线性回归 |
您所在的位置:网站首页 › 线性回归模型方程中参数怎么算 › 线性回归 |
线性回归
|
回归分析是用来评估变量之间关系的统计过程。用来解释自变量X与因变量Y的关系。即当自变量X发生改变时,因变量Y会如何发生改变。 线性回归是回归分析的一种,评估的自变量X与因变量Y之间是一种线性关系。当只有一个自变量时,称为简单线性回归,当具有多个自变量时,称为多元线性回归。 线性关系的理解: 画出来的图像是直的。每个自变量的最高次项为1。拟合是指构建一种算法,使得该算法能够符合真实的数据。从机器学习角度讲,线性回归就是要构建一个线性函数,使得该函数与目标值之间的相符性最好。从空间的角度来看,就是要让函数的直线(面),尽可能靠近空间中所有的数据点(点到直线的平行于y轴的距离之和最短)。线性回归会输出一个连续值。 线性回归模型 简单线性回归我们可以以房屋面积(x)与房价(y)为例,二者是线性关系,房屋价格正比于房屋面积,假设比例为w: 现实中的数据可能是比较复杂的,自变量也可能不止一个,例如,影响房屋价格也很可能不止房屋面积一个因素,可能还有是否在地铁附近,房间数,层数,建筑年代等诸多因素。不过,这些因素对房价影响的权重是不同的,因此,我们可以使用多个权重来表示多个因素与房屋价格的关系:
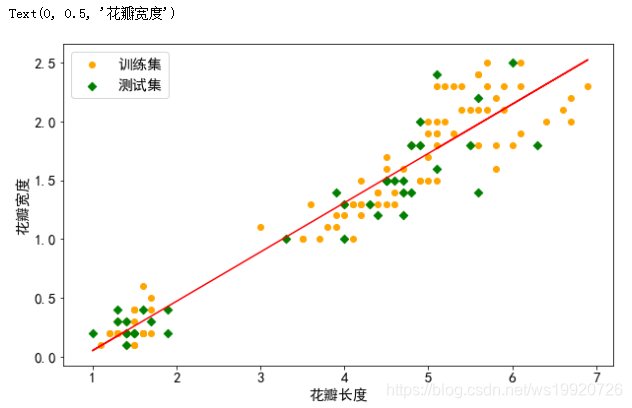
对于机器学习来讲,就是从已知数据去建立一个模型,使得该模型能够对未知数据进行预测。实际上,机器学习的过程就是确定模型参数的过程。 对于监督学习来说,我们可以通过建立损失函数来实现模型参数的求解,损失函数也称目标函数或代价函数,简单来说就是关于误差的一个函数。损失函数用来衡量模型预测值与真实值之间的差异。机器学习的目标,就是要建立一个损失函数,使得该函数的值最小。 也就是说,损失函数是一个关于模型参数的函数(以模型参数w作为自变量的函数),自变量可能的取值组合通常是无限的,我们的目标,就是要在众多可能的组合中,找到一组最合适的自变量组合,使得损失函数的值最小。 在线性回归中,我们使用平方损失函数(最小二乘法),定义如下: 我们以鸢尾花数据集中花瓣长度与花瓣宽度为例,通过程序实现简单线性回归。 import numpy as np #用于线性回归的类 from sklearn.linear_model import LinearRegression #用来切分训练集与测试集 from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris #设置输出精度。默认为8 np.set_printoptions(precision=2) iris = load_iris() #获取花瓣长度作为x,花瓣宽度作为y。 x, y = iris.data[:,2].reshape(-1,1), iris.data[:,3] lr = LinearRegression() x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=0) #使用训练集数据,训练模型。 lr.fit(x_train, y_train) print('权重:', lr.coef_) print('截距:', lr.intercept_) y_hat = lr.predict(x_test) print('实际值:', y_test[:5]) print('预测值:', y_test[:5])
对于回归模型,我们可以采用如下指标进行衡量。 MSERMSEMAER2 MSEMSE(Mean Squared Error),平均平方差,为所有样本数据误差(真实值与预测值之差)的平方和,然后取均值。 RMSE(Root Mean Squared Error),平均平方误差的平方根,即在MSE的基础上,取平方根。 MAE(Mean Absolute Error),平均绝对值误差,为所有样本数据误差的绝对值和。 R2为决定系数,用来表示模型拟合性的分值,值越高表示模型拟合性越好,在训练集中,R2的取值范围为[0,1]。在R2的取值范围为[-∞,1]。 R2的计算公式为1减去RSS与TSS的商。其中,TSS(Total Sum of Squares)为所有样本数据与均值的差异,是方差的m倍。而RSS(Residual sum of Squares)为所有样本数据误差的平方和,是MSE的m倍。
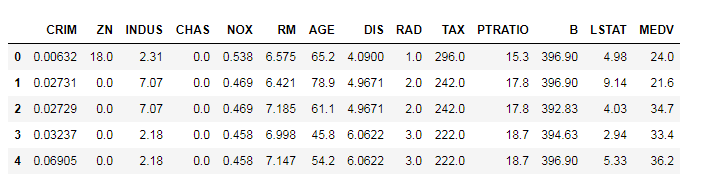
我们可以以波士顿房价为例来做程序演示 from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.datasets import load_boston import pandas as pd boston = load_boston() x, y = boston.data, boston.target df = pd.DataFrame(np.concatenate([x, y.reshape(-1,1)], axis=1), columns = boston.feature_names.tolist()+['MEDV']) df.head()
|
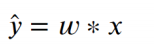 然而,这种线性方程一定是过原点的,即x为0时,y也一定为0。这可能并不符合现实中某些场景。为了能够让方程具有更广泛的适应性,就要再增加一个截距,设为b,则方程可以变为:
然而,这种线性方程一定是过原点的,即x为0时,y也一定为0。这可能并不符合现实中某些场景。为了能够让方程具有更广泛的适应性,就要再增加一个截距,设为b,则方程可以变为: 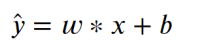 以上方程就是数据建模的模型,w与b就是模型的参数。 线性回归是用来解释自变量与因变量之间的关系,但这种关系并非严格的函数映射关系。
以上方程就是数据建模的模型,w与b就是模型的参数。 线性回归是用来解释自变量与因变量之间的关系,但这种关系并非严格的函数映射关系。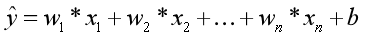
 这样,就可以表示为:
这样,就可以表示为: 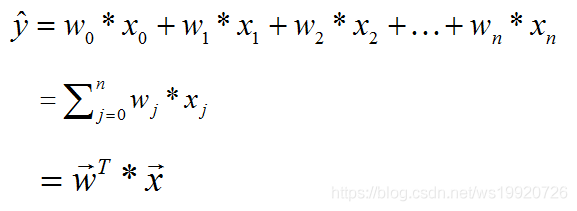 多元线性回归在空间中,可以表示为一个超平面,去拟合空间中的数据点。 我们的目的就是从现有的数据中,去学习w与b的值。一旦w与b的值确定,就能够确定拟合数据的线性方程,这样就可以对未知的数据x进行预测y(房价)。
多元线性回归在空间中,可以表示为一个超平面,去拟合空间中的数据点。 我们的目的就是从现有的数据中,去学习w与b的值。一旦w与b的值确定,就能够确定拟合数据的线性方程,这样就可以对未知的数据x进行预测y(房价)。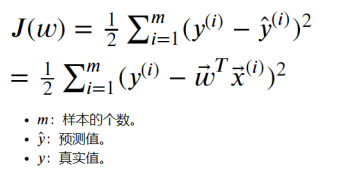


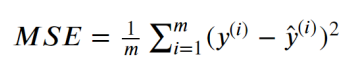
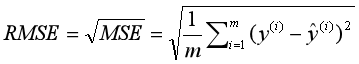
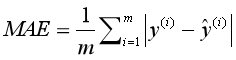
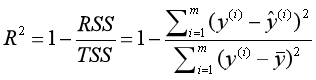
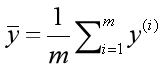 从公式定义可知,最理想情况,所有的样本数据的预测值与真实值相同,即RSS为0,此时R2为1。
从公式定义可知,最理想情况,所有的样本数据的预测值与真实值相同,即RSS为0,此时R2为1。

【本文地址】
今日新闻 |
推荐新闻 |