【社会网络分析图】python实现 |
您所在的位置:网站首页 › 社交关系网络图python线的标签 › 【社会网络分析图】python实现 |
【社会网络分析图】python实现
|
社会网络分析图—Python实现
主要记录学习《Python数据挖掘方法及应用》(王斌会 著)第八章的内容。 社会网络分析主要有两大要素: ①行动者,在社会网络中用节点(node)表示;②关系,在社会网络中用连线(edge)表示,关系的内容可以是友谊、借贷或沟通,其关系可以是单向或双方的,切关系强度存在强度的差异。 社会网络分析包networkxnetworkx是python语言开发的图论与复杂网络建模工具,内置了常用的图与复杂网络分析算法,可以方便进行复杂网络数据分析和仿真建模等工作。 网络图之知识图谱知识图谱,又称为科学知识图谱,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。 共现矩阵图谱共现矩阵是把数据进行整合筛选等操作后,将所要的某一列数据进行处理。这一列中出现的数据,通过矩阵的方式表示它们之间的联系。矩阵中的数字代表相关联的次数。 程序中出现的数据都是本书所给实例。 下载数据的网站[\《Python数据分析》暨南大学 王斌会](http://blog.leanote.com/DaPy) 附上程序 #!/usr/bin/env python # -*- coding: cp936 -*- 使用中文 import networkx as nx import matplotlib.pyplot as plt nG=nx.Graph();#创建一个空的图 nG一定要加前两行,要不然后面画图会显示不了中文 import pandas as pd #分解信息 def list_split(content,separator): new_list=[] for i in range(len(content)): new_list.append(list(filter(None,content[i].split(separator))))#以separator为分隔符 return new_list #清除信息中的空格 def list_replace(content,old,new): return[content[i].replace(old,new) for i in range(len(content))] WXdata=pd.read_excel('PyDm_data.xlsx','WXdata');设置一个分解信息函数list_split(content,separator)和清除空格的函数list_replace(content,old,new),由于原始文本数据中含标点符号,对数据进行预处理,去掉这些干扰的东西。 def find_words(content,pattern): #寻找关键词 return[content[i] for i in range(len(content)) if (pattern in content[i])==True] def search_university(content,pattern):#寻找大学 return len([find_words(content[i],pattern) for i in range(len(content)) if find_words(content[i],pattern)!=[]]) university=pd.read_excel('PyDm_data.xlsx','university'); #university1=sum(university,[]) organ=list_split(WXdata['Organ'],';') data1=pd.DataFrame([[i,search_university(organ,i)] for i in university['学校名称']]) keyword=list_split(WXdata['Keyword'].dropna(axis=0,how='all').tolist(),';;') keyword1=sum(keyword,[]) author=list_replace(WXdata['Author'].dropna(axis=0,how='all').tolist(),',',';') author1=list_split(author,';') author2=sum(author1,[]) data1;查找函数find_words(content,pattern)用于查找每一列中所要元素 由于后面要画三个图,分别是作者,大学和关键词,这里先提取出数据 #获取前30名的高频数据 data_author=pd.DataFrame(author2)[0].value_counts()[:30].index.tolist() data_keyword=pd.DataFrame(keyword1)[0].value_counts()[:30].index.tolist() data_university=data1.sort_values(by = 1,ascending=False,axis=0)[0:30][0].tolist() #data_university=data1.sort_values(by=1,ascending=False,axis=0)[0:30]['学校名称'].tolist() data_university;由于数据较多,这里设置一个提取高频数据的函数,只选取每一列中出现次数最多的三十个来进行研究。 ```python def occurence(data,document): #定义共现矩阵 empty1=[];empty2=[];empty3=[] for a in data: for b in data: count = 0 for x in document: if [a in i for i in x].count(True)>0 and [b in i for i in x].count(True)>0: count=count+1 empty1.append(a);empty2.append(b);empty3.append(count)#append() 方法向列表的尾部添加一个新的元素。只接受一个参数 df=pd.DataFrame({'from':empty1,'to':empty2,'weight':empty3}) #具有标注轴(行和列)的二维大小可变的表格数据结构 G=nx.from_pandas_edgelist(df,'from','to','weight') #返回包含边列表的图形 return (nx.to_pandas_adjacency(G,dtype=int))#注意对齐自定义用于画图的共现矩阵的函数 occurence(data,document) Matrix1=occurence(data_author,author1) Matrix1; Matrix2=occurence(data_university,organ) Matrix2; Matrix3=occurence(data_keyword,keyword) Matrix3;
作者列的网络图
最后,附上一些程序实现过程中参考的网站 1.入门|始于Jupyter Notebooks:一份全面的初学者实用指南http://baijiahao.baidu.com/s?id=1601883438842526311&wfr=spider&for=pc 2.Networkx参考手册 - qingqingpiaoguo的专栏 - CSDN博客 https://blog.csdn.net/qingqingpiaoguo/article/details/60570894 3.python复杂网络库networkx:绘图draw - 皮皮blog - CSDN博客 https://blog.csdn.net/pipisorry/article/details/54291831 4.Drawing — NetworkX 1.10 documentation https://networkx.github.io/documentation/networkx-1.10/reference/drawing.html 5.《数据挖掘方法》 http://blog.leanote.com/cate/dapy/%E7%9B%AE%E5%BD%95 |
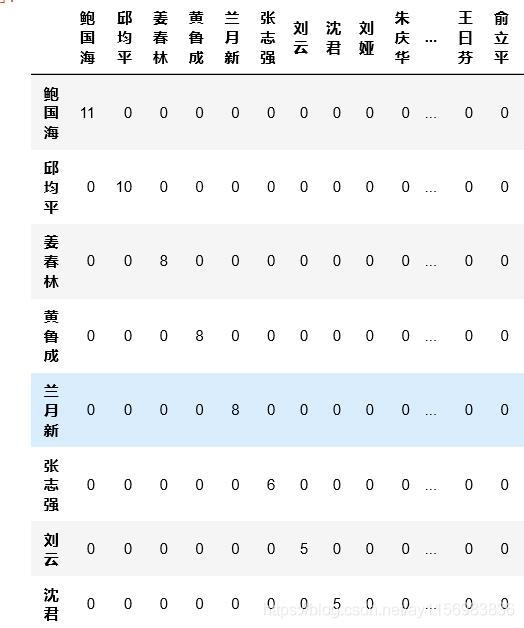 作者矩阵Matrix1的结果
作者矩阵Matrix1的结果 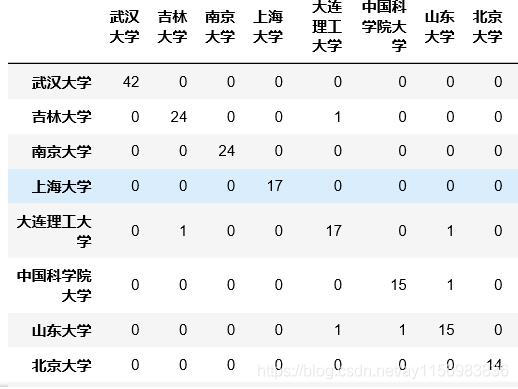 大学矩阵 Matrix2的结果
大学矩阵 Matrix2的结果 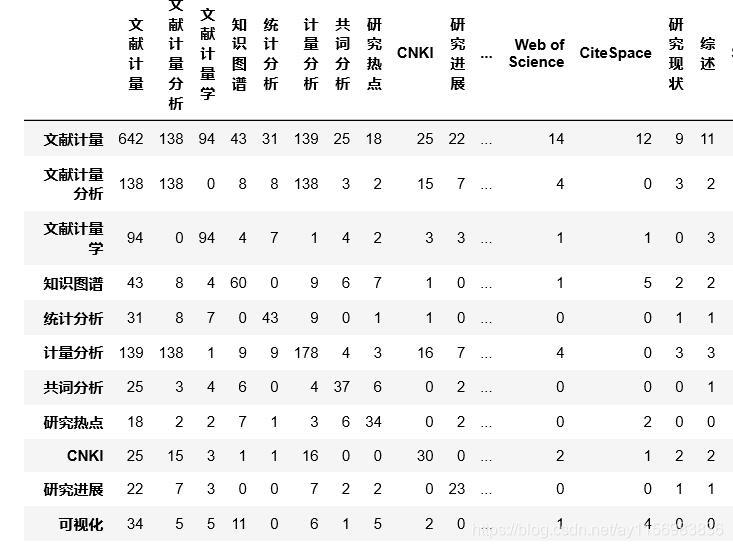 关键词矩阵 Matrix3的结果
关键词矩阵 Matrix3的结果 高频作者之间合作情况
高频作者之间合作情况 高校之间合作图谱
高校之间合作图谱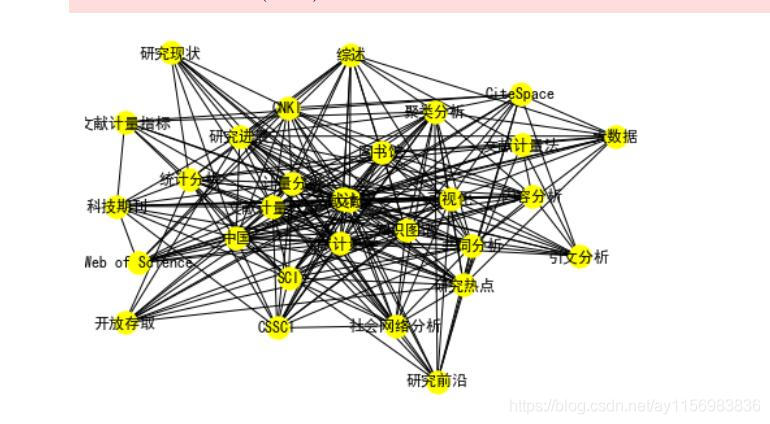 关键词知识图谱
关键词知识图谱【本文地址】