毕业设计 深度学习图像分类算法研究与实现 |
您所在的位置:网站首页 › 神经网络论文题目 › 毕业设计 深度学习图像分类算法研究与实现 |
毕业设计 深度学习图像分类算法研究与实现
|
文章目录
0 前言1 常用的分类网络介绍1.1 CNN1.2 VGG1.3 GoogleNet
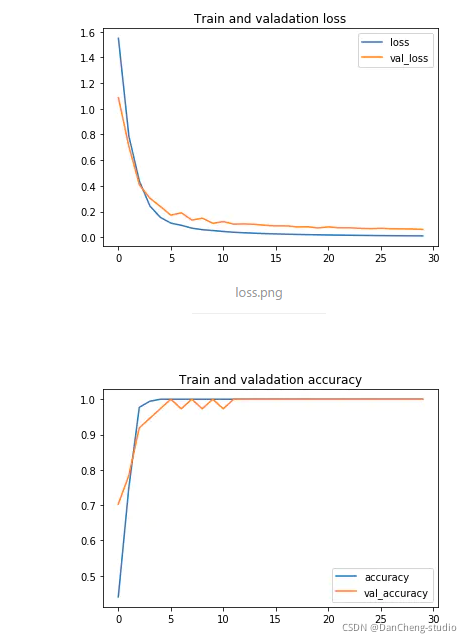
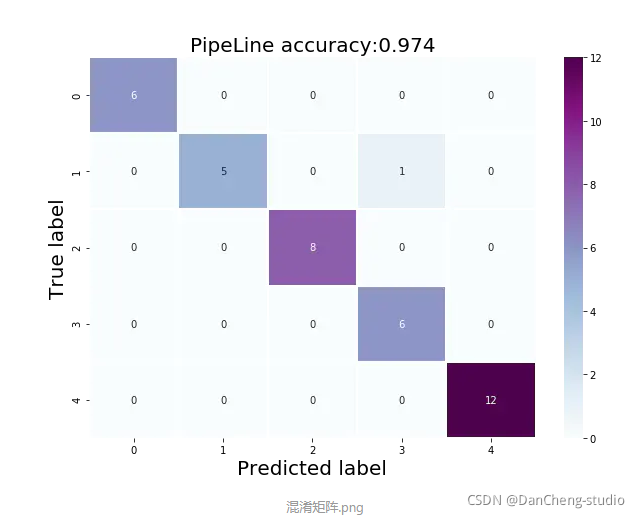
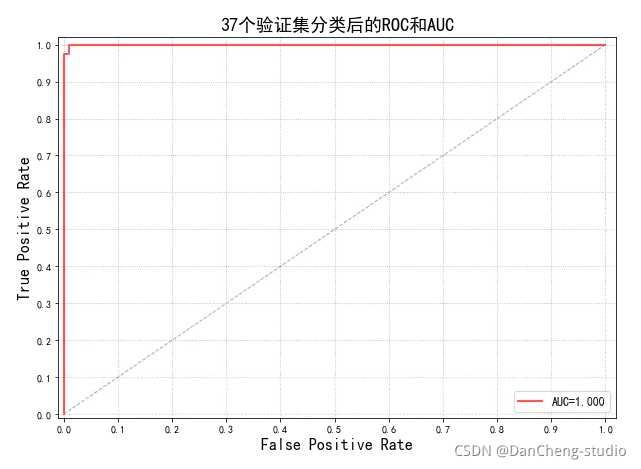
2 图像分类部分代码实现2.1 环境依赖2.2 需要导入的包2.3 参数设置(路径,图像尺寸,数据集分割比例)2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)2.5 数据预处理2.6 训练分类模型2.7 模型训练效果2.8 模型性能评估
3 1000种图像分类4 最后
0 前言
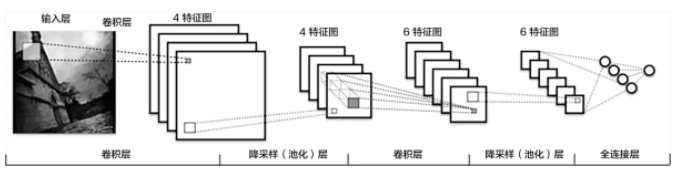
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。 为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是 🚩 毕业设计 深度学习图像分类算法研究与实现 - 卷积神经网络图像分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分🧿 选题指导, 项目分享: https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md 1 常用的分类网络介绍 1.1 CNN传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。如下图:
卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。 Dropout : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合 在CNN的训练过程总,由于每一层的参数都是不断更新的,会导致下一次输入分布发生变化,这样就需要在训练过程中花费时间去设计参数。在后续提出的BN算法中,由于每一层都做了归一化处理,使得每一层的分布相对稳定,而且实验证明该算法加速了模型的收敛过程,所以被广泛应用到较深的模型中。 1.2 VGGVGG 模型是由牛津大学提出的(19层网络),该模型的特点是加宽加深了网络结构,核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。该模型由于每组内卷积层的不同主要分为 11、13、16、19 这几种模型
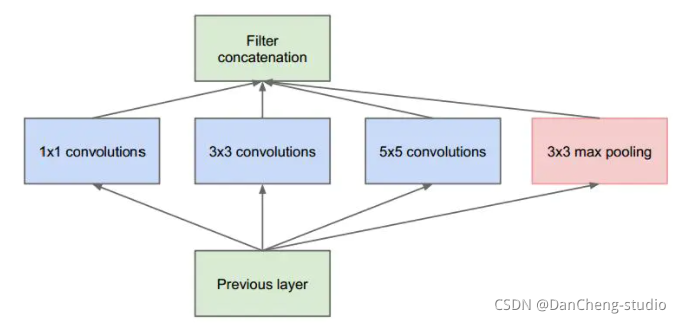
增加网络深度和宽度,也就意味着巨量的参数,而巨量参数容易产生过拟合,也会大大增加计算量。 1.3 GoogleNetGoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想. NIN模型特点: 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。 2)设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
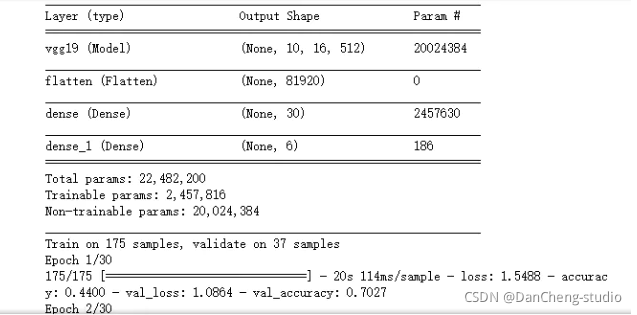
图像数据压缩, 标签数据进行独立热编码one-hot def preprocess_dl_Image(all_data,all_label): all_data = all_data.astype("float32")/255 #把图像灰度值压缩到0--1.0便于神经网络训练 all_label = to_categorical(all_label) #对标签数据进行独立热编码 return all_data,all_label all_data,all_label = preprocess_dl_Image(all_data,all_label) #处理后的数据对数据及进行划分(训练集:验证集:测试集 = 0.7:0.15:0.15) def split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent): s = np.arange(all_data.shape[0]) np.random.shuffle(s) #随机打乱顺序 all_data = all_data[s] #打乱后的图像数据 all_label = all_label[s] #打乱后的标签数据 all_len = all_data.shape[0] train_len = int(all_len*TrainingPercent/100) #训练集长度 valadation_len = int(all_len*ValidationPercent/100)#验证集长度 temp_len=train_len+valadation_len train_data,train_label = all_data[0:train_len,:,:,:],all_label[0:train_len,:] #训练集 valadation_data,valadation_label = all_data[train_len:temp_len, : , : , : ],all_label[train_len:temp_len, : ] #验证集 test_data,test_label = all_data[temp_len:, : , : , : ],all_label[temp_len:, : ] #测试集 return train_data,train_label,valadation_data,valadation_label,test_data,test_label train_data,train_label,valadation_data,valadation_label,test_data,test_label=split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent) 2.6 训练分类模型 使用迁移学习(基于VGG19)epochs = 30batch_size = 16使用 keras.callbacks.EarlyStopping 提前结束训练 def train_classifier(train_data,train_label,valadation_data,valadation_label,lr=1e-4): conv_base = VGG19(weights='imagenet', include_top=False, input_shape=(ImageHeight, ImageWidth, 3) ) model = models.Sequential() model.add(conv_base) model.add(layers.Flatten()) model.add(layers.Dense(30, activation='relu')) model.add(layers.Dense(6, activation='softmax')) #Dense: 全连接层。activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层 conv_base.trainable=False model.compile( loss='categorical_crossentropy',#loss: 拟合损失方法,这里用到了多分类损失函数交叉熵 optimizer=Adam(lr=lr),#optimizer: 优化器,梯度下降的优化方法 #rmsprop metrics=['accuracy']) model.summary() #每个层中的输出形状和参数。 early_stoping =tf.keras.callbacks.EarlyStopping(monitor="val_loss",min_delta=0,patience=5,verbose=0,baseline=None,restore_best_weights=True) history = model.fit( train_data, train_label, batch_size=16, #更新梯度的批数据的大小 iteration = epochs / batch_size, epochs=30, # 迭代次数 validation_data=(valadation_data, valadation_label), # 验证集 callbacks=[early_stoping]) return model,history model,history = train_classifier(train_data,train_label,valadation_data,valadation_label,)
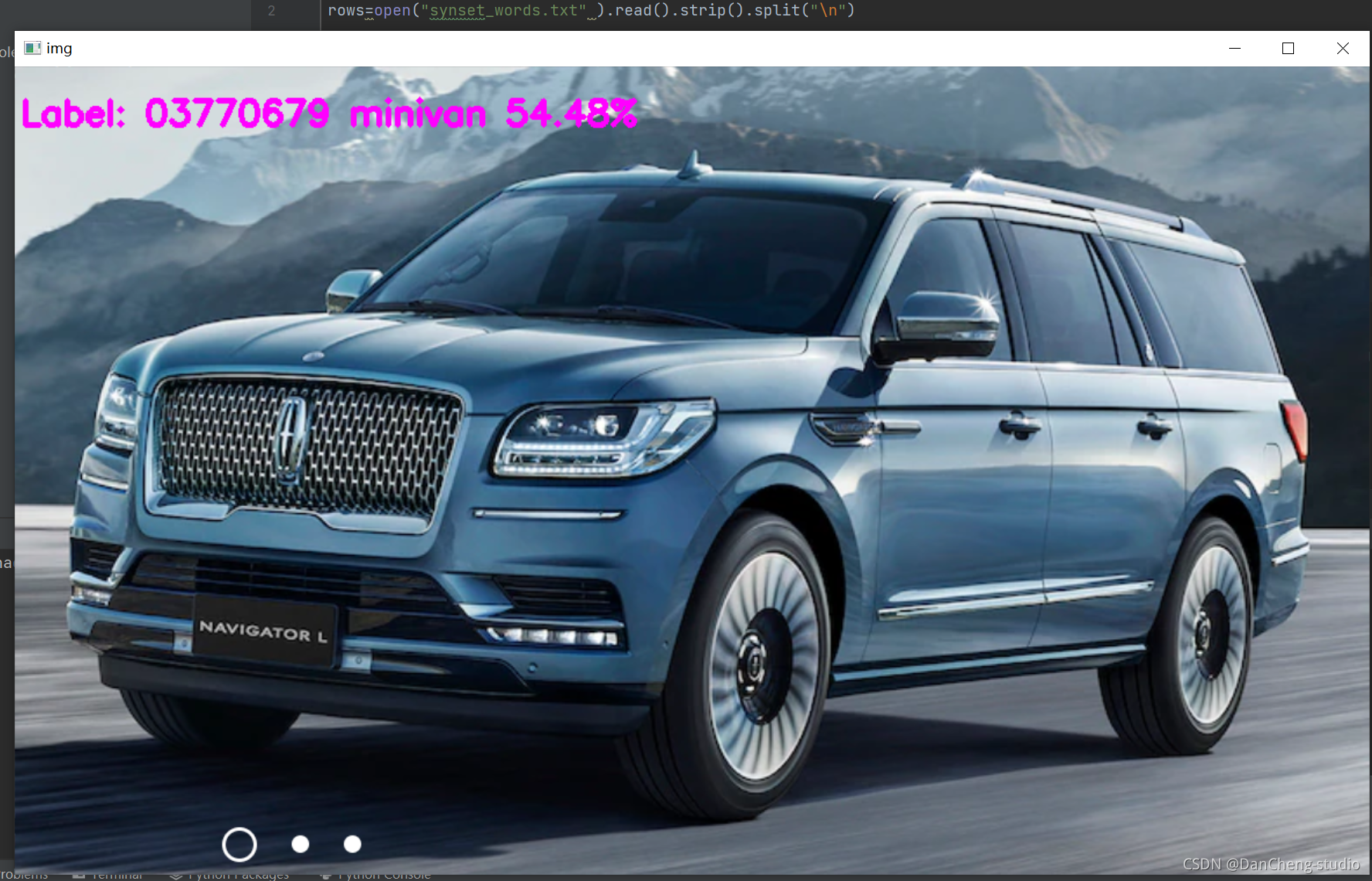
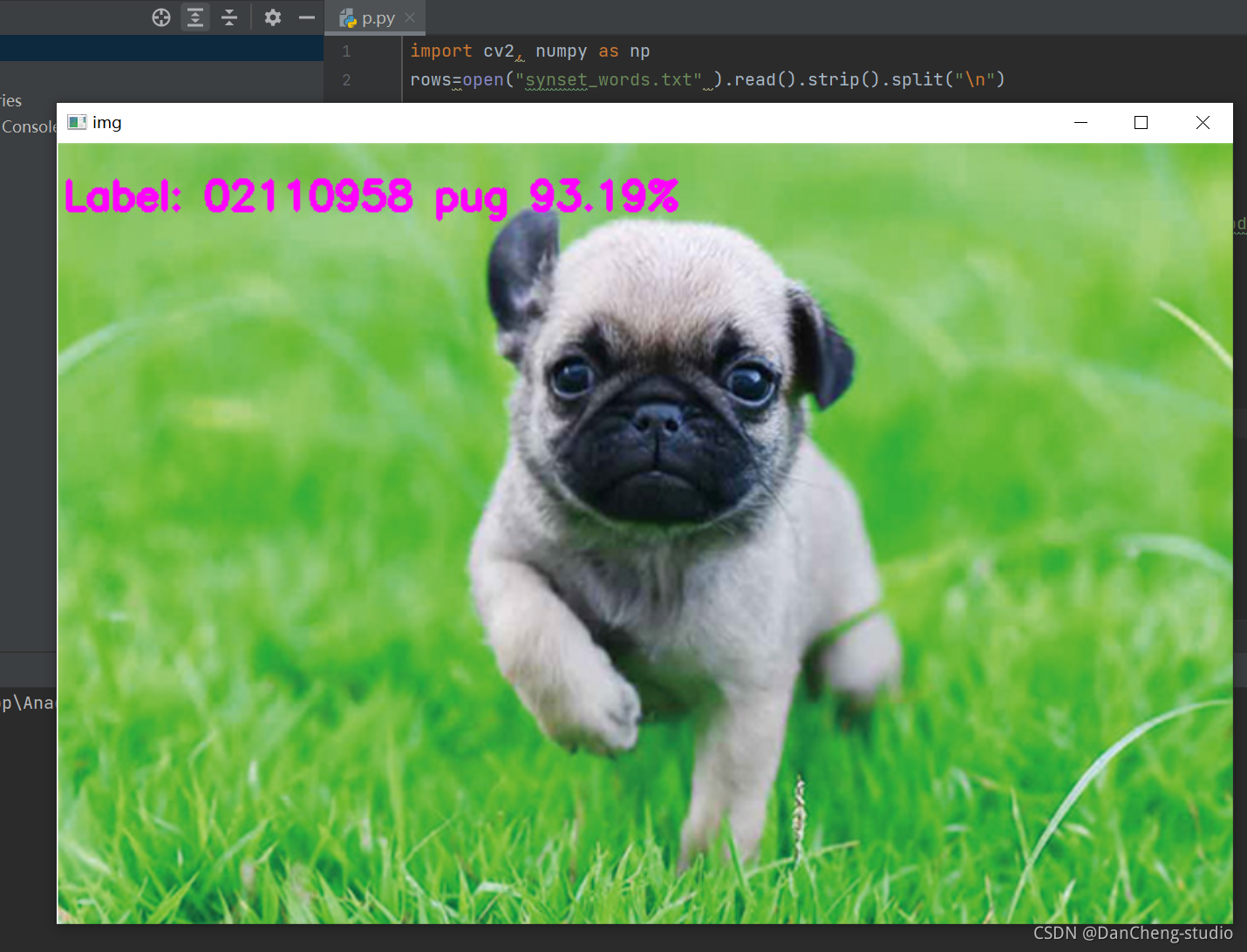
这是学长训练的能识别1000种类目标的图像分类模型,演示效果如下
|



【本文地址】
今日新闻 |
推荐新闻 |