GMM算法(python版) |
您所在的位置:网站首页 › 系统gmm模型代码怎么安装 › GMM算法(python版) |
GMM算法(python版)
|
原
【machine learning】GMM算法(Python版)
一、GMM模型
事实上,GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来(所以 GMM 除了用在 clustering 上之外,还经常被用于 density estimation ),简单地说,k-means 的结果是每个数据点被 assign 到其中某一个 cluster 了,而 GMM 则给出这些数据点被 assign 到每个 cluster 的概率,又称作 soft assignment 。 得出一个概率有很多好处,因为它的信息量比简单的一个结果要多,比如,我可以把这个概率转换为一个 score ,表示算法对自己得出的这个结果的把握,参考pluskid大神博文 也许我可以对同一个任务,用多个方法得到结果,最后选取“把握”最大的那个结果;另一个很常见的方法是在诸如疾病诊断之类的场所,机器对于那些很容易分辨的情况(患病或者不患病的概率很高)可以自动区分,而对于那种很难分辨的情况,比如,49% 的概率患病,51% 的概率正常,如果仅仅简单地使用 50% 的阈值将患者诊断为“正常”的话,风险是非常大的,因此,在机器对自己的结果把握很小的情况下,会“拒绝发表评论”,而把这个任务留给有经验的医生去解决。每个GMM由K个Gaussian分布组成,每个Gaussian称为一个“Component”,这些Component 线性加成在一起就组成了GMM 的概率密度函数: 根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K个Gaussian Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数 pi(k) ,选中了 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为了已知的问题。 那么如何用 GMM 来做 clustering 呢?其实很简单,现在我们有了数据,假定它们是由 GMM 生成出来的,那么我们只要根据数据推出 GMM 的概率分布来就可以了,然后 GMM 的 K 个 Component 实际上就对应了 K 个 cluster 了。根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。 二、参数与似然函数现在假设我们有 N 个数据点,并假设它们服从某个分布(记作 p(x)),现在要确定里面的一些参数的值,例如,在 GMM 中,我们就需要确定 影响因子pi(k)、各类均值pMiu(k) 和 各类协方差pSigma(k) 这些参数。 我们的想法是,找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于 ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和∑Ni=1logp(xi)∑i=1Nlogp(xi),得到log-likelihood function 。接下来我们只要将这个函数最大化(通常的做法是求导并令导数等于零,然后解方程),亦即找到这样一组参数值,它让似然函数取得最大值,我们就认为这是最合适的参数,这样就完成了参数估计的过程。 下面让我们来看一看 GMM 的 log-likelihood function : 由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,我们采取之前从 GMM 中随机选点的办法:分成两步,实际上也就类似于K-means 的两步。 三、算法流程1、估计数据由每个 Component 生成的概率(并不是每个 Component 被选中的概率):对于每个数据 xixi 来说,它由第 k 个 Component 生成的概率为 其中N(xi|μk,Σk)就是后验概率 2、通过极大似然估计可以通过求到令参数=0得到参数pMiu,pSigma的值。 其中 Nk=∑Ni=1γ(i,k)Nk=∑i=1Nγ(i,k)(这里的顺理成章要考证起来有很多要说) 3、重复迭代前面两步,直到似然函数的值收敛为止。 声明:这里完全可以对照EM算法的两步走,对应关系如下: 均值和方差对应θComponent 生成的概率为隐藏变量最大似然函数L(θ)=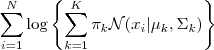 四、GMM聚类代码
四、GMM聚类代码
GMM.py #! /usr/bin/env python #coding=utf-8 from numpy import * import pylab import random,math def loadDataSet(fileName): #general function to parse tab -delimited floats dataMat = [] #assume last column is target value fr = open(fileName) for line in fr.readlines(): curLine = line.strip().split('\t') fltLine = map(float,curLine) #map all elements to float() dataMat.append(fltLine) return dataMat def gmm(file, K_or_centroids): # ============================================================ # Expectation-Maximization iteration implementation of # Gaussian Mixture Model. # # PX = GMM(X, K_OR_CENTROIDS) # [PX MODEL] = GMM(X, K_OR_CENTROIDS) # # - X: N-by-D data matrix. # - K_OR_CENTROIDS: either K indicating the number of # components or a K-by-D matrix indicating the # choosing of the initial K centroids. # # - PX: N-by-K matrix indicating the probability of each # component generating each point. # - MODEL: a structure containing the parameters for a GMM: # MODEL.Miu: a K-by-D matrix. # MODEL.Sigma: a D-by-D-by-K matrix. # MODEL.Pi: a 1-by-K vector. # ============================================================ ## Generate Initial Centroids threshold = 1e-15 dataMat = mat(loadDataSet(file)) [N, D] = shape(dataMat) K_or_centroids = 2 # K_or_centroids可以是一个整数,也可以是k个质心的二维列向量 if shape(K_or_centroids)==(): #if K_or_centroid is a 1*1 number K = K_or_centroids Rn_index = range(N) random.shuffle(Rn_index) #random index N samples centroids = dataMat[Rn_index[0:K], :]; #generate K random centroid else: # K_or_centroid is a initial K centroid K = size(K_or_centroids)[0]; centroids = K_or_centroids; ## initial values [pMiu,pPi,pSigma] = init_params(dataMat,centroids,K,N,D) Lprev = -inf #上一次聚类的误差 # EM Algorithm while True: # Estimation Step Px = calc_prob(pMiu,pSigma,dataMat,K,N,D) # new value for pGamma(N*k), pGamma(i,k) = Xi由第k个Gaussian生成的概率 # 或者说xi中有pGamma(i,k)是由第k个Gaussian生成的 pGamma = mat(array(Px) * array(tile(pPi, (N, 1)))) #分子 = pi(k) * N(xi | pMiu(k), pSigma(k)) pGamma = pGamma / tile(sum(pGamma, 1), (1, K)) #分母 = pi(j) * N(xi | pMiu(j), pSigma(j))对所有j求和 ## Maximization Step - through Maximize likelihood Estimation #print 'dtypeddddddddd:',pGamma.dtype Nk = sum(pGamma, 0) #Nk(1*k) = 第k个高斯生成每个样本的概率的和,所有Nk的总和为N。 # update pMiu pMiu = mat(diag((1/Nk).tolist()[0])) * (pGamma.T) * dataMat #update pMiu through MLE(通过令导数 = 0得到) pPi = Nk/N # update k个 pSigma print 'kk=',K for kk in range(K): Xshift = dataMat-tile(pMiu[kk], (N, 1)) Xshift.T * mat(diag(pGamma[:, kk].T.tolist()[0])) * Xshift / 2 pSigma[:, :, kk] = (Xshift.T * \ mat(diag(pGamma[:, kk].T.tolist()[0])) * Xshift) / Nk[kk] # check for convergence L = sum(log(Px*(pPi.T))) if L-Lprev < threshold: break Lprev = L return Px def init_params(X,centroids,K,N,D): pMiu = centroids #k*D, 即k类的中心点 pPi = zeros([1, K]) #k类GMM所占权重(influence factor) pSigma = zeros([D, D, K]) #k类GMM的协方差矩阵,每个是D*D的 # 距离矩阵,计算N*K的矩阵(x-pMiu)^2 = x^2+pMiu^2-2*x*Miu #x^2, N*1的矩阵replicateK列\#pMiu^2,1*K的矩阵replicateN行 distmat = tile(sum(power(X,2), 1),(1, K)) + \ tile(transpose(sum(power(pMiu,2), 1)),(N, 1)) - \ 2*X*transpose(pMiu) labels = distmat.argmin(1) #Return the minimum from each row # 获取k类的pPi和协方差矩阵 for k in range(K): boolList = (labels==k).tolist() indexList = [boolList.index(i) for i in boolList if i==[True]] Xk = X[indexList, :] #print cov(Xk) # 也可以用shape(XK)[0] pPi[0][k] = float(size(Xk, 0))/N pSigma[:, :, k] = cov(transpose(Xk)) return pMiu,pPi,pSigma # 计算每个数据由第k类生成的概率矩阵Px def calc_prob(pMiu,pSigma,X,K,N,D): # Gaussian posterior probability # N(x|pMiu,pSigma) = 1/((2pi)^(D/2))*(1/(abs(sigma))^0.5)*exp(-1/2*(x-pMiu)'pSigma^(-1)*(x-pMiu)) Px = mat(zeros([N, K])) for k in range(K): Xshift = X-tile(pMiu[k, :],(N, 1)) #X-pMiu #inv_pSigma = mat(pSigma[:, :, k]).I inv_pSigma = linalg.pinv(mat(pSigma[:, :, k])) tmp = sum(array((Xshift*inv_pSigma)) * array(Xshift), 1) # 这里应变为一列数 tmp = mat(tmp).T #print linalg.det(inv_pSigma),'54545' Sigema = linalg.det(mat(inv_pSigma)) if Sigema < 0: Sigema=0 coef = power((2*(math.pi)),(-D/2)) * sqrt(Sigema) Px[:, k] = coef * exp(-0.5*tmp) return Px 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139main.py #! /usr/bin/env python #coding=utf-8 import GMM ''' def showFigure(dataMat,k,clusterAssment): tag=['go','or','yo','ko'] for i in range(k): datalist = dataMat[nonzero(clusterAssment[:,0].A==i)[0]] pylab.plot(datalist[:,0],datalist[:,1],tag[i]) pylab.show() ''' if __name__ == '__main__': GMM.gmm('testSet.txt',2) 12345678910111213141516说明: 程序由matlab代码改过了,利用了numpy库的函数,需要下载软件可参考链接 其中的分析数据源我用了KMeans算法中的数据,不过遇到了奇异矩阵的问题(因为数据分布本来就有悖于高斯分布),即使用了伪逆也没解决问题,看之后学习能否回头再解决。也可查看博文评论围观别人的解决方法 matlab在矩阵的处理上的确优于Python太多了,一方面不用导入库,也没有存在array,mat等类的转换和众多函数的比较和考虑。不过Python综合应用多,上至Web下至PC,从测试到开发都有很多人用,相比matlab还是做测试多一点。 |
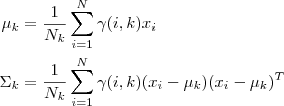
【本文地址】
今日新闻 |
推荐新闻 |