推荐算法 |
您所在的位置:网站首页 › 算法网站推荐 › 推荐算法 |
推荐算法
|
以下内容来自刘建平Pinard-博客园的学习笔记,总结如下: 1 协同过滤推荐算法总结推荐算法具有非常多的应用场景和商业价值,因此对推荐算法值得好好研究。 推荐算法种类很多,但是目前应用最广泛的应该是协同过滤类别的推荐算法,本文就对协同过滤类别的推荐算法做一个概括总结,后续也会对一些典型的协同过滤推荐算法做原理总结。 1.1 推荐算法概述 推荐算法是非常古老的,在机器学习还没有兴起的时候就有需求和应用了。 概括来说,可以分为以下5种: 1)基于内容的推荐:这一类一般依赖于自然语言处理NLP的一些知识,通过挖掘文本的TF-IDF特征向量,来得到用户的偏好,进而做推荐。这类推荐算法可以找到用户独特的小众喜好,而且还有较好的解释性。这一类需要NLP的基础。 2)协同过滤推荐:协同过滤是推荐算法中目前最主流的种类,花样繁多,在工业界已经有了很多广泛的应用。它的优点是不需要太多特定领域的知识,可以通过基于统计的机器学习算法来得到较好的推荐效果。最大的优点是工程上容易实现,可以方便应用到产品中。目前绝大多数实际应用的推荐算法都是协同过滤推荐算法。 3)混合推荐:这个类似我们机器学习中的集成学习,博才众长,通过多个推荐算法的结合,得到一个更好的推荐算法,起到三个臭皮匠顶一个诸葛亮的作用。比如通过建立多个推荐算法的模型,最后用投票法决定最终的推荐结果。混合推荐理论上不会比单一任何一种推荐算法差,但是使用混合推荐,算法复杂度就提高了,在实际应用中有使用,但是并没有单一的协同过滤推荐算法,比如逻辑回归之类的二分类推荐算法广泛。 4)基于规则的推荐:这类算法常见的比如基于最多用户点击,最多用户浏览等,属于大众型的推荐方法,在目前的大数据时代并不主流。 5)基于人口统计信息的推荐:这一类是最简单的推荐算法了,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后进行推荐,目前在大型系统中已经较少使用。  1.2 协同过滤推荐概述 协同过滤(Collaborative Filtering)作为推荐算法中最经典的类型,包括在线的协同和离线的过滤两部分。 所谓在线协同,就是通过在线数据找到用户可能喜欢的物品,而离线过滤,则是过滤掉一些不值得推荐的数据,比如推荐值评分低的数据,或者虽然推荐值高但是用户已经购买的数据。 协同过滤的模型一般为m个物品,m个用户的数据,只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。 一般来说,协同过滤推荐分为三种类型。 第一种是基于用户(user-based)的协同过滤, 第二种是基于项目(item-based)的协同过滤, 第三种是基于模型(model based)的协同过滤。 基于用户(user-based)的协同过滤主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。 而基于项目(item-based)的协同过滤和基于用户的协同过滤类似,只不过这时我们转向找到物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么我们就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。比如你在网上买了一本机器学习相关的书,网站马上会推荐一堆机器学习,大数据相关的书给你,这里就明显用到了基于项目的协同过滤思想。 我们可以简单比较下基于用户的协同过滤和基于项目的协同过滤:基于用户的协同过滤需要在线找用户和用户之间的相似度关系,计算复杂度肯定会比基于项目的协同过滤高。但是可以帮助用户找到新类别的有惊喜的物品。而基于项目的协同过滤,由于考虑的物品的相似性一段时间不会改变,因此可以很容易的离线计算,准确度一般也可以接受,但是推荐的多样性来说,就很难带给用户惊喜了。 一般对于小型的推荐系统来说,基于项目的协同过滤肯定是主流。但是如果是大型的推荐系统来说,则可以考虑基于用户的协同过滤,当然更加可以考虑我们的第三种类型,基于模型的协同过滤。 基于模型(model based)的协同过滤是目前最主流的协同过滤类型了,我们的一大堆机器学习算法也可以在这里找到用武之地。下面我们就重点介绍基于模型的协同过滤。 1.3 基于模型的协同过滤 基于模型的协同过滤作为目前最主流的协同过滤类型,这里主要是对其思想做有一个归类概括。 我们的问题是这样的m个物品,m个用户的数据,只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。 对于这个问题,用机器学习的思想来建模解决,主流的方法可以分为:用关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型来解决。下面我们分别加以介绍。 1.3.1 用关联算法做协同过滤 一般我们可以找出用户购买的所有物品数据里频繁出现的项集序列,来做频繁集挖掘,找到满足支持度阈值的关联物品的频繁N项集或者序列。如果用户购买了频繁N项集或者序列里的部分物品,那么我们可以将频繁项集或序列里的其他物品按一定的评分准则推荐给用户,这个评分准则可以包括支持度,置信度和提升度等。 常用的关联推荐算法有Apriori,FP Tree和PrefixSpan。 1.3.2 用聚类算法做协同过滤 用聚类算法做协同过滤就和前面的基于用户或者项目的协同过滤有些类似了。我们可以按照用户或者按照物品基于一定的距离度量来进行聚类。如果基于用户聚类,则可以将用户按照一定距离度量方式分成不同的目标人群,将同样目标人群评分高的物品推荐给目标用户。基于物品聚类的话,则是将用户评分高物品的相似同类物品推荐给用户。 常用的聚类推荐算法有K-Means, BIRCH, DBSCAN和谱聚类, 1.3.3 用分类算法做协同过滤 如果我们根据用户评分的高低,将分数分成几段的话,则这个问题变成分类问题。比如最直接的,设置一份评分阈值,评分高于阈值的就是推荐,评分低于阈值就是不推荐,我们将问题变成了一个二分类问题。虽然分类问题的算法多如牛毛,但是目前使用最广泛的是逻辑回归。 因为逻辑回归的解释性比较强,每个物品是否推荐我们都有一个明确的概率放在这,同时可以对数据的特征做工程化,得到调优的目的。 目前逻辑回归做协同过滤在BAT等大厂已经非常成熟了。 常见的分类推荐算法有逻辑回归和朴素贝叶斯,两者的特点是解释性很强。 1.3.4 用回归算法做协同过滤 用回归算法做协同过滤比分类算法看起来更加的自然。我们的评分可以是一个连续的值而不是离散的值,通过回归模型我们可以得到目标用户对某商品的预测打分。 常用的回归推荐算法有Ridge回归,回归树和支持向量回归。 1.3.5 用矩阵分解做协同过滤 用矩阵分解做协同过滤是目前使用也很广泛的一种方法。由于传统的奇异值分解SVD要求矩阵不能有缺失数据,必须是稠密的,而我们的用户物品评分矩阵是一个很典型的稀疏矩阵,直接使用传统的SVD到协同过滤是比较复杂的。 目前主流的矩阵分解推荐算法主要是SVD的一些变种,比如FunkSVD,BiasSVD和SVD++。这些算法和传统SVD的最大区别是不再要求将矩阵分解为 U\Sigma V^{T} 的形式,而变是两个低秩矩阵 P^{T}Q 的乘积形式。 1.3.6 用神经网络做协同过滤 用神经网络乃至深度学习做协同过滤应该是以后的一个趋势。目前比较主流的用两层神经网络来做推荐算法的是限制玻尔兹曼机(RBM)。在目前的Netflix算法比赛中, RBM算法的表现很牛。当然如果用深层的神经网络来做协同过滤应该会更好,大厂商用深度学习的方法来做协同过滤应该是将来的一个趋势。 1.3.7 用图模型做协同过滤 用图模型做协同过滤,则将用户之间的相似度放到了一个图模型里面去考虑,常用的算法是SimRank系列算法和马尔科夫模型算法。 对于SimRank系列算法,它的基本思想是被相似对象引用的两个对象也具有相似性。算法思想有点类似于大名鼎鼎的PageRank。而马尔科夫模型算法当然是基于马尔科夫链了,它的基本思想是基于传导性来找出普通距离度量算法难以找出的相似性。 1.3.8 用隐语义模型做协同过滤 隐语义模型主要是基于NLP的,涉及到对用户行为的语义分析来做评分推荐,主要方法有隐性语义分析LSA和隐含狄利克雷分布LDA。 1.4 协同过滤的一些新方向 推荐算法的变革也在进行中,就算是最火爆的基于逻辑回归推荐算法也在面临被取代。 哪些算法可能取代逻辑回归之类的传统协同过滤呢? a) 基于集成学习的方法和混合推荐:这个和混合推荐也靠在一起了。由于集成学习的成熟,在推荐算法上也有较好的表现。一个可能取代逻辑回归的算法是GBDT。目前GBDT在很多算法比赛都有好的表现,还有工业级的并行化实现类库。 b)基于矩阵分解的方法:矩阵分解,由于方法简单,一直受到青睐。目前开始渐渐流行的矩阵分解方法有分解机(Factorization Machine)和张量分解(Tensor Factorization)。 c) 基于深度学习的方法:目前两层的神经网络RBM都已经有非常好的推荐算法效果,而随着深度学习和多层神经网络的兴起,以后可能推荐算法就是深度学习的天下了?目前看最火爆的是基于CNN和RNN的推荐算法。 1.5 协同过滤总结 协同过滤作为一种经典的推荐算法种类,在工业界应用广泛,它的优点很多,模型通用性强,不需要太多对应数据领域的专业知识,工程实现简单,效果也不错。这些都是它流行的原因。 协同过滤也有些难以避免的难题,比如令人头疼的“冷启动”问题,我们没有新用户任何数据的时候,无法较好的为新用户推荐物品。同时也没有考虑情景的差异,比如根据用户所在的场景和用户当前的情绪。当然,也无法得到一些小众的独特喜好,这块是基于内容的推荐比较擅长的。 以上就是协同过滤推荐算法的一个总结。 2 矩阵分解在协同过滤算法中的应用用矩阵分解做协同过滤是广泛使用的方法,这里就对矩阵分解在协同过滤推荐算法中的应用做一个总结。 2.1 矩阵分解用于推荐算法要解决的问题 在推荐系统中,我们常常遇到的问题是这样的,我们有很多用户和物品,也有少部分用户对少部分物品的评分,我们希望预测目标用户对其他未评分物品的评分,进而将评分高的物品推荐给目标用户。比如下面的用户物品评分表:  对于每个用户,我们希望较准确的预测出用户对未评分物品的评分。对于这个问题我们有很多解决方法,本文我们关注于用矩阵分解的方法来做。如果将m个用户和n个物品对应的评分看做一个矩阵M,我们希望通过矩阵分解来解决这个问题。 2.2 传统的奇异值分解SVD用于推荐 说道矩阵分解,我们首先想到的就是奇异值分解SVD。 此时可以将这个用户物品对应的m×n矩阵M进行SVD分解,并通过选择部分较大的一些奇异值来同时进行降维,也就是说矩阵M此时分解为: 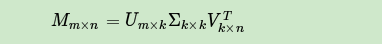 其中k是矩阵M中较大的部分奇异值的个数,一般会远远的小于用户数和物品数。如果我们要预测第i个用户对第j个物品的评分 m_{ij} ,则只需要计算 u_{i}^{T}\Sigma v_{j} 即可。通过这种方法,我们可以将评分表里面所有没有评分的位置得到一个预测评分。通过找到最高的若干个评分对应的物品推荐给用户。 可以看出这种方法简单直接,似乎很有吸引力。但是有一个很大的问题我们忽略了,就是SVD分解要求矩阵是稠密的,也就是说矩阵的所有位置不能有空白。有空白时我们的M是没法直接去SVD分解的。大家会说,如果这个矩阵是稠密的,那不就是说我们都已经找到所有用户物品的评分了嘛,那还要SVD干嘛! 的确,这是一个问题,传统SVD采用的方法是对评分矩阵中的缺失值进行简单的补全,比如用全局平均值或者用用户物品平均值补全,得到补全后的矩阵。接着可以用SVD分解并降维。 虽然有了上面的补全策略,我们的传统SVD在推荐算法上还是较难使用。因为我们的用户数和物品一般都是超级大,随便就成千上万了。这么大一个矩阵做SVD分解是非常耗时的。 那么有没有简化版的矩阵分解可以用呢? 我们下面来看看实际可以用于推荐系统的矩阵分解。 2.3 FunkSVD算法用于推荐 FunkSVD是在传统SVD面临计算效率问题时提出来的,既然将一个矩阵做SVD分解成3个矩阵很耗时,同时还面临稀疏的问题,那么我们能不能避开稀疏问题,同时只分解成两个矩阵呢?也就是说,现在期望我们的矩阵M这样进行分解: 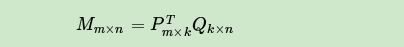 我们知道SVD分解已经很成熟了,但是FunkSVD如何将矩阵M分解为P和Q呢? 这里采用了线性回归的思想。我们的目标是让用户的评分和用矩阵乘积得到的评分残差尽可能的小,也就是说,可以用均方差作为损失函数,来寻找最终的P和Q。   通过迭代我们最终可以得到P和Q,进而用于推荐。FunkSVD算法虽然思想很简单,但是在实际应用中效果非常好,这真是验证了大道至简。 2.4 BiasSVD算法用于推荐 在FunkSVD算法火爆之后,出现了很多FunkSVD的改进版算法。其中BiasSVD算是改进的比较成功的一种算法。 BiasSVD假设评分系统包括三部分的偏置因素:一些和用户物品无关的评分因素,用户有一些和物品无关的评分因素,称为用户偏置项。而物品也有一些和用户无关的评分因素,称为物品偏置项。这其实很好理解。比如一个垃圾山寨货评分不可能高,自带这种烂属性的物品由于这个因素会直接导致用户评分低,与用户无关。  通过迭代我们最终可以得到P和Q,进而用于推荐。BiasSVD增加了一些额外因素的考虑,因此在某些场景会比FunkSVD表现好。 2.5 SVD++算法用于推荐 SVD++算法在BiasSVD算法上进一步做了增强,这里它增加考虑用户的隐式反馈。   1.6 矩阵分解推荐方法小结 FunkSVD将矩阵分解用于推荐方法推到了新的高度,在实际应用中使用也是非常广泛。当然矩阵分解方法也在不停的进步,目前张量分解和分解机方法是矩阵分解推荐方法今后的一个趋势。 对于矩阵分解用于推荐方法本身来说,它容易编程实现,实现复杂度低,预测效果也好,同时还能保持扩展性。这些都是它宝贵的优点。当然,矩阵分解方法有时候解释性还是没有基于概率的逻辑回归之类的推荐算法好,不过这也不影响它的流行程度。 小的推荐系统用矩阵分解应该是一个不错的选择。大型的话,则矩阵分解比起现在的深度学习的一些方法不占优势。 3 SimRank协同过滤推荐算法用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法。现在我们就对SimRank算法在推荐系统的应用做一个总结。 3.1 SimRank推荐算法的图论基础 SimRank是基于图论的,如果用于推荐算法,则它假设用户和物品在空间中形成了一张图。而这张图是一个二部图。所谓二部图就是图中的节点可以分成两个子集,而图中任意一条边的两个端点分别来源于这两个子集。 一个二部图的例子如下图。从图中也可以看出,二部图的子集内部没有边连接。对于我们的推荐算法中的SimRank,则二部图中的两个子集可以是用户子集和物品子集。而用户和物品之间的一些评分数据则构成了我们的二部图的边。  3.2 SimRank推荐算法思想 对于用户和物品构成的二部图,如何进行推荐呢? SimRank算法的思想是,如果两个用户相似,则与这两个用户相关联的物品也类似;如果两个物品类似,则与这两个物品相关联的用户也类似。如果回到上面的二部图,假设上面的节点代表用户子集,而下面节点代表物品子集。如果用户1和3类似,那么我们可以说和它们分别相连的物品2和4也类似。 如果我们的二部图是G(V,E),其中V是节点集合,E是边集合。则某一个子集内两个点的相似度s(a,b)可以用和相关联的另一个子集节点之间相似度表示。即:    上面的式子可以继续转化为:  但是由于节点和自己的相似度为1,即我们的矩阵S的对角线上的值都应该改为1,那么我们可以去掉对角线上的值,再加上单位矩阵,得到对角线为1的相似度矩阵。即:  只要我们对S矩阵按照上式进行若干轮迭代,当S矩阵的值基本稳定后我们就得到了二部图的相似度矩阵,进而可以利用用户与用户的相似度度量,物品与物品的相似度度量进行有针对性的推荐。 3.3 SimRank算法流程 对SimRank算法流程做一个总结。 输入:二部图对应的转移矩阵W,阻尼常数C,最大迭代次数k 输出:子集相似度矩阵S  以上基于普通的SimRank算法流程。当然,SimRank算法有很多变种,所以你可能看到其他地方的SimRank算法描述或者迭代的过程和上面的有些不同,但是算法思想基本和上面相同。 SimRank算法有很多改进变种,比较著名的一个改进是SimRank++算法。 3.4 SimRank++算法原理 SimRank++算法对SimRank算法主要做了两点改进。 第一点是考虑了边的权值,第二点是考虑了子集节点相似度的证据。 对于第一点边的权值,上面的SimRank算法,我们对于边的归一化权重,我们是用的比较笼统的关联的边数分之一来度量,并没有考虑不同的边可能有不同的权重度量,而SimRank++算法则在构建转移矩阵W时会考虑不同的边的不同权重值这个因素。 对于第二点的节点相似度的证据。回顾回顾上面的SimRank算法,我们只要认为有边相连,则为相似。却没有考虑到如果共同相连的边越多,则意味着两个节点的相似度会越高。而SimRank++算法利用共同相连的边数作为证据,在每一轮迭代过程中,对SimRank算法计算出来的节点相似度进行修正,即乘以对应的证据值得到当前轮迭代的的最终相似度值。 3.5 SimRank系列算法的求解 由于SimRank算法涉及矩阵运算,如果用户和物品量非常大,则对应的计算量是非常大的。如果直接用我们第二节讲到了迭代方法去求解,所花的时间会很长。对于这个问题,除了传统的一些SimRank求解优化以外,常用的有两种方法来加快求解速度。 第一种是利用大数据平台并行化,即利用Hadoop的MapReduce或者Spark来将矩阵运算并行化,加速算法的求解。 第二种是利用蒙特卡罗法(Monte Carlo, MC)模拟,将两结点间 SimRank 的相似度表示为两个随机游走者分别从结点 a和 b出发到最后相遇的总时间的期望函数。用这种方法时间复杂度会大大降低,但是由于MC带有一定的随机性,因此求解得到的结果的精度可能不高。 3.6 SimRank小结 作为基于图论的推荐算法,目前SimRank算法在广告推荐投放上使用很广泛。而图论作为一种非常好的建模工具,在很多算法领域都有广泛的应用,比如我之前讲到了谱聚类算法。同时,如果你理解了SimRank,那么Google的PageRank对你来说就更容易理解了。 4 用Spark学习矩阵分解推荐算法这里从实践的角度来用Spark学习矩阵分解推荐算法。 4.1 Spark推荐算法概述 在Spark MLlib中,推荐算法这块只实现了基于矩阵分解的协同过滤推荐算法。而基于的算法是FunkSVD算法,即将m个用户和n个物品对应的评分矩阵M分解为两个低维的矩阵: 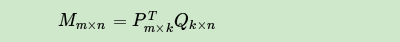 其中k为分解成低维的维数,一般远比m和n小。 4.2 Spark推荐算法类库介绍 在Spark MLlib中,实现的FunkSVD算法支持Python,Java,Scala和R的接口,本文的后面的介绍和使用也会使用MLlib的Python接口。 Spark MLlib推荐算法python对应的接口都在pyspark.mllib.recommendation包中,这个包有三个类,Rating, MatrixFactorizationModel和ALS。虽然里面有三个类,但是算法只是FunkSVD算法。下面介绍这三个类的用途。 Rating类比较简单,仅仅只是为了封装用户,物品与评分这3个值。也就是说,Rating类里面只有用户,物品与评分三元组, 并没有什么函数接口。 ALS负责训练我们的FunkSVD模型。之所以这儿用交替最小二乘法ALS表示,是因为Spark在FunkSVD的矩阵分解的目标函数优化时,使用的是ALS。ALS函数有两个函数,一个是train,这个函数直接使用我们的评分矩阵来训练数据,而另一个函数trainImplicit则稍微复杂一点,它使用隐式反馈数据来训练模型,和train函数相比,它多了一个指定隐式反馈信心阈值的参数,比如我们可以将评分矩阵转化为反馈数据矩阵,将对应的评分值根据一定的反馈原则转化为信心权重值。由于隐式反馈原则一般要根据具体的问题和数据来定,本文后面只讨论普通的评分矩阵分解。 MatrixFactorizationModel类是我们用ALS类训练出来的模型,这个模型可以帮助我们做预测。常用的预测有某一用户和某一物品对应的评分,某用户最喜欢的N个物品,某物品可能会被最喜欢的N个用户,所有用户各自最喜欢的N物品,以及所有物品被最喜欢的N个用户。 4.3 Spark推荐算法重要类参数 这里对ALS训练模型时的重要参数做一个总结。 1) ratings : 评分矩阵对应的RDD。需要我们输入。如果是隐式反馈,则是评分矩阵对应的隐式反馈矩阵。 2) rank : 矩阵分解时对应的低维的维数。即 P_{m\times k}^{T}Q_{k\times n} 中的维度k。这个值会影响矩阵分解的性能,越大则算法运行的时间和占用的内存可能会越多。通常需要进行调参,一般可以取10-200之间的数。 3) iterations :在矩阵分解用交替最小二乘法求解时,进行迭代的最大次数。这个值取决于评分矩阵的维度,以及评分矩阵的系数程度。一般来说,不需要太大,比如5-20次即可。默认值是5。 4) lambda: 在 python接口中使用的是lambda_,原因是lambda是Python的保留字。这个值即为FunkSVD分解时对应的正则化系数。主要用于控制模型的拟合程度,增强模型泛化能力。取值越大,则正则化惩罚越强。大型推荐系统一般需要调参得到合适的值。 5) alpha : 这个参数仅仅在使用隐式反馈trainImplicit时有用。指定了隐式反馈信心阈值,这个值越大则越认为用户和他没有评分的物品之间没有关联。一般需要调参得到合适值。 从上面的描述可以看出,使用ALS算法还是蛮简单的,需要注意调参的参数主要的是矩阵分解的维数rank, 正则化超参数lambda。如果是隐式反馈,还需要调参隐式反馈信心阈值alpha 。 4.4 Spark推荐算法实例 下面我们用一个具体的例子来讲述Spark矩阵分解推荐算法的使用。 这里我们使用MovieLens 100K的数据。 将数据解压后,我们只使用其中的u.data文件中的评分数据。这个数据集每行有4列,分别对应用户ID,物品ID,评分和时间戳。由于我的机器比较破,在下面的例子中,我只使用了前100条数据。因此如果你使用了所有的数据,后面的预测结果会与我的不同。 首先需要要确保你安装好了Hadoop和Spark(版本不小于1.6),并设置好了环境变量。一般我们都是在ipython notebook(jupyter notebook)中学习,所以最好把基于notebook的Spark环境搭好。当然不搭notebook的Spark环境也没有关系,只是每次需要在运行前设置环境变量。 如果你没有搭notebook的Spark环境,则需要先跑下面这段代码。当然,如果你已经搭好了,则下面这段代码不用跑了。  在跑算法之前,建议输出Spark Context如下,如果可以正常打印内存地址,则说明Spark的运行环境搞定了。  比如我的输出是: 首先将u.data文件读入内存,并尝试输出第一行的数据来检验是否成功读入,注意复制代码的时候,数据的目录要用你自己的u.data的目录。代码如下:  输出如下: u'196\t242\t3\t881250949'可以看到数据是用\t分开的,我们需要将每行的字符串划开,成为数组,并只取前三列,不要时间戳那一列。代码如下:  输出如下: [u'196', u'242', u'3']此时虽然我们已经得到了评分矩阵数组对应的RDD,但是这些数据都还是字符串,Spark需要的是若干Rating类对应的数组。因此我们现在将RDD的数据类型做转化,代码如下:  输出如下: Rating(user=196, product=242, rating=3.0)可见我们的数据已经是基于Rating类的RDD了,现在我们终于可以把整理好的数据拿来训练了,代码如下, 我们将矩阵分解的维度设置为20,最大迭代次数设置为5,而正则化系数设置为0.02。在实际应用中,我们需要通过交叉验证来选择合适的矩阵分解维度与正则化系数。这里我们由于是实例,就简化了。  将模型训练完毕后,我们终于可以来做推荐系统的预测了。 首先做一个最简单的预测,比如预测用户38对物品20的评分。代码如下:  输出如下: 0.311633491603可见评分并不高。 现在我们来预测了用户38最喜欢的10个物品,代码如下:  输出如下: [Rating(user=38, product=95, rating=4.995227969811873), Rating(user=38, product=304, rating=2.5159673379104484), Rating(user=38, product=1014, rating=2.165428673820349),可以看出用户38可能喜欢的对应评分从高到低的10个物品。 接着我们来预测下物品20可能最值得推荐的10个用户,代码如下:  输出如下: [Rating(user=115, product=20, rating=2.9892138653406635), Rating(user=25, product=20, rating=1.7558472892444517), Rating(user=7, product=20, rating=1.523935609195585),现在我们来看看每个用户最值得推荐的三个物品,代码如下:  由于输出非常长,这里就不将输出copy过来了。 而每个物品最值得被推荐的三个用户,代码如下:  同样由于输出非常长,这里就不将输出copy过来了。 以上是Spark矩阵分解推荐算法。 |
【本文地址】
今日新闻 |
推荐新闻 |