高斯径向基函数(RBF)神经网络 |
您所在的位置:网站首页 › 神经网络宽度是什么意思 › 高斯径向基函数(RBF)神经网络 |
高斯径向基函数(RBF)神经网络
|
高斯径向基函数(RBF)神经网络
牛顿插值法-知乎 泰勒公式 径向基函数-wiki 径向基网络之bp训练 RBF网络逼近能力及其算法 线性/非线性,使用”多项式“逼近非线性,通过调节超参数来改善多项式参数进一步拟合真实非线性。 1.径向基函数 2.RBF网络 3.RBF网络训练方法 4.RBF网络和BP网络对比 5.RBF网络和SVM对比 6.高斯核函数为什么可以映射到高维 7.前馈网络、递归网络和反馈网络 径向基函数说径向基网络之前,先聊下径向基函数径向基函数(英语:radial basis function,缩写为RBF)是一个取值仅依赖于到原点距离的实值函数,即 ϕ ( x ) = ϕ ( ∥ x ∥ ) {\displaystyle \phi (\mathbf {x} )=\phi (\|\mathbf {x} \|)} ϕ(x)=ϕ(∥x∥)。此外,也可以按到某一中心点c的距离来定义, 即 ϕ ( x , c ) = ϕ ( ∥ x − c ∥ ) {\displaystyle \phi (\mathbf {x} ,\mathbf {c} )=\phi (\|\mathbf {x} -\mathbf {c} \|)} ϕ(x,c)=ϕ(∥x−c∥)。任一满足 ϕ ( x ) = ϕ ( ∥ x ∥ ) {\displaystyle \phi (\mathbf {x} )=\phi (\|\mathbf {x} \|)} ϕ(x)=ϕ(∥x∥)的函数都可称作径向函数。其中,范数一般为欧几里得距离,不过亦可使用其他距离函数。 可以用于许多径向基函数的和来逼近某一给定的函数。这一逼近的过程可看作是一个简单的神经网络(rbf网络中的每个隐单元看作一个径向基函数,然后再线性加权结合逼近)。此外在机器学习中,径向基函数还被用作支持向量机的核函数。 看了好多博客基本都没有谈到为什么径向基函数可以逼近函数,说数谈的也说的不清楚,强硬开始径向基网络的分析,以下是我的一些见解 既然是逼近函数,那么建议读者先简单通过顶部的知乎链接了解下逼近这个概念和多变量插值问题。 为什么径向基函数可以逼近给定函数呢? 换句话说也就是使用径向基函数解决多变量插值问题,从几何意义上看,相当于根据稀疏的给定样本数据点恢复一个连续的超曲面,在给定点处曲面的值要满足样本值。先给出基于径向基函数的插值函数如下: BF网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。 简单说明一下为什么RBF网络学习收敛得比较快。当网络的一个或多个可调参数(权值或阈值)对任何一个输出都有影响时,这样的网络称为全局逼近网络。由于对于每次输入,网络上的每一个权值都要调整(例如传统的多项式插值法),从而导致全局逼近网络的学习速度很慢。BP网络就是一个典型的例子。 如果对于输入空间的某个局部区域只有少数几个连接权值影响输出,则该网络称为局部逼近网络。常见的局部逼近网络有RBF网络、小脑模型(CMAC)网络、B样条网络等。 明白RBF如何逼近一个给定函数后,RBF网络就是用网络来实现上述思路。 径向基函数网络通常有三层:输入层、隐藏层和一个非线性激活函数和线性径向基神经网络输出层。输入可以被建模为实数向量。输出是输入向量的一个标量函数。rbf简单网络模型如下: 我们由RBF函数过渡到RBF网络,接下来我们研究如何搭建一个RBF网络,由上述内容我们可以RBF网络无非3层,而输入层是无法优化的,只有隐藏层和输出层了,因此RBF网络训练就是对两组网络参数的学习: 1.隐层节点中心、RBF宽度、以及隐层节点数 2.隐层到输出层连接权值 1、方法一: 通过非监督方法得到径向基函数的中心和方差,通过监督方法(最小均方误差)得到隐含层到输出层的权值。具体如下: (1)在训练样本集中随机选择h个样本作为h个径向基函数的中心。更好的方法是通过聚类,例如K-means聚类得到h个聚类中心,将这些聚类中心当成径向基函数的h个中心。 (2)RBF神经网络的基函数为高斯函数时,方差可由下式求解: (3)隐含层至输出层之间神经元的连接权值可以用最小均方误差LMS直接计算得到,计算公式如下:(计算伪逆)(d是我们期待的输出值)
采用监督学习算法对网络所有的参数(径向基函数的中心、方差和隐含层到输出层的权值)进行训练。主要是对代价函数(均方误差)进行梯度下降,然后修正每个参数。具体如下: (1)随机初始化径向基函数的中心、方差和隐含层到输出层的权值。当然了,也可以选用方法一中的(1)来初始化径向基函数的中心。 (2)通过梯度下降来对网络中的三种参数都进行监督训练优化。代价函数是网络输出和期望输出的均方误差: 1、局部逼近与全局逼近: BP神经网络的隐节点采用输入向量与权向量的内积作为激活函数的自变量,而激活函数采用Sigmoid函数。各调参数对BP网络的输出具有同等地位的影响,因此BP神经网络是对非线性映射的全局逼近,每当有新的样本出现时,都要重新计算参数,训练很慢。 RBF神经网络的隐节点采用输入向量与中心向量的距离(如欧式距离)作为函数的自变量,并使用径向基函数(如Gaussian函数)作为激活函数。神经元的输入离径向基函数中心越远,神经元的激活程度就越低(高斯函数)。RBF网络的输出与部分调参数有关,譬如,一个wij值只影响一个yi的输出(参考上面的径向函数3张图,目标函数的逼近只靠最近的几个径向函数来实现,而距离远的径向函数不起作用,隐节点的这一特性常被称为“局部特性”。),RBF神经网络因此具有“局部逼近”特性。 简单说,假设输入向量的取值范围是[0,1],那么全局逼近就是有n个函数,每个函数的自变量输入范围是[0,1],每输入一个变量,会得到n个值,这n个值相加之和就是逼近的真实值,也就是说用全部函数来逼近目标函数。而局部逼近也是n个函数,但是每个函数的自变量是1/n,那么输入一个变量,只会得到一个值,这个值就是逼近的真实值,也就是说用一个函数来逼近目标函数,实际是数个函数,所以说是局部逼近。(以上例子仅为了通俗对比二者而举) 2、中间层数的区别 BP神经网络可以有多个隐含层,但是RBF只有一个隐含层。 3、训练速度的区别 使用RBF的训练速度快,一方面是因为隐含层较少,另一方面,局部逼近可以简化计算量。对于一个输入x,只有部分神经元会有响应,其他的都近似为0,对应的w就不用调参了。 4、Poggio和Girosi已经证明,RBF网络是连续函数的最佳逼近,而BP网络不是。 RBF网络和SVM对比SVM等如果使用核函数的技巧的话,不太适应于大样本和大的特征数的情况(因为SVM间隔最大化是一个二次规划问题,求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集),因此提出了RBF。 另外,SVM中的高斯核函数可以看作与每一个输入点的距离,而RBF神经网络对输入点做了一个聚类。RBF神经网络用高斯核函数时,其数据中心C可以是训练样本中的抽样,此时与svm的高斯核函数是完全等价的,也可以是训练样本集的多个聚类中心,所以他们都是需要选择数据中心的,只不过SVM使用高斯核函数时,这里的数据中心都是训练样本本身而已。 相信大部分人都听过核函数可以将低维数据映射到高维中,其实准确说核函数只是给出了数据在低维下计算高维内积的方法。 对于高斯核为什么可以将数据映射到无穷多维,我们可以从泰勒展开式的角度来解释, 首先我们要清楚,SVM中,对于维度的计算,我们可以用内积的形式,假设函数: κ ( x 1 , x 2 ) = ( 1 , x 1 x 2 , x 2 ) \kappa \left( x_{1}, x_{2} \right) = (1, x_{1}x_{2}, x^{2} ) κ(x1,x2)=(1,x1x |
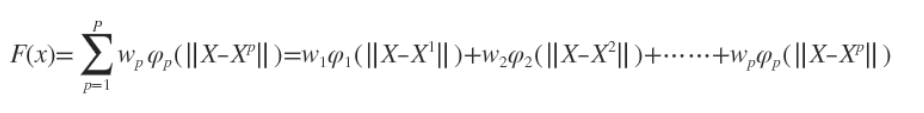 可以看出插值函数就是由p个径向基函数和其权值构成(p为给定的样本数),那么也就意味着逼近的这个超曲面上任何一点可以由对应的基函数值得出,具体实例看下图(搬运)
可以看出插值函数就是由p个径向基函数和其权值构成(p为给定的样本数),那么也就意味着逼近的这个超曲面上任何一点可以由对应的基函数值得出,具体实例看下图(搬运) 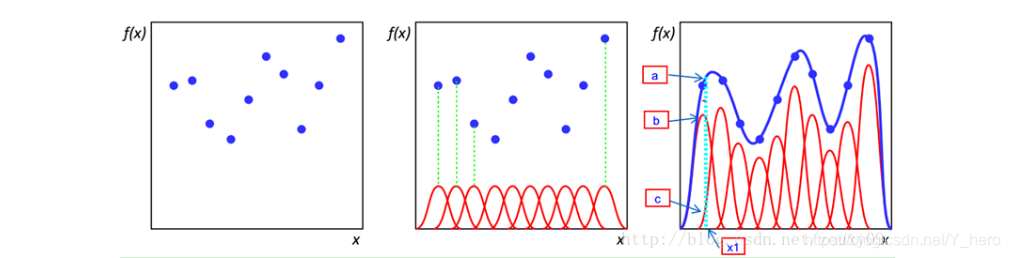 第一张图即给出二维平面中的n个样本点,然后构建n个基函数,如图二中红色的曲线,假设采用高斯径向基函数,其对应的曲线即高斯分布曲线,图三中的蓝色曲线即真正曲线,多维情况下即为超曲面。而我们高斯径向基函数要做的就是用这n个高斯曲线去拟合这条蓝色曲线。可以看出图三中的红色曲线和图二中的曲线不同,这是由图二的曲线乘以一个权值得到的,这也就对应了上面说到的插值函数就是由p个径向基函数和其权值构成(p为给定的样本数)。例如对x1,其真实值为f(x1),即图三中的a点,而与高斯曲线相交于b、c两点,高斯径向基函数拟合的结果就是b和c的纵坐标之和,f(x1)-b-c就是误差,我们要做的就是优化权值参数或者选取其他径向基函数来尽可能还原蓝色曲线。
第一张图即给出二维平面中的n个样本点,然后构建n个基函数,如图二中红色的曲线,假设采用高斯径向基函数,其对应的曲线即高斯分布曲线,图三中的蓝色曲线即真正曲线,多维情况下即为超曲面。而我们高斯径向基函数要做的就是用这n个高斯曲线去拟合这条蓝色曲线。可以看出图三中的红色曲线和图二中的曲线不同,这是由图二的曲线乘以一个权值得到的,这也就对应了上面说到的插值函数就是由p个径向基函数和其权值构成(p为给定的样本数)。例如对x1,其真实值为f(x1),即图三中的a点,而与高斯曲线相交于b、c两点,高斯径向基函数拟合的结果就是b和c的纵坐标之和,f(x1)-b-c就是误差,我们要做的就是优化权值参数或者选取其他径向基函数来尽可能还原蓝色曲线。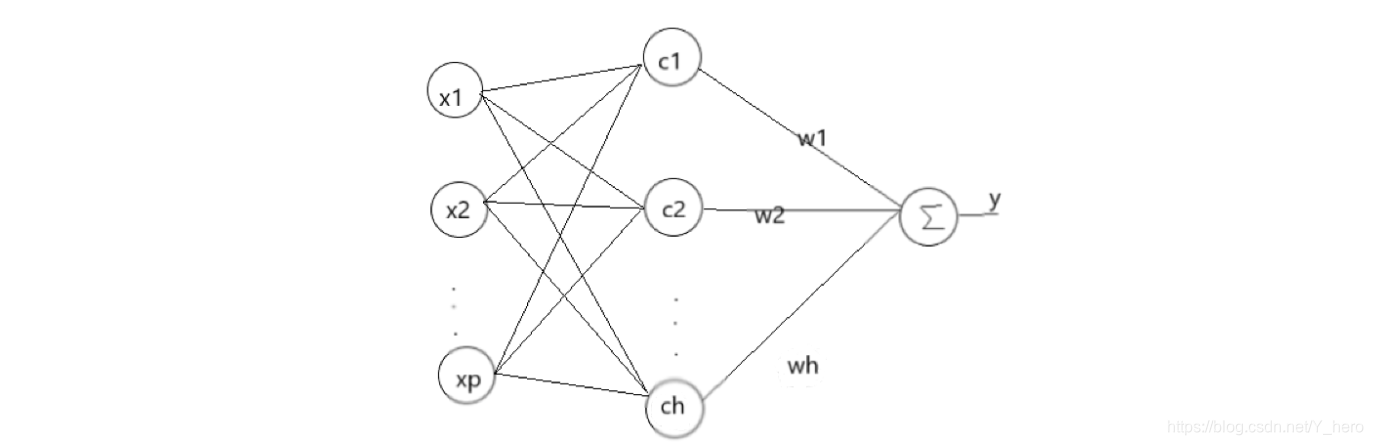 RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可以将输入矢量直接映射到隐空间,而不需要通过权连接。当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和,此处的权即为网络可调参数。其中,隐含层的作用是把向量从低维度的p映射到高维度的h,这样低维度线性不可分的情况到高维度就可以变得线性可分了,主要就是核函数的思想。这样,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。
RBF网络的基本思想是:用RBF作为隐单元的“基”构成隐含层空间,这样就可以将输入矢量直接映射到隐空间,而不需要通过权连接。当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐单元输出的线性加权和,此处的权即为网络可调参数。其中,隐含层的作用是把向量从低维度的p映射到高维度的h,这样低维度线性不可分的情况到高维度就可以变得线性可分了,主要就是核函数的思想。这样,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。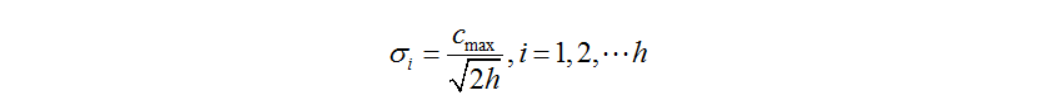 式中cmax 为所选取中心之间的最大距离,h是隐层节点的个数。扩展常数这么计算是为了避免径向基函数太尖或太平。
式中cmax 为所选取中心之间的最大距离,h是隐层节点的个数。扩展常数这么计算是为了避免径向基函数太尖或太平。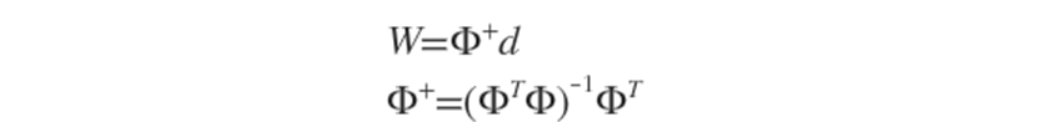 2、方法二:
2、方法二: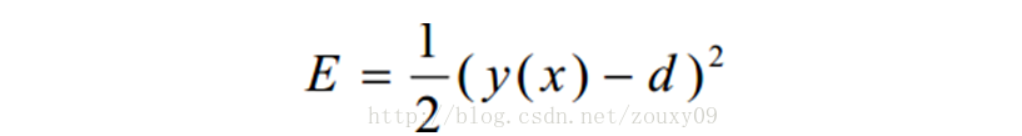 然后每次迭代,在误差梯度的负方向已一定的学习率调整参数。
然后每次迭代,在误差梯度的负方向已一定的学习率调整参数。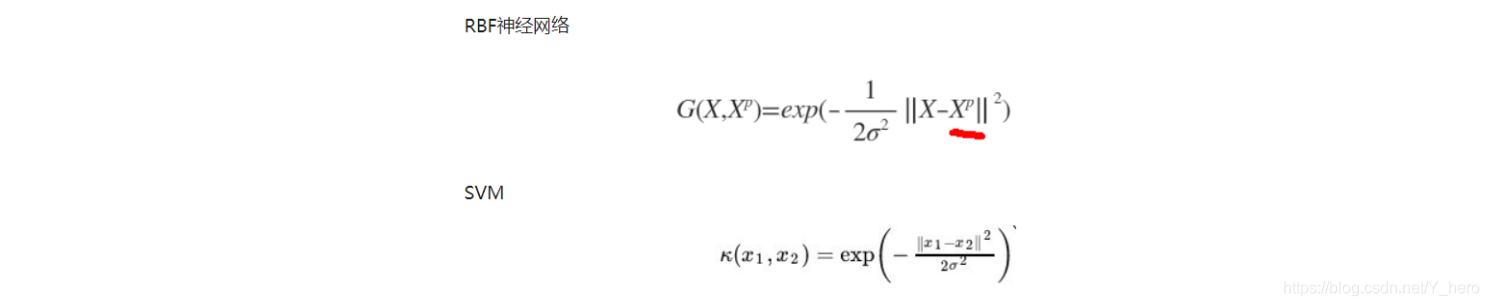
【本文地址】
今日新闻 |
推荐新闻 |