二进制数的后两位有效位,两者取且得到第三个6位有效位二进制 将第三个数 & 0x3f,得到第四个6位有效位二进制数 将获得的6位有效位二进制数转十进制,查找对应base64字符 我们以hao字符串为例,观察base64编码的过程,我们将上面转换通过代码逻辑分析实现吧。 代码实现 // 输入字符串 let str = 'hao' // base64字符串 let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' // 定义输入、输出字节的二进制数 let char1, char2, char3, out1, out2, out3, out4, out // 将字符对应的ascII编码转为8位二进制数 char1 = str.charCodeAt(0) & 0xff // 104 01101000 char2 = str.charCodeAt(1) & 0xff // 97 01100001 char3 = str.charCodeAt(2) & 0xff // 111 01101111 // 输出6位有效字节二进制数 6out1 = char1 >> 2 // 26 011010 out2 = (char1 & 0x3) 4 // 6 000110 out3 = (char2 & 0xf) 6 // 5 000101 out4 = char3 & 0x3f // 47 101111 out = base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv算法剖析 out1: char1 >> 2 01101000 -> 00011010 out2 = (char1 & 0x3) > 4 // 且运算 01101000 01100001 00000011 11110000 -------- -------- 00000000 01100000 // 移位运算后得 00000000 00000110 // 或运算 00000000 00000110 -------- 00000110第三个字符第四个字符同理 整理上述代码,扩展至多字符字符串 // 输入字符串 let str = 'haohaohao' // base64字符串 let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' // 获取字符串长度 let len = str.length // 当前字符索引 let index = 0 // 输出字符串 let out = '' while(index > 2 // 26 011010 out2 = (char1 & 0x3) 4 // 6 000110 out3 = (char2 & 0xf) 6 // 5 000101 out4 = char3 & 0x3f // 47 101111 out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv }原字符串长度不是3的整倍数的情况,需要特殊处理 ... char1 = str.charCodeAt(index++) & 0xff // 104 01101000 if (index == len) { out2 = (char1 & 0x3) 2 // 26 011010 out2 = (char1 & 0x3) 4 // 6 000110 out3 = (char2 & 0xf) char==str[0]) & 0xff // 26 011010 let char2 = base64CharsArr.findIndex(char => char==str[1]) & 0xff // 6 000110 let char3 = base64CharsArr.findIndex(char => char==str[2]) & 0xff // 5 000101 let char4 = base64CharsArr.findIndex(char => char==str[3]) & 0xff // 47 101111 let out1, out2, out3, out // 位运算 out1 = char1 4 out2 = (char2 & 0xf) 2 out3 = (char3 & 0x3) char==str[1]) let out1, out2, out3, out if (char1 == -1 || char2 == -1) return out char1 = char1 & 0xff char2 = char2 & 0xff let char3 = base64CharsArr.findIndex(char => char==str[2]) // 第三位不在base64对照表中时,只拼接第一个字符串 if (char3 == -1) { out1 = char1 4 out = String.fromCharCode(out1) return out } let char4 = base64CharsArr.findIndex(char => char==str[3]) // 第三位不在base64对照表中时,只拼接第一个和第二个字符串 if (char4 == -1) { out1 = char1 4 out2 = (char2 & 0xf) 2 out = String.fromCharCode(out1) + String.fromCharCode(out2) return out } // 位运算 out1 = char1 4 out2 = (char2 & 0xf) 2 out3 = (char3 & 0x3) char==str[i]) i++ // 第三位不在base64对照表中时,只拼接第一个字符串 out1 = char1 4 if (char3 == -1) { out = out + String.fromCharCode(out1) return out } let char4 = base64CharsArr.findIndex(char => char==str[i]) i++ // 第三位不在base64对照表中时,只拼接第一个和第二个字符串 out2 = (char2 & 0xf) 2 if (char4 == -1) { out = out + String.fromCharCode(out1) + String.fromCharCode(out2) return out } // 位运算 out3 = (char3 & 0x3) base64编码表中的h由此可见,base64DecodeChars对照accII编码表的索引存放的是base64编码表的对应字符的索引。 总结说起Base64编码可能有些奇怪,因为大多数的编码都是由字符转化成二进制的过程,而从二进制转成字符的过程称为解码。而Base64的概念就恰好反了,由二进制转到字符称为编码,由字符到二进制称为解码。Base64 是一种数据编码方式,可做简单加密使用,我们可以改变base64编码映射顺序来形成自己独特的加密算法进行加密解密。 编码表
|


【本文地址】