图神经网络:GAT学习、理解、入坑 |
您所在的位置:网站首页 › 神经网络的理解是什么意思 › 图神经网络:GAT学习、理解、入坑 |
图神经网络:GAT学习、理解、入坑
|
介绍
论文地址-GRAPH ATTENTION NETWORKS-Published as a conference paper at ICLR 2018 tensorflow代码版本源码地址 pyGAT-pytorch源码地址 keras-gat 边预测任务-GraphSAGE 原理初步理解GAT(Graph Attention Networks)采用Attention机制来学习邻居节点的权重,通过对邻居节点的加权求和来获得节点本身的表达。 给定图 G = ( V , E ) G = (V,E) G=(V,E), V V V 表示点, E E E 表示边,节点的个数 ∣ V ∣ = N |V| = N ∣V∣=N。 输入: N N N个节点的特征, h = { h ⃗ 1 , h ⃗ 2 , … , h ⃗ N } , h ⃗ i ∈ R F \mathbf{h}=\left\{\vec{h}_{1}, \vec{h}_{2}, \ldots, \vec{h}_{N}\right\}, \vec{h}_{i} \in \mathbb{R}^{F} h={h 1,h 2,…,h N},h i∈RF 输出:采用 Attention机制生成新的节点特征 h ′ = { h ⃗ 1 ′ , h ⃗ 2 ′ , … , h ⃗ N ′ } , h ⃗ i ′ ∈ R F ′ \mathbf{h^{\prime}}=\left\{\vec{h}_{1}^{\prime}, \vec{h}_{2}^{\prime}, \ldots, \vec{h}_{N}^{\prime}\right\}, \vec{h}_{i}^{\prime} \in \mathbb{R}^{F^{\prime}} h′={h 1′,h 2′,…,h N′},h i′∈RF′ 作为输出. 从GNN,GCN到GAT GNN学习的是邻居节点聚合到中心的方式,传统的GNN对于邻居节点采用求和/求平均的方式,各个邻居的权重相等为1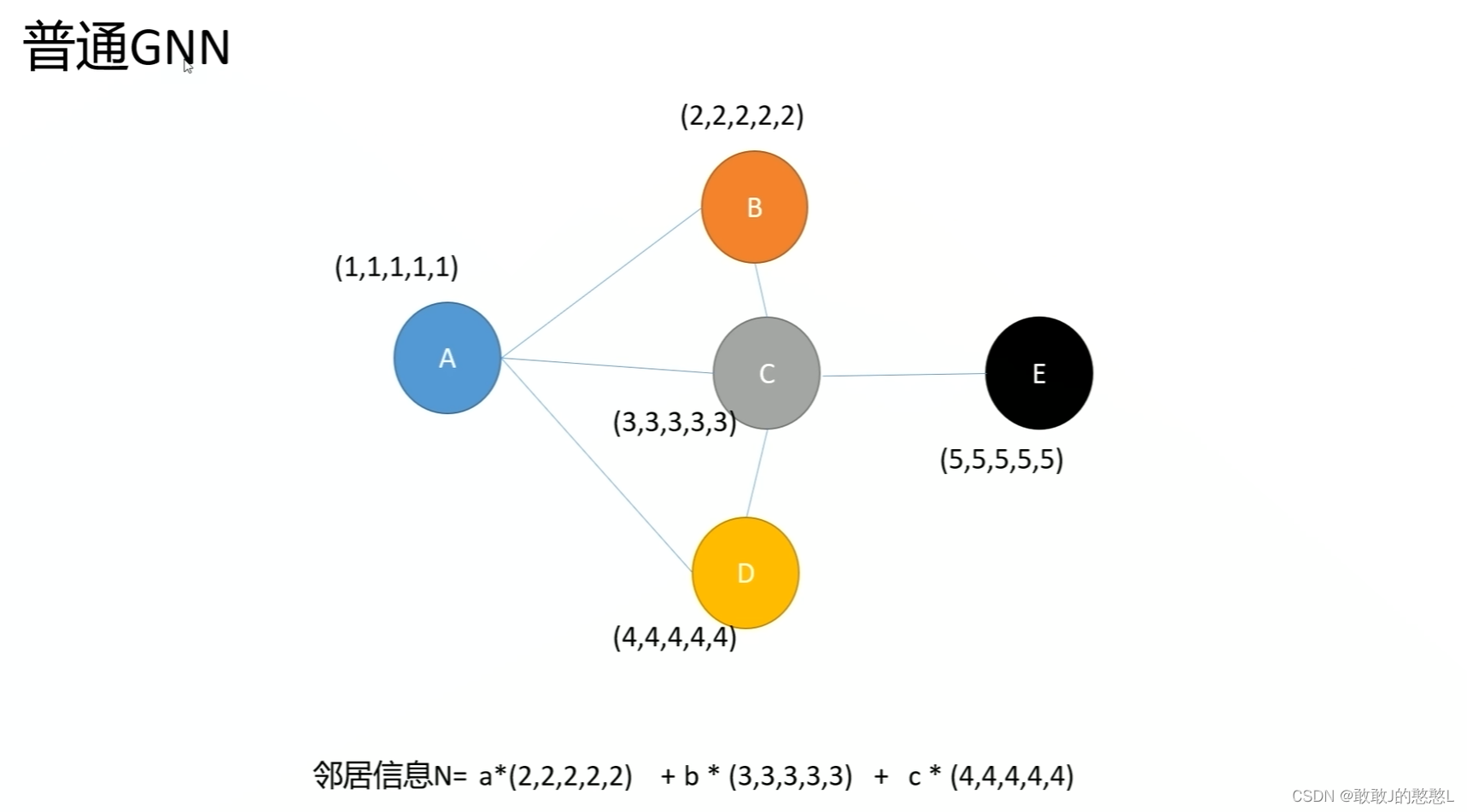 GCN进行了改造邻居聚合方式为邻接矩阵做对称归一化,也是类似求平均,但是它考虑到了节点的度大小,度越大权重往小了修正,是一种避免单节点链接巨量节点导致计算失真的调整方式,仅仅通过度+规则对权重做了修改,而没有考虑到因为节点的影响大小去调整权重的大小。 GCN进行了改造邻居聚合方式为邻接矩阵做对称归一化,也是类似求平均,但是它考虑到了节点的度大小,度越大权重往小了修正,是一种避免单节点链接巨量节点导致计算失真的调整方式,仅仅通过度+规则对权重做了修改,而没有考虑到因为节点的影响大小去调整权重的大小。 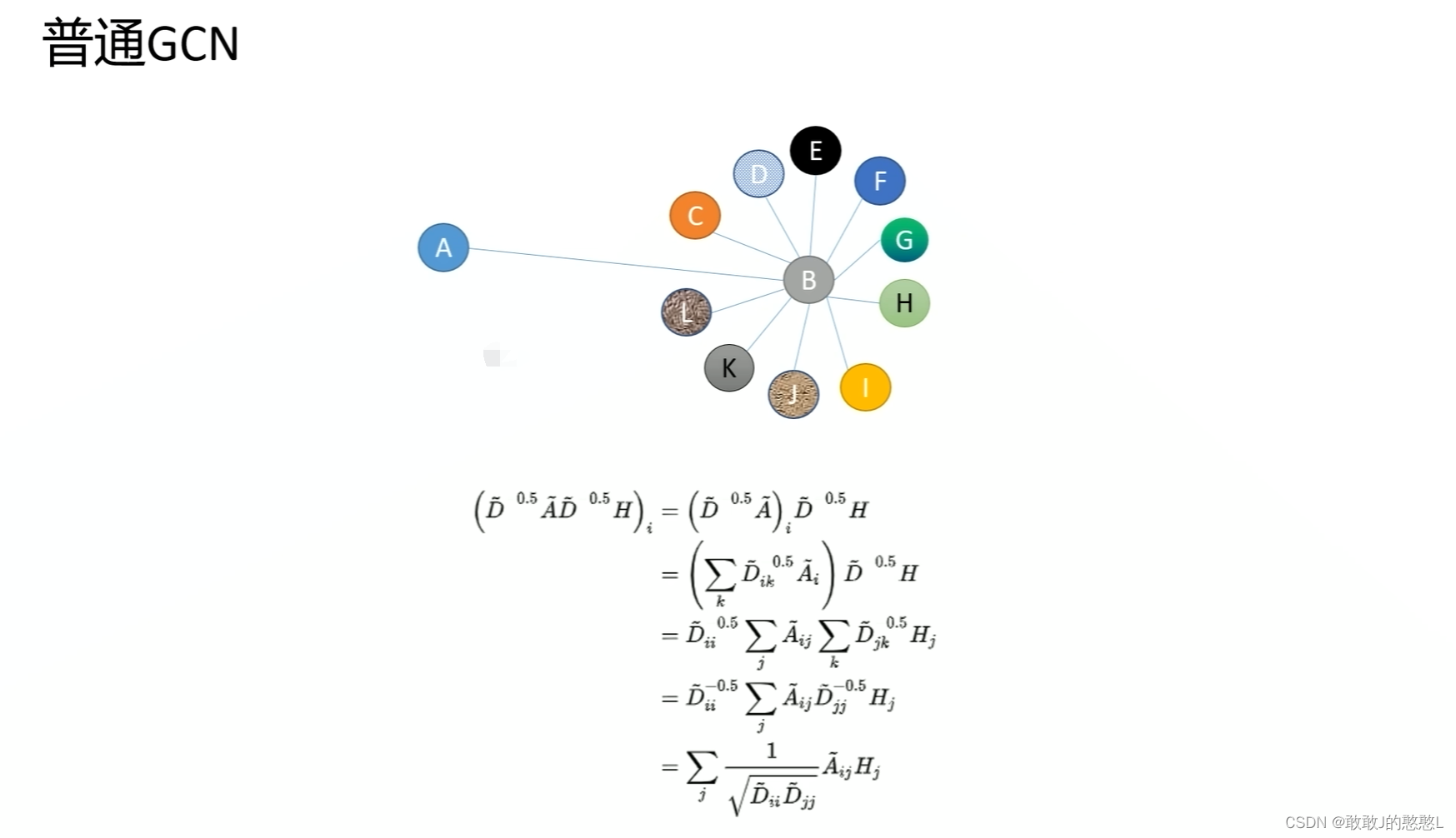 GAT认为 (1).不同邻居对中心节点的影响是不一样的,且它想通过注意力自动地去学习这个权重参数,从而提升表征能力 (2).GAT使用邻居和中心节点各自的特征属性来确定权重,中心节点的所有邻居的权重相加等于1 GAT认为 (1).不同邻居对中心节点的影响是不一样的,且它想通过注意力自动地去学习这个权重参数,从而提升表征能力 (2).GAT使用邻居和中心节点各自的特征属性来确定权重,中心节点的所有邻居的权重相加等于1 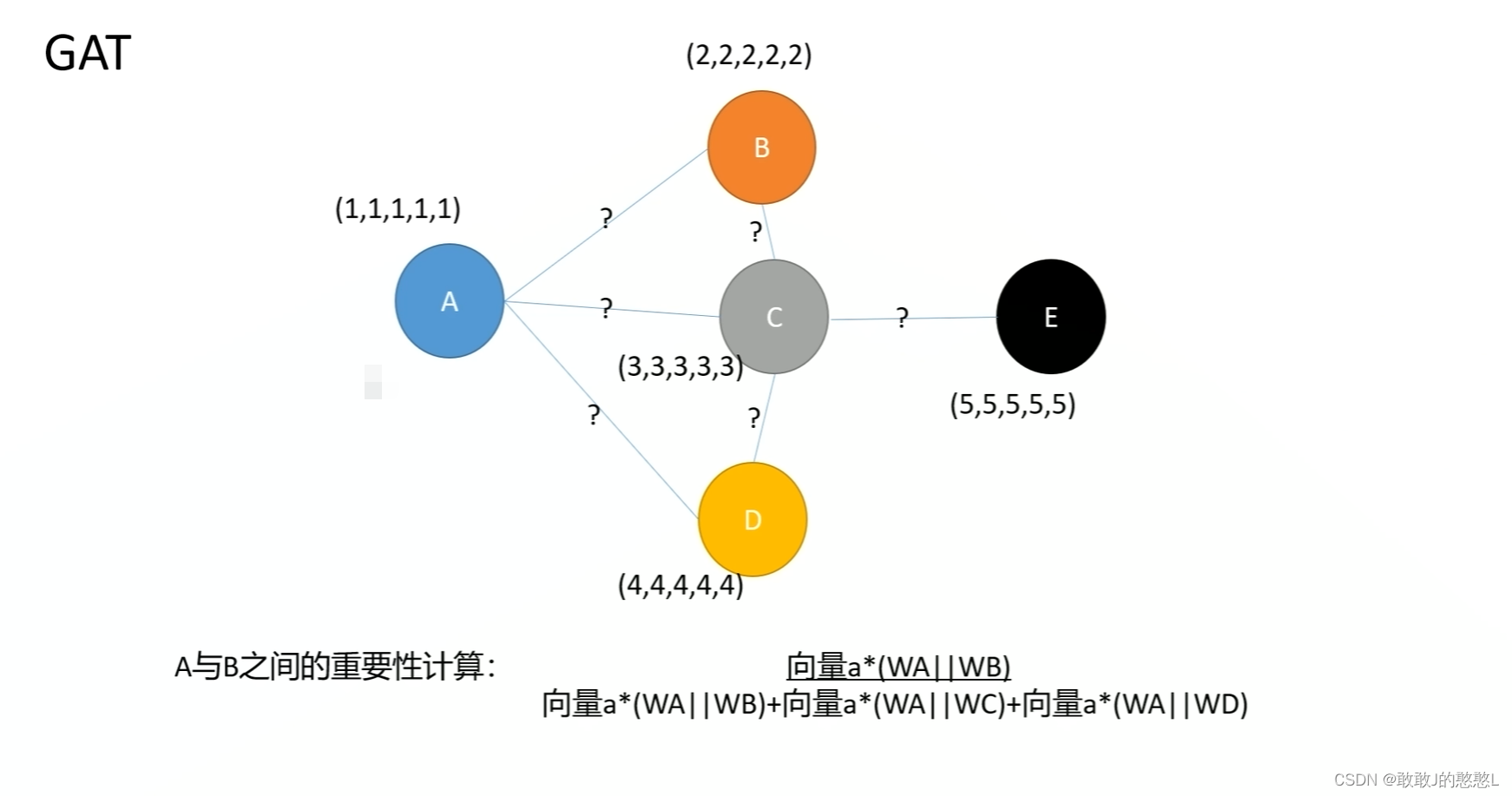 GAT模型
GAT模型
W就是可以训练的参数,分别用来针对向量A/B/…等进行操作(转置) “||”:拼接操作,“*”:内积 参数a也可以通过网络训练得到。 两个节点的权重需要基于两个节点的特征 如果将注意力机制引入到其他框架,需要将计算注意力分数的代码加到其他框架中,并且将“计算注意力分数”相关的变量定义成可训练的变量(在Pytorch中通常定义为Parameter或者Variable),将计算出的结果(可训练的张量)直接参与到“别的框架”中。需要记住的是,这些计算出的分数必须参与到“别的框架”的目标函数中(不论是隐式还是显式地参与),这样才能保证反向传播时,梯度能够从目标函数传播回来,从而根据梯度更新“计算注意力分数”所相关的那些变量。需要记住的是,仅仅将计算出的注意力分数的数值传到别的框架去是不奏效的,因为没有梯度从(别的框架的)目标函数传回来的话,将会计算注意力所关联的那些变量一直不受梯度的影响,从而一直不更新,这样的话不论计算多少次,计算出的注意力分数都将是不变的值。 代码实现 样例一首先,定义GraphAttentionLayer层,实现单个注意力机制层。 class GraphAttentionLayer(nn.Module): def __init__(self, in_features, out_features, dropout, alpha, concat=True): super(GraphAttentionLayer, self).__init__() self.dropout = dropout self.in_features = in_features self.out_features = out_features self.alpha = alpha self.concat = concat self.W = nn.Parameter(torch.zeros(size=(in_features, out_features))) nn.init.xavier_uniform_(self.W.data, gain=1.414) self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1))) nn.init.xavier_uniform_(self.a.data, gain=1.414) self.leakyrelu = nn.LeakyReLU(self.alpha) def forward(self, input, adj): h = torch.mm(input, self.W) # shape [N, out_features] N = h.size()[0] # 生成N*N的嵌入,repeat两次,两种方式,这个地方应该是为了把不同的sample拼接。为下一步求不同样本交互做准备。 a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features) # shape[N, N, 2*out_features] e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2)) # [N,N,1] -> [N,N] zero_vec = -9e15*torch.ones_like(e) attention = torch.where(adj > 0, e, zero_vec) attention = F.softmax(attention, dim=1) attention = F.dropout(attention, self.dropout, training=self.training) h_prime = torch.matmul(attention, h) # [N,N], [N, out_features] --> [N, out_features] if self.concat: return F.elu(h_prime) else: return h_prime接下来,定义GAT层,用于实现完整的网络模型。 class GAT(nn.Module): def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads): super(GAT, self).__init__() self.dropout = dropout self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)] for i, attention in enumerate(self.attentions): self.add_module('attention_{}'.format(i), attention) self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False) def forward(self, x, adj): x = F.dropout(x, self.dropout, training=self.training) x = torch.cat([att(x, adj) for att in self.attentions], dim=1) x = F.dropout(x, self.dropout, training=self.training) x = F.elu(self.out_att(x, adj)) return F.log_softmax(x, dim=1)最后,对模型进行训练,优化模型。 model = GAT(nfeat=features.shape[1], nhid=args.hidden, nclass=int(labels.max()) + 1, dropout=args.dropout, nheads=args.nb_heads, alpha=args.alpha) optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay) features, adj, labels = Variable(features), Variable(adj), Variable(labels) def train(epoch): t = time.time() model.train() optimizer.zero_grad() output = model(features, adj) loss_train = F.nll_loss(output[idx_train], labels[idx_train]) acc_train = accuracy(output[idx_train], labels[idx_train]) loss_train.backward() optimizer.step() if not args.fastmode: model.eval() output = model(features, adj) loss_val = F.nll_loss(output[idx_val], labels[idx_val]) acc_val = accuracy(output[idx_val], labels[idx_val]) print('Epoch: {:04d}'.format(epoch+1), 'loss_train: {:.4f}'.format(loss_train.data.item()), 'acc_train: {:.4f}'.format(acc_train.data.item()), 'loss_val: {:.4f}'.format(loss_val.data.item()), 'acc_val: {:.4f}'.format(acc_val.data.item()), 'time: {:.4f}s'.format(time.time() - t)) return loss_val.data.item()如果要处理的图带有边的权重或者边特征的话,GAT怎么处理呢? 边的特征可以在计算 e i j e_{ij} eij 的时候加入吧,我的理解是这样的,拼接的时候把边的特征也拼上。 原论文提到多头注意力机制,在最后一层GAT之前可以用cat操作,最后一层最好用avg,作者在上 面代码中是不是实现了两层的GAT,第一层用cat实现了一个多头的注意力,而在第二层就是一个简单的注意力机制(没有多头的cat和avg),然后输出,如果我要实现文章中的avg是不是要自己实现一下 样例二1、train.py from __future__ import division from __future__ import print_function import os import glob import time import random import argparse import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.autograd import Variable from utils import load_data, accuracy from models import GAT, SpGAT # Training settings parser = argparse.ArgumentParser() parser.add_argument('--no-cuda', action='store_true', default=False, help='Disables CUDA training.') parser.add_argument('--fastmode', action='store_true', default=False, help='Validate during training pass.') parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.') parser.add_argument('--seed', type=int, default=72, help='Random seed.') parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.') parser.add_argument('--lr', type=float, default=0.005, help='Initial learning rate.') parser.add_argument('--weight_decay', type=float, default=5e-4, help='Weight decay (L2 loss on parameters).') parser.add_argument('--hidden', type=int, default=8, help='Number of hidden units.') parser.add_argument('--nb_heads', type=int, default=8, help='Number of head attentions.') parser.add_argument('--dropout', type=float, default=0.6, help='Dropout rate (1 - keep probability).') parser.add_argument('--alpha', type=float, default=0.2, help='Alpha for the leaky_relu.') parser.add_argument('--patience', type=int, default=100, help='Patience') args = parser.parse_args() args.cuda = not args.no_cuda and torch.cuda.is_available() random.seed(args.seed) np.random.seed(args.seed) torch.manual_seed(args.seed) if args.cuda: torch.cuda.manual_seed(args.seed) # Load data adj, features, labels, idx_train, idx_val, idx_test = load_data() #labels是标量数值型的标签,adj是D^{-0.5}SD^{-0.5}, S=A+I # Model and optimizer if args.sparse: model = SpGAT(nfeat=features.shape[1], nhid=args.hidden, nclass=int(labels.max()) + 1, dropout=args.dropout, nheads=args.nb_heads, alpha=args.alpha) else: model = GAT(nfeat=features.shape[1], nhid=args.hidden, nclass=int(labels.max()) + 1, dropout=args.dropout, nheads=args.nb_heads, alpha=args.alpha) optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay) if args.cuda: model.cuda() features = features.cuda() adj = adj.cuda() labels = labels.cuda() idx_train = idx_train.cuda() idx_val = idx_val.cuda() idx_test = idx_test.cuda() features, adj, labels = Variable(features), Variable(adj), Variable(labels) #在PyTorch中计算图的特点:autograd根据用户对Variable的操作来构建其计算图。 #Variable计算时,它会逐渐地生成计算图。这个图就是将所有的计算节点都连接起来,最后进行误差反向传递的时候,一次性将所有Variable里面的梯度都计算出来,而tensor就没有这个能力。 #tensor不能反向传播,variable可以反向传播。 #variable默认是不需要被求导的,即requires_grad属性默认为False def train(epoch): t = time.time() model.train() optimizer.zero_grad() output = model(features, adj) loss_train = F.nll_loss(output[idx_train], labels[idx_train]) acc_train = accuracy(output[idx_train], labels[idx_train]) loss_train.backward() optimizer.step() if not args.fastmode: # Evaluate validation set performance separately, # deactivates dropout during validation run. model.eval() output = model(features, adj) loss_val = F.nll_loss(output[idx_val], labels[idx_val]) acc_val = accuracy(output[idx_val], labels[idx_val]) print('Epoch: {:04d}'.format(epoch+1), 'loss_train: {:.4f}'.format(loss_train.data.item()), 'acc_train: {:.4f}'.format(acc_train.data.item()), 'loss_val: {:.4f}'.format(loss_val.data.item()), 'acc_val: {:.4f}'.format(acc_val.data.item()), 'time: {:.4f}s'.format(time.time() - t)) return loss_val.data.item() def compute_test(): model.eval() output = model(features, adj) loss_test = F.nll_loss(output[idx_test], labels[idx_test]) acc_test = accuracy(output[idx_test], labels[idx_test]) print("Test set results:", "loss= {:.4f}".format(loss_test.data[0]), "accuracy= {:.4f}".format(acc_test.data[0])) # Train model t_total = time.time() loss_values = [] bad_counter = 0 best = args.epochs + 1 best_epoch = 0 for epoch in range(args.epochs): loss_values.append(train(epoch)) torch.save(model.state_dict(), '{}.pkl'.format(epoch)) if loss_values[-1] adj) - adj.multiply(adj.T > adj) features = normalize_features(features) adj = normalize_adj(adj + sp.eye(adj.shape[0])) #adj = D^{-0.5}SD^{-0.5}, S=A+I idx_train = range(140) idx_val = range(200, 500) idx_test = range(500, 1500) adj = torch.FloatTensor(np.array(adj.todense())) features = torch.FloatTensor(np.array(features.todense())) labels = torch.LongTensor(np.where(labels)[1]) #torch.Tensor默认是torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型 #np.where(condition, x, y),满足条件(condition),输出x,不满足输出y. #只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero) #这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。取[1]则是列坐标 #所以labels是标量数值型的标签 idx_train = torch.LongTensor(idx_train) idx_val = torch.LongTensor(idx_val) idx_test = torch.LongTensor(idx_test) return adj, features, labels, idx_train, idx_val, idx_test def normalize_adj(mx): """Row-normalize sparse matrix""" rowsum = np.array(mx.sum(1)) #求每一行的和 r_inv_sqrt = np.power(rowsum, -0.5).flatten() #D^{-0.5} r_inv_sqrt[np.isinf(r_inv_sqrt)] = 0. r_mat_inv_sqrt = sp.diags(r_inv_sqrt) #D^{-0.5} return mx.dot(r_mat_inv_sqrt).transpose().dot(r_mat_inv_sqrt) # mx.dot(r_mat_inv_sqrt).transpose()是(AD^{-0.5})^T # mx.dot(r_mat_inv_sqrt).transpose().dot(r_mat_inv_sqrt)是(AD^{-0.5})^T·D^{-0.5}=D^{-0.5}AD^{-0.5} def normalize_features(mx): """Row-normalize sparse matrix""" rowsum = np.array(mx.sum(1)) r_inv = np.power(rowsum, -1).flatten() r_inv[np.isinf(r_inv)] = 0. r_mat_inv = sp.diags(r_inv) mx = r_mat_inv.dot(mx) return mx def accuracy(output, labels): preds = output.max(1)[1].type_as(labels) #max(1)返回每一行中最大值的那个元素所构成的一维张量,且返回对应的一维索引张量(返回最大元素在这一行的列索引) correct = preds.eq(labels).double() correct = correct.sum() return correct / len(labels)3、models.py import torch import torch.nn as nn import torch.nn.functional as F from layers import GraphAttentionLayer, SpGraphAttentionLayer class GAT(nn.Module): def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads): """Dense version of GAT.""" super(GAT, self).__init__() self.dropout = dropout self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)] for i, attention in enumerate(self.attentions): self.add_module('attention_{}'.format(i), attention) #add_module是Module类的成员函数,输入参数为Module.add_module(name: str, module: Module)。功能为,为Module添加一个子module,对应名字为name #add_module()函数也可以在GAT.init(self)以外定义A的子模块 self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False) #输出层的输入张量的shape之所以为(nhid * nheads, nclass)是因为在forward函数中多个注意力机制在同一个节点上得到的多个不同特征被拼接成了一个长的特征 def forward(self, x, adj): x = F.dropout(x, self.dropout, training=self.training) x = torch.cat([att(x, adj) for att in self.attentions], dim=1) #将多个注意力机制在同一个节点上得到的多个不同特征进行拼接形成一个长特征 x = F.dropout(x, self.dropout, training=self.training) x = F.elu(self.out_att(x, adj)) #该行代码即完成原文中的式子(6) return F.log_softmax(x, dim=1) #F.log_softmax在数学上等价于log(softmax(x)),但做这两个单独操作速度较慢,数值上也不稳定。这个函数使用另一种公式来正确计算输出和梯度 class SpGAT(nn.Module): def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads): """Sparse version of GAT.""" super(SpGAT, self).__init__() self.dropout = dropout self.attentions = [SpGraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)] for i, attention in enumerate(self.attentions): self.add_module('attention_{}'.format(i), attention) self.out_att = SpGraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False) def forward(self, x, adj): x = F.dropout(x, self.dropout, training=self.training) x = torch.cat([att(x, adj) for att in self.attentions], dim=1) x = F.dropout(x, self.dropout, training=self.training) x = F.elu(self.out_att(x, adj)) return F.log_softmax(x, dim=1)4、layer.py import numpy as np import torch import torch.nn as nn import torch.nn.functional as F class GraphAttentionLayer(nn.Module): """ Simple GAT layer, similar to https://arxiv.org/abs/1710.10903 """ def __init__(self, in_features, out_features, dropout, alpha, concat=True): super(GraphAttentionLayer, self).__init__() self.dropout = dropout self.in_features = in_features self.out_features = out_features self.alpha = alpha self.concat = concat self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))#empty()创建任意数据类型的张量,torch.tensor()只创建torch.FloatTensor类型的张量 nn.init.xavier_uniform_(self.W.data, gain=1.414) #orch.nn.init.xavier_uniform_是一个服从均匀分布的Glorot初始化器,参见:Glorot, X. & Bengio, Y. (2010). Understanding the difficulty of training deep feedforward neural networks. self.a = nn.Parameter(torch.empty(size=(2*out_features, 1))) #遵从原文,a是shape为(2×F',1)的张量 nn.init.xavier_uniform_(self.a.data, gain=1.414) self.leakyrelu = nn.LeakyReLU(self.alpha) def forward(self, h, adj): Wh = torch.mm(h, self.W) # h.shape: (N, in_features), Wh.shape: (N, out_features) a_input = self._prepare_attentional_mechanism_input(Wh) #实现论文中的特征拼接操作 Wh_i||Wh_j ,得到一个shape = (N , N, 2 * out_features)的新特征矩阵 e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2)) #torch.matmul(a_input, self.a)的shape=(N,N,1),经过squeeze(2)后,shape变为(N,N) zero_vec = -9e15*torch.ones_like(e) attention = torch.where(adj > 0, e, zero_vec) #np.where(condition, x, y),满足条件(condition),输出x,不满足输出y. attention = F.softmax(attention, dim=1) #对每一行内的数据做归一化 attention = F.dropout(attention, self.dropout, training=self.training) h_prime = torch.matmul(attention, Wh) #当输入是都是二维时,就是普通的矩阵乘法,和tensor.mm函数用法相同 #h_prime.shape=(N,out_features) if self.concat: return F.elu(h_prime) else: return h_prime def _prepare_attentional_mechanism_input(self, Wh): N = Wh.size()[0] # number of nodes # Below, two matrices are created that contain embeddings in their rows in different orders. # (e stands for embedding) # These are the rows of the first matrix (Wh_repeated_in_chunks): # e1, e1, ..., e1, e2, e2, ..., e2, ..., eN, eN, ..., eN # '-------------' -> N times '-------------' -> N times '-------------' -> N times # # These are the rows of the second matrix (Wh_repeated_alternating): # e1, e2, ..., eN, e1, e2, ..., eN, ..., e1, e2, ..., eN # '----------------------------------------------------' -> N times # Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0) #repeat_interleave(self: Tensor, repeats: _int, dim: Optional[_int]=None) #参数说明: #self: 传入的数据为tensor #repeats: 复制的份数 #dim: 要复制的维度,可设定为0/1/2..... Wh_repeated_alternating = Wh.repeat(N, 1) #repeat方法可以对 Wh 张量中的单维度和非单维度进行复制操作,并且会真正的复制数据保存到内存中 #repeat(N, 1)表示dim=0维度的数据复制N份,dim=1维度的数据保持不变 # Wh_repeated_in_chunks.shape == Wh_repeated_alternating.shape == (N * N, out_features) # The all_combination_matrix, created below, will look like this (|| denotes concatenation): # e1 || e1 # e1 || e2 # e1 || e3 # ... # e1 || eN # e2 || e1 # e2 || e2 # e2 || e3 # ... # e2 || eN # ... # eN || e1 # eN || e2 # eN || e3 # ... # eN || eN all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1) # all_combinations_matrix.shape == (N * N, 2 * out_features) return all_combinations_matrix.view(N, N, 2 * self.out_features) def __repr__(self): return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')' class SpecialSpmmFunction(torch.autograd.Function): #虽然pytorch可以自动求导,但是有时候一些操作是不可导的,这时候你需要自定义求导方式。也就是所谓的 “Extending torch.autograd” # 创建torch.autograd.Function类的一个子类 # 必须是staticmethod @staticmethod def forward(ctx, indices, values, shape, b): #forward()可以有任意多个输入、任意多个输出 # 第一个是ctx,第二个是input,其他是可选参数。 # ctx在这里类似self,ctx的属性可以在backward中调用。 # 自己定义的Function中的forward()方法,所有的Variable参数将会转成tensor!因此这里的input也是tensor.在传入forward前,autograd engine会自动将Variable unpack成Tensor。 assert indices.requires_grad == False #检查条件,不符合就终止程序 a = torch.sparse_coo_tensor(indices, values, shape) ctx.save_for_backward(a, b) # 将Tensor转变为Variable保存到ctx中,在backward中需要这些变量 ctx.N = shape[0] return torch.matmul(a, b) @staticmethod def backward(ctx, grad_output): #backward()的输入和输出的个数就是forward()函数的输出和输入的个数。其中,backward()的输入表示关于forward()的输出的梯度(计算图中上一节点的梯度), #backward()的输出表示关于forward()的输入的梯度。在输入不需要梯度时(通过查看needs_input_grad参数)或者不可导时,可以返回None。 a, b = ctx.saved_tensors grad_values = grad_b = None if ctx.needs_input_grad[1]: # 判断forward()输入的Variable(不包括上下文ctx)是否需要进行反向求导计算梯度 grad_a_dense = grad_output.matmul(b.t()) edge_idx = a._indices()[0, :] * ctx.N + a._indices()[1, :] grad_values = grad_a_dense.view(-1)[edge_idx] if ctx.needs_input_grad[3]: grad_b = a.t().matmul(grad_output) return None, grad_values, None, grad_b class SpecialSpmm(nn.Module): def forward(self, indices, values, shape, b): return SpecialSpmmFunction.apply(indices, values, shape, b) #调用SpecialSpmmFunctionde1的forward() class SpGraphAttentionLayer(nn.Module): """ Sparse version GAT layer, similar to https://arxiv.org/abs/1710.10903 """ def __init__(self, in_features, out_features, dropout, alpha, concat=True): super(SpGraphAttentionLayer, self).__init__() self.in_features = in_features self.out_features = out_features self.alpha = alpha self.concat = concat self.W = nn.Parameter(torch.zeros(size=(in_features, out_features))) nn.init.xavier_normal_(self.W.data, gain=1.414) self.a = nn.Parameter(torch.zeros(size=(1, 2*out_features))) nn.init.xavier_normal_(self.a.data, gain=1.414) self.dropout = nn.Dropout(dropout) self.leakyrelu = nn.LeakyReLU(self.alpha) self.special_spmm = SpecialSpmm() def forward(self, input, adj): dv = 'cuda' if input.is_cuda else 'cpu' N = input.size()[0] edge = adj.nonzero().t() # edge:2 x E(E是边的数量) h = torch.mm(input, self.W) # h: N x out assert not torch.isnan(h).any() # Self-attention on the nodes - Shared attention mechanism edge_h = torch.cat((h[edge[0, :], :], h[edge[1, :], :]), dim=1).t() # edge: 2*D x E edge_e = torch.exp(-self.leakyrelu(self.a.mm(edge_h).squeeze())) #这里为什么加了-号,我不知道,反正原文没有。去掉符号最终准确率为0.839,不去掉就是0.84 assert not torch.isnan(edge_e).any() # edge_e: E e_rowsum = self.special_spmm(edge, edge_e, torch.Size([N, N]), torch.ones(size=(N,1), device=dv)) #special_spmm是我们定制的稀疏的矩阵乘法函数 # e_rowsum: N x 1 edge_e = self.dropout(edge_e) # edge_e: E h_prime = self.special_spmm(edge, edge_e, torch.Size([N, N]), h) assert not torch.isnan(h_prime).any() # h_prime: N x out h_prime = h_prime.div(e_rowsum) #除以每一行的“行和”,从而正则化 # h_prime: N x out assert not torch.isnan(h_prime).any() if self.concat: # if this layer is not last layer, return F.elu(h_prime) else: # if this layer is last layer, return h_prime def __repr__(self): return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')' 参考文献链接参考链接一 参考链接二 参考链接三 参考链接四 |
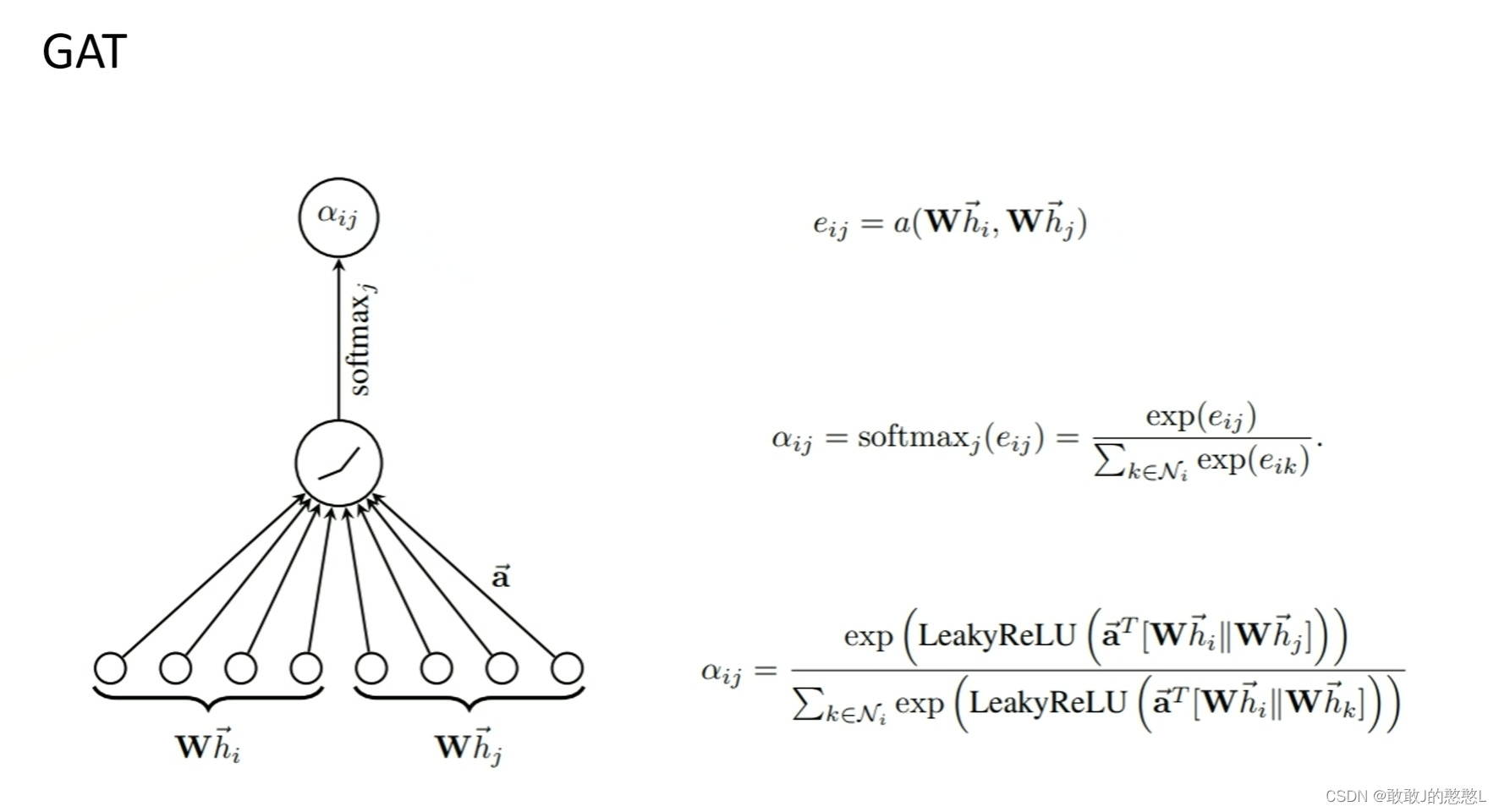 节点i的特征乘以W拼接上节点j的特征乘以W,再乘以
a
→
\overrightarrow{a}
a
,公式:(
(
W
h
i
→
∣
∣
W
h
j
→
)
∗
a
→
(W\overrightarrow{h_i}||W\overrightarrow{h_j})*\overrightarrow{a}
(Whi
∣∣Whj
)∗a
)。 首先 ,为了更加充分地表示节点的特征,对节点
h
i
h_i
hi 进行特征变换,
W
h
i
W h_i
Whi ,
W
∈
R
F
′
×
F
\mathbf{W} \in \mathbb{R}^{F^{\prime} \times F}
W∈RF′×F ,即将节点的特征维度
F
F
F映射到维度
F
′
F^{\prime}
F′上。关键的步骤来了,对图中的每个节点进行self-attention操作,计算任意两个节点之间的注意力权重。节点
j
j
j 对节点
i
i
i 的重要性计算公式如下:
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
e_{i j}=a\left(\mathbf{W} \vec{h}_{i}, \mathbf{W} \vec{h}_{j}\right)
eij=a(Wh
i,Wh
j) 一般而言,该模型允许图中的每个节点扩展到其他节点,从而丢弃所有结构信息。 原论文中,通过masked attention将图结构注入这个机制中,即对于节点 [公式] 来说,只计算其一阶邻居节点集合
N
i
N_i
Ni 中节点 对
i
i
i 的作用,
j
∈
N
i
j \in \mathcal{N}_{i}
j∈Ni。 为了使系数在不同节点之间易于比较,论文中使用softmax函数在集合
N
i
\mathcal{N}_{i}
Ni中对它们进行归一化,如下所示。在实验中,注意力机制是一个单层的前馈神经网络,激活函数采用LeakyReLU。
α
i
j
=
softmax
j
(
e
i
j
)
=
exp
(
e
i
j
)
∑
k
∈
N
i
exp
(
e
i
k
)
\alpha_{i j}=\operatorname{softmax}_{j}\left(e_{i j}\right)=\frac{\exp \left(e_{i j}\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(e_{i k}\right)}
αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij) Attention系数按如下方式生成:
α
i
j
=
exp
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
)
)
∑
k
∈
N
i
exp
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
k
]
)
)
\alpha_{i j}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{j}\right]\right)\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{k}\right]\right)\right)}
αij=∑k∈Niexp(LeakyReLU(a
T[Wh
i∥Wh
k]))exp(LeakyReLU(a
T[Wh
i∥Wh
j])) 其中
a
→
∈
R
2
F
′
\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}
a
∈R2F′,而
∣
∣
||
∣∣表示concatenatoin(拼接)操作。 由于
a
→
∈
R
2
F
′
\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}
a
∈R2F′, 因此令
a
→
=
[
a
→
1
,
a
→
2
]
\overrightarrow{\mathbf{a}}=\left[\overrightarrow{\mathbf{a}}_{1}, \overrightarrow{\mathbf{a}}_{2}\right]
a
=[a
1,a
2] , 其中
a
→
1
∈
R
F
′
\overrightarrow{\mathbf{a}}_{1} \in \mathbb{R}^{F^{\prime}}
a
1∈RF′,
a
→
2
∈
R
F
′
\overrightarrow{\mathbf{a}}_{2} \in \mathbb{R}^{F^{\prime}}
a
2∈RF′ , 那么
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}^{j}\right]
a
T[Wh
i∥Wh
j] 其实等效于
a
→
1
T
W
h
⃗
i
+
a
→
2
T
W
h
⃗
j
\overrightarrow{\mathbf{a}}_{1}^{T} \mathbf{W} \vec{h}_{i}+\overrightarrow{\mathbf{a}}_{2}^{T} \mathbf{W} \vec{h}^{j}
a
1TWh
i+a
2TWh
j. 最终,将归一化的注意力系数与其对应的特征进行线性组合,以作为每个节点的最终输出特征。
h
⃗
i
′
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
⃗
j
)
\vec{h}_{i}^{\prime}=\sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j} \mathbf{W} \vec{h}_{j}\right)
h
i′=σ⎝
⎛j∈Ni∑αijWh
j⎠
⎞
节点i的特征乘以W拼接上节点j的特征乘以W,再乘以
a
→
\overrightarrow{a}
a
,公式:(
(
W
h
i
→
∣
∣
W
h
j
→
)
∗
a
→
(W\overrightarrow{h_i}||W\overrightarrow{h_j})*\overrightarrow{a}
(Whi
∣∣Whj
)∗a
)。 首先 ,为了更加充分地表示节点的特征,对节点
h
i
h_i
hi 进行特征变换,
W
h
i
W h_i
Whi ,
W
∈
R
F
′
×
F
\mathbf{W} \in \mathbb{R}^{F^{\prime} \times F}
W∈RF′×F ,即将节点的特征维度
F
F
F映射到维度
F
′
F^{\prime}
F′上。关键的步骤来了,对图中的每个节点进行self-attention操作,计算任意两个节点之间的注意力权重。节点
j
j
j 对节点
i
i
i 的重要性计算公式如下:
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
e_{i j}=a\left(\mathbf{W} \vec{h}_{i}, \mathbf{W} \vec{h}_{j}\right)
eij=a(Wh
i,Wh
j) 一般而言,该模型允许图中的每个节点扩展到其他节点,从而丢弃所有结构信息。 原论文中,通过masked attention将图结构注入这个机制中,即对于节点 [公式] 来说,只计算其一阶邻居节点集合
N
i
N_i
Ni 中节点 对
i
i
i 的作用,
j
∈
N
i
j \in \mathcal{N}_{i}
j∈Ni。 为了使系数在不同节点之间易于比较,论文中使用softmax函数在集合
N
i
\mathcal{N}_{i}
Ni中对它们进行归一化,如下所示。在实验中,注意力机制是一个单层的前馈神经网络,激活函数采用LeakyReLU。
α
i
j
=
softmax
j
(
e
i
j
)
=
exp
(
e
i
j
)
∑
k
∈
N
i
exp
(
e
i
k
)
\alpha_{i j}=\operatorname{softmax}_{j}\left(e_{i j}\right)=\frac{\exp \left(e_{i j}\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(e_{i k}\right)}
αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij) Attention系数按如下方式生成:
α
i
j
=
exp
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
)
)
∑
k
∈
N
i
exp
(
LeakyReLU
(
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
k
]
)
)
\alpha_{i j}=\frac{\exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{j}\right]\right)\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\operatorname{LeakyReLU}\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{k}\right]\right)\right)}
αij=∑k∈Niexp(LeakyReLU(a
T[Wh
i∥Wh
k]))exp(LeakyReLU(a
T[Wh
i∥Wh
j])) 其中
a
→
∈
R
2
F
′
\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}
a
∈R2F′,而
∣
∣
||
∣∣表示concatenatoin(拼接)操作。 由于
a
→
∈
R
2
F
′
\overrightarrow{\mathbf{a}} \in \mathbb{R}^{2 F^{\prime}}
a
∈R2F′, 因此令
a
→
=
[
a
→
1
,
a
→
2
]
\overrightarrow{\mathbf{a}}=\left[\overrightarrow{\mathbf{a}}_{1}, \overrightarrow{\mathbf{a}}_{2}\right]
a
=[a
1,a
2] , 其中
a
→
1
∈
R
F
′
\overrightarrow{\mathbf{a}}_{1} \in \mathbb{R}^{F^{\prime}}
a
1∈RF′,
a
→
2
∈
R
F
′
\overrightarrow{\mathbf{a}}_{2} \in \mathbb{R}^{F^{\prime}}
a
2∈RF′ , 那么
a
→
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}^{j}\right]
a
T[Wh
i∥Wh
j] 其实等效于
a
→
1
T
W
h
⃗
i
+
a
→
2
T
W
h
⃗
j
\overrightarrow{\mathbf{a}}_{1}^{T} \mathbf{W} \vec{h}_{i}+\overrightarrow{\mathbf{a}}_{2}^{T} \mathbf{W} \vec{h}^{j}
a
1TWh
i+a
2TWh
j. 最终,将归一化的注意力系数与其对应的特征进行线性组合,以作为每个节点的最终输出特征。
h
⃗
i
′
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
⃗
j
)
\vec{h}_{i}^{\prime}=\sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j} \mathbf{W} \vec{h}_{j}\right)
h
i′=σ⎝
⎛j∈Ni∑αijWh
j⎠
⎞  确保GAT更加稳定,使用多头注意力机制。通过中间的函数来实现多套注意力机制。 GAT采用Multi-Head Attention,图中有3种颜色的曲线,表示3个不同的Head。在不同的 Head 下,节点
h
1
→
\overrightarrow {h_{1}}
h1
可以学习到不同的embedding,然后将这些embedding进行concat/avg 便生成
h
1
′
→
\overrightarrow {h_{1}^{\prime}}
h1′
. 此外,为了稳定自我注意力的学习过程,论文中发现采用多头注意力(Multi-head Attention)扩展注意力对模型是有提升的。采用
K
K
K头注意力机制的两种计算公式如下:
h
⃗
i
′
=
∥
k
=
1
K
σ
(
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
(拼接方式)
\vec{h}_{i}^{\prime}=\|_{k=1}^{K} \sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j}\right)(拼接方式)
h
i′=∥k=1Kσ⎝
⎛j∈Ni∑αijkWkh
j⎠
⎞(拼接方式)
h
⃗
i
′
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
(
均值方式
)
\vec{h}_{i}^{\prime}=\sigma\left(\frac{1}{K} \sum_{k=1}^{K} \sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j}\right) (均值方式)
h
i′=σ⎝
⎛K1k=1∑Kj∈Ni∑αijkWkh
j⎠
⎞(均值方式)
确保GAT更加稳定,使用多头注意力机制。通过中间的函数来实现多套注意力机制。 GAT采用Multi-Head Attention,图中有3种颜色的曲线,表示3个不同的Head。在不同的 Head 下,节点
h
1
→
\overrightarrow {h_{1}}
h1
可以学习到不同的embedding,然后将这些embedding进行concat/avg 便生成
h
1
′
→
\overrightarrow {h_{1}^{\prime}}
h1′
. 此外,为了稳定自我注意力的学习过程,论文中发现采用多头注意力(Multi-head Attention)扩展注意力对模型是有提升的。采用
K
K
K头注意力机制的两种计算公式如下:
h
⃗
i
′
=
∥
k
=
1
K
σ
(
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
(拼接方式)
\vec{h}_{i}^{\prime}=\|_{k=1}^{K} \sigma\left(\sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j}\right)(拼接方式)
h
i′=∥k=1Kσ⎝
⎛j∈Ni∑αijkWkh
j⎠
⎞(拼接方式)
h
⃗
i
′
=
σ
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
j
k
W
k
h
⃗
j
)
(
均值方式
)
\vec{h}_{i}^{\prime}=\sigma\left(\frac{1}{K} \sum_{k=1}^{K} \sum_{j \in \mathcal{N}_{i}} \alpha_{i j}^{k} \mathbf{W}^{k} \vec{h}_{j}\right) (均值方式)
h
i′=σ⎝
⎛K1k=1∑Kj∈Ni∑αijkWkh
j⎠
⎞(均值方式)【本文地址】
今日新闻 |
推荐新闻 |