PyTorch深度学习笔记之五(使用神经网络拟合数据) |
您所在的位置:网站首页 › 神经网络线性模型 › PyTorch深度学习笔记之五(使用神经网络拟合数据) |
PyTorch深度学习笔记之五(使用神经网络拟合数据)
|
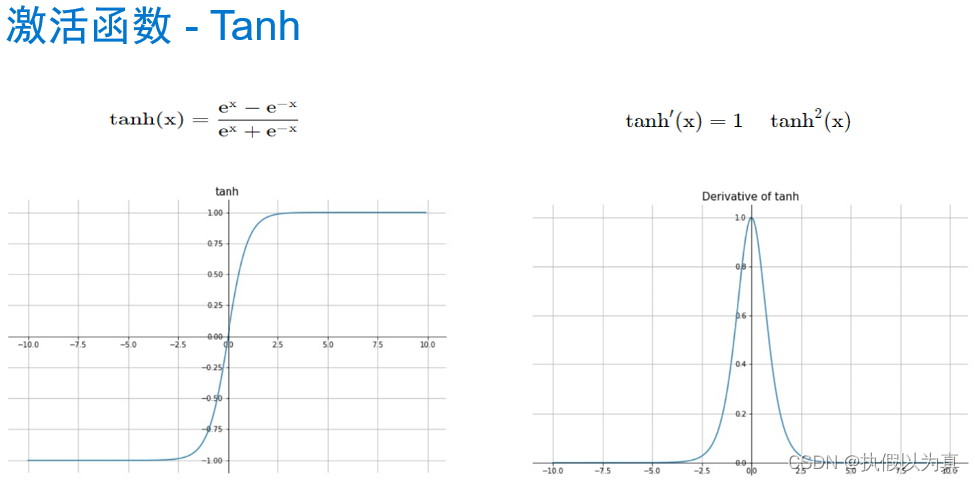
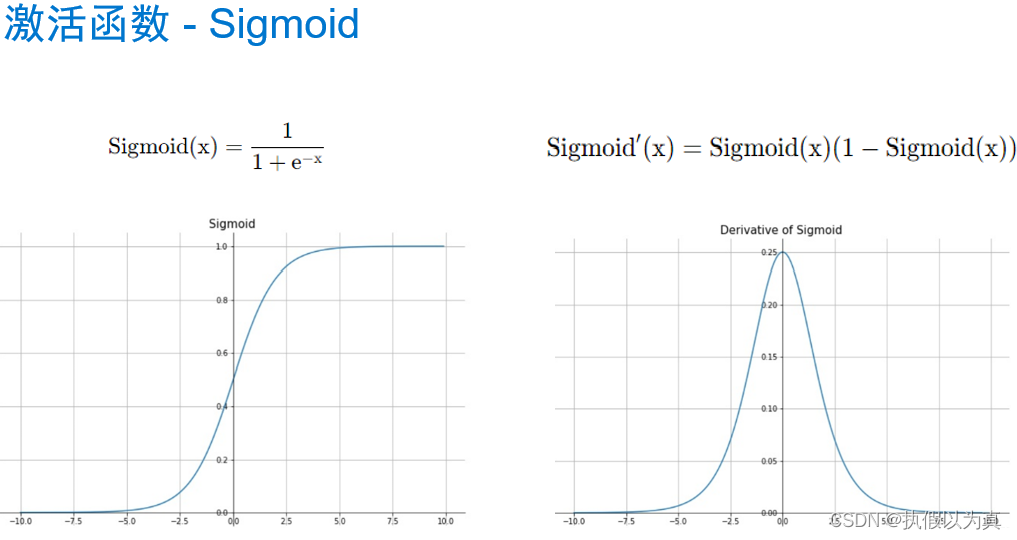
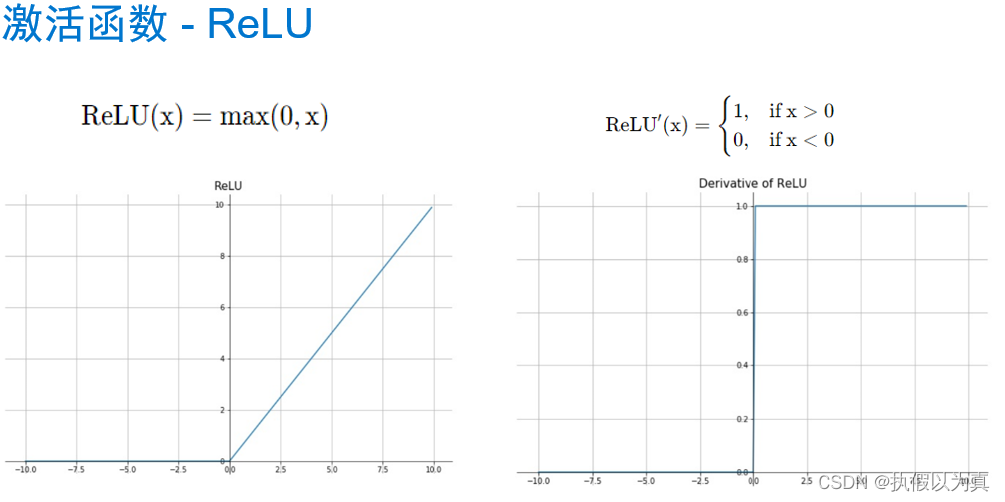
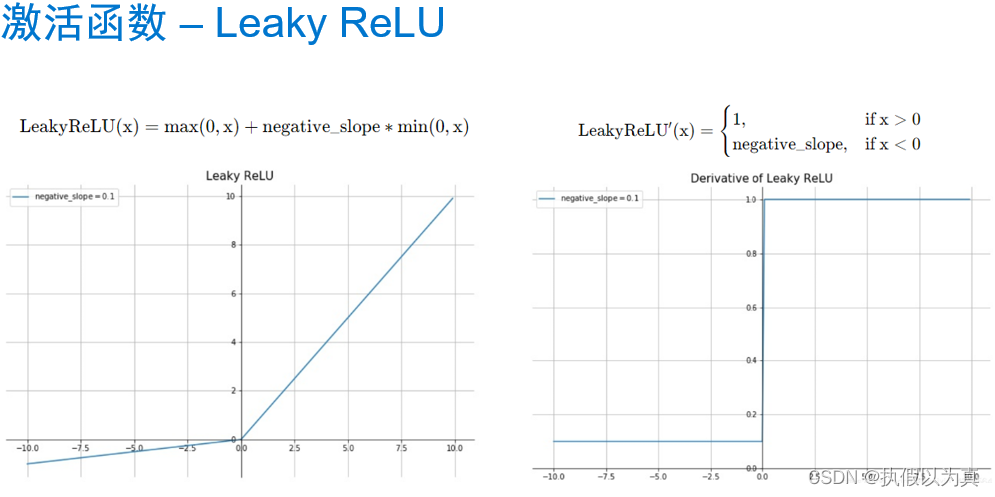
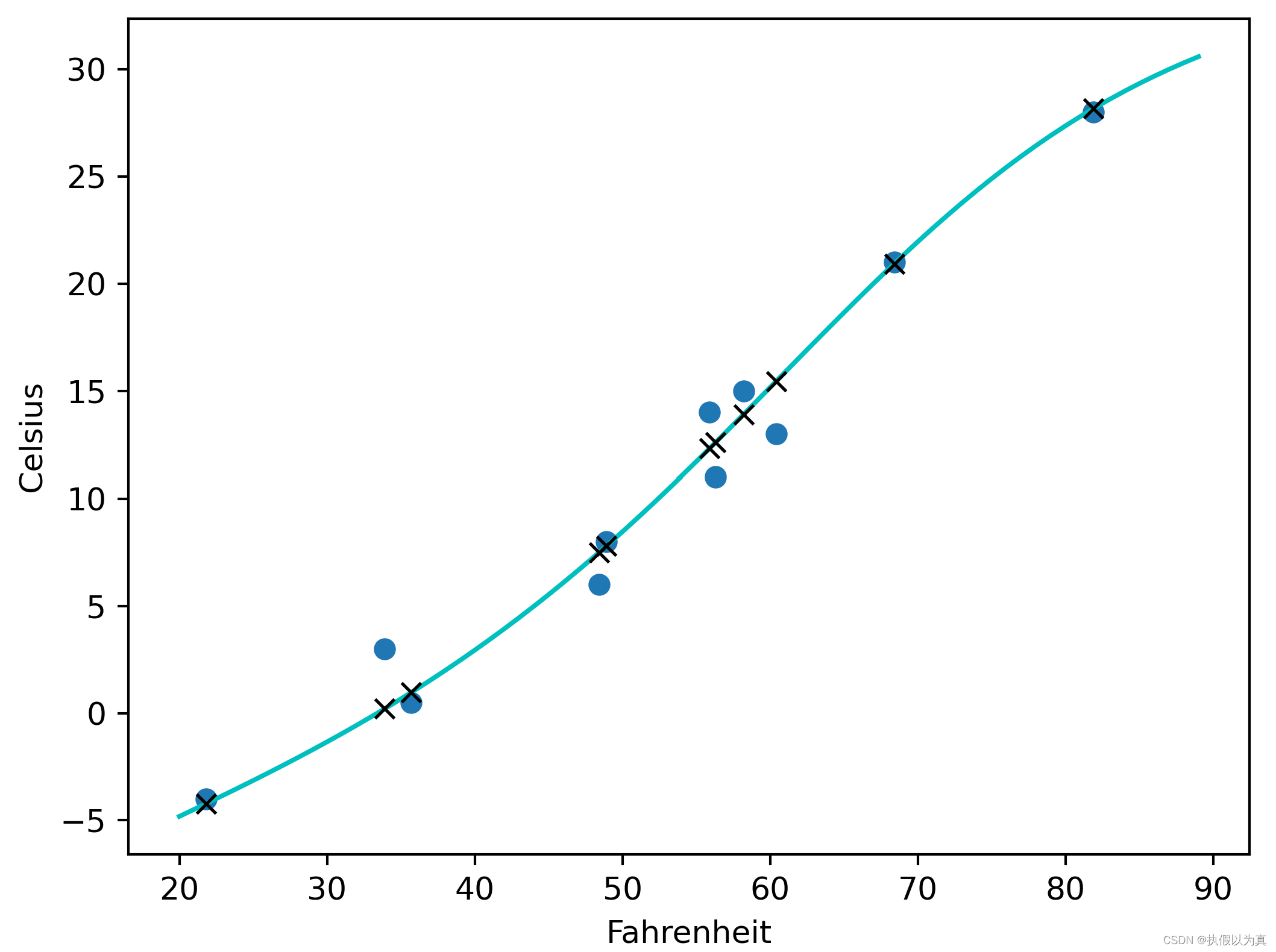
使用神经网络拟合数据 1. 人工神经网络 1.1 神经网络和神经元神经网络:一种通过简单函数的组合来表示复杂函数的数学实体。 人工神经网络和生理神经网络似乎都使用模糊相似的数学策略来逼近复杂的函数,因为这类策略非常有效。 这些复杂函数的基本构件是神经元。其核心就是给输入做一个线性变换(如乘以一个权重再加上一个常数作为偏置),然后应用一个固定的非线性函数,即激活函数。 比如: o = t a n h ( w x + b ) o = tanh(wx+b) o=tanh(wx+b) w和b就是要学习的参数,wx+b 就是线性变换, t a n h tanh tanh (双曲正切函数) 就是激活函数,也是一个非线性函数。所以,神经元就是一个包含在非线性函数中的线性变化。 从数学上,单个神经元可以写成 o = f ( w x + b ) o=f(wx+b) o=f(wx+b), f 就是激活函数;x 和 o 可以是简单的 标量(即0维张量) 或 向量(即1维张量);w, b, x 都可以是标量或向量,但它们应当一致;当w和b代表向量时,f(wx+b) 代表了一层神经元(可理解为一列),因为它通过多维权重和偏置来表示多个神经元。 1.2 组成一个多层网络一个多层的神经网络大致如下: x1 = f0(w0 * x + b0) x2 = f1(w1 * x1 + b1) x3 = f2(w2 * x2 + b2) … y = fn(wn * xn + bn) 前一层神经元的输出,被用作后一层神经元的输入。 使用向量可以让 w 承载整个神经元层,而不是单一的权重。 (注:w是向量,代表一层神经元,即一列神经元,每个神经元上的权重可能不同。) o = t a n h ( w n ( . . . t a n h ( w 1 ( t a n h ( w 0 ∗ x + b 0 ) + b 1 ) ) . . . ) + b n ) o = tanh(wn(...tanh(w1(tanh(w0*x+b0)+b1))...)+bn) o=tanh(wn(...tanh(w1(tanh(w0∗x+b0)+b1))...)+bn) 1.3 激活函数激活函数是非线性函数。它有2个作用。 在模型的内部,它允许输出函数在不同的值上有不同的斜率。这是线性函数无法做到的。通过巧妙地设置不同的斜率,神经网络可以近似任意函数。在网络的最后一层,它可以将前面的线性运算的输出集中到给定的范围内。下面看这第2个作用的几个具体例子。 限制输出范围 比如,限制在 [a, b] 这样的范围。这可以调用 torch.nn.Hardtanh()的简单激活函数。注意,默认的范围是 [-1, 1] 这里“限制”的意思是,强行设置。比如大于1的就强行设为1. 压缩输出范围 这一类的代表有 torch.nn.Sigmoid(), torch.tanh(), 1/(1+e**-x)等。 效果类似于,x趋于负无穷大时,y趋于0或-1; x趋于正无穷大时,y趋于1. 举个例子,识别一张图片是否是狗的图片。 结果越接近-1,越不可能是狗;越接近1,越可能是狗;0附近的不易判别。 给出车辆、狗、熊,一共3张图片。 车辆在倒数第2层输出 -2.2, 那么,math.tanh(-2.2)= -0.97熊在倒数第2层输出0.1, 那么,math.tanh(0.1)= 0.09狗在倒数第2层输出2.5, 那么, math.tanh(2.5)= 0.98关于更多的激活函数的信息,请参见以下的图片部分。 我们仍然使用前面讲过的温度计的例子,来完成一个神经网络。之前的神经网络是只有一层的、线性的神经网络;这里我们来做一个3层的神经网络,因为将包含激活函数。 为保证文章的完整性,再将问题描述如下: 假设有一个温度计,它本没有刻度和单位;我们给它标上刻度,然后用摄氏温度来解释这个特殊温度计测量值;即,给定特殊温度计的读数,将其翻译成摄氏度。 2.1 PyTorch 的 nn 模块首先,PyTorch 有一个专门用于神经网络的子模块,叫做 torch.nn, 它包含创建各种神经网络结构所需的构建块。(在PyTorch中,这些构建块称为模块;在其他框架中,这样的构建块称为层) PyTorch 模块派生自基类 nn.Module, 一个模块可以有一个或多个参数实例作为属性,这些参数实例是张量,它们的值在训练过程中得到了优化(如线性模型中的w和b)。 一个模块还可以有一个或多个子模块(nn.Module的子类)作为属性,并且它还能追踪它们的属性。子模块必须是顶级属性,而不是隐藏在列表或dict中,否则优化器无法定位子模块及它们的参数。 2.2 替换线性模型nn.Linear是一个关于线性模型的类。它的构造函数接收3个参数: 输入特征的数量输出特征的数量线性模型是否包含偏置,默认为True看一段代码: import torch.nn as nn linear_model = nn.Linear(1, 1) # 输入只有1个特征,输出也只有1个特征 linear_model(t_un_val) # t_un_val 是一个代表输入的张量 optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)解释: linear_model是 nn.Linear类的一个实例,其构造函数用(1,1) 来初始化,代表输入和输出都是只有一个特征;linear_model(t_un_val)是调用了 __call__()方法,相当于 linear_model.__call__(t_un_val)这里想让模型跑起来,所以貌似可以调用 forward()方法,但是一般不能这么做。 因为在__call__()方法的实现中,不仅调用了forward(),还调用了若干hook函数。所以如果我们仅仅调用forward()方法,这些hook函数就不会被调到从而引起错误。在构建SGD优化器实例的时候,将线性模型的参数传递给该优化器的构造函数的第一个参数另外,nn包含几个常见的损失函数,其中 nn.MSELoss()就是均方误差,和我们之前定义的 loss_fn一样。因此,我们可以直接调用 MSELoss(), 而不再需要手写损失函数了。 2.3 构建神经网络下面构建一个最终的神经网络:一个线性模块 => 一个激活函数 => 另一个线性模块 第一个线性模块+激活层通常也被称为隐藏层,因为它的输出并不能被直接观察到; 第一个线性模块的输出通常大于1; 激活层用于:不同的单元对不同范围的输入做出响应,以增加模型的容量; 最后的线性层:获取激活层的输出,并将它们进行线性组合以产生最后的输出值。 nn提供了一种通过 nn.Sequential容器来连接模型的方式. 这里指定第1层的输出张量的大小为10,这基本可以随意指定一个值; 第3层的输出张量的大小需要和第1层的输出张量的大小一致; 最后的 seq_model 就是一个3层的神经网络模型了。 seq_model = nn.Sequential( nn.Linear(1, 10), nn.Tanh(), nn.Linear(10, 1))调用 seq_model.parameters()将从第1个和第2个线性模块收集权重和偏置; 将来在调用 seq_model.backward()之后,所有参数都填充了它们的梯度; 然后优化器在调用 optimizer.step()期间会更新这些参数的值。 nn.Sequential也接受 OrderedDict, 可以用它来命名每个模块。 from collections import OrderedDict seq_model = nn.Sequential(OrderedDict([ ('hidden_linear', nn.Linear(1, 10)), ('hidden_activation', nn.Tanh()), ('output_linear', nn.Linear(10, 1)) ])) 2.4 完整的程序完整程序如下: import numpy as np import torch import torch.optim as optim import torch.nn as nn from collections import OrderedDict from matplotlib import pyplot as plt def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val, t_c_train, t_c_val): for epoch in range(1, n_epochs + 1): t_p_train = model(t_u_train) loss_train = loss_fn(t_p_train, t_c_train) t_p_val = model(t_u_val) # 前向传播,计算出预测值 loss_val = loss_fn(t_p_val, t_c_val) # 计算损失,只是为了打印 optimizer.zero_grad() # 梯度清零 loss_train.backward() # 利用前向图计算梯度 optimizer.step() # 利用梯度,更新参数 if epoch == 1 or epoch % 1000 == 0: print(f"Epoch {epoch}, Training loss {loss_train.item():.4f}," f" Validation loss {loss_val.item():.4f}") # 共11个元素的向量(1维张量) t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0] t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4] # 增加一个维度,即增加维度1,且该维度上只有1个元素,变成 torch.Size([11,1]) 的形状 t_c = torch.tensor(t_c).unsqueeze(1) t_u = torch.tensor(t_u).unsqueeze(1) n_samples = t_u.shape[0] # 11个元素 n_val = int(0.2 * n_samples) # 2, 代表评估集大小 shuffled_indices = torch.randperm(n_samples) # 产生11个随机数,但范围是0-10 train_indices = shuffled_indices[:-n_val] # 训练集,取前9个随机数作为index val_indices = shuffled_indices[-n_val:] # 评估集,取后2个随机数作为index # 特殊用法,即按照index,取出相应的元素组成Tensor,下面是训练集 t_u_train = t_u[train_indices] t_c_train = t_c[train_indices] # 下面是评估集 t_u_val = t_u[val_indices] t_c_val = t_c[val_indices] # 归一化处理 t_un_train = 0.1 * t_u_train t_un_val = 0.1 * t_u_val # 神经元层的神经元数量 neuron_count = 20 # 构建3层神经网络 seq_model = nn.Sequential(OrderedDict([ ('hidden_linear', nn.Linear(1, neuron_count)), ('hidden_activation', nn.Tanh()), ('output_linear', nn.Linear(neuron_count, 1)) ])) # 用整个模型的参数列表作为优化器构造函数的第一个参数 optimizer = optim.SGD(seq_model.parameters(), lr=1e-3) # 训练 training_loop( n_epochs = 5000, optimizer = optimizer, model = seq_model, loss_fn = nn.MSELoss(), t_u_train = t_un_train, t_u_val = t_un_val, t_c_train = t_c_train, t_c_val = t_c_val) # seq_model 已训练完毕,下面开始作图 t_range = torch.arange(20., 90.).unsqueeze(1) fig = plt.figure(dpi=150) plt.xlabel("Fahrenheit") plt.ylabel("Celsius") plt.plot(t_u.numpy(), t_c.numpy(), 'o') # detach() returns a tensor; numpy() returns numpy.ndarray plt.plot(t_range.numpy(), seq_model(0.1 * t_range).detach().numpy(), 'c-') plt.plot(t_u.numpy(), seq_model(0.1 * t_u).detach().numpy(), 'kx') plt.show()运行的输出是: python nn_plot.py Epoch 1, Training loss 184.2818, Validation loss 231.0507 Epoch 1000, Training loss 3.2540, Validation loss 6.3815 Epoch 2000, Training loss 2.7581, Validation loss 8.6664 Epoch 3000, Training loss 1.9816, Validation loss 6.5488 Epoch 4000, Training loss 1.7593, Validation loss 5.7282 Epoch 5000, Training loss 1.6765, Validation loss 5.3717显示的图片如下: (完) |


【本文地址】
今日新闻 |
推荐新闻 |