使用深度学习的可见光和红外图像融合综述 |
您所在的位置:网站首页 › 红外遥感技术应用论文 › 使用深度学习的可见光和红外图像融合综述 |
使用深度学习的可见光和红外图像融合综述
|
Visible and Infrared Image Fusion Using Deep Learning
@article{zhang_visible_2023, title = {Visible and Infrared Image Fusion Using Deep Learning}, url = {https://ieeexplore.ieee.org/document/10088423/}, doi = {10.1109/TPAMI.2023.3261282}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, author = {Zhang, Xingchen and Demiris, Yiannis}, month = aug, year = {2023}, } 摘要近年来,可见光和红外图像融合(VIF)因其在目标检测、目标跟踪、场景分割和人群计数等许多任务中的应用而引起了人们的广泛关注。除了传统的VIF方法外,在过去五年中,越来越多的基于深度学习的VIF方法被提出。已经提出了不同类型的方法,例如基于CNN的方法,基于自动编码器的方法,基于GAN的方法和基于变压器的方法。基于深度学习的方法无疑已成为VIF任务的主要方法。然而,虽然已经取得了很大进展,但该领域将受益于对这些基于深度学习的方法的系统审查。在本文中,我们对基于深度学习的VIF方法进行了全面的综述。我们详细讨论了动机、分类法、近期发展特征、数据集和绩效评估方法。我们还讨论了VIF领域的未来前景。本文可作为VIF研究人员和有兴趣进入这一快速发展领域的人的参考。 关键词深度学习、图像融合、多模态融合、RGB-T、可见-红外图像融合 1.介绍可见光和红外图像融合(VIF) 多年来一直是一个活跃的研究课题 [1]、[2]、[3]、[4]、[5]、[6]。这是由于可见光和红外图像的互补特性使VIF能够应用于许多应用,例如目标跟踪[7],[8],[9],[10],[11],目标检测[12],[13],[14],[15]和生物特征识别[16],[17]。具体来说,可见光图像包含丰富的纹理细节,同时它们对照明变化很敏感。相比之下,红外图像显示的热信息对照明变化不敏感。但是,红外图像无法提供足够的纹理细节。VIF的目的是将来自可见光和红外图像的信息结合起来,生成融合图像,该图像信息量更大,因此可以促进下游应用,如图1所示。 在深度学习被引入VIF之前,人们提出了各种传统的VIF方法。传统的VIF方法根据其对应的理论一般可分为几种类型,即基于多尺度变换的方法、基于稀疏表示的方法、基于子空间的方法、基于显著性的方法、混合方法和其他方法[19]。 近年来,研究人员开始使用深度学习技术进行VIF[20]。据我们所知,Wu等[21]是最早在VIF中使用深度学习的研究人员之一。在他们的研究中,他们使用深度玻尔兹曼机(DBM)来决定如何融合源图像的系数。从那时起,许多基于深度学习的VIF方法被提出。如图2所示,从2018年到2022年,每年发表的关于深度学习的VIF方法的论文数量增长非常快。 在方法方面,提出了有监督的[22]、[23]、[24]和无监督的VIF方法[25]、[26]、[27]、[28]。此外,各种深度学习模型,如CNN [29]、[30]、[31]、GANs[6]、[24]、[32]、[33]和transformers[34]、[35]、[36]、[37],已被用于执行VIF。图 3 显示了基于深度学习的 VIF方法的发展时间表及其关键里程碑。 然而,由于缺乏对基于深度学习的VIF方法的全面回顾,研究人员,尤其是那些想进入该领域的研究人员,很难理解该领域的过去、现在和未来。在VIF领域有一些综述论文[19],[38],[39],[40]。然而,马等[19]在2018年初发表了他们的全面综述论文,因此主要涵盖了传统的VIF方法。Zhang等[38]对基于VIF的目标跟踪进行了综述。然而,那篇论文的重点是物体跟踪,而不是生成融合图像的图像融合方法。Sun等[39]总结了一些基于深度学习的VIF方法,但此后已经发表了许多新的基于深度学习的方法。Zhang等[40]对基于深度学习的图像融合方法进行了非常有用的研究,但没有关注VIF。 本文对基于深度学习的VIF方法进行了综述,包括动机、分类、不同类型方法的讨论、近期发展特点、数据集和未来展望。综上所述,本文的主要贡献在于以下几个方面: 基于深度学习的方法的全面综述。我们对VIF文献进行了彻底的筛选,并分析了具有代表性的基于深度学习的方法。据我们所知,这是迄今为止对基于深度学习的VIF方法最全面的综述。全面总结了基于深度学习的VIF方法的最新发展特征。这些特征是在阅读了 200 多篇基于深度学习的 VIF 论文后总结出来的。因此,他们可以展示近年来基于深度学习的VIF方法是如何发展的。对未来前景的详细讨论。本文基于综述和实践经验,对VIF的未来发展前景进行了展望。我们希望这些可以帮助吸引更多的研究人员研究VIF领域的关键问题,并能为这个快速发展的领域提供一些启示。本文的其余部分组织如下。第二部分综述了基于深度学习的VIF方法。然后,第三节讨论了一般的图像融合方法,然后在第四节中分析了VIF领域的最新发展特征。然后,第五节总结了数据集,第六节讨论了性能评估方法。接下来,第七节讨论了未来的前景。最后,第八节总结了本文。 2. 基于深度学习的可见-红外图像融合方法 2.1 背景图像融合[122]已经研究了30多年,包含多种变体,包括可见光-红外图像融合(VIF)[19]、多焦点图像融合(MFIF)[123]、多曝光图像融合(MEF)[124]、医学图像融合(MEDIF)[125]和遥感图像融合[126]。在图像融合中,VIF是研究最多的任务之一,因为可见光和红外图像的互补特性对许多应用非常有益。 一般来说,VIF可以在三个级别执行[38]:像素级、特征级和决策级。在像素级 VIF 中,首先对可见光和红外图像进行融合以生成融合图像,并据此执行下游应用。在要素级 VIF 中,首先从可见光和红外图像中提取要素,然后进行融合。然后根据融合特征执行下游应用。在决策级 VIF 中,应用程序分别在可见光和红外图像上运行。然后将获得的结果融合以生成最终结果。在图像融合文献中,VIF 通常是指像素级 VIF 方法。本文中,VIF是指像素级VIF,即使用可见光和红外图像生成融合图像。值得一提的是,像素级 VIF 中没有真值融合图像。 2.2 在 VIF 中使用深度学习的动机VIF方法通常包括三个阶段,即特征提取、特征融合和图像重建,如图4所示。
首先,提取可见光和红外图像的特征;然后,融合这些特征。最后,进行图像重建,得到融合后的图像。 对于VIF方法,所有三个阶段对于良好的性能都是必不可少的。首先,应从可见光和红外图像中提取互补特征。更具体地说,需要提取可见光图像中的细节和纹理信息以及红外图像中的突出信息。其次,这些互补特征应有效融合。最后,应有效地重建融合后的图像。然而,这些阶段是用传统的VIF方法手动设计的,在处理各种工作条件时不是很有效。因此,传统方法提供良好融合图像的能力可能有限。 深度学习在各个图像处理领域都取得了巨大的成功。在过去的几年里,研究人员非常重视使用深度学习进行VIF,以实现更好的融合性能。请注意,深度学习只能应用于图像融合过程的一部分。 2.3 基于深度学习的VIF方法分类基于深度学习的 VIF 方法可以以不同的方式进行分组。根据训练过程中是否使用真实标签,它们可以分为监督方法和无监督方法。这里,监督意味着该方法需要在训练中对某些形式进行注释,这些形式可能不是真实融合图像。根据采用的模型类型,它们可分为基于CNN的方法、基于自动编码器(AE)的方法、基于GAN的方法、基于transformer的方法等。根据方法是否端到端,VIF方法可分为端到端方法和非端到端方法。在端到端方法中,融合图像直接从源图像生成,无需使用手动设计的步骤,例如图像分解、单独训练和基于权图的加权求和。相比之下,在非端到端方法中,至少需要一个手动设计的步骤。此外,VIF方法可分为全卷积方法和非全卷积方法。此外,在 VIF 中使用了不同的网络架构。一般来说,有单分支和双分支架构,如图 5 所示。 在单分支架构中,可见光和红外图像在通道方向上连接在一起,形成一个4通道输入 [22], [45],即输入深度学习模型。相比之下,在双分支架构中,可见光和红外图像分别由两个分支处理。在某些情况下,这两个分支是相同的 [42]、[57]、[59]、[89](权重共享)。然而,由于可见光和红外图像属于不同的模态,因此在许多情况下,分别使用两个独立的分支(没有权重共享)来处理它们。表1给出了代表性的基于深度学习的VIF方法的概述,本节的以下内容根据所采用的深度学习模型进行组织。 据我们所知,Liu等[29]提出了最早的基于CNN的VIF方法之一。在这项工作中,使用Siamese CNN从源图像生成权重映射图。使用拉普拉斯金字塔对源图像进行分解,使用高斯金字塔对权重映射图进行分解。然后以多尺度方式进行融合。该模型使用高质量图像进行训练,并使用多尺度高斯滤波和随机采样生成其模糊版本。作为一种基于深度学习的VIF方法,该方法将CNN引入VIF。自Liu等[29]的工作以来,已经提出了许多基于CNN的VIF方法。 基于CNN的VIF方法的主要架构如图6所示。 无监督方法和监督方法的主要区别在于损失函数的构造方式。此外,在一些研究中,CNN仅应用于图像融合三个阶段的一部分。因此,图6所示的基于CNN的模型可能包含一些其他的手动步骤,例如,手动融合规则。 1)无监督方法:本节介绍具有代表性的基于CNN的无监督VIF方法,其整体架构如图6(a)所示。由于缺乏真实情况,损失函数通常使用融合图像和源图像来定义。具体而言,损失函数通常包含由图像融合评估指标构建的项。 (1):CNN 应用于 VIF 过程的一部分 在许多基于 CNN 的无监督方法中,CNN 仅应用于 VIF 过程的一部分。例如,Liu等[46]将源图像分解为基础部分和细节部分。然后,他们使用加权求和方法对基础部分进行融合,并使用CNN和多层特征融合策略对细节部分进行融合。Hou等[59]提出了使用CNN进行特征提取和图像重建的VIF-Net。 (2):CNN应用于整个VIF过程 在一些基于CNN的无监督方法中,CNN应用于整个VIF过程。例如,Xu等[107]和Mustafa等[60]在VIF的所有三个阶段都应用了CNN。 (3)提高性能的措施 采取了各种措施来提高基于CNN的VIF方法的性能,总结如下: 残差连接:残差连接[127]是深度学习中一种关键而有效的技术。它被引入VIFfieldbyLietal。[43] 在2019年。此后,许多VIF方法[27]、[60]、[83]、[87]、[128]利用残差连接,表现出良好的性能。例如,Long等[83]提出了一种基于密集残差网络的VIF方法(RXDNFuse),该方法将ResNet与DenseNet相结合。Li等[114]在编码器和解码器中都使用了残差连接。Mustafa等[60]提出了一个残余自注意力块来完善特征。密集连接:密集连接[129]在许多应用中表现出良好的性能。Li等[42]于2019年将其引入VIF领域,在编码器中使用密集连接以提高表示能力。从那时起,密集连接被广泛应用于VIF方法[57]、[59]、[80]、[83]、[85]、[86]、[89]、[107]、[130]以提高性能。大多数方法仅在特征提取阶段应用密集连接[42]、[57]、[83]、[85]、[130],而一些方法[80]在特征提取和图像重建阶段都应用密集连接。 注意力机制。合并注意力机制是提高 VIF 性能的最常用技术之一。已经使用了不同类型的注意力机制,包括通道注意力[45],[52],[89],[128]和空间注意力[80],[128]。注意力机制可以应用于VIF方法的不同阶段。在一些研究中,注意力机制用于细化特征[52],[57],[60],[128]。例如,Zhu等[52]利用多通道注意力机制来改善特征,Li等[57]使用预先训练的CNN从源图像中提取特征,然后采用注意力机制来实现更有效的特征提取,Mustafa等[60]利用自注意力机制来优化可见光和红外特征。在其他一些研究中,注意力机制被用作融合策略[131]。此外,在一些方法中,注意力机制用于进行特征细化和特征融合。例如,Wang等[80]利用Lp规范化注意力策略来提炼和组合深层特征。 多尺度特征。多尺度特征在基于CNN的VIF方法中经常被使用[52],[80],[132]。实现多尺度特征的一种方法是使用不同大小的卷积核,因为较小的核可以有效地提取低频信息,而较大的核可以捕获大的特征[52]。例如,Wang等[80]和Liu等[132]使用两种不同的核大小,即1×1和3×3核来提取多尺度特征。 多级特征。获取多级特征的一种方法是使用图像分解方法。例如,Yan等[133]首先将源图像分解为基础层和细节层。采用视觉显著权重图方法对基础层进行融合,对细节层进行多分辨率奇异值分解处理,生成多层次特征,然后采用预训练的VGG19进行融合。另一种实现方法是使用来自CNN不同层的特征,正如Li等人[30]首先所做的那样。从那时起,融合多级特征已成为许多VIF方法中提高融合性能的常用技术[80],[107],[114]。 对比学习。在VIF中,红外图像中的突出物体和可见光图像中的背景细节通常保留在融合图像中[31]。因此,融合后的图像通常类似于突出物体中的红外图像和背景细节中的可见图像。基于这个想法,对比学习可以应用于 VIF。例如,Zhu等[109]通过设计对比学习框架和对比损失,将对比学习应用于VIF。此外,Luo等[82]提出了一种对比差分损失来执行特征解缠,从而最大限度地区分源图像的公共特征和私有特征。此方法可以应用于多个图像融合任务。 神经架构搜索。大多数研究人员专注于设计不同的架构来执行 VIF。这在很大程度上取决于研究人员的经验,可能需要很多时间。因此,自动学习架构是可取的。为此,Liu等[81]提出了SMoA,它利用神经架构搜索(NAS)来发现可见光和红外线图像的面向模态的特征表示。这种方法可以缓解手动设计架构的问题。据我们所知,这是第一种旨在自动搜索VIF网络架构的方法。同一团队在这个方向上做了进一步的研究。例如,他们在另一种VIF方法中提出了一种架构搜索方案[91]。具体来说,他们首先构建了一个分层聚合的融合架构,然后建立了一个可以搜索潜在架构的搜索空间。此外,他们还提出了一种基于NAS的轻量级架构[134]。在我们看来,这是一个很有前途的未来方向,因为它可以节省人工设计架构的人力,并有可能找到更好的架构。 图像或特征分解。有些方法直接融合整个源图像,而有些方法先将源图像分解成不同的部分,然后使用不同的策略融合这些不同的部分。例如,Liu等[46]将源图像分解为基础部分和细节部分。然后,他们使用加权求和方法融合了基础部分,同时使用 CNN 和多层特征融合策略融合了细节部分。除了图像分解外,一些方法还会执行特征分解。例如,Xu等[87]提出学习可见光和红外图像的解缠表示。具体来说,为可见光和红外图像学习了基于场景和属性相关的表示。然后,应用不同的融合策略分别融合基于场景的特征和属性相关的特征。融合图像是通过基于残差块和反卷积层的 CNN 获得的。与[87]不同,薛塔尔[107] 进行特征图分解以获得公共和唯一部分。然后,他们应用不同的融合规则来融合公共部分和独特部分。 照明感知模块。照明条件会显著影响可见光和红外图像的可靠性。因此,在图像融合过程中考虑照明条件非常重要。Tang等[110]提出了一个照明感知模块来评估照明条件,然后通过照明感知损失来指导图像融合过程。 其他类型的卷积。一些研究建议在VIF方法中使用其他类型的卷积,而不是常规卷积,因为这些卷积具有特殊性质。例如,Mustafa等[60]利用扩张卷积来增加感受野。 上述措施是基于深度学习的VIF方法中的重要构建块。在许多 VIF 方法中,其中一些措施已一起采用,以提高性能。例如,Li等[57]提出了一种基于DenseNet和注意力的VIF方法,Mustafa等[60]利用多尺度特征和残差连接来提高性能,Long等[83]提出了一种基于ResNet和DenseNet相结合的密集残差网络的VIF方法,Zou等[135]在他们的方法中采用了注意力和多尺度特征。 Shen等[136]在他们的方法中使用了注意力、残差连接和密集。 2)监督方法:尽管大多数基于CNN的方法都是无监督的,但也有一些监督方法,其整体架构如图6(b)所示。在基于CNN的监督方法中使用了几种类型的”真实标签”。 第一种类型是由其他方法生成的融合图像。例如,An等[58]提出了一种基于CNN的VIF方法,该方法由编码层、融合层、解码层和输出层组成。他们使用Zhang等人[4]提出的方法生成训练标签。第二种类型是其他图像融合任务的合成真值。例如,Liu等[29]使用高质量图像和使用多尺度高斯滤波和随机采样生成的模糊版本来训练他们的模型。此外,Feng等[56]提出了一种VIF方法,其全卷积网络也使用清晰的RGB图像及其模糊版本进行训练。此外,Wang等[47]使用清晰的RGB图像及其模糊版本来微调预训练的VGG和ResNet模型。Zhu等[112]使用可见光和红外图像生成合成训练数据。第三种类型是对象掩码。在 VIF 中,突出显示红外图像中更明显的目标非常重要。因此,一些方法试图借助对象掩码来提高融合性能。例如,马等[31]将VIF过程定义为可见光图像中的纹理信息与红外图像中的突出目标的融合。因此,他们在源图像中注释了目标掩码,并利用这些掩码帮助网络进行显著目标检测和信息融合。最近使用的第四种类型是下游应用的基本事实。例如,Tang等[108]在训练中使用了场景分割的地面实况。这种类型将在第四节中进一步讨论。 总之,监督方法可以具有与无监督方法相似的网络架构。然而,由于VIF任务中没有真正的真值融合图像,因此应使用不同类型的“真值”来补偿这一点并计算损失函数。此外,用于提高基于 CNN 的无监督 VIF 方法性能的措施也经常用于监督方法。 3)基于迁移学习的方法:基于CNN的方法的一部分基于迁移学习,其中在大规模数据集(如ImageNet)上预先训练的现成模型(通常由其他研究人员)用于提取特征。例如,Li等[43]和Zhang等[137]使用ResNet50从源图像的高频部分提取特征。Li等[30]和任等[41]使用VGG19提取特征。Yang等[84]使用VGG16,Li等[57]使用在ImageNet上预训练的DenseNet-201来提取深层特征。在一些研究中,这些特征在融合之前被处理。例如,Li等[43]应用零相位分量分析和l1范数对提取的特征进行归一化。 在这些基于迁移学习的方法中,通常手动设计融合规则来融合提取的特征。在图像重建方面,一些研究首先根据提取的特征生成权重图[43]或多个权重图[57]、[84],然后使用加权平均策略获得融合图像。或者,一些研究[30],[137]将融合的基底部分和细节部分结合起来,以获得融合图像。此外,任等[41]利用L-BFGS方法优化了基于提取的特征计算的损失函数。 2.5 基于自动编码器的 VIF 方法基于自动编码器 (AE) 的方法包括两个步骤。在第一步中,使用可见光图像和/或红外图像对自动编码器进行预训练,如图7(a)所示。第二步,使用训练好的编码器进行特征提取,训练好的解码器进行图像重建,如图7(b)所示。 编码器和解码器之间的融合通常根据手动融合规则进行,或者通过使用可见-红外图像对通过第二个训练步骤进行学习。请注意,基于 AE 的方法和基于迁移学习的方法之间的区别在于,自动编码器是在基于 AE 的方法中训练的,而现成的预训练模型直接用于基于迁移学习的方法。 一种著名的、开创性的基于AE的VIF方法是DenseFuse[42],它使用MS-COCO[138]来预训练AE和不同的融合策略(加法和l1范数)来执行特征融合。Raza等[55]还提出了一种基于AE的VIF方法,该方法使用基于权重图的融合策略。权重图是使用 l1-norm 和 softmax 基于提取特征获得的。此外,Fu等[72]提出了一种基于AE的方法,该方法在编码器中具有双分支。采用加法策略和信道选择策略进行特征融合。此外,Jian等[28]提出了SEDRFuse,它首先使用可见光和红外图像训练AE,以获得可以提取特征的编码器和可以重建融合图像的解码器。他们设计了一种基于注意力的特征融合策略来融合中间特征,并设计了一种选择最大策略来融合补偿特征。同样,Li等[51]提出使用基于空间注意力和通道注意力的融合策略来融合多尺度特征。Wang等[106]还提出了一种基于空间非局部注意力和通道非局部注意力的融合策略来处理远程信息。Zhao等[76]提出了一种略有不同的基于AE的方法,使用双尺度分解过程将源图像分解为基础部分和细节部分。加法策略用于融合来自两个源图像的基础部分(和细节部分)的分解特征图。然而,上述基于AE的方法的特征融合步骤是按照手动融合规则进行的,可能不是很有效。为了解决这个问题,Li等[73]最近提出了RFN-Nest,它利用通过使用可见光和红外图像对的训练学习的残差融合网络来执行特征融合。此外,他们还利用编码器中的多尺度功能和解码器中的嵌套连接来提高性能。类似地,Xu等[75]首先使用可见光和红外图像来训练自动编码器。然后,他们训练分类器以获得特征的分类显著性图,然后用于以像素级加权方式融合特征。最后使用解码器基于融合特征重建融合图像。 许多基于AE的方法[42]、[51]、[52]、[55]、[74]、[106]仅利用RGB图像来训练AE,并将训练好的AE直接应用于红外图像。因此,由于RGB和红外图像之间的差异,性能可能会受到限制。为了解决这个问题,一些方法[28]、[53]、[72]、[75]、[76]、[78]同时使用RGB和红外图像来训练AE,而一些方法[105]则使用RGB-红外图像对来训练编码器。此外,一些方法[79]训练可见光AE和红外AE。此外,在SFA-Fuse[77]中,在预训练阶段使用一个编码器和两个解码器来减轻重要信息的丢失。具体来说,两个解码器分别用于重建可见光图像和红外图像。此外,Liu等[81]提出使用两个编码器和一个统一解码器,其架构是使用NAS技术获得的。另一种方法是使用可见光-红外图像对来训练融合模块[73],[75]。最后,值得一提的是,2节中介绍的用于提高性能的措施也可以应用于基于AE的方法,例如多尺度特征[52],[80],多级特征[139],密集连接[79],[80],[140],注意力机制[80]和其他类型的卷积(深度卷积)[53],[78]。 2.6 基于 GAN 的 VIF 方法2019年,马等[32]将GAN引入图像融合。此后,许多基于GAN的VIF方法被提出,基于GAN的方法成为最重要的VIF方法类型之一。在本节中,我们将介绍具有代表性的基于GAN的VIF方法。 1)无监督方法:大多数基于GAN的VIF方法是无监督方法。训练通常由损失函数驱动,该函数将融合图像与源图像的差异进行比较。该损失函数通常包含多个项目,这些项目从不同角度反映差异。在本节中,我们根据生成器和鉴别器的数量来讨论这些方法,如图 8 所示。 Transformer 可以处理长距离依赖关系,并已应用于各种自然语言处理 [147] 和视觉任务 [148], [149]。2021年,Transformers被引入图像融合领域,并提出了一些基于Transformer的方法来执行VIF [35]、[37]、[117]、[118]、[119]、[120]、[150]、[151]、一般图像融合[34]、[36]、[121]、[152]等图像融合任务[153]、[154]、[155]、[156]。在某些方法中,transformer 仅用于执行特征融合。例如,VS等[34]提出使用基于Transformer 的多尺度融合策略来融合局部和全局信息。Zhao等[35]提出了DNDT,它使用双变压器作为融合策略。设计了一个编码器来从源图像中提取特征,一个解码器被设计用于构建融合图像。刘等[120] 提出了一种基于焦点自注意力的变压器融合块,以融合多尺度编码器提取的多尺度特征。融合图像是通过包含嵌套连接的解码器获得的。最近,Rao等[37]提出了一种基于变压器和GAN的VIF方法。具体来说,将空间变压器和通道变压器组合在一起,在transformer中形成变压器融合模块。此外,马等人提出了SwinFusion[121],这是一种基于swin变压器的通用图像融合方法。他们表明,整体信息在图像融合和可视化全球信息中至关重要。据我们所知,SwinFusion是第一个在图像融合背景下清楚地展示整体信息的研究。 在其他一些方法中,transformer也应用于VIF方法的其他阶段。例如,Fu等[36]提出了一种金字塔贴片变压器方法,该方法由基于变压器的特征提取模块和基于MLP的解码器组成。该方法被设计为一种基于 AE 的方法。平均策略用于融合。类似地,Wang等[119]在基于AE的框架中设计了SwinFuse,并使用基于转换器的编码器来提取全局特征。Tang等[118]提出了在编码分支和解码分支中结合CNN和transformer的YDTR。可见光图像和红外图像的特征相加。类似的方法是CGTF[117],它在编码分支和解码分支中都使用transformer特征提取模块和卷积特征提取模块。此外,Tang等[151]设计了一个基于Transtransformer的全局特征提取分支,该分支与基于CNN的局部特征提取分支平行。Yang等[150]使用一堆变压器块和卷积块从源图像生成融合图像。基于 Transformer 的方法的体系结构因方法而异。值得一提的是,现有的基于变压器的方法很少是纯粹基于变压器的。在图像融合过程中,CNN通常与变压器一起使用,如图9所示的示例架构。此外,所有现有的基于变压器的VIF方法都是无监督方法。因此,使用融合图像和源图像计算损失函数。 除了基于CNN的方法、基于AE的方法、基于GAN的方法和基于Transformer的方法外,还有一些其他基于深度学习的VIF方法。例如,Wu等[21]在2018年提出了一种基于DBM的VIF方法。然而,其他基于深度学习的VIF方法的数量非常有限。 3.一般图像融合方法上述大多数图像融合方法都是专门为VIF任务设计的。除了这些方法之外,研究人员还设计了可应用于多种图像融合任务的通用图像融合方法,即 VIF、MFIF、MEF 和 MEDIF。在一般的图像融合方法中,通常采用相同的模型来执行不同的融合任务。一般图像融合方法还包括基于CNN的方法[23]、[61]、[62]、[63]、基于AE的方法[82]、基于GAN的方法[71]、[157]、[158]和基于转换器的方法[34]、[36]、[121]。 有不同的方法可以实现一般的图像融合方法。首先,一些方法[62]、[136]在不同的图像融合任务中为损失项选择不同的权重。例如,Zhang等[93]利用压缩分解网络,手动调整强度损失的权重,以满足不同图像融合任务对强度分布的要求。其次,将不同的特征融合策略应用于不同的图像融合任务;Zhang等[23]提出的IFCNN就是一个例子,它对MEF使用elementwisemean策略,对VIF、MFIF和MEDIF使用elementwise-max策略。第三,一些研究人员[48]在其他计算机视觉任务(如图像分类)上使用预训练模型来提取各种图像融合任务的特征。此外,除了这些研究之外,还提出了其他通用图像融合方法[25],[64],[71]。请注意,一些通用的图像融合方法将训练数据用于一项任务,然后将训练后的模型应用于各种图像融合任务[23],[82]。相比之下,一些方法对每个图像融合任务使用不同的训练数据[63],[93],[121]。 一般的图像融合方法使用起来很方便,因为它们可以执行多个图像融合任务。一些方法还可以利用各种图像融合任务之间的共同特征。然而,不同的图像融合任务具有非常不同的特点,因此需要考虑不同的关键点才能获得良好的融合性能。例如,在 VIF 中,保留可见图像中的纹理细节和红外图像中的突出信息至关重要。在MFIF中,必须找到聚焦区域和散焦区域之间的边界,并正确处理散焦扩散效应(DSE)。在 MEF 中,去除光晕效应和重影效应至关重要。事实上,正如Zhang[123]所声称的那样,对于一般的图像融合方法来说,在单个模型中处理不同图像融合任务之间的这些关键差异是具有挑战性的。因此,一般的图像融合方法可能不比特定的VIF方法具有优越的性能。关于一般图像融合方法的更多详细信息可以在[123],[124]中找到。 4. 近期发展特点本节总结了近年来VIF领域的一些新特征。 4.1 越来越多的深度学习模型被应用于VIF当深度学习被引入 VIF 时,只有 DBM [21] 和 CNN [29]、[30]、[41] 被应用于执行 VIF。后来(2019年),GANs[32]和AE[42]被引入VIF,成为非常重要的VIF方法类型。2021年,变分自编码器[85]和变压器[35]、[36]、[37]也被引入该领域。此外,一些重要的网络架构,如DenseNet和ResNet,已被引入VIF并成为重要的构建块。我们相信,将引入越来越多的深度学习模型来执行VIF,以获得更好的融合性能。 4.2 大多数方法是无监督方法大多数基于深度学习的 VIF 方法都是无监督方法,因为 VIF 中没有地面实况图像。这与 MFIF 和 MEF 不同,在 MFIF 和 MEF 中,全清晰且曝光良好的图像可以用作合成数据集的地面实况。因此,在VIF中,研究人员非常重视基于融合图像和源图像设计各种损失函数。 4.3 深度学习与传统图像处理技术的结合在 VIF 方法中,深度学习和传统图像处理技术一起使用的情况并不少见。例如,Raza等[86]提出使用密集的多尺度网络和四叉树分解以及贝塞尔插值来提取不同的特征。一些方法还将GAN与传统的图像处理技术相结合。例如,在Wang等[26]的方法中,首先将源图像分解为基础层和细节层。然后,使用拉普拉斯金字塔方法融合基础层,而使用 GAN 融合细节层。此外,Yang等[33]提出了结合GAN和自适应引导滤波器(AGF)的TC-GAN。具体来说,该生成器旨在生成组合纹理贴图,该贴图被用作AGF的引导图像。通过将深度学习与传统图像处理技术相结合,它们的优势可以保留在VIF方法中。 4.4 VIF 与其他任务的结合以前,VIF 是几乎所有 VIF 研究的唯一目标。近年来,一些研究人员研究了将 VIF 与其他任务一起执行。例如,Gu等[159]提出了一种无数据集的自监督图像超分辨率融合方法,可以在单个网络中进行VIF和超分辨率。具体来说,可以将两个低分辨率源图像融合到一个高分辨率图像中。Li等[27]还提出了一种可以同时执行VIF和超分辨率的VIF方法。Xiao等[160]提出了一种同时进行VIF和超分辨率的知识蒸馏方法。通过将 VIF 和其他任务组合在一起,可以更有效地使用模型,因为一个模型可以执行更多任务。 4.5 同时学习图像融合和配准由于可见光和红外图像的成像机制不同,可见光和红外相机的参数不同,因此很难准确对准可见光-红外图像对。已经提出了许多方法来进行可见光-红外图像配准[161],[162],[163]。然而,几乎所有这些研究都没有考虑图像融合任务。为了解决这个问题,一些研究人员开始同时学习图像融合和配准[111],[164]。例如,Wang等[111]首先使用跨模态感知风格迁移网络生成伪红外图像。然后,他们学习真实红外图像和伪红外图像之间的位移矢量场,这是一个更容易的单模态配准问题。然后,利用学习到的位移矢量场重建配准的真实红外图像。最后,他们通过双路径交互融合网络,利用可见光图像和配准红外图像进行图像融合。设计了一种由样式传递损失、交叉正则化损失、配准损失和图像融合损失组成的损失函数来指导模型训练。此外,Xu等[164]提出了RFNet,这是一个相互强化的框架,可以一起学习融合和注册。具体来说,RFNet利用图像融合为图像配准提供反馈。然而,尽管这个想法很鼓舞人心,但RFNet是为配准可见光图像和近红外图像而不是热红外图像而设计的。 4.6 不同分辨率图像的VIF方法大多数现有的VIF方法旨在融合相同分辨率的可见光和红外图像。然而,在实践中,高分辨率可见光图像和低分辨率红外图像更为常见。最近,一些研究人员开始开发融合不同分辨率图像的方法。例如,Xu等[49]提出了一种融合高分辨率可见光图像和低分辨率红外图像的方法。这是通过首先使用两个上采样层对红外图像进行上采样,然后采用鉴别器来区分原始红外图像和下采样融合图像来实现的。马等人[71]随后扩展了这种方法。具体来说,反卷积层用于学习从低分辨率特征到高分辨率特征的映射,用于替换两个上采样层。通过这种方式,参数是从训练中获得的,而不是预定义的。但是,这两种方法对源图像的输入大小都有要求,即可见光图像与红外图像的分辨率之比应为4。 最近,Li等[27]提出了一种基于元学习的VIF方法,该方法可以将不同分辨率的源图像融合为任意分辨率的融合图像。Liu等[165]也提出了融合不同分辨率的源图像。他们设计了上投影和下投影模块,以实现不同分辨率图像之间的特征映射。该方法已被用于融合可见光和红外图像以及多分辨率医学图像。 4.7 基准研究与计算机视觉中的许多任务不同,图像融合长期以来一直缺乏基准。直到最近,一些研究人员才开始在图像融合领域创建基准[124],[166]。关于VIF,Zhang等[167]提出了第一个可见-红外图像融合基准(VIFB),该基准由21个可见-红外图像对的测试集、一个由20种VIF方法组成的代码库和13个评估指标组成。许多VIF研究[143]、[159]、[168]、[169]、[170]、[171]、[172]、[173]、[174]已采用VIFB。 4.8 面向应用的 VIF 方法大多数现有的 VIF 方法没有考虑图像融合过程中的下游应用,如图 10(a) 所示。因此,在图像融合过程中学习和融合的特征是一般特征,这可能会导致视觉上令人愉悦的融合图像,但对于下游应用来说可能不是最佳选择。 在过去的三年中,一个非常重要的特征是开发面向应用的VIF方法。这与大多数现有的VIF研究有很大不同,这些研究没有考虑图像融合过程中的下游应用。据我们所知,Shopovska等[44]是最早考虑VIF下游应用的研究之一。具体而言,在损失函数中采用了辅助行人检测误差来帮助定义人类外观的相关特征。这项工作的主要重点是提高人类观察者在融合图像中行人的可见性。最近,Tang等[108]提出了SeAFusion,该方法考虑了图像融合过程中的场景分割。Liu等[115]在双层优化公式中阐述了图像融合和目标检测,并提出了一种联合训练策略,将融合模型和检测模型一起训练。Peng等[139]在损失函数中也使用了图像融合损失项和目标检测项。与大多数VIF方法相比,这些方法通过在损失函数中包含基于应用的项来直接考虑融合过程中下游应用的性能,如图10(b)所示。因此,这些方法可以提供更适合特定应用的融合图像。 4.9 损失函数中的不同项基于深度学习的VIF方法的一个共同特点是损失函数中通常包含不同的项。其主要原因是由于没有基本事实,因此聚变质量在很大程度上取决于损失函数。因此,研究人员必须设计自己的损失函数来指导模型训练。在设计损失函数时,一种直接的方法是根据图像融合评估指标设计损失函数。事实上,几乎所有基于深度学习的VIF方法都包含根据图像融合评估指标设计的损耗项。请注意,大多数基于深度学习的VIF方法的损失函数仅考虑图像融合性能。因此,我们将这种损失函数称为VIF损失,如图10(a)所示。然而,正如Zhang等[167]所证明的那样,VIF方法在不同类型的图像融合评估指标方面可能具有非常不同的性能,例如基于结构的指标和基于信息理论的指标。因此,基于单一指标的 VIF 损失不足以训练良好的 VIF 方法。因此,研究人员开始在VIF损失中加入不同的术语。通常,其中一些术语对应于不同类型的评估指标。例如,Li等[117]使用强度损失项和结构相似性指数测量(SSIM)损失项,Tang等[118]使用空间频率(SF)损失项和SSIM损失项,Cheng等[175]使用SSIM损失项、基于梯度的损失项和均方误差(MSE)损失项。 此外,如第4节所述,除了VIF损失外,研究人员还开始在损失函数中加入基于应用的项。我们将这些术语称为应用程序损失,如图 10(b) 所示。例如,Shopovska等[44]和Liu等[115]在损失函数中增加了目标检测损失项,Tang等[108]在损失函数中增加了语义分割损失项。综上所述,现有的大多数VIF方法仅使用VIF损耗。然而,一种更有前途的方法是同时使用VIF损失和应用程序损失。值得一提的是,应用损耗通常是在网络输出和应用的地面实况之间计算的。相比之下,VIF 损耗通常在融合图像和源图像或伪真实值之间计算。 4.10 可以直接融合彩色图像的方法大多数 VIF 方法只能融合灰度图像。为了融合彩色图像,这些方法首先将RGB图像转换为YCbCr空间,然后将Y通道与红外图像融合[91],[116],[118],[121]。然后应用反向色彩空间变换以获得颜色融合图像。但是,这个过程很复杂。此外,大多数方法仅使用深度学习方法融合 Y 通道,而融合 Cr 和Cb 通道使用常规方法(例如手动方法)。这可能会导致信息丢失,因为 Cb 和 Cr 通道也包含重要信息。最近,研究人员提出了一些VIF方法[25],可以直接融合可见光和红外图像,我们认为这是一个重要的发展特征和前景广阔的未来趋势。 4.11 编程框架我们回顾了图 2 中所示的所有基于深度学习的 VIF 方法,以检查所使用的编程框架。图 11 显示了每年使用的编程框架。可以看出,在 2021 年之前,使用 Tensorflow 的方法数量迅速增加,并在 2022 年开始减少。相比之下,使用 Pytorch 的方法数量增长非常快,这表明 Pytorch 已成为基于深度学习的 VIF 方法中使用的最流行的编程框架。从 2018 年到 2022 年,使用 Matlab 的方法数量略有增加。 5. 数据集 5.1 基于深度学习的方法的训练数据VIF 任务中不存在地面实况。因此,开发有监督的VIF方法并不简单。这反映在表I中,其中大多数基于深度学习的VIF方法是无监督方法。然而,研究人员已经尝试了各种方法来生成伪“地面真相”或使用其他形式的标签来执行监督训练。在本节中,我们将讨论监督方法和无监督方法的训练数据。 1)监督方法的训练数据:在本节中,我们总结了所有类型的监督方法为生成训练数据而采取的措施。 第一种方法是使用其他方法生成的融合图像作为地面实况。例如,Li等[24]使用GFF[146]生成标签。Lebedev等[22]使用拉普拉斯金字塔算法和MultiScale Retinex[144]生成了地面实况图像。然而,这种方法可能会为学习设定上限[101]。 第二种方法是使用全清晰图像及其模糊版本。典型的例子是[23]、[29]、[47]、[56]、[82],其中使用 RGB 图像及其模糊版本。最近,Zhu等[112]为RGB和红外图像生成了模糊版本。然而,以这种方式生成的训练数据不是很逼真,并且与真实的可见-红外图像对不同。 第三种方法是对现有 VIF 数据集使用手动标记的对象掩码。例如,一些研究人员[31]、[94]、[95]、[96]使用掩码来帮助融合图像保持语义信息。但是,获得这些口罩是劳动密集型的,而且不方便。 第四种方式是使用下游应用的标签。这样,没有基本实况的 VIF 任务将转换为对损失函数的一部分具有基本实况的任务。例如,Shopovska等[44]利用预先训练的行人检测器生成行人标签,然后使用这些标签构建辅助检测损失以执行检测引导训练。Tang等[108]将场景分割作为下游任务,并利用损失函数中的分割损失项来指导训练。场景分割标签由场景分割数据集的作者手动标记。另一个例子是Liu等[115]使用通用目标检测作为下游任务,并在损失函数中增加了一个目标检测损失项。该作品中提供了对象检测标签。 最后一种方法是使用YCbCr空间中RGB图像的Y通道作为地面实况,并生成合成的红外和可见光图像进行训练[102]。 2)无监督方法的训练数据:无监督VIF方法中有几种类型的训练数据。第一种类型是可见光-红外图像对[37]、[75]、[143]。第二种是可见光和红外图像,但它们不一定是成对的。一些基于AE的方法[28]、[53]、[72]、[76]、[78]使用这种训练数据。第三种是全透明可见光图像,主要用于基于AE的方法。例如,Li等[42]使用MS-COCO数据集来训练编码器和解码器。第四种类型是可见光图像加上可见光-红外图像对。在这种情况下,可见光图像和可见光-红外图像对用于训练模型的不同模块。例如,Jian等[90]使用可见光图像来训练图像分解模块,使用可见光-红外图像对来训练堆叠稀疏自编码器,用于局部显著性图提取。另一个例子是RFN-Nest方法[73]。处理训练数据缺失的第五种方法是迁移学习,即使用使用大规模 RGB 数据集训练的预训练模型,如第2 节所述。 我们在补充材料中总结了有监督和无监督方法的训练数据生成的主要方法,这些方法可以在计算机学会数字图书馆上找到,网址为 http://doi.ieeecomputersociety.org/10.1109/ TPAMI.2023.3261282。 5.2 测试集一些VIF数据集,包括TNO [176]、INO[177]、MFNet [178]、RoadScene [61]、VIFB[167]、LLVIP[179]和M3FD [115],已被用于VIF任务中作为评估图像融合性能的测试集。这些数据集的信息在现有的补充材料中进行了在线总结。值得一提的是,一些研究也使用这些数据集作为训练数据。一般来说,VIF 字段没有完善的测试集,如表 II 所示。这与计算机视觉中的许多其他任务不同,例如对象跟踪和检测。 5.3 包含可见红外图像的其他数据集除了上面提到的VIF数据集外,其他一些数据集还包含可见光和红外图像。例如,CVC-14 [180] 和 FLIR [181] 为驾驶场景提供可见光-红外图像对。但是,这些数据集中的图像未对齐。GTOT [182]、RGBT234 [9]和LasHeR [183]主要用于RGBT跟踪。它们提供了大量的可见-红外图像对。然而,这些数据集中可见光-红外图像的对齐不是很准确。此外,多光谱KAIST[184]是一个多光谱数据集,主要用于多光谱行人检测。此外,OSU数据集[185]是VIF中使用的较早数据集。 6. 表现评估方法本节总结了 VIF 中使用的性能评估方法。由于缺乏真实情况,对VIF方法进行性能评估并非易事。一般而言,现有研究采用视觉性能定性评价和基于图像融合评价指标的定量评价。 6.1 定性评估定性评估是指手动和目视检查融合图像的质量。通常,融合图像应包含可见图像的纹理细节和红外图像的显着特征。定性评价对于VIF方法的性能评估至关重要,几乎所有VIF论文都选择了定性评价。然而,定性评估不是自动的,因此很耗时。此外,手动检查所有融合图像是不可行的,尤其是在生成大量融合图像时。在现有文献中,一种常见的方法是选择几个例子进行比较。这可能导致采样偏差[186],这是图像增强任务中的常见问题。此外,不同的观察者在检查融合图像时可能有不同的标准。导致主观偏差[186]。据我们所知,目前还没有很好的解决方案来解决这些问题。 6.2 定量评价定量评价是指使用图像融合评价指标来检查融合图像的质量。已经提出了许多评估指标,如交叉熵(CE)[187]、空间频率(SF)[188]和归一化互信息(NMI)[189]。然而,在大多数VIF研究中,没有一个公认的指标被使用。此外,每个指标通常从一个方面或非常有限的方面部分评估融合图像的质量。这导致了一个重大问题,即不同的VIF研究可能使用不同的指标,如表II所示。此外,在现有的VIF文献中,也使用了不同的测试集。因此,很难公平地比较VIF方法的性能。 最近,Zhang等[167]提出了第一个VIF基准(VIFB),可用于对VIF方法进行全面的性能比较。VIFB 包含 21 个可见-红外图像对、20 种 VIF 方法和 13 个评估指标。所有融合结果均公开提供。VIFB是开发更好的方法来评估图像融合方法的重要一步。 VIF方法的性能评估是一个活跃的话题。一些研究人员正在努力提出更好的评估指标或评估方法。有关评估指标的更多详细信息,请参见 [19]、[123]、[191]。 7.未来前景在本节中,我们将讨论 VIF 的未来前景。 7.1 更好的评估指标VIF 方法是通过现有论文中使用视觉性能的定性比较和使用图像融合评估指标的定量比较来评估的。然而,如表II所示,不同论文中普遍选择不同的指标和测试图像,这使得公平性能比较变得困难。此外,一个指标通常只从某些方面评估融合结果[167]。此外,定性结果通常与图像融合领域的定量结果不一致[167],[192]。因此,最好有更好的指标。理想的指标应与视觉性能一致,并全面反映融合性能。 7.2 更好的基准尽管Zhang等[167]开发了VIF基准,但对VIF基准的研究仍处于早期阶段。我们选择了五种最新的基于深度学习的方法(IFCNN [23]、SeAFusion [108]、SwinFusion [121]、U2Fusion [63] 和 YDTR [118]),这些方法可以代表 VIF 领域的最新发展,并在 VIFB [167] 上测试了它们的性能。在这些方法,IFCNN 和 U2Fusion 是基于 CNN 的通用图像融合方法,SeAFusion 是一种应用驱动的 VIF 方法,SwinFusion 是一种基于 transformer 的通用图像融合方法,YDTR 是一种基于 transformer 的 VIF 方法。定量结果见表三。由于页数限制,我们将定性结果放在补充材料中,可在线获取。我们从VIFB的结果中得出了一些观察结果。首先,最新的基于深度学习的方法在VIFB上没有显示出比旧的基于深度学习的方法的优势。例如,2022 年发表的三种方法,即 SeAFusion、SwinFusion 和 YDTR,在 VIFB 上的定量性能比 CNN 和 DLF 差。其次,一些传统的VIF方法,即LatLRR、LP_SR和NSCT_SR,与基于深度学习的方法相比,在定量性能上具有很强的竞争力,表明基于深度学习的方法在VIFB上没有表现出优势性能。第三,很难从定性比较中得出哪种方法更好的结论。具体来说,最新的基于深度学习的方法在某些情况下显示出良好的融合性能,但在其他情况下则表现不佳。一些传统的VIF方法也显示出非常有竞争力的定性性能。最后,定量性能与定性性能不是很一致,这是图像融合领域的常见问题。请注意,这些观察结果基于VIFB[167]。如果使用一组不同的测试图像和评估指标,可能会获得不同的观察结果。 VIFB 是开发 VIF 基准的初步努力。它有一些局限性,例如测试图像的数量少且分辨率低。需要付出更多的努力来制定更好的基准,以更好地比较VIF方法。例如,未来的基准测试可能包含更多的测试图像、更多样化的场景以及更好的高质量评估指标组合。 7.3 基于 Transformer 的方法Transformer 在许多计算机视觉任务中都取得了出色的性能。然而,正如第II-G节所介绍的,变压器在VIF中的应用还处于非常早期的阶段。我们预计未来几年将出现许多基于变压器的VIF方法。特别是,开发纯基于变压器的VIF方法很有趣。此外,在VIF的上下文中证明什么是全局信息至关重要,这在现有的基于变压器的VIF方法中很少得到解释。 7.4 面向应用的图像融合方法使用 VIF 的动机之一是提高下游应用程序的性能。然而,从我们的综述中可以看出,大多数现有的VIF方法都没有考虑下游应用。这也可以从性能评估方法中观察到,即使用视觉性能的定性比较和使用图像融合指标的定量比较。然而,以这种方式设计的VIF方法可以学习一般特征和融合规则,而这些特征和融合规则可能无法针对下游应用进行优化。因此,在VIF方法的设计中最好考虑下游应用。图 10(b) 显示了一个可能的框架,其中 VIF 损失和应用程序损失都用于指导训练。我们预计面向应用的图像融合方法将成为该领域的主流方法。 7.5 更多应用VIF有可能提高许多应用的性能,特别是那些需要在各种照明条件下工作的应用。然而,VIF主要应用于目标跟踪[7]、[193]、目标检测[14]、[115]、显著性目标检测[31]、[194]和场景分割[108]、[195]。许多其他应用,如人员救援[196]和机器人技术[197],都具有很大的价值,但很少被研究。我们认为未来应该探索VIF的更多应用。 7.6 错位的处理可见光和红外图像的错位可能会降低应用的性能,例如行人检测[198]。因此,处理融合的错位非常重要。这也将有助于促进VIF方法的应用。然而,尽管已经进行了许多研究来处理可见光和红外图像的错位,但对准仍然是一个悬而未决的问题,完美对齐可见光和红外图像非常具有挑战性。事实上,几乎所有现有的RGB红外数据集,如LasHeR [183]、RGBT234 [9]和M3FD [115],都存在一些错位问题。正如最近的两项研究[111]和[164]所探讨的那样,深度学习可能为这个问题提供潜在的解决方案,这些研究同时学习图像融合和配准。同样值得研究的是图像融合、配准和下游应用,正如Tang等[199]所做的那样。我们预计未来会提出更多基于深度学习的配准方法来解决错位问题。 7.7 将 VIF 与其他任务相结合在大多数 VIF 研究中,只考虑了可见光和红外图像融合。最近,一些研究人员一起执行了VIF和其他任务,这可能更有效和高效。例如,Li等[27]和Gu等[159]将VIF与图像超分辨率相结合。然而,关于VIF与其他任务相结合的研究仍然非常有限。我们预计未来几年将沿着这个方向提出更多的研究,以进一步探索VIF和其他任务的互惠互利。 7.8 提高融合效率随着基于深度学习的 VIF 方法的发展,研究人员设计了更大、更深的模型来执行 VIF。然而,较大的模型使 VIF 方法效率不够高,这阻碍了 VIF 方法在实际应用中的价值,例如目标跟踪和检测。一些研究人员[200]已经注意到了这一点,并试图设计有效的深度VIF方法。然而,这些研究仍然非常有限。设计高效的VIF方法将是VIF未来的重要趋势。 8. 总结本文详细综述了基于深度学习的可见光和红外图像融合(VIF)方法。从综述中可以看出,自2018年以来,每年都有越来越多的基于深度学习的VIF方法被开发出来,各种深度学习技术被应用于VIF。我们仔细地对现有方法进行了分组,并介绍了代表方法。我们也讨论了现在这个领域的发展特点。此外,我们总结了VIF数据集,包括测试数据和训练数据,以及性能评估方法。基于这些回顾和分析,我们通过分析我们认为应该引起更多关注的几个重要问题来讨论VIF的未来前景。我们希望这项研究能为该领域的研究人员提供合适的参考。 参考文献[1] A. Toet, L. J. Van Ruyven, and J. M. Valeton, “Merging thermal and visual images by a contrast pyramid,” Opt. Eng., vol. 28, no. 7, pp. 789–792, 1989.[2] Y. Liu, S. Liu, and Z. Wang, “A general framework for image fusion based on multi-scale transform and sparse representation,” Inf. Fusion, vol. 24, pp. 147–164, 2015.[3] J. Ma, C. Chen, C. Li, and J. Huang, “Infrared and visible image fusion via gradient transfer and total variation minimization,” Inf. Fusion, vol. 31, pp. 100–109, 2016.[4] Y. Zhang, L. Zhang, X. Bai, and L. Zhang, “Infrared and visual image fusion through infrared feature extraction and visual information preservation,” Infrared Phys. Technol., vol. 83, pp. 227–237, 2017.[5] H. Li, X.-J. Wu, and J. Kittler, “MDLatLRR: A novel decomposition method for infrared and visible image fusion,” IEEE Trans. Image Process, vol. 29, pp. 4733–4746, 2020.[6] J. Ma et al., “Infrared and visible image fusion via detail preserving adversarial learning,” Inf. Fusion, vol. 54, pp. 85–98, 2020.[7] X. Zhang, G. Xiao, P. Ye, D. Qiao, J. Zhao, and S. Peng, “Object fusion tracking based on visible and infrared images using fully convolutional siamese networks,” in Proc. IEEE 22nd Int. Conf. Inf. Fusion, 2019, pp. 1–8.[8] X. Zhang et al., “DSiamMFT: An RGB-T fusion tracking method via dynamic Siamese networks using multi-layer feature fusion,” Signal Process. Image Commun., vol. 84, 2020, Art. no. 115756.[9] C. Li et al., “RGB-T object tracking: Benchmark and baseline,” Pattern Recognit., vol. 96, 2019, Art. no. 106977.[10] V. Chandrakanth, M. V., and S. Channappayya, “Siamese cross domain tracker design for seamless tracking of targets in RGB and thermal videos,” IEEE Trans. Artif. Intell., vol. 4, no. 1, pp. 161–172, Feb. 2023.[11] P. Zhang, J. Zhao, D. Wang, H. Lu, and X. Ruan, “Visible-thermal UAV tracking: A large-scale benchmark and new baseline,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 8886–8895.[12] Y. Yan et al., “Cognitive fusion of thermal and visible imagery for effective detection and tracking of pedestrians in videos,” Cogn. Comput., vol. 10, no. 1, pp. 94–104, 2018.[13] R. Lahmyed, M. El Ansari, and A. Ellahyani, “A new thermal infrared and visible spectrum images-based pedestrian detection system,” Multimedia Tools Appl., vol. 78, no. 12, pp. 15 861–15 885, 2019.[14] H. Sun et al., “Fusion of infrared and visible images for remote detection of low-altitude slow-speed small targets,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 2971–2983, 2021.[15] H. Zhou et al., “Visible-thermal image object detection via the combination of illumination conditions and temperature information,” Remote Sens., vol. 13, no. 18, 2021, Art. no. 3656.[16] S. G. Kong et al., “Recent advances in visual and infrared face recognition - A review,” Comput. Vis. Image Understanding, vol. 97, no. 1, pp. 103–135, 2005.[17] S. Ariffin, N. Jamil, and P. Rahman, “Can thermal and visible image fusion improves ear recognition?,” in Proc. 8th Int. Conf. Inf. Technol., 2017, pp. 780–784.[18] D. P. Bavirisetti et al., “Multi-scale guided image and video fusion: A fast and efficient approach,” Circuits, Syst. Signal Process., vol. 38, no. 12, pp. 5576–5605, 2019.[19] J. Ma, Y. Ma, and C. Li, “Infrared and visible image fusion methods and applications: A survey,” Inf. Fusion, vol. 45, pp. 153–178, 2019.[20] Y. Liu et al., “Deep learning for pixel-level image fusion: Recent advances and future prospects,” Inf. Fusion, vol. 42, pp. 158–173, 2018.[21] W. Wu et al., “Visible and infrared image fusion using NSST and deep Boltzmann machine,” Optik, vol. 157, pp. 334–342, 2018.[22] M. Lebedev, D. Komarov, O. Vygolov, and Y. V. Vizilter, “Multisensor image fusion based on generative adversarial networks,” in Image and Signal Processing for Remote Sensing XXV, vol. 11155. Bellingham, WA, USA: SPIE, 2019, pp. 565–574.[23] Y. Zhang et al., “IFCNN: A general image fusion framework based on convolutional neural network,” Inf. Fusion, vol. 54, pp. 99–118, 2020.[24] Q. Li et al., “Coupled GAN with relativistic discriminators for infrared and visible images fusion,” IEEE Sensors J., vol. 21, no. 6, pp. 7458–7467, Mar. 2021.[25] H. Jung, Y. Kim, H. Jang, N. Ha, and K. Sohn, “Unsupervised deep image fusion with structure tensor representations,” IEEE Trans. Image Process, vol. 29, pp. 3845–3858, 2020.[26] J. Wang et al., “Infrared and visible image fusion based on Laplacian pyramid and generative adversarial network,” KSII Trans. Internet Inf. Syst., vol. 15, no. 5, pp. 1761–1777, 2021.[27] H. Li, Y. Cen, Y. Liu, X. Chen, and Z. Yu, “Different input resolutions and arbitrary output resolution: A meta learning-based deep framework for infrared and visible image fusion,” IEEE Trans. Image Process, vol. 30, pp. 4070–4083, 2021.[28] L. Jian, X. Yang, Z. Liu, G. Jeon, M. Gao, and D. Chisholm, “SEDRFuse: A symmetric encoder-decoder with residual block network for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–15, 2021.[29] Y. Liu et al., “Infrared and visible image fusion with convolutional neural networks,” Int. J. Wavelets, Multiresolution Inf. Process., vol. 16, no. 03, 2018, Art. no. 1850018.[30] H. Li, X.-J. Wu, and J. Kittler, “Infrared and visible image fusion using a deep learning framework,” in Proc. 24th Int. Conf. Pattern Recognit., 2018, pp. 2705–2710.[31] J. Ma, L. Tang, M. Xu, H. Zhang, and G. Xiao, “STDFusionNet: An infrared and visible image fusion network based on salient target detection,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–13, 2021.[32] J. Ma et al., “FusionGAN: A generative adversarial network for infrared and visible image fusion,” Inf. Fusion, vol. 48, pp. 11–26, 2019.[33] Y. Yang, J. Liu, S. Huang, W. Wan, W. Wen, and J. Guan, “Infrared and visible image fusion via texture conditional generative adversarial network,” IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 12, pp. 4771–4783, Dec. 2021.[34] V. Vs, J. Valanarasu, P. Oza, and V. M. Patel, “Image fusion transformer,” in Proc. IEEE Int. Conf. Image Process., 2022, pp. 3566–3570.[35] H. Zhao and R. Nie, “DNDT: Infrared and visible image fusion via DenseNet and dual-transformer,” in Proc. IEEE Int. Conf. Inf. Technol. Biomed. Eng., 2021, pp. 71–75.[36] Y. Fu, T. Xu, X. Wu, and J. Kittler, “PPT Fusion: Pyramid patch transformer for a case study in image fusion,” 2021, arXiv:2107.13967.[37] D. Rao, X.-J. Wu, and T. Xu, “TGFuse: An infrared and visible image fusion approach based on transformer and generative adversarial network,” 2022, arXiv:2201.10147.[38] X. Zhang et al., “Object fusion tracking based on visible and infrared images: A comprehensive review,” Inf. Fusion, vol. 63, pp. 166–187, 2020.[39] C. Sun, C. Zhang, and N. Xiong, “Infrared and visible image fusion techniques based on deep learning: A review,” Electronics, vol. 9, no. 12, 2020, Art. no. 2162.[40] H. Zhang et al., “Image fusion meets deep learning: A survey and perspective,” Inf. Fusion, vol. 76, pp. 323–336, 2021.[41] X. Ren et al., “Infrared-visible image fusion based on convolutional neural networks,” in Proc. Int. Conf. Intell. Sci. Big Data Eng., Springer, 2018, pp. 301–307.[42] H. Li and X. Wu, “DenseFuse: A fusion approach to infrared and visible images,” IEEE Trans. Image Process, vol. 28, no. 5, pp. 2614–2623, May 2019.[43] H. Li, X.-J. Wu, and T. S. Durrani, “Infrared and visible image fusion with ResNet and zero-phase component analysis,” Infrared Phys. Technol., vol. 102, 2019, Art. no. 103039.[44] I. Shopovska, L. Jovanov, and W. Philips, “Deep visible and thermal image fusion for enhanced pedestrian visibility,” Sensors, vol. 19, no. 17, 2019, Art. no. 3727.[45] Y. Cui, H. Du, and W. Mei, “Infrared and visible image fusion using detail enhanced channel attention network,” IEEE Access, vol. 7, pp. 182 185–182 197, 2019.[46] Y. Liu et al., “Infrared and visible image fusion through details preservation,” Sensors, vol. 19, no. 20, 2019, Art. no. 4556.[47] M. Wang, X. Liu, and H. Jin, “A generative image fusion approach based on supervised deep convolution network driven by weighted gradient flow,” Image Vis. Comput., vol. 86, pp. 1–16, 2019.[48] F. Lahoud and S. Süsstrunk, “Fast and efficient zero-learning image fusion,” 2019, arXiv: 1905.03590.[49] H. Xu et al., “Learning a generative model for fusing infrared and visible images via conditional generative adversarial network with dual discriminators,” in Proc. Int. Joint Conf. Artif. Intell., 2019, pp. 3954–3960.[50] J. Li, H. Huo, K. Liu, C. Li, S. Li, and X. Yang, “Infrared and visible image fusion via multi-discriminators wasserstein generative adversarial network,” in Proc. IEEE 18th Int. Conf. Mach. Learn. Appl., 2019, pp. 2014–2019.[51] H. Li, X.-J. Wu, and T. Durrani, “NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models,” IEEE Trans. Instrum. Meas., vol. 69, no. 12, pp. 9645–9656, Dec. 2020.[52] J. Zhu et al., “Multiscale channel attention network for infrared and visible image fusion,” Concurrency Comput. Pract. Experience, vol. 33, 2021, Art. no. e6155.[53] H. Patel et al., “An approach for fusion of thermal and visible images,” in Proc. Int. Conf. Emerg. Technol. Trends Electron. Commun. Netw., Springer, 2020, pp. 225–234.[54] Z. Zhao et al., “DIDFuse: Deep image decomposition for infrared and visible image fusion,” in Proc. Int. Joint Conf. Artif. Intell., 2020, pp. 970–976.[55] A. Raza, H. Hong, and T. Fang, “PFAF-Net: Pyramid feature network for multimodal fusion,” IEEE Sens. Lett., vol. 4, no. 12, pp. 1–4, Dec. 2020.[56] Y. Feng et al., “Fully convolutional network-based infrared and visible image fusion,” Multimedia Tools Appl., vol. 79, no. 21, pp. 15 001–15 014, 2020.[57] Y. Li et al., “Unsupervised densely attention network for infrared and visible image fusion,” Multimedia Tools Appl., vol. 79, no. 45, pp. 34 685–34 696, 2020.[58] W.-B. An and H.-M. Wang, “Infrared and visible image fusion with supervised convolutional neural network,” Optik, vol. 219, 2020, Art. no. 165120.[59] R. Hou et al., “VIF-Net: An unsupervised framework for infrared and visible image fusion,” IEEE Trans. Comput. Imag., vol. 6, pp. 640–651, 2020.[60] H. T. Mustafa et al., “Infrared and visible image fusion based on dilated residual attention network,” Optik, vol. 224, 2020, Art. no. 165409.[61] H. Xu et al., “FusionDN: A unified densely connected network for image fusion,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 12484–12491.[62] H. Zhang et al., “Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 12797–12804.[63] H. Xu, J. Ma, J. Jiang, X. Guo, and H. Ling, “U2Fusion: A unified unsupervised image fusion network,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 1, pp. 502–518, Jan. 2022.[64] F. Zhao and W. Zhao, “Learning specific and general realm feature representations for image fusion,” IEEE Trans. Multimedia, vol. 23, pp. 2745–2756, 2021.[65] D. Xu et al., “Infrared and visible image fusion with a generative adversarial network and a residual network,” Appl. Sci., vol. 10, no. 2, 2020, Art. no. 554.[66] J. Li, H. Huo, C. Li, R. Wang, and Q. Feng, “AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks,” IEEE Trans. Multimedia, vol. 23, pp. 1383–1396, 2021.[67] J. Li et al., “Infrared and visible image fusion using dual discriminators generative adversarial networks with wasserstein distance,” Inf. Sci., vol. 529, pp. 28–41, 2020.[68] J. Xu et al., “LBP-BEGAN: A generative adversarial network architecture for infrared and visible image fusion,” Infrared Phys. Technol., vol. 104, 2020, Art. no. 103144.[69] C. Yuan et al., “FLGC-Fusion GAN: An enhanced fusion GAN model by importing fully learnable group convolution,” Math. Problems Eng., vol. 2020, pp. 1–13, 2020.[70] Y. Zhao, G. Fu, H. Wang, and S. Zhang, “The fusion of unmatched infrared and visible images based on generative adversarial networks,” Math. Problems Eng., vol. 2020, pp. 1–12, 2020.[71] J. Ma, H. Xu, J. Jiang, X. Mei, and X.-P. Zhang, “DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion,” IEEE Trans. Image Process, vol. 29, pp. 4980–4995, 2020.[72] Y. Fu and X.-J. Wu, “A dual-branch network for infrared and visible image fusion,” in Proc. IEEE 25th Int. Conf. Pattern Recognit., 2021, pp. 10 675–10 680.[73] H. Li, X.-J. Wu, and J. Kittler, “RFN-Nest: An end-to-end residual fusion network for infrared and visible images,” Inf. Fusion, vol. 73, pp. 72–86, 2021.[74] Y. Fu, X.-J. Wu, and J. Kittler, “Effective method for fusing infrared and visible images,” J. Electron. Imag., vol. 30, no. 3, 2021, Art. no. 033013.[75] H. Xu, H. Zhang, and J. Ma, “Classification saliency-based rule for visible and infrared image fusion,” IEEE Trans. Comput. Imag.,vol.7, pp. 824–836, 2021.[76] Z. Zhao, S. Xu, J. Zhang, C. Liang, C. Zhang, and J. Liu, “Efficient and model-based infrared and visible image fusion via algorithm unrolling,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 3, pp. 1186–1196, Mar. 2022.[77] F. Zhao, W. Zhao, L. Yao, and Y. Liu, “Self-supervised feature adaption for infrared and visible image fusion,” Inf. Fusion, vol. 76, pp. 189–203, 2021.[78] H. Patel and K. P. Upla, “DepthFuseNet: An approach for fusion of thermal and visible images using a convolutional neural network,” Opt. Eng., vol. 60, no. 1, 2021, Art. no. 013104.[79] Y. Pan et al., “DenseNetFuse: A study of deep unsupervised DenseNet to infrared and visual image fusion,” J. Ambient Intell. Humanized Comput., vol. 12, pp. 10339–10351, 2021.[80] Z. Wang, J. Wang, Y. Wu, J. Xu, and X. Zhang, “UNFusion: A unified multi-scale densely connected network for infrared and visible image fusion,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 6, pp. 3360–3374, Jun. 2022.[81] J. Liu, Y. Wu, Z. Huang, R. Liu, and X. Fan, “SMoA: Searching a modality-oriented architecture for infrared and visible image fusion,” IEEE Signal Process. Lett., vol. 28, pp. 1818–1822, 2021.[82] X. Luo, Y. Gao, A. Wang, Z. Zhang, and X. -J. Wu, “IFSepR: A general framework for image fusion based on separate representation learning,” IEEE Trans. Multimedia, vol. 25, pp. 608–623, 2023.[83] Y. Long et al., “RXDNFuse: A aggregated residual dense network for infrared and visible image fusion,” Inf. Fusion, vol. 69, pp. 128–141, 2021.[84] Y. Yang et al., “VMDM-fusion: A saliency feature representation method for infrared and visible image fusion,” Signal Image Video Process., vol. 15, no. 6, pp. 1221–1229, 2021.[85] K. Ren et al., “An infrared and visible image fusion method based on improved DenseNet and mRMR-ZCA,” Infrared Phys. Technol., vol. 115, 2021, Art. no. 103707.[86] A. Raza et al., “IR-MSDNet: Infrared and visible image fusion based on infrared features multiscale dense network,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 3426–3437, 2021.[87] H. Xu, X. Wang, and J. Ma, “DRF: Disentangled representation for visible and infrared image fusion,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–13, 2021.[88] Z. Xu, G. Liu, L. L. Tang, and Y. H. Li, “Blur regional features based infrared and visible image fusion using an improved C3Net model,” J. Phys.Conf.Ser., vol. 1820, no. 1. IOP Publishing, 2021, Art. no. 012169.[89] L. Liu, M. Chen, M. Xu, and X. Li, “Two-stream network for infrared and visible images fusion,” Neurocomputing, vol. 460, pp. 50–58, 2021.[90] L. Jian, R. Rayhana, L. Ma, S. Wu, Z. Liu, and H. Jiang, “Infrared and visible image fusion based on deep decomposition network and saliency analysis,” IEEE Trans. Multimedia, vol. 24, pp. 3314–3326, 2021.[91] R. Liu et al., “Searching a hierarchically aggregated fusion architecture for fast multi-modality image fusion,” in Proc. 29th ACM Int. Conf. Multimedia, 2021, pp. 1600–1608.[92] R. Liu, J. Liu, Z. Jiang, X. Fan, and Z. Luo, “A bilevel integrated model with data-driven layer ensemble for multi-modality image fusion,” IEEE Trans. Image Process, vol. 30, pp. 1261–1274, 2021.[93] H. Zhang and J. Ma, “SDNet: A versatile squeeze-and-decomposition network for real-time image fusion,” Int. J. Comput. Vis., vol. 129, pp. 2761–2785, 2021.[94] Y. Gu, X. Wang, C. Zhang, and B. Li, “Advanced driving assistance based on the fusion of infrared and visible images,” Entropy, vol. 23, no. 2, 2021, Art. no. 239.[95] J. Hou et al., “A generative adversarial network for infrared and visible image fusion based on semantic segmentation,” Entropy, vol. 23, no. 3, 2021, Art. no. 376.[96] H. Zhou, W. Wu, Y. Zhang, J. Ma, and H. Ling, “Semantic-supervised infrared and visible image fusion via a dual-discriminator generative adversarial network,” IEEE Trans. Multimedia, vol. 25, pp. 635–648, 2023.[97] S. Bhagat, S. D. Joshi, B. Lall, and S. Gupta, “Multimodal sensor fusion using symmetric skip autoencoder via an adversarial regulariser,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 1146–1157, 2021.[98] J. Li, H. Huo, C. Li, R. Wang, C. Sui, and Z. Liu, “Multigrained attention network for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–12, 2021.[99] J. Liu, X. Fan, J. Jiang, R. Liu, and Z. Luo, “Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 1, pp. 105–119, Jan. 2022.[100] Y. Fu, X.-J. Wu, and T. Durrani, “Image fusion based on generative adversarial network consistent with perception,” Inf. Fusion, vol. 72, pp. 110–125, 2021.[101] J. Ma, H. Zhang, Z. Shao, P. Liang, and H. Xu, “GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–14, 2021.[102] X. Luo, A. Wang, Z. Zhang, X. Xiang, and X. -J. Wu, “LatRAIVF: An infrared and visible image fusion method based on latent regression and adversarial training,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–16, 2021.[103] H. Zhang, J. Yuan, X. Tian, and J. Ma, “GAN-FM: Infrared and visible image fusion using GAN with full-scale skip connection and dual Markovian discriminators,” IEEE Trans. Comput. Imag., vol. 7, pp. 1134–1147, 2021.[104] X. Li, H. Chen, Y. Li, and Y. Peng, “MAFusion: Multiscale attention network for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–16, 2022.[105] W. Su, Y. Huang, Q. Li, F. Zuo, and L. Liu, “Infrared and visible image fusion based on adversarial feature extraction and stable image reconstruction,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–14, 2022.[106] Z. Wang, Y. Wu, J. Wang, J. Xu, and W. Shao, “Res2Fusion: Infrared and visible image fusion based on dense Res2net and double nonlocal attention models,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–12, 2022.[107] H. Xu et al., “CUFD: An encoder–decoder network for visible and infrared image fusion based on common and unique feature decomposition,” Comput. Vis. Image Understanding, vol. 218, 2022, Art. no. 103407.[108] L. Tang, J. Yuan, and J. Ma, “Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network,” Inf. Fusion, vol. 82, pp. 28–42, 2022.[109] Z. Zhu, X. Yang, R. Lu, T. Shen, X. Xie, and T. Zhang, “CLF-Net: Contrastive learning for infrared and visible image fusion network,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–15, 2022.[110] L. Tang, J. Yuan, H. Zhang, X. Jiang, and J. Ma, “PIAFusion: A progressive infrared and visible image fusion network based on illumination aware,” Inf. Fusion, vol. 83, pp. 79–92, 2022.[111] D. Wang, J. Liu, X. Fan, and R. Liu, “Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration,” in Proc. Int. Joint Conf. Artif. Intell., 2022, pp. 3508–3515.[112] D. Zhu, W. Zhan, Y. Jiang, X. Xu, and R. Guo, “IPLF: A novel image pair learning fusion network for infrared and visible image,” IEEE Sensors J., vol. 22, no. 9, pp. 8808–8817, May 2022.[113] C. Cheng et al., “StyleFuse: An unsupervised network based on style loss function for infrared and visible image fusion,” Signal Process. Image Commun., vol. 106, 2022, Art. no. 116722.[114] Q. Li et al., “A multilevel hybrid transmission network for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–14, 2022.[115] J. Liu et al., “Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 5792–5801.[116] Y. Gao, S. Ma, and J. Liu, “DCDR-GAN: A densely connected disentangled representation generative adversarial network for infrared and visible image fusion,” IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 2, pp. 549–561, Feb. 2023.[117] J. Li, J. Zhu, C. Li, X. Chen, and B. Yang, “CGTF: Convolution-guided transformer for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–14, 2022.[118] W. Tang, F. He, and Y. Liu, “YDTR: Infrared and visible image fusion via y-shape dynamic transformer,” IEEE Trans. Multimedia, early access, Jul. 20, 2022, doi: 10.1109/TMM.2022.3192661.[119] Z. Wang, Y. Chen, W. Shao, H. Li, and L. Zhang, “SwinFuse: A residual swin transformer fusion network for infrared and visible images,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–12, 2022.[120] X. Liu et al., “MFST: Multi-modal feature self-adaptive transformer for infrared and visible image fusion,” Remote Sens., vol. 14, no. 13, 2022, Art. no. 3233.[121] J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, and Y. Ma, “SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer,” IEEE/CAA J. Automatica Sinica, vol. 9, no. 7, pp. 1200–1217, Jul. 2022.[122] G. Xiao, D. P. Bavirisetti, G. Liu, and X. Zhang, Image Fusion. Shanghai, China: Spinger Press & Shanghai Jiao Tong University Press, 2020.[123] X. Zhang, “Deep learning-based multi-focus image fusion: A survey and a comparative study,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 9, pp. 4819–4838, Sep. 2022.[124] X. Zhang, “Benchmarking and comparing multi-exposure image fusion algorithms,” Inf. Fusion, vol. 74, pp. 111–131, 2021.[125] A. P. James and B. V. Dasarathy, “Medical image fusion: A survey of the state of the art,” Inf. Fusion, vol. 19, pp. 4–19, 2014.[126] H. Ghassemian, “A review of remote sensing image fusion methods,” Inf. Fusion, vol. 32, pp. 75–89, 2016.[127] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778.[128] D. Xu et al., “Multi-scale unsupervised network for infrared and visible image fusion based on joint attention mechanism,” Infrared Phys. Technol., vol. 125, 2022, Art. no. 104242.[129] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 4700–4708.[130] Z. Yang and S. Zeng, “TPFusion: Texture preserving fusion of infrared and visible images via dense networks,” Entropy, vol. 24, no. 2, 2022, Art. no. 294.[131] Z. Ding et al., “A robust infrared and visible image fusion framework via multi-receptive-field attention and color visual perception,” Appl. Intell., vol. 53, pp. 8114–8132, 2023.[132] Y. Liu, C. Miao, J. Ji, and X. Li, “MMF: A Multi-scale MobileNet based fusion method for infrared and visible image,” Infrared Phys. Technol., vol. 119, 2021, Art. no. 103894.[133] L. Yan, J. Cao, S. Rizvi, K. Zhang, Q. Hao, and X. Cheng, “Improving the performance of image fusion based on visual saliency weight map combined with CNN,” IEEE Access, vol. 8, pp. 59 976–59 986, 2020.[134] J. Liu, Y. Wu, G. Wu, R. Liu, and X. Fan, “Learn to search a lightweight architecture for target-aware infrared and visible image fusion,” IEEE Signal Process. Lett., vol. 29, pp. 1614–1618, 2022.[135] Y. Zou et al., “Infrared visible color night vision image fusion based on deep learning,” in AI and Optical Data Sciences II, vol. 11703. Bellingham, WA, USA: SPIE, 2021, Art. no. 117031S.[136] Z. Shen et al., “Cross attention-guided dense network for images fusion,” 2021, arXiv:2109.11393.[137] D. Zhang et al., “An infrared and visible image fusion method based on deep learning,” in Proc. 4th Opt. Young Scientist Summit, International Society for Optics and Photonics, 2021, Art. no. 1178109.[138] T.-Y. Lin et al., “Microsoft COCO: Common objects in context,” in Proc. Eur. Conf. Comput. Vis., Springer, 2014, pp. 740–755.[139] Y. Peng et al., “MFDetection: A highly generalized object detection network unified with multilevel heterogeneous image fusion,” Optik, vol. 266, 2022, Art. no. 169599.[140] Z. Li et al., “Infrared and visible fusion imaging via double-layer fusion denoising neural network,” Digit. Signal Process., vol. 123, 2022, Art. no. 103433.[141] J. Wang, Y. Li, and Z. Miao, “A new infrared and visible image fusion method based on generative adversarial networks and attention mechanism,” in Proc. Int. Conf. Image Graph. Process., 2021, pp. 109–119.[142] B. Liao, Y. Du, and X. Yin, “Fusion of infrared-visible images in UE-IoT for fault point detection based on GAN,” IEEE Access, vol. 8, pp. 79 754–79 763, 2020.[143] A. Song, H. Duan, H. Pei, and L. Ding, “Triple-discriminator generative adversarial network for infrared and visible image fusion,” Neurocomputing, vol. 483, pp. 183–194, 2022.[144] A. B. Petro, C. Sbert, and J.-M. Morel, “Multiscale retinex,” Image Process. On Line, vol. 4, pp. 71–88, 2014.[145] M.-Y. Liu and O. Tuzel, “Coupled generative adversarial networks,” in Proc. 30th Int. Conf. Neural Inf. Process. Syst., 2016, pp. 469–477.[146] S. Li, X. Kang, and J. Hu, “Image fusion with guided filtering,” IEEE Trans. Image Process, vol. 22, no. 7, pp. 2864–2875, Jul. 2013.[147] A. Vaswani et al., “Attention is all you need,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 6000–6010.[148] A. Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Proc. Int. Conf. Learn. Representations, 2021.[149] Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 10 012–10 022.[150] X. Yang et al., “DGLT-Fusion: A decoupled global-local infrared and visible image fusion transformer,” Infrared Phys. Technol., vol. 128, 2023, Art. no. 104522.[151] W. Tang, F. He, and Y. Liu, “TCCFusion: An infrared and visible image fusion method based on transformer and cross correlation,” Pattern Recognit., vol. 137, 2023, Art. no. 109295.[152] L. Qu et al., “Transfuse: A unified transformer-based image fusion framework using self-supervised learning,” 2022, arXiv:2201.07451.[153] Q. Zhou et al., “Multi-modal medical image fusion based on denselyconnected high-resolution CNN and hybrid transformer,” Neural Comput. Appl., vol. 34, no. 24, pp. 21 741–21 761, 2022.[154] X. Jin et al., “An unsupervised multi-focus image fusion method based on Transformer and U-Net,” IET Image Process., vol. 17, pp. 733–746, 2022.[155] W. Tang, F. He, Y. Liu, and Y. Duan, “MATR: Multimodal medical image fusion via multiscale adaptive transformer,” IEEE Trans. Image Process, vol. 31, pp. 5134–5149, 2022.[156] L. Qu et al., “TransMEF: A transformer-based multi-exposure image fusion framework using self-supervised multi-task learning,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 2126–2134.[157] Z. Le et al., “UIFGAN: An unsupervised continual-learning generative adversarial network for unified image fusion,” Inf. Fusion, vol. 88, pp. 305–318, 2022.[158] H. Zhou, J. Hou, Y. Zhang, J. Ma, and H. Ling, “Unified gradient-and intensity-discriminator generative adversarial network for image fusion,” Inf. Fusion, vol. 88, pp. 184–201, 2022.[159] Y. Gu et al., “A dataset-free self-supervised disentangled learning method for adaptive infrared and visible images super-resolution fusion,” 2021, arXiv:2112.02869.[160] W. Xiao, Y. Zhang, H. Wang, F. Li, and H. Jin, “Heterogeneous knowledge distillation for simultaneous infrared-visible image fusion and super-resolution,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–15, 2022.[161] J. H. Lee, Y. S. Kim, D. Lee, D. -G. Kang, and J. B. Ra, “Robust CCD and IR image registration using gradient-based statistical information,” IEEE Signal Process. Lett., vol. 17, no. 4, pp. 347–350, Apr. 2010.[162] J. Han, E. J. Pauwels, and P. De Zeeuw, “Visible and infrared image registration in man-made environments employing hybrid visual features,” Pattern Recognit. Lett., vol. 34, no. 1, pp. 42–51, 2013.[163] C. Min, Y. Gu, Y. Li, and F. Yang, “Non-rigid infrared and visible image registration by enhanced affine transformation,” Pattern Recognit., vol. 106, 2020, Art. no. 107377.[164] H. Xu, J. Ma, J. Yuan, Z. Le, and W. Liu, “RFNet: Unsupervised network for mutually reinforcing multi-modal image registration and fusion,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 19 679–19 688.[165] C. Liu, B. Yang, X. Zhang, and L. Pang, “IBPNet: A multi-resolution and multi-modal image fusion network via iterative back-projection,” Appl. Intell., vol. 52, pp. 16185–16201, 2022.[166] X. Zhang, “Multi-focus image fusion: A benchmark,” 2020, arXiv: 2002.03322.[167] X. Zhang, P. Ye, and G. Xiao, “VIFB: A visible and infrared image fusion benchmark,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, 2020, pp. 468–478.[168] Y. Yuan et al., “Defogging technology based on dual-channel sensor information fusion of near-infrared and visible light,” J. Sensors, vol. 2020, pp. 1–17, 2020.[169] A. Fang et al., “Non-linear and selective fusion of cross-modal images,” Pattern Recognit., vol. 119, 2021, Art. no. 108042.[170] C. Zhang, H. Hu, Y. Tai, L. Yun, and J. Zhang, “Trustworthy image fusion with deep learning for wireless applications,” Wirel. Commun. Mobile Comput., vol. 2021, pp. 1–9, 2021.[171] F. C. Ataman and G. B. Akar, “Visible and infrared image fusion using encoder-decoder network,” in Proc. IEEE Int. Conf. Image Process., 2021, pp. 1779–1783.[172] A. Fang et al., “A light-weight, efficient, and general cross-modal image fusion network,” Neurocomputing, vol. 463, pp. 198–211, 2021.[173] Z. Wang and B. Sun, “Explicit and implicit models in infrared and visible image fusion,” 2022, arXiv:2206.09581.[174] X. Lin, G. Zhou, X. Tu, Y. Huang, and X. Ding, “Two-level consistency metric for infrared and visible image fusion,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–13, 2022.[175] C. Cheng, X.-J. Wu, T. Xu, and G. Chen, “UNIFusion: A lightweight unified image fusion network,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–14, 2021.[176] TNO Image Fusion Dataset. Accessed: Oct. 10, 2022.[Online]. Available: https://figshare.com/articles/dataset/TNO_Image_Fusion_ Dataset/1008029 [177] Videos Analytics Dataset. Accessed: Oct. 10, 2022.[Online]. Available: https://www.ino.ca/en/technologies/video-analytics-dataset/videos/ [178] Q. Ha, K. Watanabe, T. Karasawa, Y. Ushiku, and T. Harada, “MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes,” in Proc. IEEE Int. Conf. Intell. Robots Syst., 2017, pp. 5108–5115.[179] X. Jia et al., “LLVIP: A visible-infrared paired dataset for low-light vision,” in Proc. Int. Conf. Comput. Vis., 2021, pp. 3496–3504.[180] A. González et al., “Pedestrian detection at day/night time with visible and FIR cameras: A comparison,” Sensors, vol. 16, no. 6, 2016, Art. no. 820.[181] Teledyne FLIR ADAS Dataset. Accessed: Oct. 10, 2022.[Online]. Available: https://www.flir.com/oem/adas/adas-dataset-form//#anchor29 [182] C. Li, H. Cheng, S. Hu, X. Liu, J. Tang, and L. Lin, “Learning collaborative sparse representation for grayscale-thermal tracking,” IEEE Trans. Image Process, vol. 25, no. 12, pp. 5743–5756, Dec. 2016.[183] C. Li et al., “LasHeR: A large-scale high-diversity benchmark for RGBT tracking,” IEEE Trans. Image Process, vol. 31, pp. 392–404, 2021.[184] S. Hwang, J. Park, N. Kim, Y. Choi, and I. S. Kweon, “Multispectral pedestrian detection: Benchmark dataset and baseline,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2015, pp. 1037–1045.[185] J. W. Davis and V. Sharma, “Background-subtraction using contour-based fusion of thermal and visible imagery,” Comput. Vis. Image Understanding, vol. 106, no. 2–3, pp. 162–182, 2007.[186] P. Cao, Z. Wang, and K. Ma, “Debiased subjective assessment of realworld image enhancement,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2021, pp. 711–721.[187] D. M. Bulanon, T. Burks, and V. Alchanatis, “Image fusion of visible and thermal images for fruit detection,” Biosyst. Eng., vol. 103, no. 1, pp. 12–22, 2009.[188] A. M. Eskicioglu and P. S. Fisher, “Image quality measures and their performance,” IEEE Trans. Commun., vol. 43, no. 12, pp. 2959–2965, Dec. 1995.[189] M. Hossny, S. Nahavandi, and D. Creighton, “Comments on’information measure for performance of image fusion’,” Electron. Lett., vol. 44, no. 18, pp. 1066–1067, 2008.[190] M. Xu, L. Tang, H. Zhang, and J. Ma, “Infrared and visible image fusion via parallel scene and texture learning,” Pattern Recognit., vol. 132, 2022, Art. no. 108929.[191] Z. Liu, E. Blasch, Z. Xue, J. Zhao, R. Laganiere, and W. Wu, “Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: A comparative study,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 1, pp. 94–109, Jan. 2012.[192] H. Xu, J. Ma, and X.-P. Zhang, “MEF-GAN: Multi-exposure image fusion via generative adversarial networks,” IEEE Trans. Image Process, vol. 29, pp. 7203–7216, 2020.[193] Y. Zhu, C. Li, J. Tang, and B. Luo, “Quality-aware feature aggregation network for robust RGBT tracking,” IEEE Trans. Intell. Veh., vol. 6, no. 1, pp. 121–130, Mar. 2021.[194] Z. Tu, Y. Ma, Z. Li, C. Li, J. Xu, and Y. Liu, “RGBT salient object detection: A large-scale dataset and benchmark,” IEEE Trans. Multimedia, early access, May 03, 2022, doi: 10.1109/TMM.2022.3171688.[195] W. Zhou, S. Dong, C. Xu, and Y. Qian, “Edge-aware guidance fusion network for RGB-thermal scene parsing,” in Proc. AAAI Conf. Artif. Intell., 2022, pp. 3571–3579.[196] D. C. Schedl, I. Kurmi, and O. Bimber, “An autonomous drone for search and rescue in forests using airborne optical sectioning,” Sci. Robot.,vol.6, no. 55, 2021, Art. no. eabg1188.[197] L. Chen, L. Sun, T. Yang, L. Fan, K. Huang, and Z. Xuanyuan, “RGBT SLAM: A flexible SLAM framework by combining appearance and thermal information,” in Proc. IEEE Int. Conf. Robot. Automat., 2017, pp. 5682–5687.[198] L. Zhang et al., “Weakly aligned cross-modal learning for multispectral pedestrian detection,” in Proc. Int. Conf. Comput. Vis., 2019, pp. 5127–5137.[199] L. Tang, Y. Deng, Y. Ma, J. Huang, and J. Ma, “SuperFusion: A versatile image registration and fusion network with semantic awareness,” IEEE/CAA J. Automatica Sinica, vol. 9, no. 12, pp. 2121–2137, Dec. 2022.[200] S. Özer, M. Ege, and M. A. Özkanoglu, “SiameseFuse: A computationally efficient and a not-so-deep network to fuse visible and infrared images,” Pattern Recognit., vol. 129, 2022, Art. no. 108712. |
 图1:可见光和红外图像融合的好处。第一行显示可见光图像,而第二行显示相应的红外图像。第三行显示了使用MGFF方法[18]的融合结果。可以看出,融合图像包含来自可见光和红外图像的特征。
图1:可见光和红外图像融合的好处。第一行显示可见光图像,而第二行显示相应的红外图像。第三行显示了使用MGFF方法[18]的融合结果。可以看出,融合图像包含来自可见光和红外图像的特征。
 图2:关于基于深度学习的VIF方法的论文数量迅速增加。基于深度学习的通用图像融合方法也包括在内,这些方法可以应用于包括VIF在内的多个图像融合任务。
图2:关于基于深度学习的VIF方法的论文数量迅速增加。基于深度学习的通用图像融合方法也包括在内,这些方法可以应用于包括VIF在内的多个图像融合任务。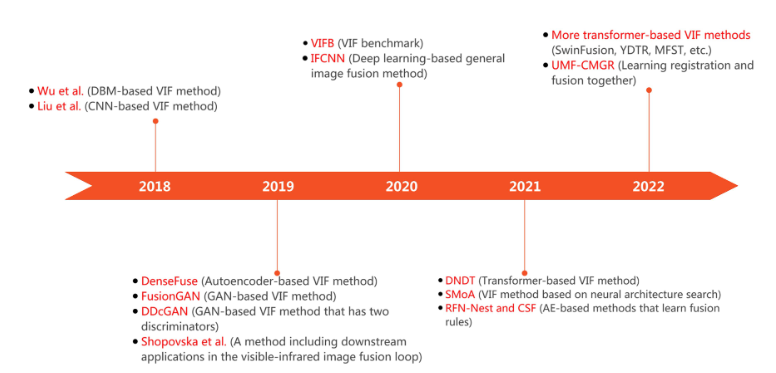 图 3:基于深度学习的VIF方法的开发时间表,以及一些关键的里程碑。
图 3:基于深度学习的VIF方法的开发时间表,以及一些关键的里程碑。 图 4.VIF方法分为三个阶段,即特征提取、特征融合和图像重建。
图 4.VIF方法分为三个阶段,即特征提取、特征融合和图像重建。 图 5.用于处理可见光和红外图像的单分支和双分支架构。在一些双分支研究中,两个深度学习模型共享权重,用虚线表示。
图 5.用于处理可见光和红外图像的单分支和双分支架构。在一些双分支研究中,两个深度学习模型共享权重,用虚线表示。
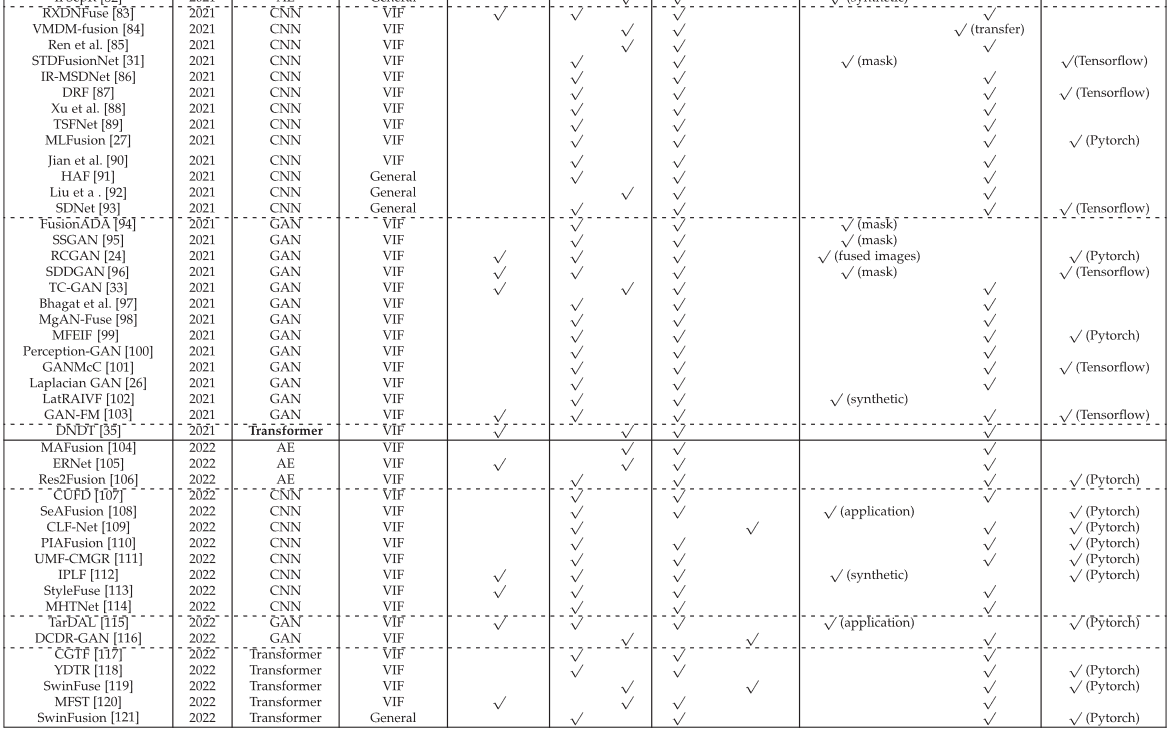 表1:为代表性的基于深度学习的VIF方法概述。此表仅总结了同行评审的方法。
表1:为代表性的基于深度学习的VIF方法概述。此表仅总结了同行评审的方法。 图 6.基于CNN的VIF方法的主要架构。请注意,基于 CNN 的模型可以包含单分支或双分支。它还可以包含其他组件,例如图像分解。
图 6.基于CNN的VIF方法的主要架构。请注意,基于 CNN 的模型可以包含单分支或双分支。它还可以包含其他组件,例如图像分解。 图 7.基于 AE 的 VIF 方法的基本架构。首先,训练自动编码器来重建输入图像。然后,利用经过训练的编码器和解码器,借助融合规则生成融合图像。
图 7.基于 AE 的 VIF 方法的基本架构。首先,训练自动编码器来重建输入图像。然后,利用经过训练的编码器和解码器,借助融合规则生成融合图像。 图 8.基于GAN的无监督VIF方法的基本架构。 (1) 一个生成器和一个鉴别器 FusionGAN [32] 是第一个基于 GAN 的 VIF 方法。在FusionGAN中,一个生成器被设计用于生成具有突出显示目标的融合图像,而一个鉴别器被设计为强制融合图像以包含更多纹理细节,如可见图像。马等[6]通过引入细节损失和目标边缘增强损失来扩展FusionGAN,使融合图像具有更多的纹理细节。Yuan等[69]还对FusionGAN进行了改进,利用可学习的群卷积代替了生成器中的卷积层,降低了计算成本,并采用了生成器中含有密集块的多级残差网络来增强网络容量。 在基于GAN的VIF方法中,一些措施也被用于提高融合性能。例如,Xu等[68]利用局部二元模式损失进行训练。Xu等[65]利用了发生器中的残余块和跳跃连接。Fu等[100]提出利用密集块来使生成器能够学习更多信息。它们不仅将浅层和深层的特征连接起来,而且还在生成器的每一层插入可见图像以帮助网络学习可见信息。此外,还应用了其他措施,如注意力机制[141]和残差连接[65]。 上述方法直接使用原始可见光和红外图像作为发生器的输入。此外,这些方法只考虑主要信息,即可见光图像中的纹理和红外图像中的对比信息,而忽略了辅助信息,即红外图像中的纹理和可见光图像中的对比信息。为了解决这个问题,马等[101]提出了GANMcC,它使用特定的内容损失作为生成器。它们对生成器使用双分支体系结构,每个分支(渐变分支和对比度分支)采用不同的源图像组合作为输入。渐变分支的输入是两个可见图像和一个红外图像的串联,而对比度分支的输入是两个红外图像和一个可见图像的串联。这种设计使发生器能够从两个源图像中获取主要和辅助信息。 除了上述方法之外,还有一种有趣的VIF方法是[99]中提出的MFEIF。MFEIF 的一个有趣功能是它不需要对齐良好的图像对来训练。该方法还通过从粗到细的深度架构利用了多尺度特征。此外,还设计了一种跨领域边缘引导的注意力机制,以鼓励模型专注于共同的结构,从而保留更多细节。Liao等[142]提出了另一种有趣的方法,他们使用VGG19从可见光图像和生成器生成的融合图像中提取特征,然后最小化特征空间中的Wasserstein距离。 上述大多数基于GAN的方法的主要缺点是,只有一个判别器可以强制生成的融合图像与可见光图像[6]、[32]、[65]、[69]、[97]、[100]或红外图像[101]相似。但是,无论哪种方式,随着对抗性游戏的进行,融合的图像都会丢失源图像的一些细节。为了解决这个问题,马等[101]提出使用基于多分类的判别器来实现可见光分布和红外分布之间的平衡。此外,一些研究人员建议使用更多的鉴别器来解决这个问题。 (2) 一个生成器和多个鉴别器 为了解决在鉴别器中考虑单个源图像的问题,一些研究人员将基于GAN的方法扩展到两个或多个鉴别器。使用更多鉴别器的主要优点是保留两个源图像中的特征。例如,Xu等[49]提出了DDcGAN,这是一种基于GAN的VIF方法,具有两个鉴别器,可用于保留两个源图像中的特征。这种方法的另一个新颖之处在于它可以融合不同分辨率的源图像。马等人[71]随后扩展了这种方法。从技术角度来看,主要改进如下。首先,使用密集连接的CNN来取代发电机中的U-Net。其次,鉴别器将图像本身而不是图像的渐变作为输入。第三,使用反卷积层替换两个上采样层对红外图像执行上采样操作,以生成器的输入。 其他研究人员也注意到,采用两个鉴别器是有益的。例如,Li等[50]、[66]、[67]、[98]设计了一系列基于GAN的VIF方法,使用一个生成器和两个鉴别器。最初,他们提出了MDWGAN [50],它使用一个生成器和两个鉴别器。定义了一个基于局部二进制模式的纹理损失函数,以强制融合图像保留更多的纹理信息。该方法随后扩展到D2WGAN[67]。主要的改进是采用了具有 Wasserstein 距离的 GAN。然后,该方法扩展到在编码器中采用多尺度注意力的MgAN-Fuse [98]。此外,源可见光图像和红外图像使用两个不同的编码器进行处理,而不是由同一个 CNN 串联和处理。Li等[66]还提出了AttentionFGAN,它在生成器和判别器中都采用了多尺度注意力机制。此外,在发生器中,可见光图像的意图图和红外图像的意图图分别由两个多尺度注意力网络生成。这两个意图图和源图像一起用于生成融合图像。这与MgAN-Fuse[98]不同,后者在发生器中采用编码器-解码器架构。此外,基于鉴别器在融合图像和源图像之间设计了注意力损失。此外,Zhang等[103]提出使用一个基于全尺寸跳跃连接的发生器和两个马尔可夫判别器来保存可见光和红外源图像中的有用信息。 除了使用两个判别器的方法外,Song等[143]最近在VIF方法中使用了一个生成器和三个判别器。除了可见光和红外分别器外,他们还设计了一个差分图像鉴别器来解释可见光和红外图像之间的差异。 (3)两个生成器和两个判别器 Zhao等[70]提出了一种使用两个生成器和两个判别器的VIF方法。他们首先使用第一个发生器从可见光图像生成假红外图像。然后,他们将假红外图像和可见光图像融合在一起,使用第二个发生器获得融合图像。第一个鉴别器用于将融合图像与可见图像进行比较。第二个鉴别器用于比较融合图像、真实红外图像和假红外图像。据我们所知,这是第一个在测试阶段仅使用可见图像作为输入的VIF方法。 2)监督方法:有一些基于GAN的监督方法使用不同类型的真实标签。第一种类型使用其他方法生成的融合图像作为地面实况。例如,列别杰夫等[22]提出了一种由一个生成器和一个判别器组成的方法。他们使用使用拉普拉斯金字塔算法生成的融合图像以及MultiScale Retinex[144]作为基本事实。之后,Li等[24]提出了基于耦合GAN的RCGAN[145]。特别是,RCGAN有两个发生器和两个鉴别器。这种方法的一个创新之处在于采用GFF[146]生成的预融合图像在耦合发生器中进行优化。但是,RCGAN的性能将受到所选择的生成预融合图像的方法的影响。 第二种类型使用对象掩码作为监督信号。例如,Gu等[94]提出了由一个发生器和一个鉴别器组成的FusionADA。在FusionADA中,使用标记掩模来帮助融合图像包含来自红外图像的突出热目标。然而,判别器的输入仅包含显著的热目标,因此融合图像可能会丢失可见图像的纹理细节。之后,Hou等[95]提出了利用语义分割来生成目标掩码的SSGAN。生成器采用包含前景路径和背景路径的双编码器-单解码器结构来生成融合图像。鉴别器的输入是可见图像背景和红外图像前景的组合。通过这种方式,可以保留红外图像中的热目标和可见光图像中的纹理细节。但是,在SSGAN中,需要单独训练分割网络。最近,周等[96]提出了一种使用一个生成器和两个判别器的语义监督VIF方法。这项工作的一个新贡献是设计了一个信息量鉴别器模块来生成融合权重,然后用于保存可见光和红外图像中的语义信息。此外,两个鉴别器有助于使融合图像包含可见光图像的纹理细节和红外图像的热辐射。训练模型需要标记的掩码。 第三种类型使用来自RGB-D数据集的RGB图像的YCbCr空间中的Y通道作为真实情况[102]。该方法基于地面实况图像生成合成红外和可见光图像[102]。然后使用合成数据集进行训练。 综上所述,基于GAN的方法已成为最流行的VIF方法类型之一。请注意,在某些基于 GAN 的方法中,GAN 仅应用于图像融合过程的一部分。例如,GAN仅用于融合拉普拉斯GAN中源图像的细节层[26]。
图 8.基于GAN的无监督VIF方法的基本架构。 (1) 一个生成器和一个鉴别器 FusionGAN [32] 是第一个基于 GAN 的 VIF 方法。在FusionGAN中,一个生成器被设计用于生成具有突出显示目标的融合图像,而一个鉴别器被设计为强制融合图像以包含更多纹理细节,如可见图像。马等[6]通过引入细节损失和目标边缘增强损失来扩展FusionGAN,使融合图像具有更多的纹理细节。Yuan等[69]还对FusionGAN进行了改进,利用可学习的群卷积代替了生成器中的卷积层,降低了计算成本,并采用了生成器中含有密集块的多级残差网络来增强网络容量。 在基于GAN的VIF方法中,一些措施也被用于提高融合性能。例如,Xu等[68]利用局部二元模式损失进行训练。Xu等[65]利用了发生器中的残余块和跳跃连接。Fu等[100]提出利用密集块来使生成器能够学习更多信息。它们不仅将浅层和深层的特征连接起来,而且还在生成器的每一层插入可见图像以帮助网络学习可见信息。此外,还应用了其他措施,如注意力机制[141]和残差连接[65]。 上述方法直接使用原始可见光和红外图像作为发生器的输入。此外,这些方法只考虑主要信息,即可见光图像中的纹理和红外图像中的对比信息,而忽略了辅助信息,即红外图像中的纹理和可见光图像中的对比信息。为了解决这个问题,马等[101]提出了GANMcC,它使用特定的内容损失作为生成器。它们对生成器使用双分支体系结构,每个分支(渐变分支和对比度分支)采用不同的源图像组合作为输入。渐变分支的输入是两个可见图像和一个红外图像的串联,而对比度分支的输入是两个红外图像和一个可见图像的串联。这种设计使发生器能够从两个源图像中获取主要和辅助信息。 除了上述方法之外,还有一种有趣的VIF方法是[99]中提出的MFEIF。MFEIF 的一个有趣功能是它不需要对齐良好的图像对来训练。该方法还通过从粗到细的深度架构利用了多尺度特征。此外,还设计了一种跨领域边缘引导的注意力机制,以鼓励模型专注于共同的结构,从而保留更多细节。Liao等[142]提出了另一种有趣的方法,他们使用VGG19从可见光图像和生成器生成的融合图像中提取特征,然后最小化特征空间中的Wasserstein距离。 上述大多数基于GAN的方法的主要缺点是,只有一个判别器可以强制生成的融合图像与可见光图像[6]、[32]、[65]、[69]、[97]、[100]或红外图像[101]相似。但是,无论哪种方式,随着对抗性游戏的进行,融合的图像都会丢失源图像的一些细节。为了解决这个问题,马等[101]提出使用基于多分类的判别器来实现可见光分布和红外分布之间的平衡。此外,一些研究人员建议使用更多的鉴别器来解决这个问题。 (2) 一个生成器和多个鉴别器 为了解决在鉴别器中考虑单个源图像的问题,一些研究人员将基于GAN的方法扩展到两个或多个鉴别器。使用更多鉴别器的主要优点是保留两个源图像中的特征。例如,Xu等[49]提出了DDcGAN,这是一种基于GAN的VIF方法,具有两个鉴别器,可用于保留两个源图像中的特征。这种方法的另一个新颖之处在于它可以融合不同分辨率的源图像。马等人[71]随后扩展了这种方法。从技术角度来看,主要改进如下。首先,使用密集连接的CNN来取代发电机中的U-Net。其次,鉴别器将图像本身而不是图像的渐变作为输入。第三,使用反卷积层替换两个上采样层对红外图像执行上采样操作,以生成器的输入。 其他研究人员也注意到,采用两个鉴别器是有益的。例如,Li等[50]、[66]、[67]、[98]设计了一系列基于GAN的VIF方法,使用一个生成器和两个鉴别器。最初,他们提出了MDWGAN [50],它使用一个生成器和两个鉴别器。定义了一个基于局部二进制模式的纹理损失函数,以强制融合图像保留更多的纹理信息。该方法随后扩展到D2WGAN[67]。主要的改进是采用了具有 Wasserstein 距离的 GAN。然后,该方法扩展到在编码器中采用多尺度注意力的MgAN-Fuse [98]。此外,源可见光图像和红外图像使用两个不同的编码器进行处理,而不是由同一个 CNN 串联和处理。Li等[66]还提出了AttentionFGAN,它在生成器和判别器中都采用了多尺度注意力机制。此外,在发生器中,可见光图像的意图图和红外图像的意图图分别由两个多尺度注意力网络生成。这两个意图图和源图像一起用于生成融合图像。这与MgAN-Fuse[98]不同,后者在发生器中采用编码器-解码器架构。此外,基于鉴别器在融合图像和源图像之间设计了注意力损失。此外,Zhang等[103]提出使用一个基于全尺寸跳跃连接的发生器和两个马尔可夫判别器来保存可见光和红外源图像中的有用信息。 除了使用两个判别器的方法外,Song等[143]最近在VIF方法中使用了一个生成器和三个判别器。除了可见光和红外分别器外,他们还设计了一个差分图像鉴别器来解释可见光和红外图像之间的差异。 (3)两个生成器和两个判别器 Zhao等[70]提出了一种使用两个生成器和两个判别器的VIF方法。他们首先使用第一个发生器从可见光图像生成假红外图像。然后,他们将假红外图像和可见光图像融合在一起,使用第二个发生器获得融合图像。第一个鉴别器用于将融合图像与可见图像进行比较。第二个鉴别器用于比较融合图像、真实红外图像和假红外图像。据我们所知,这是第一个在测试阶段仅使用可见图像作为输入的VIF方法。 2)监督方法:有一些基于GAN的监督方法使用不同类型的真实标签。第一种类型使用其他方法生成的融合图像作为地面实况。例如,列别杰夫等[22]提出了一种由一个生成器和一个判别器组成的方法。他们使用使用拉普拉斯金字塔算法生成的融合图像以及MultiScale Retinex[144]作为基本事实。之后,Li等[24]提出了基于耦合GAN的RCGAN[145]。特别是,RCGAN有两个发生器和两个鉴别器。这种方法的一个创新之处在于采用GFF[146]生成的预融合图像在耦合发生器中进行优化。但是,RCGAN的性能将受到所选择的生成预融合图像的方法的影响。 第二种类型使用对象掩码作为监督信号。例如,Gu等[94]提出了由一个发生器和一个鉴别器组成的FusionADA。在FusionADA中,使用标记掩模来帮助融合图像包含来自红外图像的突出热目标。然而,判别器的输入仅包含显著的热目标,因此融合图像可能会丢失可见图像的纹理细节。之后,Hou等[95]提出了利用语义分割来生成目标掩码的SSGAN。生成器采用包含前景路径和背景路径的双编码器-单解码器结构来生成融合图像。鉴别器的输入是可见图像背景和红外图像前景的组合。通过这种方式,可以保留红外图像中的热目标和可见光图像中的纹理细节。但是,在SSGAN中,需要单独训练分割网络。最近,周等[96]提出了一种使用一个生成器和两个判别器的语义监督VIF方法。这项工作的一个新贡献是设计了一个信息量鉴别器模块来生成融合权重,然后用于保存可见光和红外图像中的语义信息。此外,两个鉴别器有助于使融合图像包含可见光图像的纹理细节和红外图像的热辐射。训练模型需要标记的掩码。 第三种类型使用来自RGB-D数据集的RGB图像的YCbCr空间中的Y通道作为真实情况[102]。该方法基于地面实况图像生成合成红外和可见光图像[102]。然后使用合成数据集进行训练。 综上所述,基于GAN的方法已成为最流行的VIF方法类型之一。请注意,在某些基于 GAN 的方法中,GAN 仅应用于图像融合过程的一部分。例如,GAN仅用于融合拉普拉斯GAN中源图像的细节层[26]。 图 9.基于 Transformer 的 VIF 方法的示例体系结构。CNN 模型用于提取特征,这些特征使用变压器模块进行融合。融合图像是通过使用另一个 CNN 模型获得的。
图 9.基于 Transformer 的 VIF 方法的示例体系结构。CNN 模型用于提取特征,这些特征使用变压器模块进行融合。融合图像是通过使用另一个 CNN 模型获得的。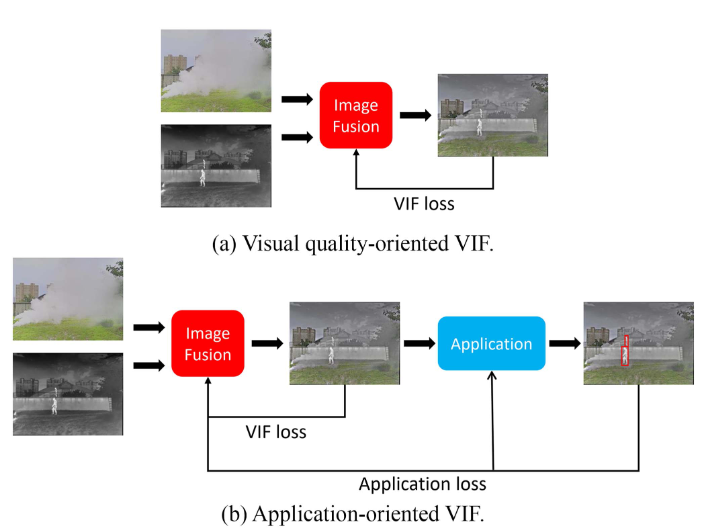 图 10.以视觉质量为导向的 VIF 与面向应用的 VIF。以人员检测为例。可见光和红外图像在M3FD数据集中提供[115]。融合图像由作者使用 MGFF [18] 图像融合算法生成。
图 10.以视觉质量为导向的 VIF 与面向应用的 VIF。以人员检测为例。可见光和红外图像在M3FD数据集中提供[115]。融合图像由作者使用 MGFF [18] 图像融合算法生成。【本文地址】
今日新闻 |
推荐新闻 |