数据分析 |
您所在的位置:网站首页 › 红酒知识每日一学 › 数据分析 |
数据分析
|
文章目录
1.读取本的数据集2.查看数据的前5行3.将salary列的数据转换为最大值和最小值的平均值4.将数据根据学历进行分组计算平均值5.将createTime列转换为月日6.查看所索引,数据类型和内存信息7.查看数值型列的汇总统计8.新增一列根据salary将数据分为三组9.按照salary列队数据降序排序10.取出第33行的数据
1.读取本的数据集
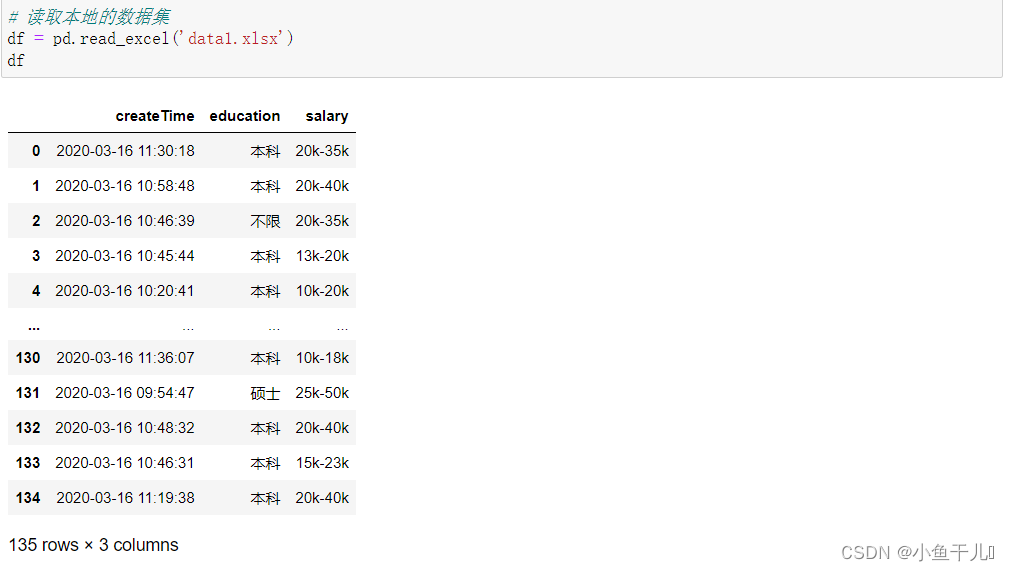
# 读取本地的数据集
# 数据集可以私信我我发给你们,同样也可以
df = pd.read_excel('data1.xlsx')
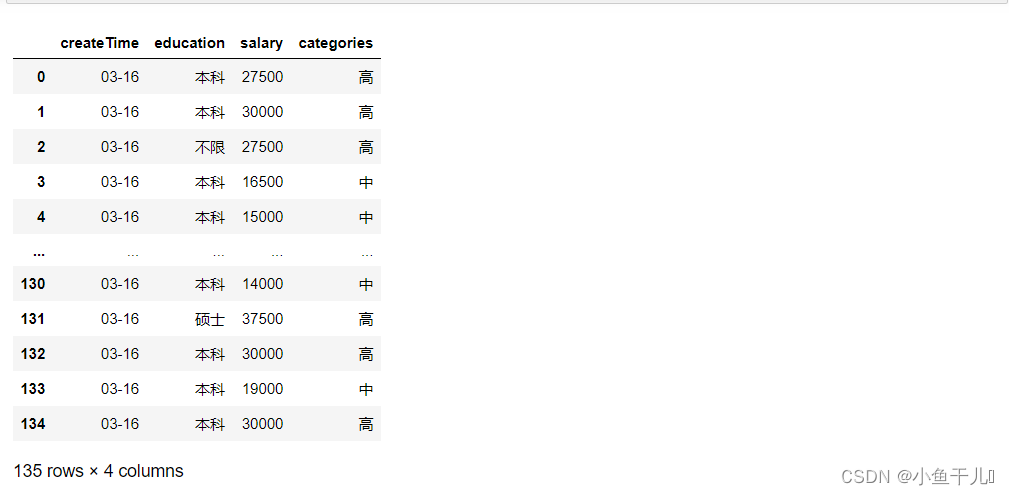
df
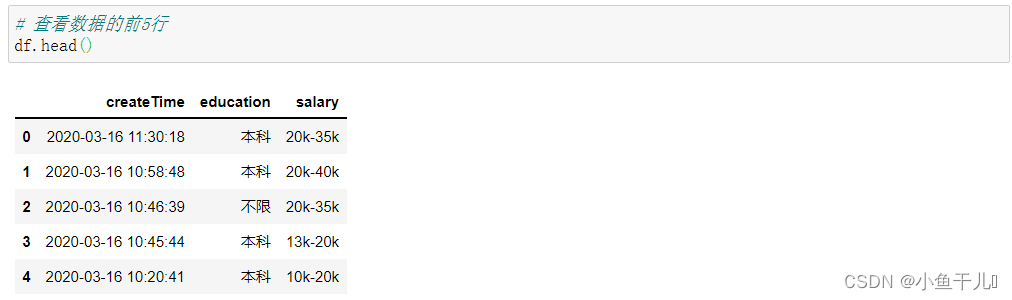
使用head()函数查看数据的前几行,可以传入具体的数,默认是5 # 查看数据的前5行 df.head()
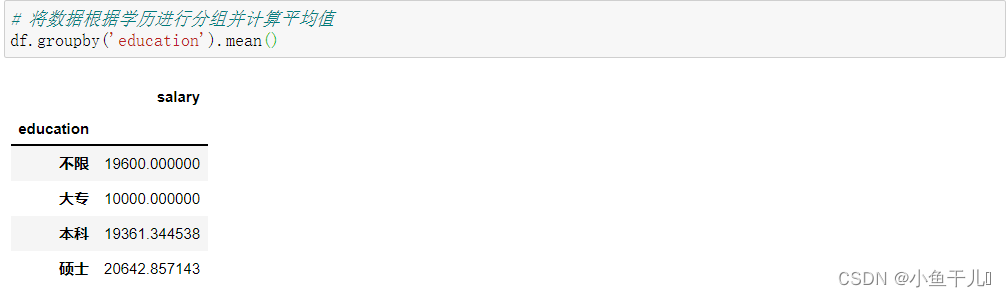
map和apply函数接受的参数都是一个行数,而且都不会直接改变原数据,都是返回一个新的DataFrame对象 # 将salary列数据转换为最大值和最小值的平均值 # 方式一 使用map函数 def fun(x): a,b = x.split('-') a = int(a.strip('k'))*1000 b = int(b.strip('k'))*1000 return int((a+b)/2) df['salary'].map(fun) # 方式二使用apply函数 df['salary'] = df['salary'].apply(fun) df 4.将数据根据学历进行分组计算平均值使用groupby()函数进行分组 # 将数据根据学历进行分组并计算平均值 df.groupby('education').mean()
info()函数 # 查看索引,数据类型,和内存信息 df.info()
describe() 返回的数据包括,数量,数据的平均值,标准差,最小值,最大值,25%、50% 75 % 的分位数 # 查看数值型列的汇总统计 df.describe()
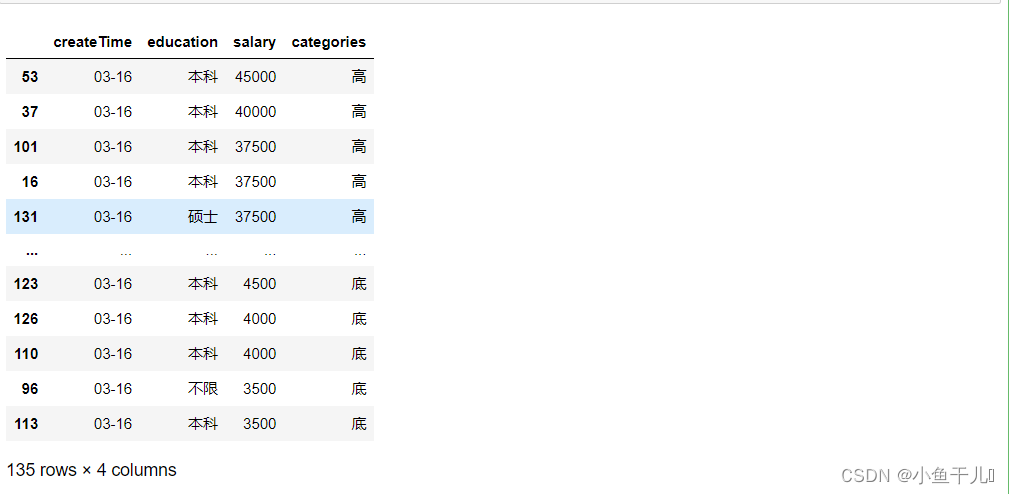
sort_values 默认是升序 # 按照salary列对数据降序排列 # ascending=False降序 # ascending=True升序 df.sort_values('salary',ascending=False)
根据索引选出第33行,索引从0开始 # 取出第33行的数据 df.loc[32]
今天的10道题涉及的东西多了一些,groupby、describe、cut、sort_values、info等,如果想要全部的了解这些,仅靠这10道题是远远不够的,希望大家能够额外找些试题练习,也可以根据跟着博主的文章一块刷题✨✨✨ 推荐使用牛客网进行练习 直达牛客,快人一步
欢迎您的关注 |




【本文地址】