|
线性回归 (一)
1 线性回归原理
1.1 定义与公式
线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归。 通用公式 : 其中w,x可以理解为矩阵: 其中w,x可以理解为矩阵: 线性回归用矩阵表示举例: 线性回归用矩阵表示举例:  写成矩阵形式: 写成矩阵形式: 从列的角度看: 从列的角度看:  那么怎么理解呢?我们来看几个例子 那么怎么理解呢?我们来看几个例子
①期末成绩:0.7×考试成绩+0.3×平时成绩 ②房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
上面两个例子, 我们看到特征值与目标值之间建立了一个关系,这个关系可以理解为线性模型 。
1.2 线性回归的特征与目标的关系分析
线性回归当中主要有两种模型, 一种是线性关系,另一种是非线性关系。
线性关系又可以分为单变量线性关系,多变量线性关系
单特征与目标值的关系呈直线关系,或者两个特征与目标值呈现平面的关系,更高维度的我们不用自己去想,记住这种关系即可
如果是非线性关系,那么它的回归方程可以理解为: 存在变量的多次方的关系。 存在变量的多次方的关系。
1.3 线性回归API
sklearn中, 线性回归的API在linear_model模块中 sklearn.linear_model.LinearRegression() LinearRegression.coef_:回归系数 例如: 使用代码对其进行实现: 使用代码对其进行实现:
from sklearn.linear_model import LinearRegression
# 加载数据
x = [[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]]
y = [84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]
# 实例化API
estimator = LinearRegression()
# 使用fit方法进行训练
estimator.fit(x,y)
print(estimator.coef_)
# 对未知样本预测
estimator.predict([[100, 80]])
结果: 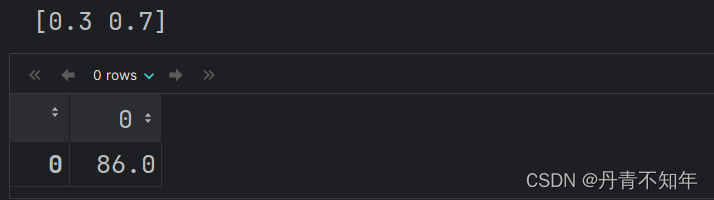 即: ①线性回归公式 : 即: ①线性回归公式 :  为目标值 为目标值
②线性回归公式中,w、b 代表模型参数 ③LinearRegression.fit 表示模型训练函数 ④LinearRegression.predict 表示模型预测函数 ⑥线性回归模型的目标:通过学习得到线性方程的这两个权值,如在y=kx+b中,得到k和b两个权值,并用这个方程解释变量和目标变量之间的关系
2 损失函数和正规方程
2.1 损失函数的概念
损失函数的概念:
①用来衡量机器学习模型性能的函数 ②损失函数可以计算预测值与真实值之间的误差(用一个实数来表示),误差越小说明模型性能越好
损失函数的作用:确定损失函数之后, 我们通过求解损失函数的极小值来确定机器学习模型中的参数 先看下面的例子,有如下一组训练数据
X = [0.0, 1.0, 2.0, 3.0]
y = [0.0, 2.5, 3.3, 6.2]
 很显然,上面的数据中,X与y的关系可以近似的表示为一元线性关系, 即: y = WX (注意:当前例子中, y 和 X均为已知,由训练数据给出,W为未知) 训练线性回归模型模型的过程实际上就是要找到一个 合适的W ,那么什么才是合适的W,我们先随机的给出几个W看下效果 很显然,上面的数据中,X与y的关系可以近似的表示为一元线性关系, 即: y = WX (注意:当前例子中, y 和 X均为已知,由训练数据给出,W为未知) 训练线性回归模型模型的过程实际上就是要找到一个 合适的W ,那么什么才是合适的W,我们先随机的给出几个W看下效果
当W = 5.0时如下图所示:  从上图中可以观察到模型预测值与真实值不同,我们希望通过一个数学表达式来表示这个差值: ①很自然的能想到,将真实值与预测值相减并查看结果是否等于零,不为零意味着预测有误差 ②误差的大小是坐标系中两点之间的距离 我们将距离定义为: 从上图中可以观察到模型预测值与真实值不同,我们希望通过一个数学表达式来表示这个差值: ①很自然的能想到,将真实值与预测值相减并查看结果是否等于零,不为零意味着预测有误差 ②误差的大小是坐标系中两点之间的距离 我们将距离定义为:  根据上面的公式, 我们可以计算出当W=5.0时预测的误差分别为: 根据上面的公式, 我们可以计算出当W=5.0时预测的误差分别为:
 在前面的概念中提到, 损失函数的计算结果应该为一个具体的实数,因此我们将上面所有点的预测误差相加得到: 在前面的概念中提到, 损失函数的计算结果应该为一个具体的实数,因此我们将上面所有点的预测误差相加得到:
 从上面的结果中发现,误差有些大,我们的模型应该还有调整的空间,尝试将W减小,令W=0.5 从上面的结果中发现,误差有些大,我们的模型应该还有调整的空间,尝试将W减小,令W=0.5  根据公式我们可以计算出当W=0.5时预测的误差分别为: 根据公式我们可以计算出当W=0.5时预测的误差分别为:  再尝试W=2: 再尝试W=2: 根据公式我们可以计算出当W=2时预测的误差分别为: 根据公式我们可以计算出当W=2时预测的误差分别为:  我们前面提到,利用损失函数可以确定损失的大小,损失越小的模型效果越好,通过对比发现 我们前面提到,利用损失函数可以确定损失的大小,损失越小的模型效果越好,通过对比发现
 当前的计算方法中 当W=0.5的cost的值最小,但从图像中可以看出当W=2时,模型拟合的更好 当W=2时计算出的误差为0,但实际情况除了d0之外其余点均存在预测误差 综上所述,我们用来衡量回归损失的时候, 不能简单的将每个点的预测误差相加 当前的计算方法中 当W=0.5的cost的值最小,但从图像中可以看出当W=2时,模型拟合的更好 当W=2时计算出的误差为0,但实际情况除了d0之外其余点均存在预测误差 综上所述,我们用来衡量回归损失的时候, 不能简单的将每个点的预测误差相加
2.2 平方损失
回归问题的损失函数通常用下面的函数表示:  ①yi 为第i个训练样本的真实值 ②h(xi) 为第i个训练样本特征值组合预测函数又称最小二乘法 我们的目标是: 找到该损失函数最小时对应的 w、b. ①yi 为第i个训练样本的真实值 ②h(xi) 为第i个训练样本特征值组合预测函数又称最小二乘法 我们的目标是: 找到该损失函数最小时对应的 w、b.
接下来我们开始对平方损失求解最优解
2.3 正规方程
正规方程公式:  那么,该公式是如何得出的? 那么,该公式是如何得出的?  上式对W求导数 上式对W求导数  令导数等于0 可以求得W 令导数等于0 可以求得W  示例代码: 示例代码:
import numpy as np
from sklearn.linear_model import LinearRegression
if __name__ == '__main__':
# 特征值
x = np.mat([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
# 目标值
y = np.mat([84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]).transpose()
# 给特征值增加一列1
ones_array = np.ones([len(x), 1])
x = np.hstack([ones_array, x])
# 使用正规方程公式计算 w、b
w = (x.transpose() * x) ** -1 * x.transpose() * y
print('[%.1f %.1f %.1f]' % (w[0][0], w[1][0], w[2][0]))
# 使用 LinearRegression 求解
estimator = LinearRegression(fit_intercept=True)
estimator.fit(x, y)
print(estimator.coef_[0])
# 输出结果
# [0.0 0.3 0.7]
# [0. 0.3 0.7]
即: ①损失函数在训练阶段能够指导模型的优化方向,在测试阶段能够用于评 ②估模型的优劣。 ③线性回归使用平方损失 ④正规方程是线性回归的一种优化方法
|