【机器学习】K |
您所在的位置:网站首页 › 程序流程图的主要缺点是什么 › 【机器学习】K |
【机器学习】K
|
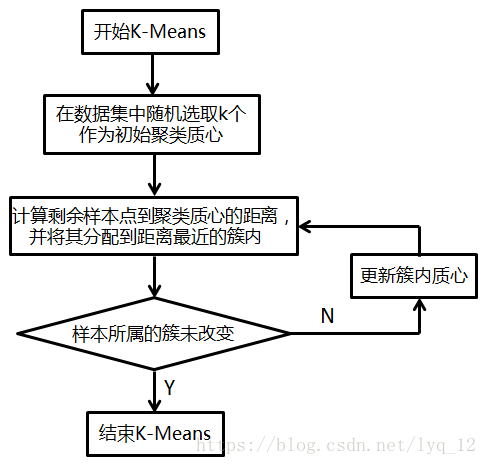
分类是根据样本某些属性或某类特征(可以融合多类特征),把样本类型归为已确定的某一类别中。机器学习中常见的分类算法有:SVM(支持向量机)、KNN(最邻近法)、Decision Tree(决策树分类法)、Naive Bayes(朴素贝叶斯分类)、Neural Networks(神经网络法)等。 而分类作为一种监督学习方法,需要事先知道样本的各种类别信息。因此当对海量数据进行分类时,为了降低数据满足分类算法要求所需要的预处理代价,往往需要选择非监督学习的聚类算法。 K-Means Clustering(K均值聚类),就是最典型的聚类算法之一,接下来一起进行该算法的学习。 1、K-Means算法原理 K-Means算法思想:对给定的样本集,事先确定聚类簇数K,让簇内的样本尽可能紧密分布在一起,使簇间的距离尽可能大。该算法试图使集群数据分为n组独立数据样本,使n组集群间的方差相等,数学描述为最小化惯性或集群内的平方和。K-Means作为无监督的聚类算法,实现较简单,聚类效果好,因此被广泛使用。 2、K-Means步骤及流程 2.1、算法步骤 输入:样本集D,簇的数目k,最大迭代次数N; 输出:簇划分(k个簇,使平方误差最小); 算法步骤: (1)为每个聚类选择一个初始聚类中心; (2)将样本集按照最小距离原则分配到最邻近聚类; (3)使用每个聚类的样本均值更新聚类中心; (4)重复步骤(2)、(3),直到聚类中心不再发生变化; (5)输出最终的聚类中心和k个簇划分; 2.2、流程框图: 3、K-Means代码实现 Python代码实现请参考:python 实现周志华 机器学习书中 k-means 算法; Matlab代码实现请参考:https://blog.csdn.net/u010248552/article/details/78476934?locationNum=8&fps=1; C#代码实现请参考:https://www.cnblogs.com/gaochundong/p/kmeans_clustering.html; 4、K-Means算法优缺点 4.1、优点 (1)原理易懂、易于实现; (2)当簇间的区别较明显时,聚类效果较好; 4.2、缺点 (1)当样本集规模大时,收敛速度会变慢; (2)对孤立点数据敏感,少量噪声就会对平均值造成较大影响; (3)k的取值十分关键,对不同数据集,k选择没有参考性,需要大量实验; 5、参考资料 1、简单易学的机器学习算法——K-Means算法; 2、k-means 的原理,优缺点以及改进; |

【本文地址】
今日新闻 |
推荐新闻 |