Python批量提取多个csv文件内指定行数据并汇总在新csv文件内 |
您所在的位置:网站首页 › 统计多个excel文件中的指定数据 › Python批量提取多个csv文件内指定行数据并汇总在新csv文件内 |
Python批量提取多个csv文件内指定行数据并汇总在新csv文件内
|
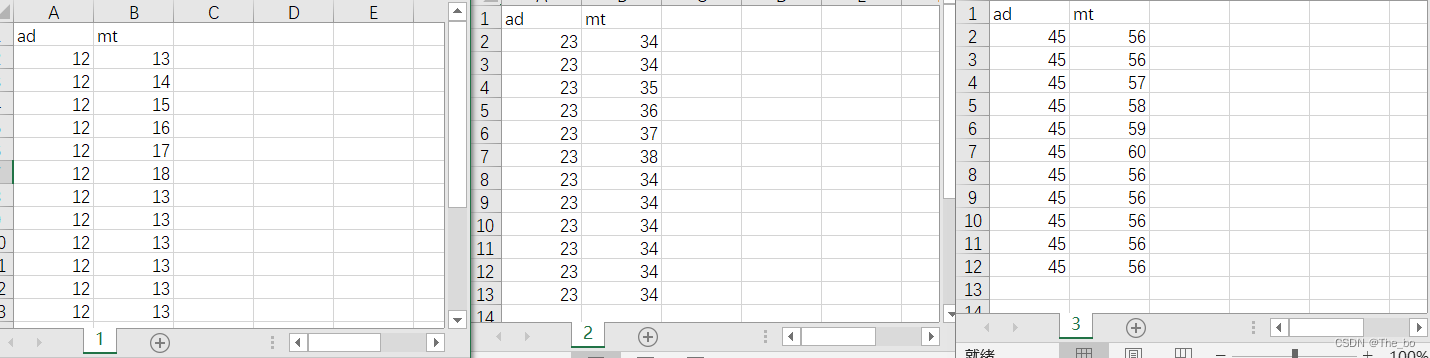
有时候我们需要统计软件分析出来的数据,这些数据保存到了csv文件中,而我们需要对比这些数据差异,就需要一个个的打开csv文件,而后找到数据复制粘贴出来,自己整理对比,而当数据文件比较多的时候,一个个打开复制就会显得比较耗时,那我们可以利用Python脚本来批量处理这些文件,这里我假如有3个csv文件数据:
而我们的目标是提取 ‘mt’这一列第4行到第7行的数据,话不多说,看下怎么操作吧。 这里我们先将脚本放在要处理文件的目录下,这样我们可以获取当前路径直接处理文件了。
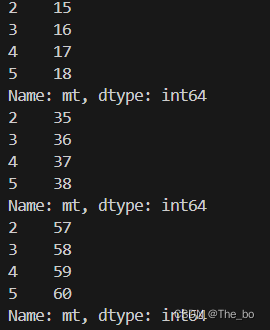
首先我们就要获取当前路径,然后遍历路径下的csv文件: # 获取当前路径 current_path = os.getcwd() # 获取当前路径下所有CSV文件的文件名 csv_files = [f for f in os.listdir(current_path) if f.endswith('.csv')]接下来就是对每个csv文件中的数据进行提取操作了,利用pandas存储列表数据,首先我们可以设定一些参数,比如上面所说的列名为 ‘mt’的这一列,以及第4到第7行: target_column = 'mt' start_row = 2 end_row = 5利用loc函数进行定位: for csv_file in csv_files: df = pd.read_csv(os.path.join(current_path,csv_file),error_bad_lines=False,encoding='utf-8') # 提取指定列、行范围的数据 extracted_data = df.loc[start_row:end_row, target_column]当然如果单纯就是第几列的话,这边需要用iloc函数,比如我们提取的是第二列,那么将上述的target_column改为1,这里注意区间是左闭右开,所以ens_row要改为6,不然就会少一行数据: target_column = 1 start_row = 2 end_row = 6 # 遍历每个CSV文件,提取数据并保存到新的CSV文件中 for csv_file in csv_files: df = pd.read_csv(os.path.join(current_path, csv_file),error_bad_lines=False,encoding='utf-8') extracted_data = df.iloc[start_row:end_row, target_column] # 区间是左闭右开这里其实我们已经完成了提取操作,print一下:
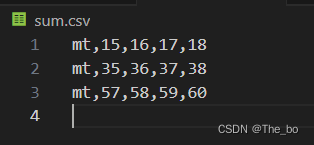
接下来我们需要将这些数据汇总到一个新csv中,并且想让这些数据一行一行输出,也就是转置,如果不想转置也无所谓,看个人需求。 我们先将数据存储到sum_data列表中,然后在写入csv中: sum_data=[] # 遍历每个CSV文件,提取数据并保存到新的CSV文件中 for csv_file in csv_files: df = pd.read_csv(os.path.join(current_path, csv_file),error_bad_lines=False,encoding='utf-8') # 提取指定列、行范围的数据 extracted_data = df.iloc[start_row:end_row, target_column] # 区间是左闭右开 sum_data.append(extracted_data) df2 = pd.concat(sum_data,axis=1) # df3 = pd.pivot(df2) # 转置 df3 = df2.T # 保存提取的数据到新的CSV文件中 new_csv_file = 'sum.csv' df3.to_csv(os.path.join(current_path, new_csv_file), index=True, header = False)最终结果,这里将列名去掉了,只保留了行名也就是index=True, header = False的作用:
在这过程中遇到pd.read_csv报错,可以参考这篇博客: 利用pandas读取csv文件时遇到UnicodeDecodeError问题以及解决过程-CSDN博客 完整代码附上: # -*- coding: utf-8 -*- import os import pandas as pd # 获取当前路径 current_path = os.getcwd() # 获取当前路径下所有CSV文件的文件名 csv_files = [f for f in os.listdir(current_path) if f.endswith('.csv')] # 指定要提取的列和行范围 # target_column = 'mt' # 假设提取'mt'列 target_column = 1 # 假设提取2列 start_row = 2 # 假设要提取从第3行开始 end_row = 6 # 假设要提取到第6行结束 sum_data=[] # 遍历每个CSV文件,提取数据并保存到新的CSV文件中 for csv_file in csv_files: df = pd.read_csv(os.path.join(current_path, csv_file),error_bad_lines=False,encoding='utf-8') # 提取指定列、行范围的数据 # extracted_data = df.loc[start_row:end_row, target_column] extracted_data = df.iloc[start_row:end_row, target_column] # 区间是左闭右开 # print(extracted_data) # 添加数据 sum_data.append(extracted_data) df2 = pd.concat(sum_data,axis=1) # df3 = pd.pivot(df2) df3 = df2.T # print(df3) # 保存提取的数据到新的CSV文件中 new_csv_file = 'sum.csv' df3.to_csv(os.path.join(current_path, new_csv_file), index=True, header = False) |
【本文地址】
今日新闻 |
推荐新闻 |