一文述说人工智能(AI)发展史,几经沉浮! |
您所在的位置:网站首页 › 简述人工智能的未来 › 一文述说人工智能(AI)发展史,几经沉浮! |
一文述说人工智能(AI)发展史,几经沉浮!
|
人工智能将和电力一样具有颠覆性 。 --吴恩达
本文从介绍人工智能及主要的思想派系,进一步系统地梳理了其发展历程、标志性成果并侧重其算法思想介绍,将这段 60余年几经沉浮的历史,以一个清晰的脉络呈现出来,以此展望人工智能(AI)未来的趋势。 一、人工智能简介 1.1 人工智能研究目的人工智能(Artificial Intelligence,AI)研究目的是通过探索智慧的实质,扩展人类智能——促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。(A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation)” 1.2 人工智能的学派在人工智能的发展过程中,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的思想主张,并由此衍生了不同的学派,影响较大的学派及其代表方法如下: 其中,符号主义及联结主义为主要的两大派系: “符号主义”(Symbolicism),又称逻辑主义、计算机学派,认为认知就是通过对有意义的表示符号进行推导计算,并将学习视为逆向演绎,主张用显式的公理和逻辑体系搭建人工智能系统。如用决策树模型输入业务特征预测天气: “联结主义”(Connectionism),又叫仿生学派,笃信大脑的逆向工程,主张是利用数学模型来研究人类认知的方法,用神经元的连接机制实现人工智能。如用神经网络模型输入雷达图像数据预测天气: 从始至此,人工智能(AI)便在充满未知的道路探索,曲折起伏,我们可将这段发展历程大致划分为5个阶段期: 起步发展期:1943年—20世纪60年代反思发展期:20世纪70年代应用发展期:20世纪80年代平稳发展期:20世纪90年代—2010年蓬勃发展期:2011年至今
人工智能概念的提出后,发展出了符号主义、联结主义(神经网络),相继取得了一批令人瞩目的研究成果,如机器定理证明、跳棋程序、人机对话等,掀起人工智能发展的第一个高潮。 1943年,美国神经科学家麦卡洛克(Warren McCulloch)和逻辑学家皮茨(Water Pitts)提出神经元的数学模型,这是现代人工智能学科的奠基石之一。 1950年,艾伦·麦席森·图灵(Alan Mathison Turing)提出“图灵测试”(测试机器是否能表现出与人无法区分的智能),让机器产生智能这一想法开始进入人们的视野。 1950年,克劳德·香农(Claude Shannon)提出计算机博弈。 1956年,达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。 1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。
LR是类似于感知机结构的线性分类判别模型,主要不同在于神经元的激活函数f为sigmoid,模型的目标为(最大似然)极大化正确分类概率。 1959年,Arthur Samuel给机器学习了一个明确概念:Field of study that gives computers the ability to learn without being explicitly programmed.(机器学习是研究如何让计算机不需要显式的程序也可以具备学习的能力)。 1961年,Leonard Merrick Uhr 和 Charles M Vossler发表了题目为A Pattern Recognition Program That Generates, Evaluates and Adjusts its Own Operators 的模式识别论文,该文章描述了一种利用机器学习或自组织过程设计的模式识别程序的尝试。 1965年,古德(I. J. Good)发表了一篇对人工智能未来可能对人类构成威胁的文章,可以算“AI威胁论”的先驱。他认为机器的超级智能和无法避免的智能爆炸最终将超出人类可控范畴。后来著名科学家霍金、发明家马斯克等人对人工智能的恐怖预言跟古德半个世界前的警告遥相呼应。 1966 年,麻省理工学院科学家Joseph Weizenbaum 在 ACM 上发表了题为《ELIZA-a computer program for the study of natural language communication between man and machine》文章描述了ELIZA 的程序如何使人与计算机在一定程度上进行自然语言对话成为可能,ELIZA 的实现技术是通过关键词匹配规则对输入进行分解,而后根据分解规则所对应的重组规则来生成回复。 1967年,Thomas等人提出K最近邻算法(The nearest neighbor algorithm)。 KNN的核心思想,即给定一个训练数据集,对新的输入实例Xu,在训练数据集中找到与该实例最邻近的K个实例,以这K个实例的最多数所属类别作为新实例Xu的类别。
人工智能发展初期的突破性进展大大提升了人们对人工智能的期望,人们开始尝试更具挑战性的任务,然而计算力及理论等的匮乏使得不切实际目标的落空,人工智能的发展走入低谷。 1974年,哈佛大学沃伯斯(Paul Werbos)博士论文里,首次提出了通过误差的反向传播(BP)来训练人工神经网络,但在该时期未引起重视。BP算法的基本思想不是(如感知器那样)用误差本身去调整权重,而是用误差的导数(梯度)调整。通过误差的梯度做反向传播,更新模型权重, 以下降学习的误差,拟合学习目标,实现’网络的万能近似功能’的过程。 1975年,马文·明斯基(Marvin Minsky)在论文《知识表示的框架》(A Framework for Representing Knowledge)中提出用于人工智能中的知识表示学习框架理论。 1976年,兰德尔·戴维斯(Randall Davis)构建和维护的大规模的知识库,提出使用集成的面向对象模型可以提高知识库(KB)开发、维护和使用的完整性。 1976年,斯坦福大学的肖特利夫(Edward H. Shortliffe)等人完成了第一个用于血液感染病的诊断、治疗和咨询服务的医疗专家系统MYCIN。 1976年,斯坦福大学的博士勒纳特发表论文《数学中发现的人工智能方法——启发式搜索》,描述了一个名为“AM”的程序,在大量启发式规则的指导下开发新概念数学,最终重新发现了数百个常见的概念和定理。 1977年,海斯·罗思(Hayes. Roth)等人的基于逻辑的机器学习系统取得较大的进展,但只能学习单一概念,也未能投入实际应用。 1979年,汉斯·贝利纳(Hans Berliner)打造的计算机程序战胜双陆棋世界冠军成为标志性事件。(随后,基于行为的机器人学在罗德尼·布鲁克斯和萨顿等人的推动下快速发展,成为人工智能一个重要的发展分支。格瑞·特索罗等人打造的自我学习双陆棋程序又为后来的强化学习的发展奠定了基础。) 2.3 应用发展期:20世纪80年代人工智能走入应用发展的新高潮。专家系统模拟人类专家的知识和经验解决特定领域的问题,实现了人工智能从理论研究走向实际应用、从一般推理策略探讨转向运用专门知识的重大突破。而机器学习(特别是神经网络)探索不同的学习策略和各种学习方法,在大量的实际应用中也开始慢慢复苏。 1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。 1980年,德鲁·麦狄蒙(Drew McDermott)和乔恩·多伊尔(Jon Doyle)提出非单调逻辑,以及后期的机器人系统。 1980年,卡耐基梅隆大学为DEC公司开发了一个名为XCON的专家系统,每年为公司节省四千万美元,取得巨大成功。 1981年,保罗(R.P.Paul)出版第一本机器人学课本,“Robot Manipulator:Mathematics,Programmings and Control”,标志着机器人学科走向成熟。 1982年,马尔(David Marr)发表代表作《视觉计算理论》提出计算机视觉(Computer Vision)的概念,并构建系统的视觉理论,对认知科学(CognitiveScience)也产生了很深远的影响。 1982年,约翰·霍普菲尔德(John Hopfield) 发明了霍普菲尔德网络,这是最早的RNN的雏形。霍普菲尔德神经网络模型是一种单层反馈神经网络(神经网络结构主要可分为前馈神经网络、反馈神经网络及图网络),从输出到输入有反馈连接。它的出现振奋了神经网络领域,在人工智能之机器学习、联想记忆、模式识别、优化计算、VLSI和光学设备的并行实现等方面有着广泛应用。 1983年,Terrence Sejnowski, Hinton等人发明了玻尔兹曼机(Boltzmann Machines),也称为随机霍普菲尔德网络,它本质是一种无监督模型,用于对输入数据进行重构以提取数据特征做预测分析。 1985年,朱迪亚·珀尔提出贝叶斯网络(Bayesian network),他以倡导人工智能的概率方法和发展贝叶斯网络而闻名,还因发展了一种基于结构模型的因果和反事实推理理论而受到赞誉。 贝叶斯网络是一种模拟人类推理过程中因果关系的不确定性处理模型,如常见的朴素贝叶斯分类算法就是贝叶斯网络最基本的应用。 1986年,罗德尼·布鲁克斯(Brooks)发表论文《移动机器人鲁棒分层控制系统》,标志着基于行为的机器人学科的创立,机器人学界开始把注意力投向实际工程主题。 1986年,辛顿(Geoffrey Hinton)等人先后提出了多层感知器(MLP)与反向传播(BP)训练相结合的理念(该方法在当时计算力上还是有很多挑战,基本上都是和链式求导的梯度算法相关的),这也解决了单层感知器不能做非线性分类的问题,开启了神经网络新一轮的高潮。 1986年,昆兰(Ross Quinlan)提出ID3决策树算法。 决策树模型可视为多个规则(if, then)的组合,与神经网络黑盒模型截然不同是,它拥有良好的模型解释性。
卷积神经网络通常由输入层、卷积层、池化(Pooling)层和全连接层组成。卷积层负责提取图像中的局部特征,池化层用来大幅降低参数量级(降维),全连接层类似传统神经网络的部分,用来输出想要的结果。 由于互联网技术的迅速发展,加速了人工智能的创新研究,促使人工智能技术进一步走向实用化,人工智能相关的各个领域都取得长足进步。在2000年代初,由于专家系统的项目都需要编码太多的显式规则,这降低了效率并增加了成本,人工智能研究的重心从基于知识系统转向了机器学习方向。 1995年,Cortes和Vapnik提出联结主义经典的支持向量机(Support Vector Machine),它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
Adaboost迭代算法基本思想主要是通过调节的每一轮各训练样本的权重(错误分类的样本权重更高),串行训练出不同分类器。最终以各分类器的准确率作为其组合的权重,一起加权组合成强分类器。 1997年国际商业机器公司(简称IBM)深蓝超级计算机战胜了国际象棋世界冠军卡斯帕罗夫。深蓝是基于暴力穷举实现国际象棋领域的智能,通过生成所有可能的走法,然后执行尽可能深的搜索,并不断对局面进行评估,尝试找出最佳走法。 1997年,Sepp Hochreiter 和 Jürgen Schmidhuber提出了长短期记忆神经网络(LSTM)。
1998年,万维网联盟的蒂姆·伯纳斯·李(Tim Berners-Lee)提出语义网(Semantic Web)的概念。其核心思想是:通过给万维网上的文档(如HTML)添加能够被计算机所理解的语义(Meta data),从而使整个互联网成为一个基于语义链接的通用信息交换媒介。换言之,就是构建一个能够实现人与电脑无障碍沟通的智能网络。 2001年,John Lafferty首次提出条件随机场模型(Conditional random field,CRF)。 CRF是基于贝叶斯理论框架的判别式概率图模型,在给定条件随机场P ( Y ∣ X ) 和输入序列x,求条件概率最大的输出序列y *。在许多自然语言处理任务中比如分词、命名实体识别等表现尤为出色。 2001年,布雷曼博士提出随机森林(Random Forest)。 随机森林是将多个有差异的弱学习器(决策树)Bagging并行组合,通过建立多个的拟合较好且有差异模型去组合决策,以优化泛化性能的一种集成学习方法。多样差异性可减少对某些特征噪声的依赖,降低方差(过拟合),组合决策可消除些学习器间的偏差。 随机森林算法的基本思路是对于每一弱学习器(决策树)有放回的抽样构造其训练集,并随机抽取其可用特征子集,即以训练样本及特征空间的多样性训练出N个不同的弱学习器,最终结合N个弱学习器的预测(类别或者回归预测数值),取最多数类别或平均值作为最终结果。 LDA是一种无监督方法,用来推测文档的主题分布,将文档集中每篇文档的主题以概率分布的形式给出,可以根据主题分布进行主题聚类或文本分类。 2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础。 2005 年,波士顿动力公司推出一款动力平衡四足机器狗,有较强的通用性,可适应较复杂的地形。 2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念(Deeping Learning),开启了深度学习在学术界和工业界的浪潮。2006年也被称为深度学习元年,杰弗里·辛顿也因此被称为深度学习之父。 深度学习的概念源于人工神经网络的研究,它的本质是使用多个隐藏层网络结构,通过大量的向量计算,学习数据内在信息的高阶表示。 迁移学习(transfer learning)通俗来讲,就是运用已有的知识(如训练好的网络权重)来学习新的知识以适应特定目标任务,核心是找到已有知识和新知识之间的相似性。 随着大数据、云计算、互联网、物联网等信息技术的发展,泛在感知数据和图形处理器等计算平台推动以深度神经网络为代表的人工智能技术飞速发展,大幅跨越了科学与应用之间的技术鸿沟,诸如图像分类、语音识别、知识问答、人机对弈、无人驾驶等人工智能技术实现了重大的技术突破,迎来爆发式增长的新高潮。 2011年,IBM Watson问答机器人参与Jeopardy回答测验比赛最终赢得了冠军。Waston是一个集自然语言处理、知识表示、自动推理及机器学习等技术实现的电脑问答(Q&A)系统。 2012年,Hinton和他的学生Alex Krizhevsky设计的AlexNet神经网络模型在ImageNet竞赛大获全胜,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。 AlexNet是一个经典的CNN模型,在数据、算法及算力层面均有较大改进,创新地应用了Data Augmentation、ReLU、Dropout和LRN等方法,并使用GPU加速网络训练。 
知识图谱是结构化的语义知识库,是符号主义思想的代表方法,用于以符号形式描述物理世界中的概念及其相互关系。其通用的组成单位是RDF三元组(实体-关系-实体),实体间通过关系相互联结,构成网状的知识结构。 VAE基本思路是将真实样本通过编码器网络变换成一个理想的数据分布,然后把数据分布再传递给解码器网络,构造出生成样本,模型训练学习的过程是使生成样本与真实样本足够接近。 
Word2Vec基本的思想是学习每个单词与邻近词的关系,从而将单词表示成低维稠密向量。通过这样的分布式表示可以学习到单词的语义信息,直观来看,语义相似的单词的距离相近。 2014年,聊天程序“尤金·古斯特曼”(Eugene Goostman)在英国皇家学会举行的“2014图灵测试”大会上,首次“通过”了图灵测试。 2014年,Goodfellow及Bengio等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。 GAN是基于强化学习(RL)思路设计的,由生成网络(Generator, G)和判别网络(Discriminator, D)两部分组成, 生成网络构成一个映射函数G: Z→X(输入噪声z, 输出生成的伪造数据x), 判别网络判别输入是来自真实数据还是生成网络生成的数据。在这样训练的博弈过程中,提高两个模型的生成能力和判别能力。 《Deep learning》文中指出深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次及抽象的表达,能够强化输入数据的区分能力。通过足够多的转换的组合,非常复杂的函数也可以被学习。 残差网络的主要贡献是发现了网络不恒等变换导致的“退化现象(Degradation)”,并针对退化现象引入了 “快捷连接(Shortcut connection)”,缓解了在深度神经网络中增加深度带来的梯度消失问题。 2015年,谷歌开源TensorFlow框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。 2015年,马斯克等人共同创建OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT等。 2016年,谷歌提出联邦学习方法,它在多个持有本地数据样本的分散式边缘设备或服务器上训练算法,而不交换其数据样本。 联邦学习保护隐私方面最重要的三大技术分别是: 差分隐私 ( Differential Privacy )、同态加密 ( Homomorphic Encryption )和 隐私保护集合交集 ( Private Set Intersection ),能够使多个参与者在不共享数据的情况下建立一个共同的、强大的机器学习模型,从而解决数据隐私、数据安全、数据访问权限和异构数据的访问等关键问题。 AlphaGo是一款围棋人工智能程序,其主要工作原理是“深度学习”,由以下四个主要部分组成:策略网络(Policy Network)给定当前局面,预测并采样下一步的走棋;快速走子(Fast rollout)目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快1000倍;价值网络(Value Network)估算当前局面的胜率;蒙特卡洛树搜索(Monte Carlo Tree Search)树搜索估算每一种走法的胜率。 2017年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,是历史上首个获得公民身份的一台机器人。索菲亚看起来就像人类女性,拥有橡胶皮肤,能够表现出超过62种自然的面部表情。其“大脑”中的算法能够理解语言、识别面部,并与人进行互动。 2018年,Google提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。 BERT是一个预训练的语言表征模型,可在海量的语料上用无监督学习方法学习单词的动态特征表示。它基于Transformer注意力机制的模型,对比RNN可以更加高效、能捕捉更长距离的依赖信息,且不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。 2019年, IBM宣布推出Q System One,它是世界上第一个专为科学和商业用途设计的集成通用近似量子计算系统。 2019年,香港 Insilico Medicine 公司和多伦多大学的研究团队实现了重大实验突破,通过深度学习和生成模型相关的技术发现了几种候选药物,证明了 AI 发现分子策略的有效性,很大程度解决了传统新药开发在分子鉴定困难且耗时的问题。 2020年,Google与Facebook分别提出SimCLR与MoCo两个无监督学习算法,均能够在无标注数据上学习图像数据表征。两个算法背后的框架都是对比学习(contrastive learning),对比学习的核心训练信号是图片的“可区分性”。 2020年,OpenAI开发的文字生成 (text generation) 人工智能GPT-3,它具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍,该模型经过了将近0.5万亿个单词的预训练,可以在多个NLP任务(答题、翻译、写文章)基准上达到最先进的性能。 2020年,马斯克的脑机接口(brain–computer interface, BCI)公司Neuralink举行现场直播,展示了植入Neuralink设备的实验猪的脑部活动。 2020年,谷歌旗下DeepMind的AlphaFold2人工智能系统有力地解决了蛋白质结构预测的里程碑式问题。它在国际蛋白质结构预测竞赛(CASP)上击败了其余的参会选手,精确预测了蛋白质的三维结构,准确性可与冷冻电子显微镜(cryo-EM)、核磁共振或 X 射线晶体学等实验技术相媲美。 2020年,中国科学技术大学潘建伟等人成功构建76个光子的量子计算原型机“九章”,求解数学算法“高斯玻色取样”只需200秒,而目前世界最快的超级计算机要用6亿年。 2021年,OpenAI提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。 2021年,德国Eleuther人工智能公司于今年3月下旬推出开源的文本AI模型GPT-Neo。对比GPT-3的差异在于它是开源免费的。 2021年,美国斯坦福大学的研究人员开发出一种用于打字的脑机接口(brain–computer interface, BCI),这套系统可以从运动皮层的神经活动中解码瘫痪患者想象中的手写动作,并利用递归神经网络(RNN)解码方法将这些手写动作实时转换为文本。相关研究结果发表在2021年5月13日的Nature期刊上,论文标题为“High-performance brain-to-text communication via handwriting”。 人工智能有三个要素:数据、算力及算法,数据即是知识原料,算力及算法提供“计算智能”以学习知识并实现特定目标。 数据是现实世界映射构建虚拟世界的基本要素,随着数据量以指数形式增长,开拓的虚拟世界的疆土也不断扩张。不同于AI算法开源,关键数据往往是不开放的,数据隐私化、私域化是一种趋势,数据之于AI应用,如同流量是互联网的护城河,有核心数据才有关键的AI能力。 推理就是计算(reason is nothing but reckoning) --托马斯.霍布斯 计算是AI的关键,自2010年代以来的深度学习浪潮,很大程度上归功于计算能力的进步。 量子计算发展在计算芯片按摩尔定律发展越发失效的今天,计算能力进步的放慢会限制未来的AI技,量子计算提供了一条新量级的增强计算能力的思路。随着量子计算机的量子比特数量以指数形式增长,而它的计算能力是量子比特数量的指数级,这个增长速度将远远大于数据量的增长,为数据爆发时代的人工智能带来了强大的硬件基础。 边缘计算作为云计算的一种补充和优化,一部分的人工智能正在加快速度从云端走向边缘,进入到越来越小的物联网设备中。而这些物联网设备往往体积很小,为此轻量机器学习(TinyML)受到青睐,以满足功耗、延时以及精度等问题。 类脑计算发展以类脑计算芯片为核心的各种类脑计算系统,在处理某些智能问题以及低功耗智能计算方面正逐步展露出优势。类脑计算芯片设计将从现有处理器的设计方法论及其发展历史中汲取灵感,在计算完备性理论基础上结合应用需求实现完备的硬件功能。同时类脑计算基础软件将整合已有类脑计算编程语言与框架,实现类脑计算系统从“专用”向“通用”的逐步演进。 人工智能计算中心成为智能化时代的关键基础设施人工智能计算中心基于最新人工智能理论,采用领先的人工智能计算架构,是融合公共算力服务、数据开放共享、智能生态建设、产业创新聚集的“四位一体”综合平台,可提供算力、数据和算法等人工智能全栈能力,是人工智能快速发展和应用所依托的新型算力基础设施。未来,随着智能化社会的不断发展,人工智能计算中心将成为关键的信息基础设施,推动数字经济与传统产业深度融合,加速产业转型升级,促进经济高质量发展。 3.3 算法层面 机器学习自动化(AutoML)发展自动化机器学习(AutoML)解决的核心问题是:在给定数据集上使用哪种机器学习算法、是否以及如何预处理其特征以及如何设置所有超参数。随着机器学习在许多应用领域取得了长足的进步,这促成了对机器学习系统的不断增长的需求,并希望机器学习应用可以自动化构建并使用。借助AutoMl、MLOps技术,将大大减少机器学习人工训练及部署过程,技术人员可以专注于核心解决方案。 当前全球多个国家和地区已出台数据监管法规,如HIPAA(美国健康保险便利和责任法案)、GDPR(欧盟通用数据保护条例)等,通过严格的法规限制多机构间隐私数据的交互。分布式隐私保护机器学习(联邦学习)通过加密、分布式存储等方式保护机器学习模型训练的输入数据,是打破数据孤岛、完成多机构联合训练建模的可行方案。 数据和机理融合AI模型的发展是符合简单而美的定律的。从数据出发的建模从数据中总结规律,追求在实践中的应用效果。从机理出发的建模以基本物理规律为出发点进行演绎,追求简洁与美的表达。 一个好的、主流的的模型,通常是高度总结了数据规律并切合机理的,是“优雅”的,因为它触及了问题的本质。就和科学理论一样,往往简洁的,没有太多补丁,而这同时解决了收敛速度问题和泛化问题。 神经网络模型结构发展神经网络的演进一直沿着模块化+层次化的方向,不断把多个承担相对简单任务的模块组合起来。 神经网络结构通过较低层级模块侦测基本的特征,并在较高层级侦测更高阶的特征,无论是多层前馈网络,还是卷积神经网络,都体现了这种模块性(近年Hinton提出的“胶囊”(capsule)网络就是进一步模块化发展)。因为我们处理的问题(图像、语音、文字)往往都有天然的模块性,学习网络的模块性若匹配了问题本身内在的模块性,就能取得较好的效果。 层次化并不仅仅是网络的拓扑叠加,更重要的是学习算法的升级,仅仅简单地加深层次可能会导致BP网络的梯度消失等问题。 多学派方法融合发展通过多学派方法交融发展,得以互补算法之间的优势和弱点。如 1)贝叶斯派与神经网络融合,Neil Lawrence组的Deep Gaussian process, 用简单的概率分布替换神经网络层。2)符号主义、集成学习与神经网络的融合,周志华老师的深度随机森林。3) 符号主义与神经网络的融合:将知识库(KG)融入进神经网络,如GNN、知识图谱表示学习。4) 神经网络与强化学习的融合,如谷歌基于DNN+强化学习实现的Alpha Go 让AI的复杂任务表现逼近人类。 基于大规模无(自)监督预训练发展If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL) – Yann Lecun 监督学习需要足够的带标签数据,然而人工标注大量数据既耗时又费力,在一些领域(如医学领域)上几乎不太可能获得足量的标注数据。通过大规模无(自)监督预训练方法利用现实中大量的无标签数据是一个研究的热点,如GPT-3的出现激发了对大规模自监督预训练方法继续开展探索和研究。未来,基于大规模图像、语音、视频等多模态数据的跨语言的自监督预训练模型将进一步发展,并不断提升模型的认知、推理能力。 基于因果学习方法发展当前人工智能模型大多关注于数据特征间相关性,而相关性与更为本源的因果关系并不等价,可能导致预测结果的偏差,对抗攻击的能力不佳,且模型往往缺乏可解释性。另外,模型需要独立同分布(i.i.d.)假设(现实很多情况,i.i.d.的假设是不成立的),若测试数据与训练数据来自不同的分布,统计学习模型往往效果不佳,而因果推断所研究的正是这样的情形:如何学习一个可以在不同分布下工作、蕴含因果机制的因果模型(Causal Model),并使用因果模型进行干预或反事实推断。 可解释性AI (XAI)发展可解释的人工智能有可能成为未来机器学习的核心,随着模型变得越来越复杂,确定简单的、可解释的规则就会变得越来越困难。一个可以解释的AI(Explainable AI, 简称XAI)意味着AI运作的透明,便于人类对于对AI监督及接纳,以保证算法的公平性、安全性及隐私性。 随着数据、算力及算法取得不断的突破,人工智能可能进入一个永恒的春天。 本文主要从技术角度看待AI趋势是比较片面的,虽然技术是“高大上”的第一生产力,有着自身的发展规律,但不可忽视的是技术是为需求市场所服务的。技术结合稳定的市场需求,才是技术发展的实际导向。 文章首发于“算法进阶”,公众号阅读原文可访问Github博客 |
 如同蒸汽时代的蒸汽机、电气时代的发电机、信息时代的计算机和互联网,人工智能(AI)正赋能各个产业,推动着人类进入智能时代。
如同蒸汽时代的蒸汽机、电气时代的发电机、信息时代的计算机和互联网,人工智能(AI)正赋能各个产业,推动着人类进入智能时代。





 感知机可以被视为一种最简单形式的前馈式人工神经网络,是一种二分类的线性分类判别模型,其输入为实例的特征向量想(x1,x2…),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。
感知机可以被视为一种最简单形式的前馈式人工神经网络,是一种二分类的线性分类判别模型,其输入为实例的特征向量想(x1,x2…),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。

 专家系统(Expert Systems)是AI的一个重要分支,同自然语言理解,机器人学并列为AI的三大研究方向。它的定义是使用人类专家推理的计算机模型来处理现实世界中需要专家作出解释的复杂问题,并得出与专家相同的结论,可视作“知识库(knowledge base)”和“推理机(inference machine)” 的结合。
专家系统(Expert Systems)是AI的一个重要分支,同自然语言理解,机器人学并列为AI的三大研究方向。它的定义是使用人类专家推理的计算机模型来处理现实世界中需要专家作出解释的复杂问题,并得出与专家相同的结论,可视作“知识库(knowledge base)”和“推理机(inference machine)” 的结合。


 贝叶斯网络拓朴结构是一个有向无环图(DAG),通过把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,以描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)就形成了贝叶斯网络。 对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出。如图中b依赖于a(即:a->b),c依赖于a和b,a独立无依赖,根据贝叶斯定理有 P(a,b,c) = P(a)*P(b|a)*P(c|a,b)
贝叶斯网络拓朴结构是一个有向无环图(DAG),通过把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,以描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)就形成了贝叶斯网络。 对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出。如图中b依赖于a(即:a->b),c依赖于a和b,a独立无依赖,根据贝叶斯定理有 P(a,b,c) = P(a)*P(b|a)*P(c|a,b) 

 ID3算法核心的思想是通过自顶向下的贪心策略构建决策树:根据信息增益来选择特征进行划分(信息增益的含义是 引入属性A的信息后,数据D的不确定性减少程度。也就是信息增益越大,区分D的能力就越强),依次递归地构建决策树。
ID3算法核心的思想是通过自顶向下的贪心策略构建决策树:根据信息增益来选择特征进行划分(信息增益的含义是 引入属性A的信息后,数据D的不确定性减少程度。也就是信息增益越大,区分D的能力就越强),依次递归地构建决策树。 “万能近似定理”可视为神经网络的基本理论:⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。
“万能近似定理”可视为神经网络的基本理论:⼀个前馈神经⽹络如果具有线性层和⾄少⼀层具有 “挤压” 性质的激活函数(如 sigmoid 等),给定⽹络⾜够数量的隐藏单元,它可以以任意精度来近似任何从⼀个有限维空间到另⼀个有限维空间的 borel 可测函数。
 支持向量机(Support Vector Machine, SVM)可以视为在感知机基础上的改进,是建立在统计学习理论的VC维理论和结构风险最小原理基础上的广义线性分类器。与感知机主要差异在于:1、感知机目标是找到一个超平面将各样本尽可能分离正确(有无数个),SVM目标是找到一个超平面不仅将各样本尽可能分离正确,还要使各样本离超平面距离最远(只有一个最大边距超平面),SVM的泛化能力更强。2、对于线性不可分的问题,不同于感知机的增加非线性隐藏层,SVM利用核函数,本质上都是实现特征空间非线性变换,使可以被线性分类。
支持向量机(Support Vector Machine, SVM)可以视为在感知机基础上的改进,是建立在统计学习理论的VC维理论和结构风险最小原理基础上的广义线性分类器。与感知机主要差异在于:1、感知机目标是找到一个超平面将各样本尽可能分离正确(有无数个),SVM目标是找到一个超平面不仅将各样本尽可能分离正确,还要使各样本离超平面距离最远(只有一个最大边距超平面),SVM的泛化能力更强。2、对于线性不可分的问题,不同于感知机的增加非线性隐藏层,SVM利用核函数,本质上都是实现特征空间非线性变换,使可以被线性分类。

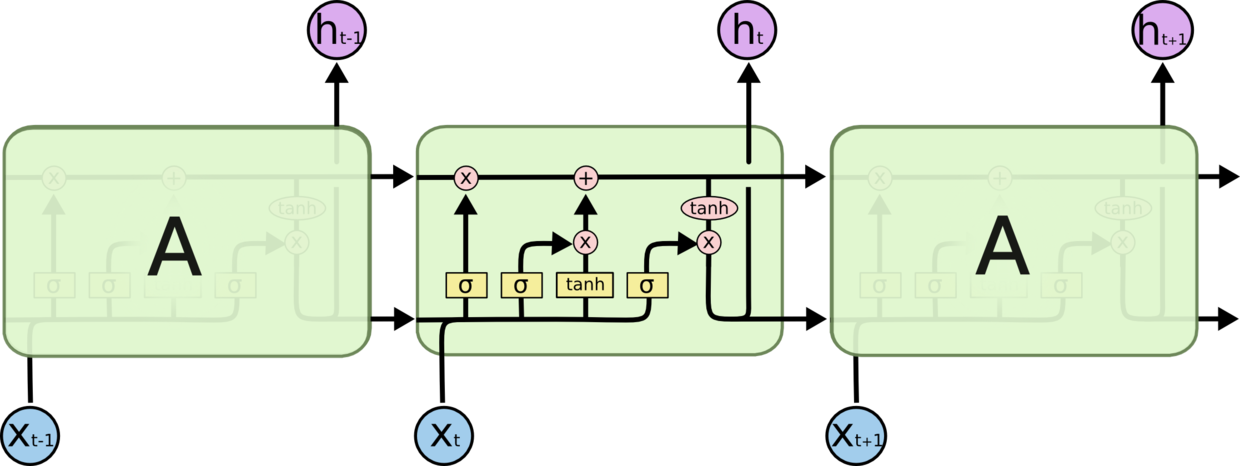 LSTM是一种复杂结构的循环神经网络(RNN),结构上引入了遗忘门、输入门及输出门:输入门决定当前时刻网络的输入数据有多少需要保存到单元状态,遗忘门决定上一时刻的单元状态有多少需要保留到当前时刻,输出门控制当前单元状态有多少需要输出到当前的输出值。这样的结构设计可以解决长序列训练过程中的梯度消失问题。
LSTM是一种复杂结构的循环神经网络(RNN),结构上引入了遗忘门、输入门及输出门:输入门决定当前时刻网络的输入数据有多少需要保存到单元状态,遗忘门决定上一时刻的单元状态有多少需要保留到当前时刻,输出门控制当前单元状态有多少需要输出到当前的输出值。这样的结构设计可以解决长序列训练过程中的梯度消失问题。


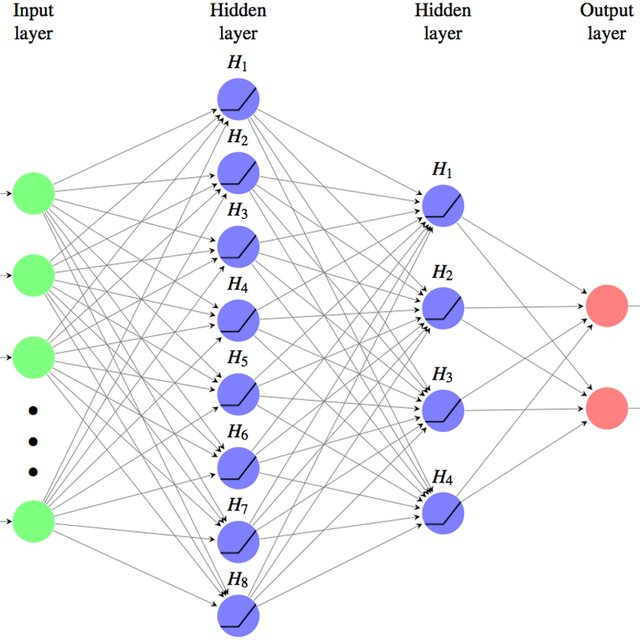




 Word2Vec网络结构是一个浅层神经网络(输入层-线性全连接隐藏层->输出层),按训练学习方式可分为CBOW模型(以一个词语作为输入,来预测它的邻近词)或Skip-gram模型 (以一个词语的邻近词作为输入,来预测这个词语)。
Word2Vec网络结构是一个浅层神经网络(输入层-线性全连接隐藏层->输出层),按训练学习方式可分为CBOW模型(以一个词语作为输入,来预测它的邻近词)或Skip-gram模型 (以一个词语的邻近词作为输入,来预测这个词语)。 




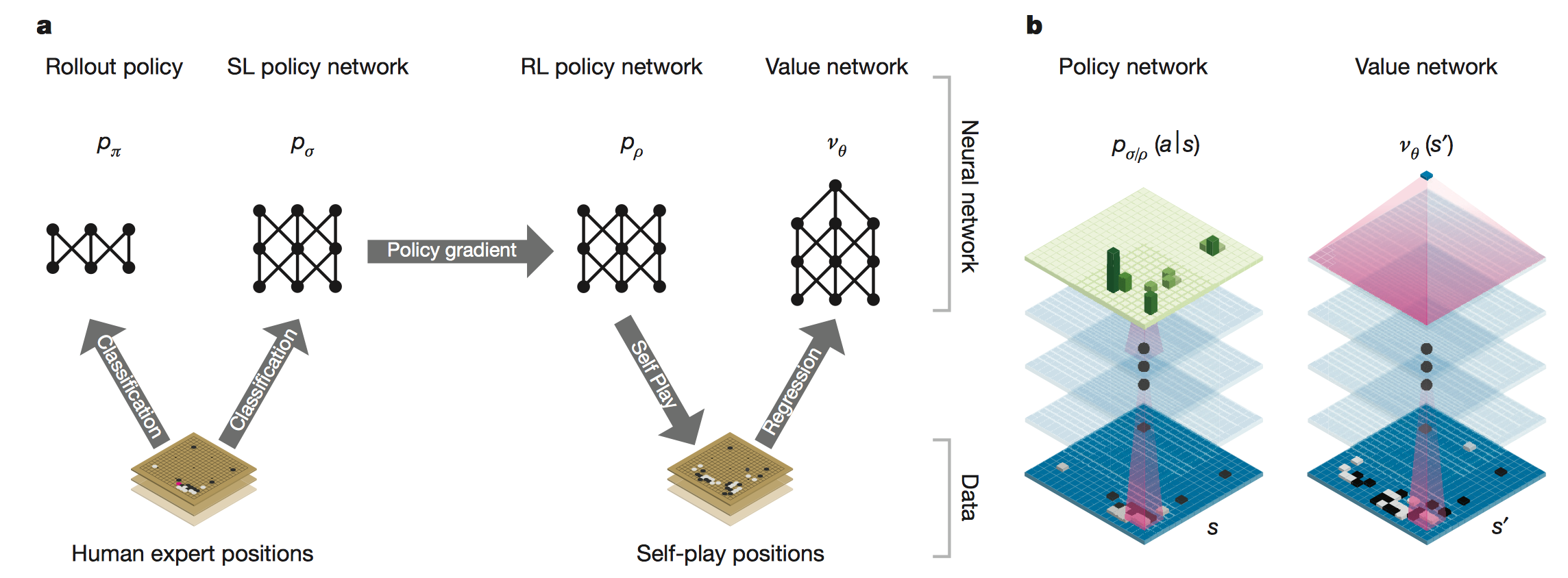 在2017年更新的AlphaGo Zero,在此前的版本的基础上,结合了强化学习进行了自我训练。它在下棋和游戏前完全不知道游戏规则,完全是通过自己的试验和摸索,洞悉棋局和游戏的规则,形成自己的决策。随着自我博弈的增加,神经网络逐渐调整,提升下法胜率。更为厉害的是,随着训练的深入,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
在2017年更新的AlphaGo Zero,在此前的版本的基础上,结合了强化学习进行了自我训练。它在下棋和游戏前完全不知道游戏规则,完全是通过自己的试验和摸索,洞悉棋局和游戏的规则,形成自己的决策。随着自我博弈的增加,神经网络逐渐调整,提升下法胜率。更为厉害的是,随着训练的深入,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。


 人工智能60多年的技术发展,可以归根为算法、算力及数据层面的发展,那么在可以预见的未来,人工智能发展将会出现怎样的趋势呢?
人工智能60多年的技术发展,可以归根为算法、算力及数据层面的发展,那么在可以预见的未来,人工智能发展将会出现怎样的趋势呢?




【本文地址】
今日新闻 |
推荐新闻 |