CPU三级缓存原理与优化 |
您所在的位置:网站首页 › 硬盘128缓存和256缓存 › CPU三级缓存原理与优化 |
CPU三级缓存原理与优化
|
现代CPU的缓存一般分为三个层次,L1,L2,L3。我们称为“三级缓存‘ 在CPU之外,还有RAM和Disk作为大容量的存储器。 各个层级的速度和空间大小可以参照上图,图中以普通的家用计算机为例子粗略的估计了数据,请不要有刻板的印象(不同配置的机器可能产生较大的误差),而且不是所有CPU都按照三级缓存的结构进行存储的。但是绝大多数现代计算机的CPU都按照此种结构。 本文的目的绝不是详细的阐述CPU的工作原理,而是使得读者对CPU的缓存有一个认知,哪怕推出四级缓存,也能举一反三的理解其工作原理。 借图: L1缓存分成两部分,指令缓存和数据缓存,指令缓存用于存储最近使用的指令,而数据缓存则存储最近使用的数据。 L1缓存是最接近CPU核心的,速度最快,但是空间最小。 (2) L2缓存现代多核心CPU中,一般每个核心都拥有一个L2缓存,相对于L1缓存而言,L2空间的更大,但是也更缓慢。 (3) L3缓存在现代CPU中,往往多个核心拥有共同的一个L3缓存,相对L2缓存,L3远离核心,更加缓慢,空间更大 (4) RAMRAM的全称是random-access memory,随机访问内存,或者随机存储器,它的速度相对于L3更加缓慢,但是空间几何倍的增长。 也就是和我们俗称的“内存条”差不多是一个概念。 (5) DiskDisk就是我们常说的硬盘,一般分为两种,SSD(固态硬盘)和HDD(机械硬盘),现代的计算机很少见到机械硬盘了,固态硬盘的访问速度相对于RAM来讲,要断崖式的下降,但是可用空间也是爆炸式的增长。 2.是什么造成访问速度差异 空间的差异:更小的空间有利于快速定位数据离CPU核心的远近 : L1一般离核心的距离较近,需要通过更短的距离制程不同 : 在设计上L1往往更加倾向于速度,电路排布方式等存在差异 3.读取数据的大概流程命中 : 这里指在指定存储器里能发现这个数据 我们可以去这样理解,但是CPU其实不是按照这个步骤去执行的。 检查L1是否能被命中 命中L1,处理数据并结束未能命中L1,继续步骤2 检查L2能否被命中 命中L2 ,填充数据到L1并回到步骤1未命中L2,继续步骤3 检查L3能否命中 命中L3,填充数据到L2,回到步骤2未命中L3,继续步骤4 检查RAM是否命中 命中RAM,填充数据到L3,回到步骤3未命中RAM,继续步骤5 等待数据写入到RAM(手动分配或者从Disk) 写入后,回到步骤4 4.如何保证较高的缓存命中率让我们回到这张图,我们将以这张图的结构为例进行分析。 缓存行:是在主内存和高速缓存之间传输的最小粒度(大概64字节,取决于架构),例如从主内存读取一个数据,会直接读取这个地址往后的一个缓存行。 伪共享:多个线程从同一个缓存行取数据,出现缓存一致性开销,一般出现在多个线程访问相同数据结构时。缓存行填充: 当一个线程加载一个缓存行中的数据时,整个缓存行通常会被加载到CPU的缓存中。如果其他线程稍后尝试访问相同缓存行的其他数据,就可能导致冲突。解决方案: 建议使用”内存对齐“:尽量使得数据按照缓存行的边界进行对齐。使用缓存填充: 在共享数据结构的字段之间插入填充字段,以确保它们不会位于同一缓存行中。使用原子操作: 使用原子操作可以避免多线程同时访问同一缓存行的问题,但要注意原子操作可能引入性能开销。使用线程局部存储: 每个线程使用自己的缓存行副本,而不是共享相同的缓存行,可以避免缓存行冲突。使用非缓存内存: 在某些情况下,可以使用非缓存内存(例如volatile关键字)来禁用缓存,以避免缓存行冲突。但要小心,因为这可能会引入性能开销。 6.缓存一致性原理我们假设,如果核心1修改了内存里的数据时,而核心2却早已缓存了这个数据。 那么就将导致差异性。 而缓存一致性协议就是解决这个问题的,如果核心1修改了内存数据,就要更新其他核心的缓存数据。 这也是我们需要避免的事情。 |
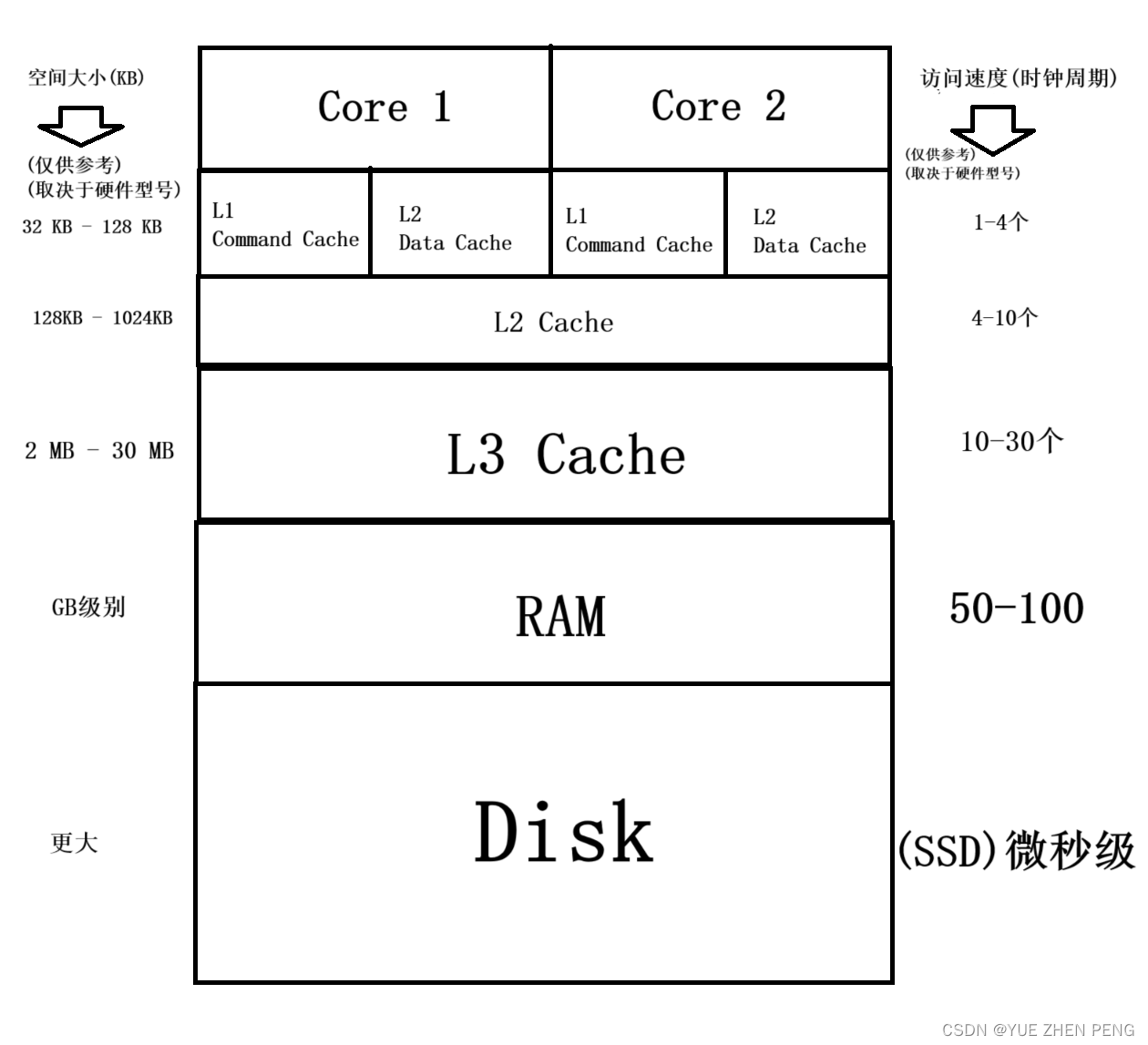 注意:时钟周期的现实长度是CPU主频的倒数
注意:时钟周期的现实长度是CPU主频的倒数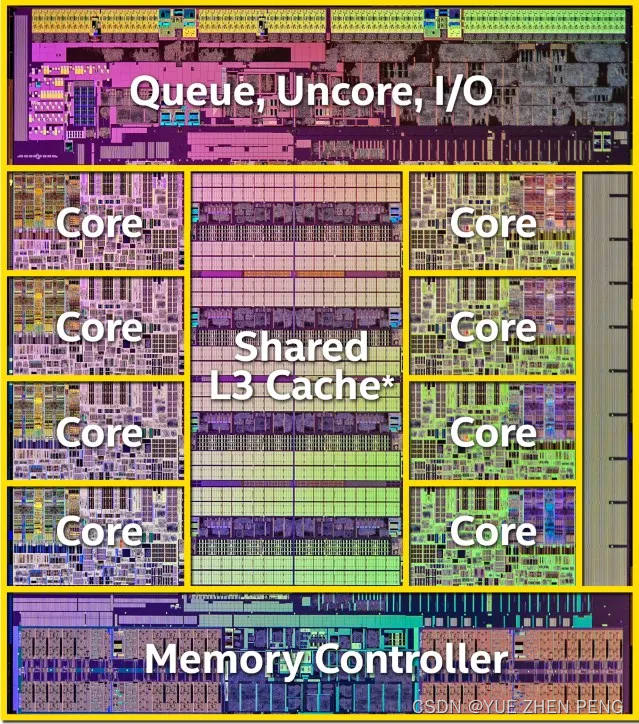
【本文地址】
今日新闻 |
推荐新闻 |