机器学习(二) |
您所在的位置:网站首页 › 线性概率模型的系数怎么求 › 机器学习(二) |
机器学习(二)
|
二、线性学习模型
回归跟分类的区别在于要预测的目标函数是连续值。 线性模型优点: ①形式简单、易于建模 ②可解释性 提及线性学习,我们首先会想到线性回归。 1、线性回归线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。通过构建损失函数,来求解损失函数最小时的参数w和b。 线性回归模型一般形式: 分别对w和b求偏导,可得 梯度下降法参考链接: ooon博客:深入梯度下降(Gradient Descent)算法https://www.cnblogs.com/ooon/p/4947688.html 安可的橙子博客:梯度下降法原理和实现https://blog.csdn.net/weixin_41919646/article/details/86652023 2、广义线性回归现实应用中,很多问题都是非线性的。 为拓展其应用场景,我们可以将线性回归的预测值 做一个非线性的函数变化去逼近真实值,这样得到 的模型统称为广义线性回归: 逻辑斯蒂(logistic function) 函数形似s,是Sigmoid 函数的典型代表,它将z值转化为一个接近0或1的y 值,并且其输出值在z=0附近变化很陡。其对应的模型称为逻辑斯蒂回归(logistic regression) 。 需要特别说明的是,虽然它的名字是“回归”, 但实际上却是一种分类学习方法。 优点:1)可以直接对分类可能性进行预测,将y视为样本x作为正例的概率;2)无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题;3)是任意阶可导的凸函数,可直接应用现有数值优化算法求取最优解。 logistic回归参考: feilong_csdn博客:logistic回归原理解析及Python应用实例 https://blog.csdn.net/feilong_csdn/article/details/64128443 4、线性判别分析(Linear Discriminant Analysis)
(1)多分类学习方法: ①二分类学习方法推广到多类; ②利用二分类学习器解决多分类问题(常用): 对问题进行拆分,为拆出的每个二分类任务训练一个分类器;对每个分类器的预测结果进行集成以获得最终的多分类结果 。 (2)拆分策略 ①一对一(One vs. One, OvO): 拆分阶段 : N个类别两两配对:N(N-1)/2 个二类任务; 各个二类任务学习分类器:N(N-1)/2 个二类分类器。 测试阶段: 新样本提交给所有分类器预测:N(N-1)/2 个分类结果 ; 投票产生最终分类结果:被预测最多的类别为最终类别。 ② 一对其余(One vs. Rest, OvR): 拆分阶段: 某一类作为正例,其余类作为反例:N 个二类任务; 各个二类任务学习分类器:N 个二类分类器。 测试阶段: 新样本提交给所有分类器预测:N 个分类结果; 比较各分类器的预测置信度:仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果;若有多个分类器预测为正类,选择置信度最大类别作为最终类别。 ③多对多(Many vs. Many, MvM): 若干类作为正类,若干个其他类作为反类 。 比较: ①一对一:训练N(N-1)/2个分类器,存储开销和测试时间大;训练只用两个类的样例,训练时间短。 ②一对其余:训练N个分类器,存储开销和测试时间小;训练用到全部训练样例, 训练时间长。 |
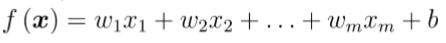 其中 xi 是x在第i个属性上的取值。 向量形式:
其中 xi 是x在第i个属性上的取值。 向量形式: 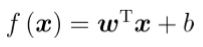 (1)目标/损失函数 预测值与真实值之间的平均距离,即均方误差。
(1)目标/损失函数 预测值与真实值之间的平均距离,即均方误差。 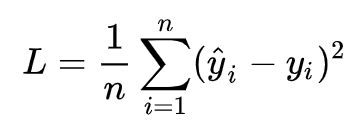
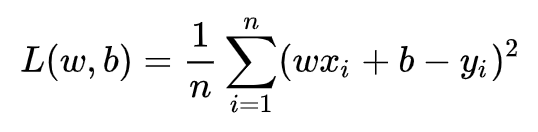 损失函数最小化即求解最小化L时的w和b的值,
损失函数最小化即求解最小化L时的w和b的值, 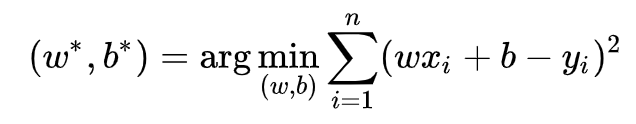 求解方法有两种:一是最小二乘法,二是梯度下降法。 (2)最小二乘法: 可用最小二乘法 (least square method) 对w 和b进行估计。下面以一元线性回归为例,来详细讲解w和b的最小二乘法估计 :
求解方法有两种:一是最小二乘法,二是梯度下降法。 (2)最小二乘法: 可用最小二乘法 (least square method) 对w 和b进行估计。下面以一元线性回归为例,来详细讲解w和b的最小二乘法估计 :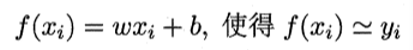 最小二乘法就是基于预测值和真实值的均方差最小化的方法来估计参数w和b:
最小二乘法就是基于预测值和真实值的均方差最小化的方法来估计参数w和b: 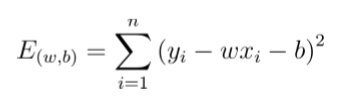 最小化均方误差
最小化均方误差 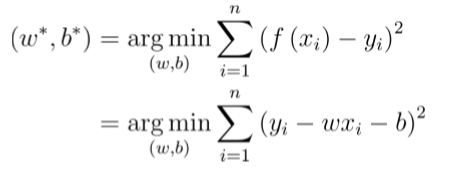
 令上两式为零可得到w和b最优解的闭式(closedform)解:
令上两式为零可得到w和b最优解的闭式(closedform)解:  (3)梯度下降: 梯度下降核心内容是对自变量进行不断的更新(针对w和b求偏导),使得目标函数不断逼近最小值的过程。
(3)梯度下降: 梯度下降核心内容是对自变量进行不断的更新(针对w和b求偏导),使得目标函数不断逼近最小值的过程。 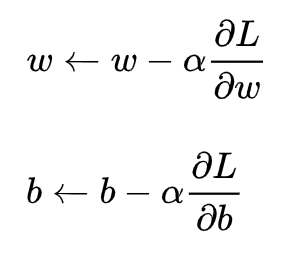 梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(梯度方向)变化最快,变化率最大;即函数在当前位置的导数。
梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(梯度方向)变化最快,变化率最大;即函数在当前位置的导数。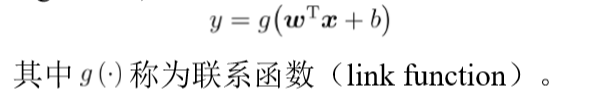 理论上,联系函数可以是任意函数,比如当被指定为指数函数时,得到的回归模型称为对数线性回归:
理论上,联系函数可以是任意函数,比如当被指定为指数函数时,得到的回归模型称为对数线性回归: 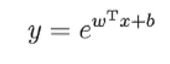 之所以叫对数线性回归,是因为它将真实值的对数作为线性回归逼近的目标,即
之所以叫对数线性回归,是因为它将真实值的对数作为线性回归逼近的目标,即 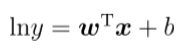
 LDA的思想: 欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小;欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大。 变量说明: 第i类示例的集合xi 第i类示例的均值向量
LDA的思想: 欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小;欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大。 变量说明: 第i类示例的集合xi 第i类示例的均值向量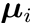 第i类示例的协方差矩阵
第i类示例的协方差矩阵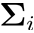 两类样本的中心在直线上的投影:
两类样本的中心在直线上的投影: 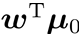 和
和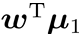 两类样本的协方差:
两类样本的协方差: 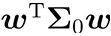 和
和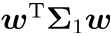 最大化目标
最大化目标 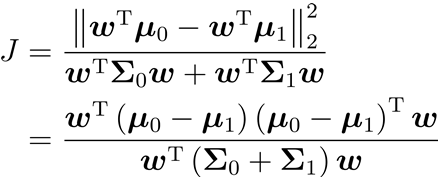 类内散度矩阵
类内散度矩阵 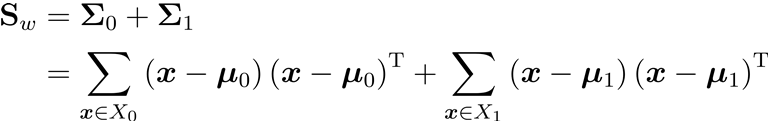 类间散度矩阵
类间散度矩阵 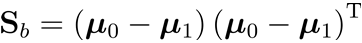
【本文地址】
今日新闻 |
推荐新闻 |