12种相关系数汇总,那些你不知道的相关系数 |
您所在的位置:网站首页 › 等级相关系数取值范围 › 12种相关系数汇总,那些你不知道的相关系数 |
12种相关系数汇总,那些你不知道的相关系数
|
所谓相关关系是指2个或2个以上变量取值之间在某种意义下所存在的规律,其目的在于探索数据集所存在隐藏的关系网,在19世纪80年代,Galton通过研究人类身高遗传问题首次提出了相关的概念,文中指出相关关系可以定义为:一个变量变化时,另一个变量或多或少的相应的变量。这种相关关系的统计量称为相关关系。相关分析不只有我们常用的pearson相关,还有其它相关系数等等,本篇文章为大家梳理都有哪些相关系数。
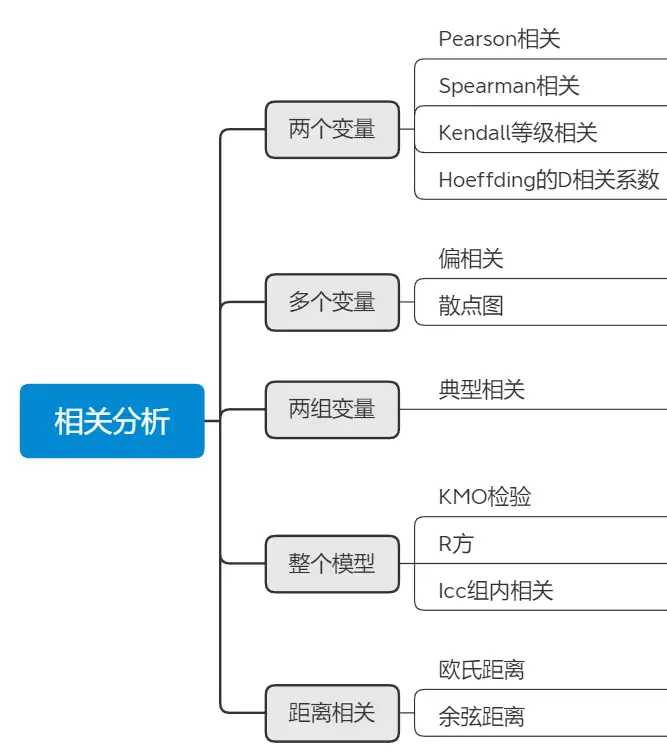
Pearson相关分析的说明: pearson 法则是一种经典的相关系数计算方法,主要用于表征线性相关性,假设2个变量服 从正态分布且标准差不为0,他的值介于-1到1之间,pearson相关系数的绝对值越接近于1,表明 2个变量的相关程度越高,即这2个变量越相似。 Pearson相关分析的计算: 其相关系数计算如下:
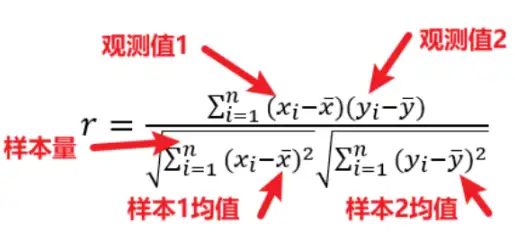
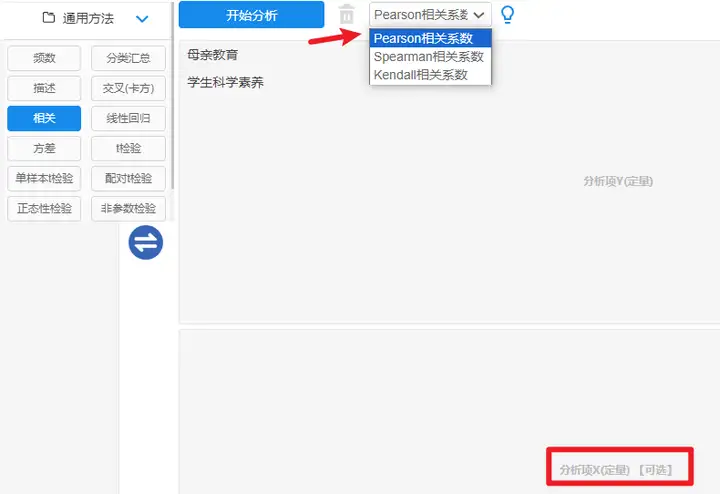
Pearson相关分析的操作: 以SPSSAU为例,pearson相关系数路径【通用方法】→【相关分析】
分析前选择“pearson相关系数”按钮即可,au这里有提供两个分析项放置框,第二个分析项放置框可以不放置分析项为可选项,如果将分析项放置两个框和一个框内,结果不会改变,但是结果的表现形式会些许不一致,建议根据所需进行选择即可。 Pearson相关分析系数判断:
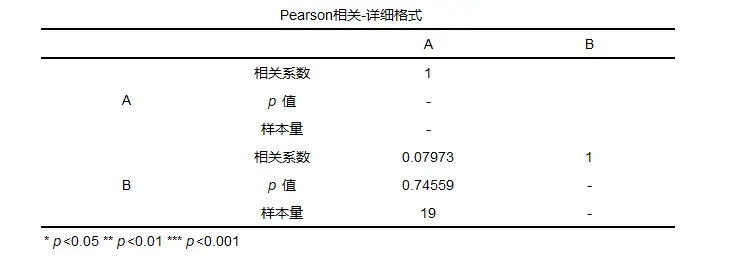
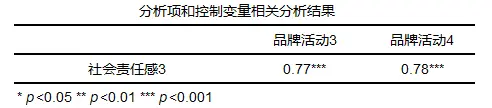
不同的文献相关系数的判断标准不同,如果在分析中,建议以及所参考的文献等进行参考,比如上面的文献就来自于贾俊平, 何晓群, 金勇进. 统计学.第7版[M]. 中国人民大学出版社, 2018. Pearson的一般结果:
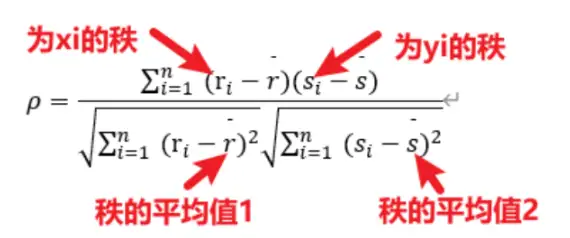
一般结果会提供相关系数以及p值等,可以根据p值结合相关系数进行分析,若p值小于显著性水平(比如显著性水平为0.05)则拒绝原假设,该模型显著,具有相关关系。反之,接受原假设,不具有相关关系。 2、Spearman相关spearman相关分析的说明: Spearman 相关性分析是对两组变量的等级大小作相关性分析,从而得到一个自变量与因变量之间的关系和自变量对因变量的影响强弱。它首先将两组变量的数据按照大小顺序排列,然后用等级代替原始数据,最后计算等级之间的相关性。 spearman相关分析的计算: 设自变量 X 和 Y 的 2 个随机样本为 ( x1 ,y1 ),⋯,( xn ,yn ),将 x1 ,⋯,xn和 y1 ,⋯,yn按升序方式进行排列,则X和Y的spearman秩相关系数为:
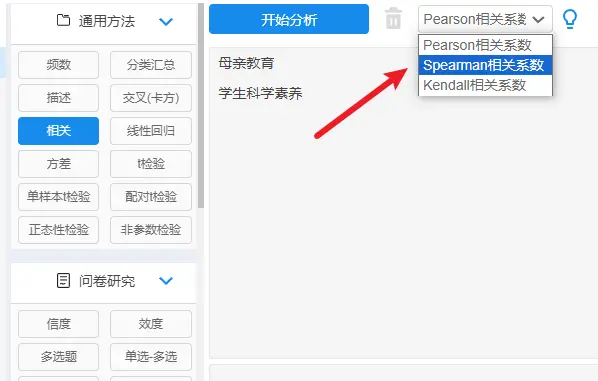
spearman相关分析的操作: 以SPSSAU为例,pearson相关系数路径【通用方法】→【相关分析】
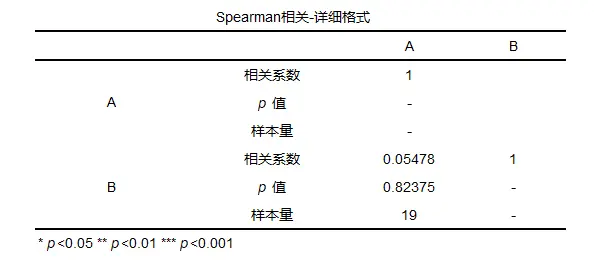
spearman相关分析系数判断: Spearman相关系数范围为-1――1,小于0代表负相关,大于0代表正相关,等于0则代表不存在相关关系。相关系数绝对值越接近0,相关关系越弱;绝对值越接近1,证明相关关系越强。 spearman的一般结果:
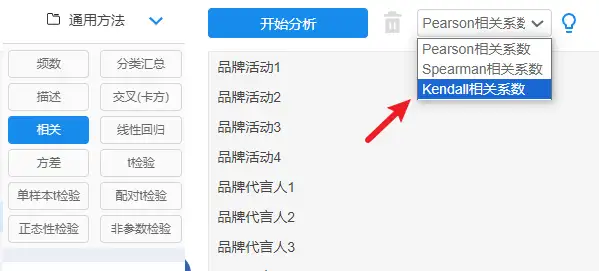
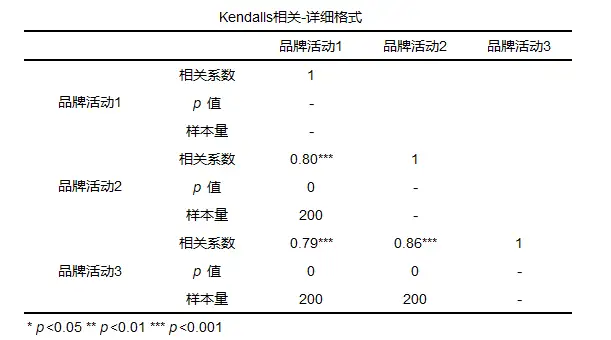
一般结果会提供相关系数(此相关系数为spearman相关系数)以及p值等,可以根据p值结合相关系数进行分析,若p值小于显著性水平(比如显著性水平为0.05)则拒绝原假设,该模型显著,具有相关关系。反之,接受原假设,不具有相关关系。 3、Kendall等级相关kendall相关分析的说明: kendall相关系数也叫kendall秩相关系数,广泛用于量化不同变量间的相关程度,作为一类无参数假设检验,用于衡量两变量之间的相关性,其并不要求数据满足正态分布,对于样本容量也没有过多要求,适用性比较广。 kendall相关分析的分类: kendall相关系数常见的有 tau-a、tau-b、tau-c,除此之外还有tub_b等等。其中tau-a未对数据中的结做校正,tau-b对数据中的结做校正,tau-c适用于两列变量尺度不相等的情况。tub_b适合两个变量为定量变量。 kendall相关分析的操作: 这里以kendall tub_b为例,操作路径【通用方法】→相关分析;
kendall相关分析系数判断: kendall相关系数取值范围介于-1到1之间,其中绝对值越接近于1说明相关性越强,越接近于0说明相关性越弱。 kendall的一般结果: 以kendall tub_b为例,结果如下:
分析结果一般提供kendall相关系数和p值,可以根据p值结合相关系数进行分析,若p值小于显著性水平(比如显著性水平为0.05)则拒绝原假设,该模型显著,具有相关关系。反之,接受原假设,不具有相关关系。 4、Hoeffding’D相关系数Hoeffding相关分析的说明: Hoeffding’D是由Wassily Hoeffding在1948年提出的,用于衡量两个变量之间的相关关系。 Hoeffding相关分析的计算: 其计算公式如下:
Hoeffding相关分析系数判断: Hoeffding’D相关系数取值范围介于-1到1之间,其中绝对值越接近于1说明相关性越强,越接近于0说明相关性越弱。 二、多个变量 1、偏相关偏相关分析的说明: 相关分析用于研究两两变量之间的关系情况,如果有第三个变量会干扰到分析结果,也就是我们常说的控制变量,这是控制变量也需要考虑在模型内,比如研究身高与肺活量之间的关系,如果直接进行相关分析,会出现有相关关系,但真实结论很可能并不应该这样,同样身高的人肺活量很可能明显不一样,原因是体重并不一样。所以此时在分析时需要将体重考虑在内,此种情况下适合使用的为偏相关。 偏相关分析的计算: 以au为例,其原理计算与pearson相关系数的计算一致:
偏相关分析的操作: 分析路径【进阶方法】→【偏相关】;
偏相关分析系数判断: 其判断也与pearson相关系数的判断标准类似:
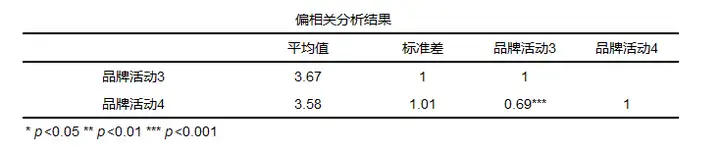
偏相关的一般结果:
SPSSAU分析建议如下:
SPSSAU分析建议如下:
散点图的说明: 散点图是一种以点的分布反映变量之间的相关情况的统计图,根据散点图中的各点分布走向和密集程度,可以大致判断变量之间的相互关系。 散点图的操作: 以SPSSAU为例,pearson相关系数路径【可视化】→【散点图】
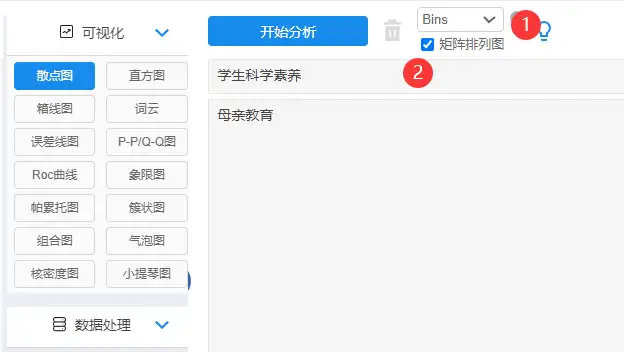
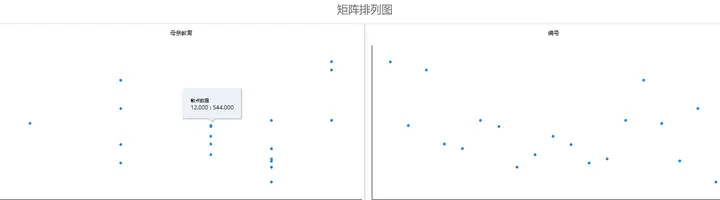
将左侧分析项拖拽到右侧分析框内,选择相应参数,点击开始分析,其中**“bins”为一种散点数据处理方式,当散点过多时可通过bins处理更清晰的查看散点数据关系情况,当散点数量>1000时,SPSSAU自动会进行bins处理(bins=100),与此同时,研究者也可自主设置bins数量。“矩阵排列图”**当自变量不止一项时,勾选矩阵排列图,结果会默认提供不同自变量的散点图排列图,比如:
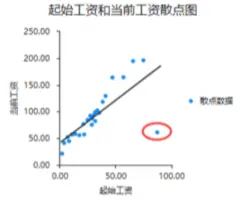
散点图应用场景: 观测数据是否有异常值如果数据明显偏离数据群,判定其可能为异常值(偏主观);比如:
其中包括正相关、负相关、不相关,比如正相关:
两个变化趋势相同。 散点图的一般结果:
一般用于相关分析之前,通过图示化查看两个变量之间的基本关系,分析上偏主观,一般还需要结合相关分析进一步分析,比如如图所示,散点整体比较杂乱,并没有什么特别趋势,所以两个变量可能不相关,具体可以查看相关分析进行查看相关系数以及p值等。 三、两组变量 1、典型相关典型相关分析的说明: 典型相关分析简称CAA,用于研究一组X与另一组Y数据之间的相关关系情况。如果研究1个X和1个Y之间的关系情况,此时直接使用相关分析即可,但如果希望研究1组X和1组Y之间的关系情况,则需要使用典型相关分析。 典型相关分析的操作: 分析路径【进阶方法】→【典型相关】;
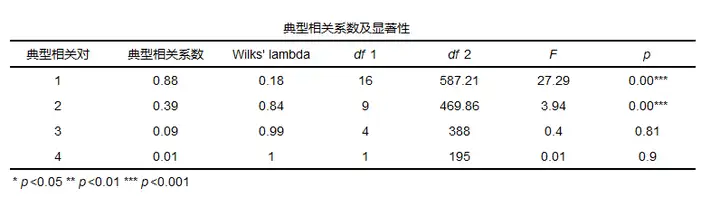
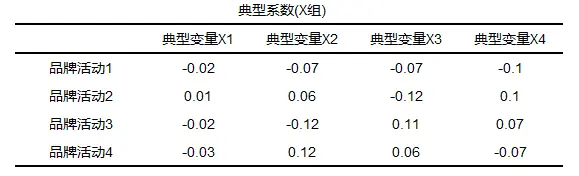
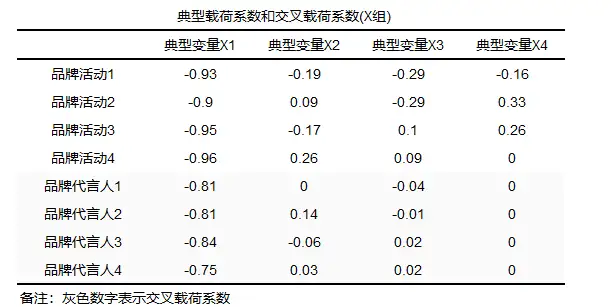
典型相关分析的步骤: 一般步骤分为三步: Step1:提取出典型相关变量; Step2:寻找典型变量与研究变量之间的关系表达式,以及典型变量与研究变量间的关系情况; Step3:典型冗余分析。 典型相关分析系数判断: 典型相关系数介于-1-1之间,绝对值越接近于1说明相关行越强,绝对值越接近于0说明相关性越弱,分析时还是要结合p值一起分析。 典型的一般结果:
中间过程:
除此之外也提供了典型系数(Y组)。 四、整个模型 1、KMO检验KMO值的说明: KMO值是用来判断所选取变量在因素分析中的可接受程度,考察变量之间相关关系,KMO值应用于很多方法中,比如进行探索性因子分析,第一步需要通过KMO和巴特利特检验进行测量问卷量表进而决定是否适合进行因子分析等等。 KMO值的计算: KMO值的计算如下:
KMO值的操作: 很多方法都有提及到KMO值,比如因子分析、主成分分析等,这里以探索性因子分析作为例子进行演示操作:
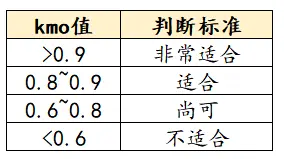
默认结果有提供KMO值检验结果。 KMO值判断标准: kmo值的判断标准是怎么样的呢?
所以一般进行因子分析(主成分分析)需要kmo值大于0.6即可。 KMO值一般结果: 以探索性因子分析为例:
一般判断数据是否适合进行因子分析或者主成分分析,KMO 和 Bartlett 的检验是第一步,所以在KMO 和 Bartlett 的检验表格中上半部分为kmo值,下半部分为Bartlett 的检验,从表中可以看到kmo值大于0.6说明适合进行分析。 2、R方R方的说明: r方也被称为决定系数,是用来描述模型拟合程度的重要指标,R方测度了回归直线对观测数据的拟合程度,一般常用于回归分析中,在一元线性回归中,R2(R方)=Pearson相关系数的平方。 R方的计算: R方的计算如下:
从图片中可以看出:
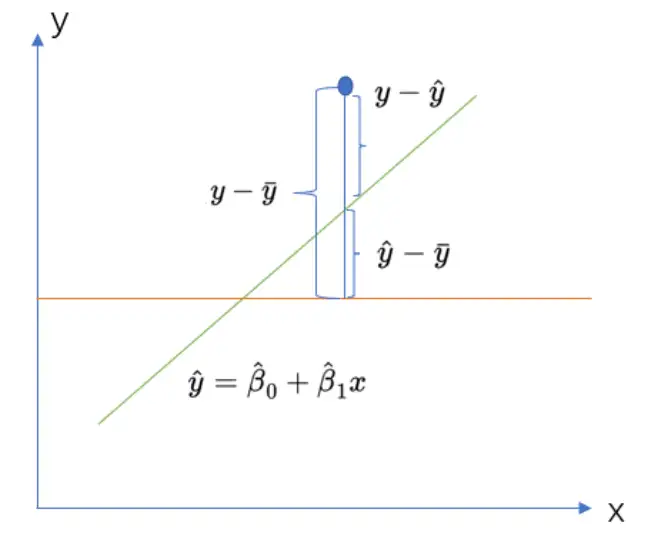
所以对于模型来讲肯定是能用回归直线解释的变差部分越大越好,也就是说明SSR占SST的比例越大,解释越多,同时也可以说明直线拟合的越好,所以我们引出一个指标R方,回归平方和占总平方和的比例,即为R方。计算公式为:
R方的操作: 以线性回归为例,操作如下:
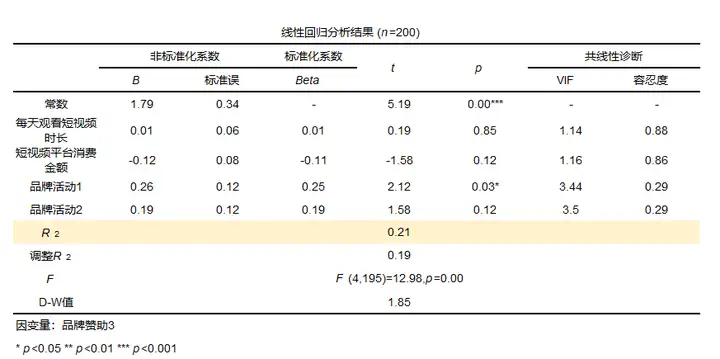
R方判断: R方的取值范围在【0,1】,同时根据计算公式,也可以得到,R方越接近1说明SSR占SST的占比越大,也就是说明模型拟合越好,反之,如果R方越接近1,说明SSR占SST的占比越小,被解释部分越少,模型拟合越差。 R方的一般结果: SPSSAU线性回归结果默认有提供R方值,如下:
一个模型只有一个R方,如果在文献中看到有多个R方的结果,通常是由多次分析最后整合在一起的,如果模型仅关注于变量是否显著等,一般不需要过度关注R方值,但是如果是利用线性回归进行预测,可以关注下R方,具体以专业和研究目的为准。 3、Icc组内相关ICC组内相关的说明: ICC组内相关系数是一种用来检验观测值在多个观察者之间是否具有一致性,是一种常用的两阶标准化相关系数。 ICC组内相关的计算: ICC=个体变异/总变异;
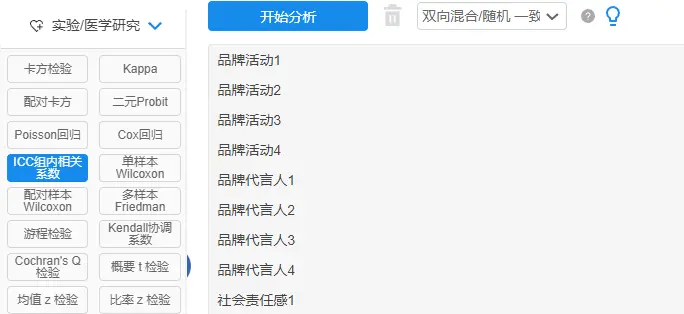
ICC组内相关的操作: SPSSAU【实验/医学研究】→icc组内相关系数;
ICC组内相关判断: ICC取值在0~1之间,通常情况下: ICC |


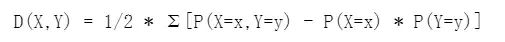




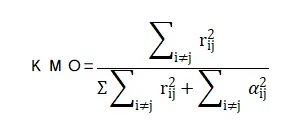
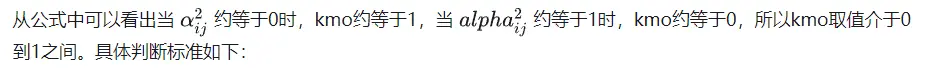

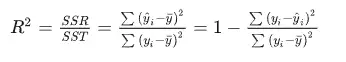
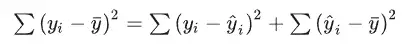

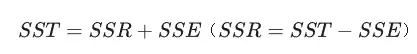
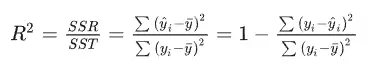
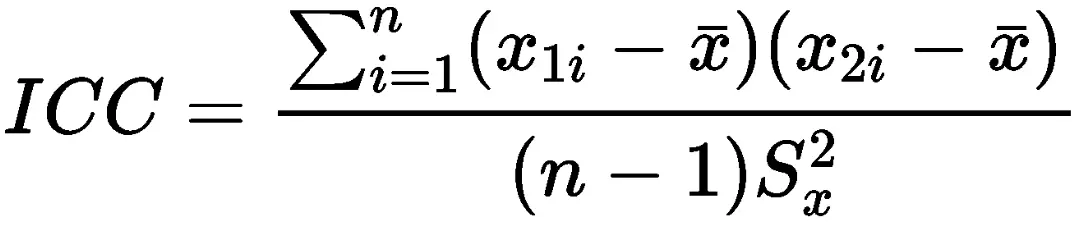
【本文地址】
今日新闻 |
推荐新闻 |