GNSS定位坐标序列抽稀算法及Python实现 |
您所在的位置:网站首页 › 经纬度blh › GNSS定位坐标序列抽稀算法及Python实现 |
GNSS定位坐标序列抽稀算法及Python实现
|
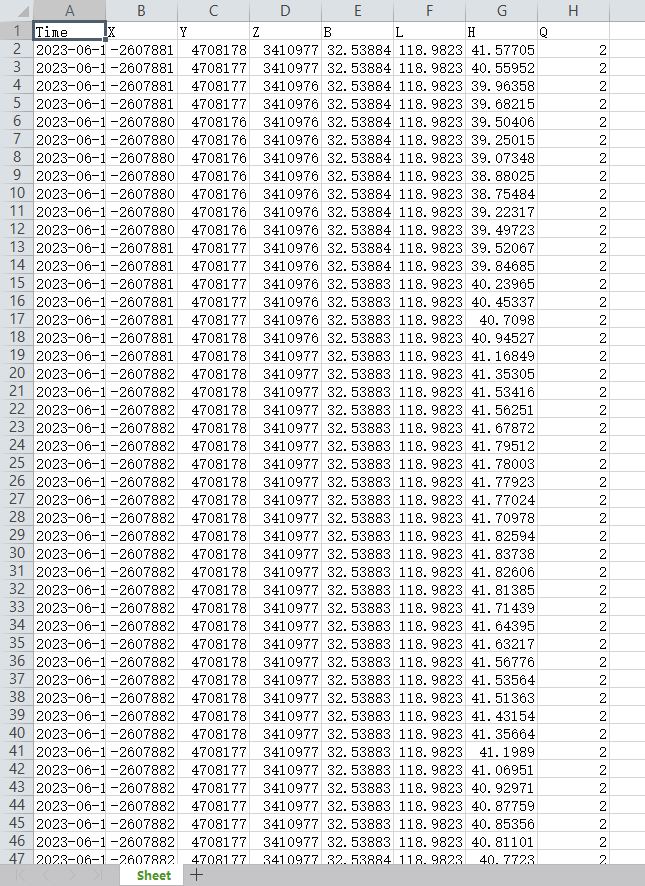
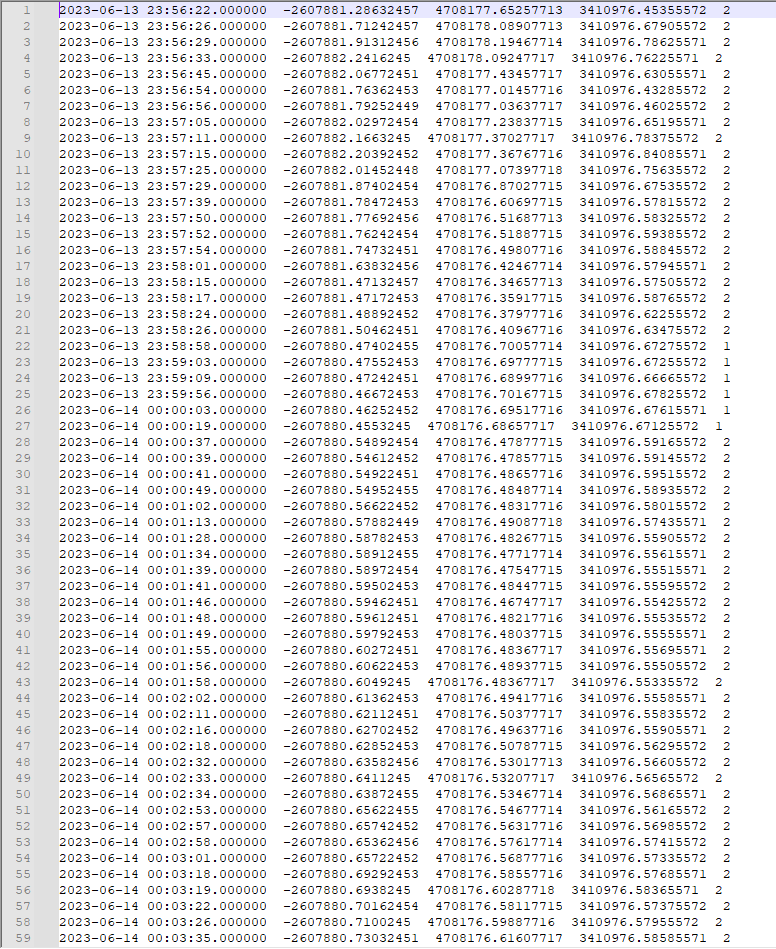
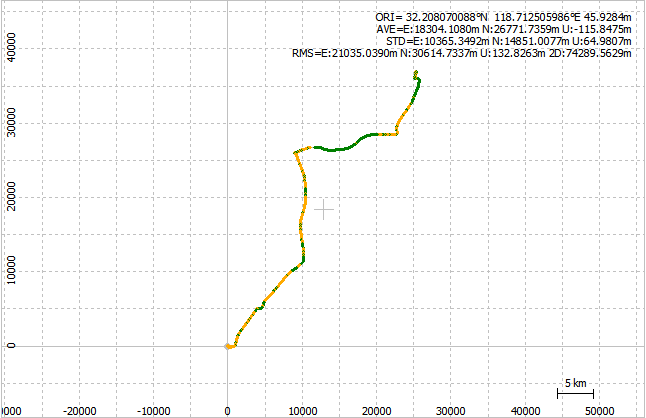
背景:在工程实践中,北斗/GNSS接收机输出的位置时间序列一般是1HZ采样率,数据量较大会导致再网页显示过程中出现加载缓慢的现象。很多时候由于各种原因,我们并不需要绘制全部的点,面对这样的情况我们需要对数据抽稀、舍弃不重要点,提高性能,同时不影响视觉效果。为了解决这个问题,本文主要介绍两个python代码 分别实现: 利用python代码read_posECEF_rtklib函数读取坐标后转换为BLH。对经纬度序列进行抽稀:抽稀过程需要考虑Q的状态:1、2、5分类进行抽稀。如果单类的点数较少,如少于500,则不进行抽稀。本文使用可被RTKPOST读取的lc29_spp_ref1_w1_amb-h_freq3.pos文件,调用read_posECEF_rtklib函数提取pos文件里面的XYZ 坐标,并将其转换为BLH。在得到经纬度数据之后,对经纬度序列进行抽稀处理,抽稀过程需要考虑Q的状态:1、2、5分类进行抽稀。抽稀结束后结果以excel文件输出,并且输出的是BLH坐标序列。此时我们将BLH坐标再转回xyz,且将excel文件转成pos,放如RTKPLOT中即可进行抽稀后结果的读取。 一、我们首先介绍一下read_posECEF_rtklib,它用于读取RTKLIB软件生成的文件,并提取文件中的位置信息。下面是对代码的逐行解释:这里定义了一个名为read_posECEF_rtklib的函数,它接受两个参数:ofile和iref。ofile是要读取的文件路径,iref是参考位置的坐标,是一个包含三个元素的列表(默认为空列表)。 代码声明: @Description :Read POS file data @Author :ZhaiWei @Version :1.0 @Contact :navsense [email protected] @Time :2023/07/01 21:47:28 import os import numpy as np import datetime from matplotlib.pylab import date2num from xyz2neu import * from xyz2blh import * from blh2xyz import * import gps_date,time_convert #tms用于存储时间戳,dneu用于存储东北天(ENU)坐标系下的位置偏差,blh1用于存储经纬度高程信息,solfix用于存储定位解的类型,section_coor是一个标志变量,用于指示当前读取的数据部分。 def read_posECEF_rtklib(ofile, iref=[]): tms = [] dneu = [[] for i in range(3)] blh1 = [[] for i in range(3)] solfix = [] section_coor = 0 #检查输入的文件路径是否存在,并给出相应的提示信息。如果文件不存在,函数将立即返回空的结果。 if len(ofile) > 0 and os.path.isfile(ofile): print("read_posECEF_rtklib for : " + ofile) else: print("Input file does not exist: " + ofile) return tms, dneu, blh1 with open(ofile) as fo: for ln in fo.readlines(): if 'x-ecef(m) y-ecef(m) z-ecef(m)' in ln: section_coor = 1 continue if 'e-baseline(m) n-baseline(m) u-baseline(m)' in ln: section_coor = 2 continue if section_coor == 1: info = ln.split() t0 = datetime.datetime.strptime(info[0] + ' ' + info[1], '%Y/%m/%d %H:%M:%S.%f') if len(iref) == 3: north, east, up = xyz2neu(iref[0], iref[1], iref[2], float(info[2]), float(info[3]), float(info[4])) dneu[0].append(north) dneu[1].append(east) dneu[2].append(up) solfix.append(int(info[5])) else: dneu[0].append(float(info[2])) dneu[1].append(float(info[3])) dneu[2].append(float(info[4])) solfix.append(int(info[5])) blh = xyz2blh(float(info[2]), float(info[3]), float(info[4])) blh1[0].append(blh[0]) blh1[1].append(blh[1]) blh1[2].append(blh[2]) tms.append(t0) if section_coor == 2: info = ln.split() t0 = datetime.datetime.strptime(info[0] + ' ' + info[1], '%Y/%m/%d %H:%M:%S.%f') neu = [float(info[2]), float(info[3]), float(info[4])] dneu[0].append(float(info[2])) dneu[1].append(float(info[3])) dneu[2].append(float(info[4])) solfix.append(int(info[5])) blh = xyz2blh(float(info[2]), float(info[3]), float(info[4])) blh1[0].append(blh[0]) blh1[1].append(blh[1]) blh1[2].append(blh[2]) tms.append(t0)这部分代码使用open函数打开文件,并逐行读取文件内容。根据文件中的特定行的内容,将数据分为两个部分进行处理。首先,检测到包含"x-ecef(m) y-ecef(m) z-ecef(m)"的行时,将section_coor设置为1,表示接下来要处理的是直角坐标系下的位置信息;检测到包含"e-baseline(m) n-baseline(m) u-baseline(m)"的行时,将section_coor设置为2,表示接下来要处理的是基线坐标系下的位置信息。 当section_coor为1时,将读取的行(ln)进行分割,将提取到的信息存储在变量info中。然后,根据iref的长度判断是否使用参考位置进行转换。如果iref的长度为3,表示提供了参考位置,将使用xyz2neu函数将直角坐标转换为东北天坐标,并将结果分别存储在dneu中的对应列表中。否则,直接将直角坐标存储在dneu中。同时,将定位解类型(info[5])存储在solfixed中。然后,使用xyz2blh函数将直角坐标转换为经纬度高程坐标,并将结果存储在blh1中。最后,将时间戳(t0)存储在tms中。 当section_coor为2时,处理方式类似,不过不涉及参考位置的转换。 return tms, dneu, blh1最后,函数返回提取到的时间戳(tms)、东北天坐标偏差(dneu)和经纬度高程坐标(blh1)。 二、我们调用这段代码 来进行pos文件里xyz的提取,并将XYZ 转成BLH。同时提取结果的状态。 import os import numpy as np import datetime from matplotlib.pylab import date2num from xyz2neu import * from xyz2blh import * from blh2xyz import * import gps_date, time_convert from openpyxl import Workbook # 定义函数 read_posECEF_rtklib,用于从文件中读取位置信息 def read_posECEF_rtklib(ofile, iref=[], extract_q=False): tms = [] # 存储时间戳 dneu = [[] for i in range(3)] # 存储东北天坐标偏差 blh1 = [[] for i in range(3)] # 存储经纬度高程坐标 solfix = [] # 存储定位解类型 q = [] # 存储附加信息(假设为第六列) section_coor = 0 # 用于标识当前处理的坐标系部分 # 检查输入文件是否存在 if len(ofile) > 0 and os.path.isfile(ofile): print("read_posECEF_rtklib for : " + ofile) else: print("Input file does not exist: " + ofile) return tms, dneu, blh1, solfix, q # 打开文件并逐行读取数据 with open(ofile) as fo: for ln in fo.readlines(): if 'x-ecef(m) y-ecef(m) z-ecef(m)' in ln: section_coor = 1 # 标识当前处理直角坐标系下的位置信息 continue if 'e-baseline(m) n-baseline(m) u-baseline(m)' in ln: section_coor = 2 # 标识当前处理基线坐标系下的位置信息 continue if section_coor == 1: info = ln.split() t0 = datetime.datetime.strptime(info[0] + ' ' + info[1], '%Y/%m/%d %H:%M:%S.%f') if len(iref) == 3: north, east, up = xyz2neu(iref[0], iref[1], iref[2], float(info[2]), float(info[3]), float(info[4])) dneu[0].append(north) dneu[1].append(east) dneu[2].append(up) solfix.append(int(info[5])) else: dneu[0].append(float(info[2])) dneu[1].append(float(info[3])) dneu[2].append(float(info[4])) solfix.append(int(info[5])) if extract_q: q.append(info[5]) # 假设第六列为需要提取的附加信息 blh = xyz2blh(float(info[2]), float(info[3]), float(info[4])) blh1[0].append(blh[0]) blh1[1].append(blh[1]) blh1[2].append(blh[2]) tms.append(t0) if section_coor == 2: info = ln.split() t0 = datetime.datetime.strptime(info[0] + ' ' + info[1], '%Y/%m/%d %H:%M:%S.%f') neu = [float(info[2]), float(info[3]), float(info[4])] dneu[0].append(float(info[2])) dneu[1].append(float(info[3])) dneu[2].append(float(info[4])) solfix.append(int(info[5])) if extract_q: q.append(info[5]) # 假设第六列为需要提取的附加信息 blh = xyz2blh(float(info[2]), float(info[3]), float(info[4])) blh1[0].append(blh[0]) blh1[1].append(blh[1]) blh1[2].append(blh[2]) tms.append(t0) return tms, dneu, blh1, solfix, q # 指定文件路径 ofile = r'C:\Users\Administrator\Desktop\代码撰写\lc29_spp_ref1_w1_amb-h_freq3.pos' # 调用函数读取文件数据 tms, dneu, blh1, solfix, q = read_posECEF_rtklib(ofile, extract_q=True) # 打印结果 print("Timestamps:") for tm in tms: print(tm) print("\nNEU Coordinates:") for i in range(len(dneu[0])): print(dneu[0][i], dneu[1][i], dneu[2][i]) print("\nBLH Coordinates:") for i in range(len(blh1[0])): print(blh1[0][i], blh1[1][i], blh1[2][i]) # 定义函数 write_results_to_excel,将结果写入 Excel 文件 def write_results_to_excel(tms, dneu, blh1, solfix, q): # 获取桌面路径 desktop_path = os.path.expanduser("~/Desktop") # 拼接输出文件路径 output_file = os.path.join(desktop_path, "result.xlsx") # 创建工作簿 workbook = Workbook() # 创建工作表 sheet = workbook.active # 设置表头 sheet.append(["Time", "X", "Y", "Z", "B", "L", "H", "Q"]) # 写入数据 for i in range(len(tms)): row = [ tms[i].strftime('%Y-%m-%d %H:%M:%S.%f'), dneu[0][i], dneu[1][i], dneu[2][i], blh1[0][i], blh1[1][i], blh1[2][i], q[i] ] sheet.append(row) # 保存工作簿 workbook.save(output_file) # 输出成功消息 print("Results have been written to:", output_file) # 调用函数将结果写入 Excel 文件 write_results_to_excel(tms, dneu, blh1, solfix, q)该代码片段展示了一个用于读取位置信息并将结果写入 Excel 文件的Python函数。read_posECEF_rtklib函数从给定的文件中读取位置信息,将时间戳、东北天坐标偏差、经纬度高程坐标、定位解类型以及附加信息存储在相应的变量中。write_results_to_excel函数将这些结果写入Excel文件,并保存在桌面上的result.xlsx文件中。 得到的excel结果文件: 三、我们写一个抽稀的脚本来对该文件进行抽稀处理 import pandas as pd在这个段落中,我们导入了pandas库,并将其重命名为pd,以便在后续代码中更方便地使用pd来引用pandas。 file_path = r'C:\Users\Administrator\Desktop\代码撰写\提取后的XYZ和BLH和Q.xlsx' df = pd.read_excel(file_path)这段代码用于读取指定路径的Excel文件。file_path变量存储了文件的路径。pd.read_excel函数被用来读取Excel文件,并将数据存储在DataFrame对象df中。 b_column = df.iloc[:, 4] l_column = df.iloc[:, 5] q_column = df.iloc[:, 7]这段代码用于提取DataFrame对象df中的特定列。通过使用df.iloc方法,我们可以按索引位置提取列数据。在这个例子中,我们提取了第5列(索引为4)、第6列(索引为5)和第8列(索引为7),并将它们分别存储在b_column、l_column和q_column变量中。 data = pd.DataFrame({'B': b_column, 'L': l_column, 'Q': q_column})这段代码用于将提取的列b_column、l_column和q_column组合成一个新的DataFrame对象data。通过使用pd.DataFrame构造函数,并传递一个字典,我们可以指定每个列的名称。 filtered_data = pd.DataFrame() for q_value in [1, 2, 5]: q_filtered_data = data[data['Q'] == q_value] if len(q_filtered_data) < 500: filtered_data = pd.concat([filtered_data, q_filtered_data]) else: sampled_data = q_filtered_data.sample(n=500) filtered_data = pd.concat([filtered_data, sampled_data])这段代码用于对数据进行抽稀处理。它首先创建一个空的DataFrame对象filtered_data来存储抽稀后的数据。 然后,通过循环迭代不同的Q值(1、2和5),选择具有相应Q值的行数据并存储在q_filtered_data中。 如果q_filtered_data的行数小于500,则直接将其添加到filtered_data中。 如果q_filtered_data的行数大于等于500,则使用sample()函数对数据进行抽样,例如从中随机选择500行数据,并将采样结果存储在sampled_data中。最后,将sampled_data与filtered_data合并。 filtered_data.to_excel(r'C:\Users\Administrator\Desktop\代码撰写\抽稀后的数据3.xlsx', index=False)这段代码将处理后的数据filtered_data保存到一个新的Excel文件。通过使用to_excel方法,我们可以将DataFrame对象中的数据保存到指定的文件路径。index=False参数用于禁止保存索引列。 四、通过抽稀之后 我们就能得到含有BLH 的excel结果文件,我们将其转换成pos文件之后,该文件可能会出现无法导入RTKPLOT的情况,这个时候我们将BLH列去除,留下“时间”、“X”、“Y”、“Z”、“Q” 得到的pos文件如图所示: 此时,我们将其导入RTKPLOT并可查看抽稀后的结果。 五:抽稀前后结果对比 抽稀前:
抽稀后:
对比抽稀前后的精度,我们发现在各个方向上的RMS均得到了提升。 |

【本文地址】