c语言多线程性能调优,C++性能优化(八) |
您所在的位置:网站首页 › 线程性能优化 › c语言多线程性能调优,C++性能优化(八) |
c语言多线程性能调优,C++性能优化(八)
|
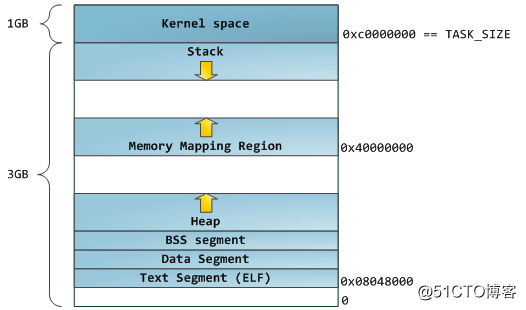
C++性能优化(八)——内存分配机制 一、操作系统内存布局 1、32位系统经典内存布局 Linux Kernel 2.6.7前版本采用的默认内存布局形式如下:
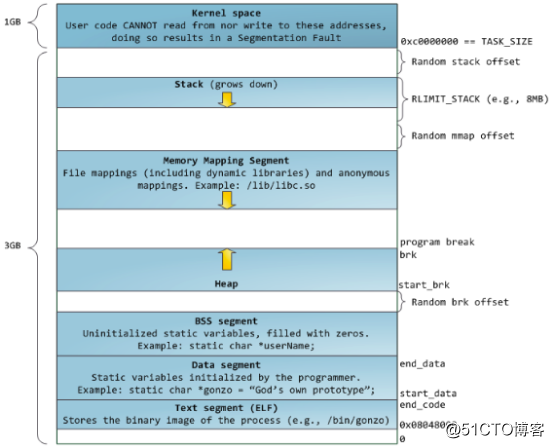
(1)32操作系统中,loader将可执行文件的各个段次依次载入到从0x80048000(128M)位置开始的空间中。应用程序能够访问的最后地址是0xbfffffff(3G)的位置,3G以上的位置是给内核使用的,应用程序不能直接访问。 (2)内存布局从低地址到高地址依次为:txet段、data段、bss段、heap、mmap映射区、stack栈区。 (3)heap和mmap是相对增长的,heap只有1G的虚拟地址空间可供使用。 (4)stack空间不需要映射,用户可以直接访问栈空间,因此是利用堆栈溢出进行的基础。 起始1GB地址为内核空间,随后是向下增加的栈空间和由0x40000000向上增加的MMAP地址;堆空间从底部开始,去除ELF、数据段、代码段、常量段后的地址,并向上增长。缺点是容易遭受溢出,堆地址空间只有不到1GB。 2、32位系统默认内存布局 Linux Kernel 2.6.7版本后32位操作系统的默认内存布局方式如下:
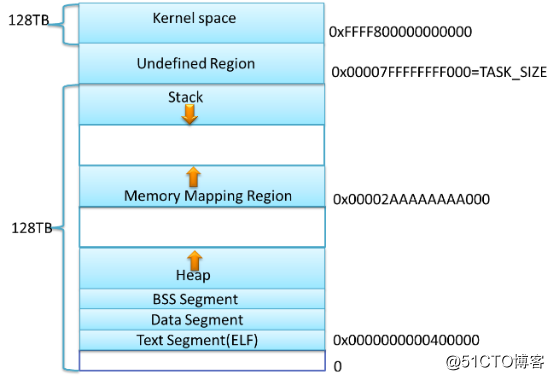
在经典内存布局基础上增加了Random offset随机偏移,不容易遭受溢出***;堆地址向上增长,但MMAP向下增长,栈空间不是动态增长的,会受到限制;内存地址利用率较高。 栈自顶向下扩展,但栈有边界,因此栈大小有限制(ulimit -s查看)。堆自底向上扩展,mmap映射区自顶向下扩展,mmap和heap是相对扩展,直至消耗尽虚拟地址空间中的剩余区域。 3、64位系统内存布局
64位操作系统的寻址空间比较大,沿用32位操作系统的经典内存布局,增加随机MMAP地址,防止溢出***。 二、操作系统内存管理机制 1、操作系统内存管理简介 内存管理自底向上分为三个层次: (1)操作系统内核的内存管理。 (2)glibc层使用系统调用维护的内存管理算法。 (3)应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化,比如使用引用计数std::shared_ptr,内存池方式等等。 应用程序可以直接使用系统调用从内核分配内存,根据程序特性自己维护内存,但会大大增加开发成本。 2、操作系统内存管理机制 Linux Kernel内存管理的基本思想是内存延迟分配,即只有在真正访问一个地址的时候才建立地址的物理映射。Linux Kernel在用户申请内存的时候,只分配一个虚拟地址,并没有分配实际物理地址,只有当用户使用内存时,Linux Kernel才会分配具体的物理地址给用户使用。 对于大内存,通常不同的内存分配方式都是直接MMAP;对于小数据,则通过向操作系统申请扩大堆顶,操作系统会把内存分页映射到进程堆空间,再由malloc管理内存堆块,减少系统调用;free内存时,不同内存分配方式有不同策略,不一定会将内存还给操作系统,因此如果访问释放的内存并不会立即Run Time Error,只有访问的地址没有对应的内存分页才会。 对于heap操作,操作系统提供brk系统调用,c运行库提供sbrk库函数;对于mmap映射区操作,操作系统提供了mmap和munmap系统调用。 3、heap操作系统调用接口 #include int brk(void *addr); void *sbrk(intptr_t increment); 当参数increment为0时,sbrk返回进程当前的brk值,increment为正数 |
【本文地址】