【情感提取+情感计算+词频统计】python情感分析 |
您所在的位置:网站首页 › 统计数据的英语单词有哪些 › 【情感提取+情感计算+词频统计】python情感分析 |
【情感提取+情感计算+词频统计】python情感分析
|
目录 1、情感分析介绍 2、基于大连理工情感词汇方法 2.1加载大连理工情感词典,程度副词典,否定词典,停用词典 2.2译文断章切句 2.3提取情感词并计算情感值 2.4统计词频 2.5调用实现 1、情感分析介绍情感分析是一种自然语言处理技术,旨在识别文本中的情感并将其分类为积极、消极或中性。它通过使用机器学习算法和自然语言处理技术来自动分析文本中的情感,从而帮助人们更好地理解文本的情感含义。 本文以某译本new_deepl_translated.txt为分析对象,通过对译文断章切句,进而对每一个句子情感词提取、情感值计算,以及词频统计,最后保存为excel文件。 new_deepl_translated.txt部分内容如下:
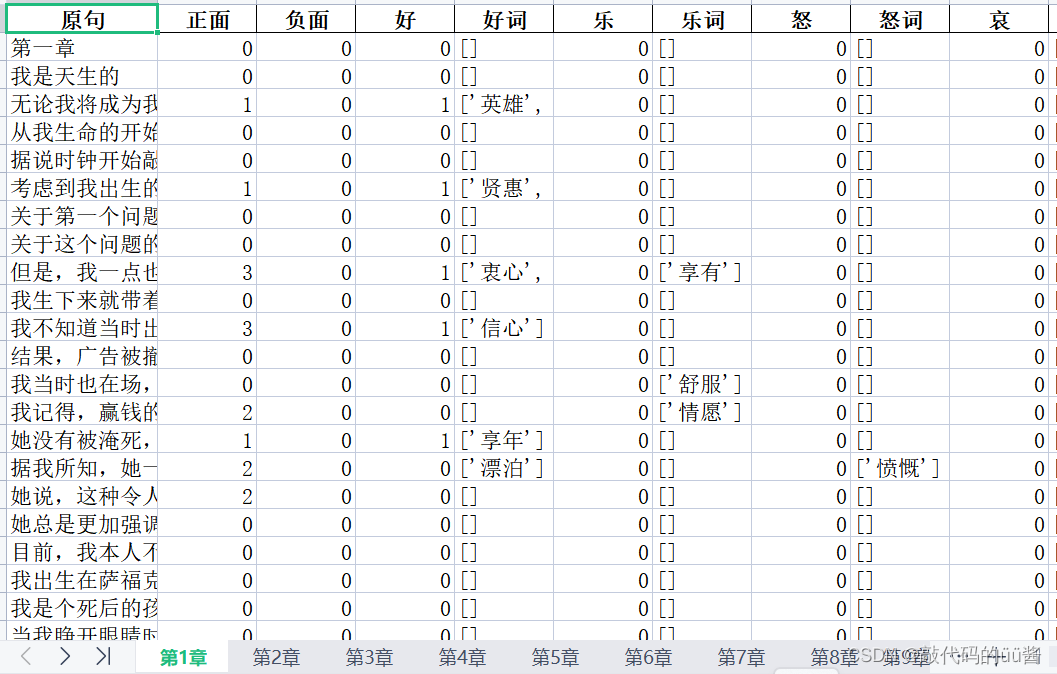
情感值计算结果:
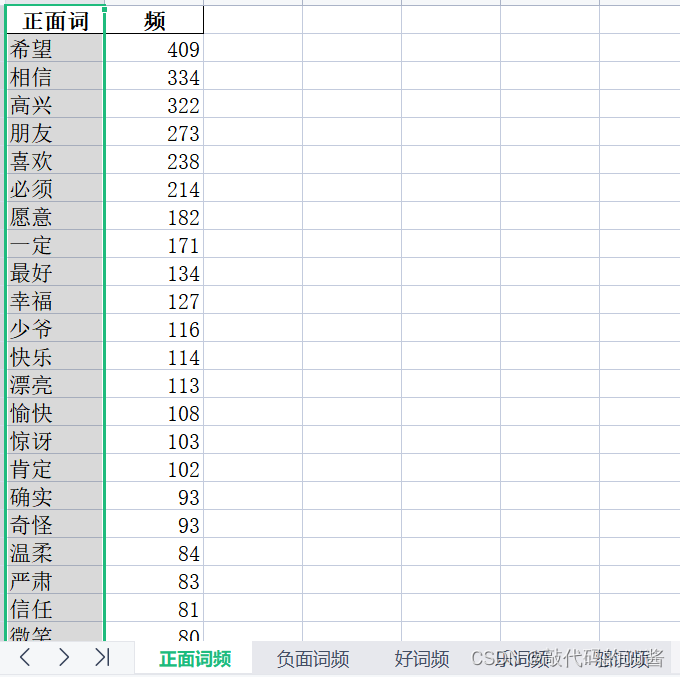
词频统计结果:
各词典大家可以从网上进行下载,顶部我放了一个资源包可以直接拿来用,或者直接网盘提取: 链接:https://pan.baidu.com/s/1WpdbGVcZ58LEbRR0X7VCCQ 提取码:2345
定义一个类sa,用于加载情感词典、程度副词典、否定词典、停用词典,以及分词和去除停用词。针对大连理工情感词典,我只需要加载词语、情感分类、强度、极性这4列内容。 class sa: # 加载情感词典、程度副词典、否定词典、停用词典 def __init__(self, senti_dict_path, degree_dict_path, not_dict_path, stopword_path): self.senti_dict = self.load_dict(senti_dict_path) self.degree_dict = self.load_degree_dict(degree_dict_path) self.not_dict = self.load_not_dict(not_dict_path) self.stopwords = self.load_stopwords(stopword_path) # 加载情感词典 def load_dict(self, path): with open(path, 'r', encoding='utf-8') as f: lines = f.readlines() word_dict = {} for line in lines: items = line.strip().split('\t') if len(items) >= 7: word = items[0] #情词 emotion = items[4] #情词类别 strength = int(items[5]) #情词强度 polarity = int(items[6]) #情词极性 word_dict[word] = {'emotion': emotion, 'strength': strength, 'polarity': polarity} return word_dict # 加载程度副词词典 def load_degree_dict(self, path): with open(path, 'r', encoding='utf-8') as f: lines = f.readlines() degree_dict = {} for line in lines: items = line.strip().split('\t') if len(items) >= 2: degree_word = items[0] #副词 degree_value = float(items[1]) #副词权值 degree_dict[degree_word] = degree_value return degree_dict # 加载否定词词典 def load_not_dict(self, path): with open(path, 'r', encoding='utf-8') as f: lines = f.readlines() not_dict = {} for line in lines: items = line.strip().split('\t') if len(items) >= 1: not_word = items[0] #否定词 not_dict[not_word] = True return not_dict # 加载停用词表 def load_stopwords(self, path): with open(path, 'r', encoding='utf-8') as f: stopwords = [line.strip() for line in f.readlines()] return stopwords # 分词 def cut_words(self, text): words = jieba.cut(text) return [word for word in words] # 去除停用词 def remove_stopword(self, words): return [word for word in words if word not in self.stopwords] 2.2译文断章切句定义一个SplitFile方法对译文进行分章,然后定义normal_cut_sentence方法对译文进行分句。 # 断章 将一个txt文件的内容,按照第几章进行分割 section def SplitFile(filename): f=open(filename, 'r', encoding="utf-8") # 获取文件每一行 lines = f.readlines() zhang = "" zhangji = [] i = 0 for line in lines: strh = line[0:6] # 取一行前5个字 if ("第" in strh and "章" in strh): #print (strh) if (i>0): zhangji.append([zhang]) zhang = "" zhang += line i += 1 zhangji.append([zhang]) #最后一章 #print (章集) print (filename,"章节数 = ",len(zhangji)) return zhangji #切句 将文本切句,换回句列表 def normal_cut_sentence(text): text = re.sub('([。!?\?])([^’”")])',r'\1\n\2',text)#普通断句符号且后面没有引号 #text = re.sub('(\.{6})([^’”])',r'\1\n\2',text)#英文省略号且后面没有引号 text = re.sub('(\…{2})([^’”])',r'\1\n\2',text)#中文省略号且后面没有引号 text = re.sub('([.。!?\?\.{6}\…{2}][’”"])([^’”"])',r'\1\n\2',text)#断句号+引号且后面没有引号 text = re.sub(r"\n\n",r'\n',text) #删除多余空行 text = re.sub(r"\n\n",r'\n',text) #删除多余空行 text = re.sub(r"\n\n",r'\n',text) #删除多余空行 text = re.sub(r"\n\n",r'\n',text) #删除多余空行 text = text.rstrip("\r\n") # 去掉段尾的\n,然后 return text.split("\n") 2.3提取情感词并计算情感值利用jieba包进行分词后,去除停用词,然后在大连理工情感词汇中查找每一个词汇,依次判断词语是否是情感词,提取情感种类与分值。 情感值计算公式:
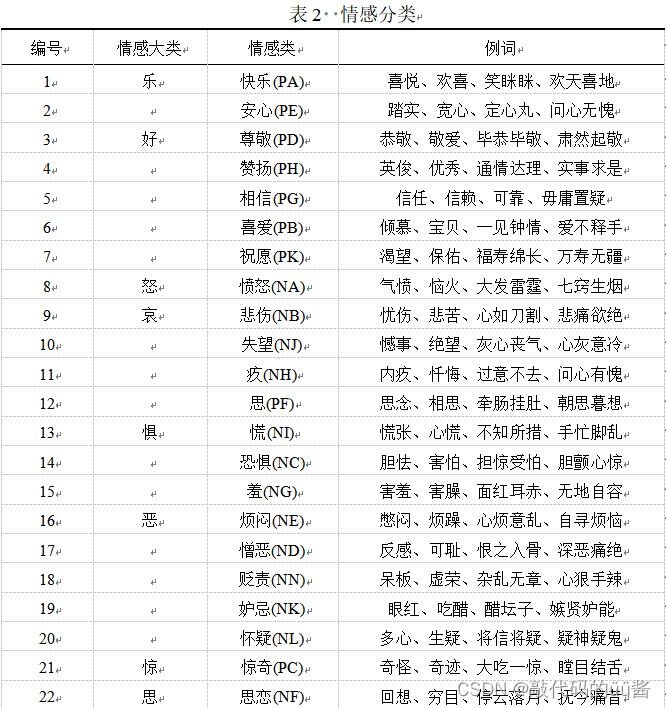
其中,大连理工情感词典各情感分类规则如下:
定义"添加词频"方法,向词频列表中添加词汇,如果词汇已存在,则将其频次加1,否则将其添加到列表末尾。 def 添加词频(word, freq_list): """ 参数: word -- 待添加的词汇 freq_list -- 词频列表 返回值: 无 """ word_str = ','.join(map(str.strip, word)).strip('[]\'\"') # 将词汇转换为字符串并去除引号和方括号 # 将逗号分隔的字符串转换为词汇列表 word_list = word_str.split(',') for w in word_list: added = False for i in range(len(freq_list)): if freq_list[i][0] == w: freq_list[i][1] += 1 added = True break if not added: freq_list.append([w, 1]) 2.5调用实现 #导入相关包 import re import os import time import pandas as pd import jieba #传入词典 senti_dict_path = 'D:/emotion_project/origin/tici/大连理工情感词汇.txt' degree_dict_path = 'D:/emotion_project/origin/tici/副词赋值.txt' not_dict_path = 'D:/emotion_project/origin/tici/否定词.txt' stopword_path = 'D:/emotion_project/origin/tici/cn_stopwords.txt' #加载词典实例化对象sa类 sa_obj = sa(senti_dict_path, degree_dict_path, not_dict_path, stopword_path) #计算情值实例化对象ScoreAnalysis类 sa = ScoreAnalysis(senti_dict_path, degree_dict_path, not_dict_path, stopword_path) #************************************************************************** #分析deepl机器翻译译本每句8种情感值,生成情感表格、词频表格 machine_trans = [ "deepl"] f_deepl = "new_deepl_translated.txt" #文本路径 files = [f_deepl] 情类 = ['好','乐','怒','哀','惧','恶','惊','思'] 表头 = ["原句","正面","负面","好","好词","乐","乐词","怒","怒词","哀","哀词","惧","惧词","恶","恶词","惊", "惊词","思","思词"] 情感乐 = [[0]*5]*64 篇号 = 0 章号 = 0 行号 = 0 #************************************************************************** 开始时间 = time.time() for 篇 in files[0:]:#不含后边界 共5篇 #情感值统计表结果路径 writer = pd.ExcelWriter("D:/emotion_project/" + machine_trans[篇号]+'.xlsx') #词频统计表结果路径 词频表格 = pd.ExcelWriter("D:/emotion_project/" + machine_trans[篇号]+'词频表.xlsx') 正面词频 = [] 负面词频 = [] 八情词频 = [[] for i in range(8)] 章号 = 0 章集 = SplitFile(篇) #调用-断章-方法 for 章 in 章集[0:]: #共64章 章情词频 = [] 章情词集 = "" 句集 = normal_cut_sentence( 章[0] ) # 调用-分句-方法 章分析 = [] for 句 in 句集: words = sa_obj.cut_words(句) # 分词 words_ = sa_obj.remove_stopword(words) #去除停用词 八情 = sa.get8score(words_) #提取情感词和计算情感值 #数据处理 正面 = 0 负面 = 0 for 情 in 八情: if 情[1] > 0 : 正面 += 情[1] else: 负面 += 情[1] #添加表格行数据 行 = [] 行.append(句) 行.append(正面) 行.append(负面) for 情 in 八情: 行.append(情[1]) #情感值 行.append(情[2]) #情感词 print(行) 章分析.append(行) #*******************************词频统计************************************* for 情 in 八情[0:2]: #0,1 添加词频( 情[2], 正面词频 ) for 情 in 八情[6:8]: #6,7 添加词频( 情[2], 正面词频 ) for 情 in 八情[2:6]: #2,3,4,5 添加词频( 情[2], 负面词频 ) i = 0 for 情 in 八情: if len(情[2]) > 0: 添加词频(情[2], 章情词频 ) 添加词频(情[2], 八情词频[i] ) i +=1 #print(章情词频) 第几章 = '第'+str(章号+1) +'章' df = pd.DataFrame(章情词频, columns = ['章情词','频'] ) df.sort_values(by="频",ascending = False, inplace = True) #按词频降序排列 df.to_excel( 词频表格, 第几章 ,index=False ) #************************************************************************** df = pd.DataFrame(章分析, columns = 表头 ) df.to_excel( writer, 第几章 ,index=False ) 章号 += 1 df = pd.DataFrame(正面词频, columns = ['正面词','频'] ) df.sort_values(by="频",ascending = False, inplace = True) #按词频降序排列 df.to_excel( 词频表格, '正面词频' ,index=False ) df = pd.DataFrame(负面词频, columns = ['负面词','频'] ) df.sort_values(by="频",ascending = False, inplace = True) #按词频降序排列 df.to_excel( 词频表格, '负面词频' ,index=False ) for i in range(8): df = pd.DataFrame(八情词频[i], columns = [情类[i]+'词','频'] ) df.sort_values(by="频",ascending = False, inplace = True) #按词频降序排列 df.to_excel( 词频表格, 情类[i]+'词频' ,index=False ) 词频表格.save() writer.save() 篇号 += 1 结束时间 = time.time() print("耗时",结束时间-开始时间,"秒")运行结果:
|





【本文地址】
今日新闻 |
推荐新闻 |