机器学习(概述一) |
您所在的位置:网站首页 › 简述统计学的概念 › 机器学习(概述一) |
机器学习(概述一)
|
何谓机器学习不同人的认知与人类认知过程的对比基本定义基本概念
机器学习能用来干吗机器学习的常见应用框架机器学习的分类基于学习形式分类基于目的分类
机器学习中的十大经典算法补充术语关系
总结
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
何谓机器学习
那究竟何谓机器学习呢?在给概念之前先来看几张图,看看不同人对机器学习的认识: 不同人的认知
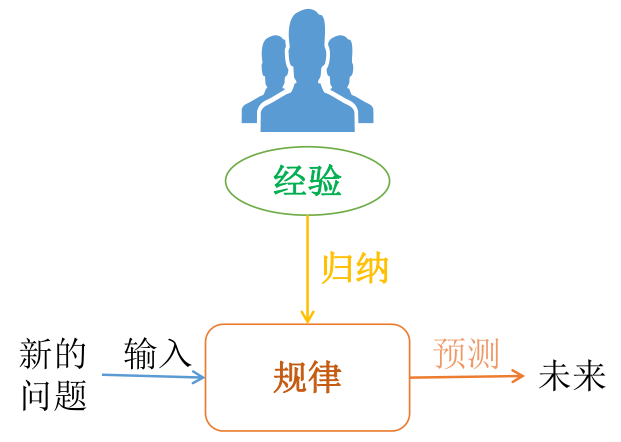
可见,不同人对机器学习的认识截然不同。正所谓外行看热闹,内行看门道,就像最后一张图,看似高大上的内容,在功能实现上,可能就需要一两行代码。 与人类认知过程的对比而真实的机器学习,其实跟人的认知过程是样的: 人们通过所经历事总结出规律,当遇到新的问题时,就可以运动规律就进行判断或预测。你的阅历越丰富,你可能会走得越远。想到韩雪说过的一句话:“喜欢看过世界的男生,不喜欢对世界还蠢蠢欲动的男生”。 而机器学习的基础是数据,通过对历史数据总结出规律(这个规律在机器学习中叫模型,总结的过程用到的是算法),当遇到新数据时,就可以模型进行预测: 通过上面的大概认真,现在给出机器学习的基本定义: Machine Learning(ML) is a scientific discipline that deals with the construction and study of algorithms that can learn from data. 机器学习是一门从数据中研究算法的科学学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。就像上面说的,直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测。 基本概念
比如说预测房价,我们根据房源的一些信息,通过机器学习的算法,得到一个函数 g ,当有一个新的房源,代入到函数中,就可以得到它的房价。 因为真实的目标函数 f 是未知的无法得到的,根本不可能通过机器学习找到这个完美的函数 f,我们只是找到了一个假设公式 g ,通过机器学习算法达到的最优假设,使其非常接近目标函数 f 的效果。 模型的好坏,需要进行评估(评估相关的内容,下一篇文章会进行介绍),效果不好话,需要再次进行训练。随着训练次数的增加,该系统可以在性能上不断学习和改进。 算 法 模 型 评 估 机器学习能用来干吗 个性化推荐:个性化指的是根据各种因素来改变用户体验和呈现给用户内容,这些因素可能包含用户的行为数据和外部因素;推荐常指系统向用户呈现一个用户可能感兴趣的物品列表。比如刷抖音,我们会发现,怎么某些类型(像美食)的内容特别多呢?其实就是根据你的操作数据(点赞量、评论量、转发量、完播率等),认为你可能对美食等类型的内容感兴趣,因此会更多的推荐相关的内容。精准营销:从用户群众中找出特定的要求的营销对象。客户细分:试图将用户群体分为不同的组,根据给定的用户特征进行客户分组。比如你打算去银行贷款,银行会根据你的个人信息、信用卡使用情况等判断你是否有还款能力,决定是否贷给你钱。预测建模及分析:根据已有的数据进行建模,并使用得到的模型预测未来。当然,机器学习还能做一些听起来更高大上的事: 机器学习的使用场景
机器学习的常见应用框架
机器学习的使用场景
机器学习的常见应用框架
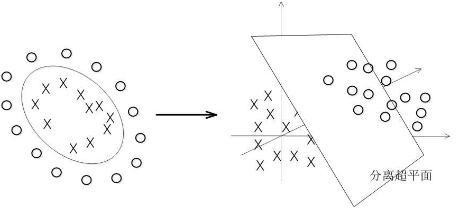
因为常用的算法都封装好,多数情况下使用相应的框架就能实现,很少有自己手写某某算法。就像文章开始时“What I really do”的那张图,我们想使用SVM(一种机器学习算法)这个算法,只需引入进来即可。 sciket-learn scikit-learn(简记sklearn),是用python实现的机器学习算法库。sklearn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法,并且易于安装与使用。sklearn是基于NumPy, SciPy, matplotlib的。一般用于相对小规模数据量的。 网址:http://scikit-learn.org/stable/
Mahout Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,使用了Taste来提高协同过滤算法的实现,它是一个基于Java实现的可扩展的,高效的推荐引擎。Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。主要用于大规模数据量。(没用过这个,就从其他地方抄来的这段话) 网址:http://mahout.apache.org/ Spark MLlib MLlib是Spark的机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。主要用于大规模数据量。(没用过这个,同样也从其他地方抄来的这段话) 网址:http://spark.apache.org/mllib/ 机器学习的分类机器学习有多种分类角度,像什么基于学习策略的分类、基于所获取知识的表示形式分类、基于应用领域分类等等。这里只提两种比较觉的分类: 基于学习形式分类有监督学习 在监督学习的过程中,我们只需要给定输入样本集,机器就可以从中推演出指定目标变量的可能结果。监督学习相对比较简单,机器只需从输入数据中预测合适的模型,并从中计算出目标变量的结果。 监督学习一般使用两种类型的目标变量 :标称型(也叫离散型)和数值型(也叫连续型)。标称型目标变量的结果只在有限目标集中取值,如真与假、动物分类集合 { 爬行类、鱼类、哺乳类、两栖类 } ;数值型目标变量则可以从无限的数值集合中取值,如 0.100、42.001、1000.743 等。数值型目标变量主要用于回归分析。 有监督学习根据生成模型的方式又可分为判别式模型和生成式模型 1.1 判别式模型:直接对条件概率p(y|x)进行建模,常见判别模型有线性回归、决策树、支持向量机SVM、k近邻、神经网络等; 1.2 生成式模型:对联合分布概率p(x,y)进行建模,常见生成式模型有隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等。 生成式模型更普适;判别式模型更直接,目标性更强。 生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的差异性,寻找的是分类面。 由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型。 无监督学习 监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。 与有监督学习“对于输入数据 X 能预测变量 Y”不同的是,这里要回答的问题是 :“从数据 X 中能发现什么?” 这里需要回答的 X 方面的问题可能是 :“构成 X 的最佳 6 个数据簇都是哪些?”或者“X 中哪三个特征最频繁共现?” 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。 半监督学习 考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习和无监督学习的结合。 主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。 缺点:抗干扰能力弱,仅适合于实验室环境,其现实意义还没有体现出来;未来 的发展主要是聚焦于新模型假设的产生。 基于目的分类 分类 通过分类模型,将样本数据集中的样本映射到某个给定的类别中聚类 通过聚类模型,将样本数据集中的样本分为几个类别,属于同一类别的样本相似性比较大回归 反映了样本数据集中样本的属性值的特性,通过函数表达样本映射的关系来发现属性值之间的依赖关系关联规则 获取隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现频率。分类和回归属于有监督学习,而聚类和关联规则属于无监督学习: 回归与分类的不同,就在于其目标变量是连续数值型。聚类就是将相似项聚团,关联分析可以用于回答“哪些物品经常被同时购买?”之类的问题。 机器学习中的十大经典算法 算法名称算法描述C4.5分类决策树算法,决策树的核心算法,ID3算法的改进算法CART分类与回归树(Classification and Regression Trees),决策树的变种,可做回归kNNK近邻分类算法;如果一个样本在特征空间中的k个最相似的样本中大多数属于某一个类别,那么该样本也属于该类别。简单来说就是:近朱者赤,近墨者黑NaiveBayes贝叶斯分类模型;一般用于文本数据,要求属性(特征)间相关性小,如果相关性大的话,用决策树更好(原因:贝叶斯模型假设属性之间是互不影响的)SVM支持向量机,一种有监督学习的统计学习方法,广泛应用于统计分类和回归分析中EM最大期望算法,常用于机器学习和计算机视觉中的数据集聚领域Apriori关联规则挖掘算法K-Means聚类算法,是最大似然估计上的一个提升,功能是将n个对象根据属性特征分为k个分割(k |



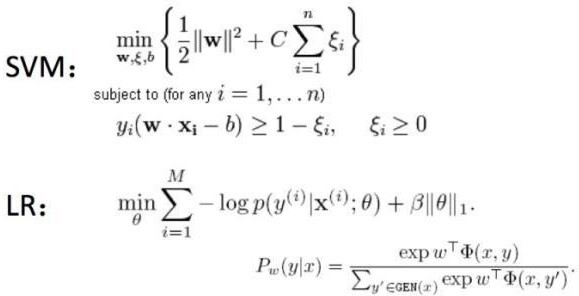

 可看出,跟我们初高中学的函数是一样的,就是通过一些手段进行训练找到这个函数 g(也就是模型),当有新数据 x 时,代入函数 g 就可以得到 y 。(当然这里是以有监督学习为例说的,毕竟机器学习主要还是以有监督学习为主;对于无监督学习相当于只有 x ,没有 y)
可看出,跟我们初高中学的函数是一样的,就是通过一些手段进行训练找到这个函数 g(也就是模型),当有新数据 x 时,代入函数 g 就可以得到 y 。(当然这里是以有监督学习为例说的,毕竟机器学习主要还是以有监督学习为主;对于无监督学习相当于只有 x ,没有 y)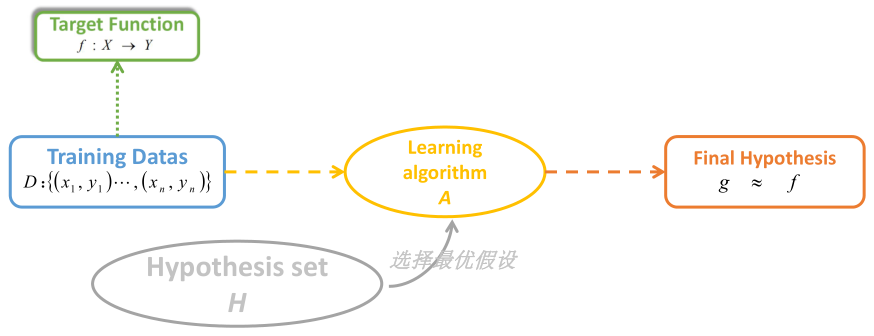

【本文地址】
今日新闻 |
推荐新闻 |