MapReduce实现矩阵乘法的一些总结 |
您所在的位置:网站首页 › 矩阵乘法的时间复杂度怎么算 › MapReduce实现矩阵乘法的一些总结 |
MapReduce实现矩阵乘法的一些总结
MapReduce实现矩阵乘法的一些总结
文章目录
MapReduce实现矩阵乘法的一些总结矩阵乘法概述MapReduce 思路具体方法 1具体方法 2具体方法 3
实现代码结果分析一些杂杂碎碎Hex 与 bytes 与 Int 的转换Hadoop 环境配置本地调试本地安装 hadoop
如何修改 mapper,reducer 数量
参考资料
矩阵乘法概述

对于矩阵乘法 A ( i , j ) ∗ B ( j , k ) = C ( i , k ) A(i,j) * B(j,k) = C(i,k) A(i,j)∗B(j,k)=C(i,k),有: ( i , k ) = ( i , j 1 ) ( j 1 , k ) + ( i , j 2 ) ( j 2 , k ) + . . . + ( i , j n ) ( j n , k ) (i,k) = (i,j_1)(j_1,k) + (i,j_2)(j_2,k)+...+(i,j_n)(j_n,k) (i,k)=(i,j1)(j1,k)+(i,j2)(j2,k)+...+(i,jn)(jn,k) A 矩阵的 第 i i i行和 B 矩阵的 第 k k k列做乘法再求和的操作,在 A 的行与行,B 的列与列之间,是互不影响,可以并行的。 对于不并行的矩阵乘法,复杂度为 O ( n 3 ) O(n^3) O(n3) 对于采用 map reduce 的矩阵乘法,复杂度降为:??? MapReduce 思路以下面的矩阵乘法为例: 1 2 3 4 × 5 6 7 8 \begin{matrix} 1&2\\ 3&4 \end{matrix} \times \begin{matrix} 5&6\\ 7&8 \end{matrix} 1324×5768 基本思路是,将最终结果(矩阵 C)的坐标作为 key,从而可以确定 A 的行和 B 的列,进一步求行和列的对应元素乘积求和即可。 具体方法 1Mapper 工作: 对于矩阵 A: k e y : ( i , k ) key: (i,k) key:(i,k) , v a l u e : ( A , j , A i j ) value: (A, j, A_{ij}) value:(A,j,Aij) 对于矩阵 B: k e y : ( i , k ) key: (i,k) key:(i,k) , v a l u e : ( B , j , A j k ) value: (B, j, A_{jk}) value:(B,j,Ajk) Reducer 工作: 对于所有的 ( i , k ) = = > S u m m a t i o n ( A i j ∗ B j k ) (i,k) ==> Summation(A_{ij}*B_{jk}) (i,k)==>Summation(Aij∗Bjk) for all j j j 
 具体方法 2
具体方法 2
Mapper 工作: 对于矩阵 A: k e y : ( i , k ) key: (i,k) key:(i,k) , v a l u e : ( A , i , [ . . . . ] ) value: (A, i, [....]) value:(A,i,[....]) 对于矩阵 B: k e y : ( i , k ) key: (i,k) key:(i,k) , v a l u e : ( B , k , [ . . . . ] ) value: (B, k, [....]) value:(B,k,[....]) 与上面的区别在于,mapper 发送的键值对,直接将 A 矩阵的一整行或者 B 矩阵的一整列发送给 reducer。 Reducer 工作: 将键值对相同的对应行和对应列进行乘积再求和。 具体方法 3将矩阵分为 n 个区块,每个区块包含 n 行(n 列)。然后进行区块之间的操作。 此时,key 就不再是以 i , k i,k i,k 表示的行号和列号,而是区块号。 实现代码根据拥有的数据文件,我选择了方法 2 。 数据文件的格式如下: 矩阵 A(1024 * 1024):
L作为矩阵 A 的 标识,数字是行号 i i i,剩下的是矩阵的每个元素值,长度为 1024。 矩阵 B(1024 * 1024):
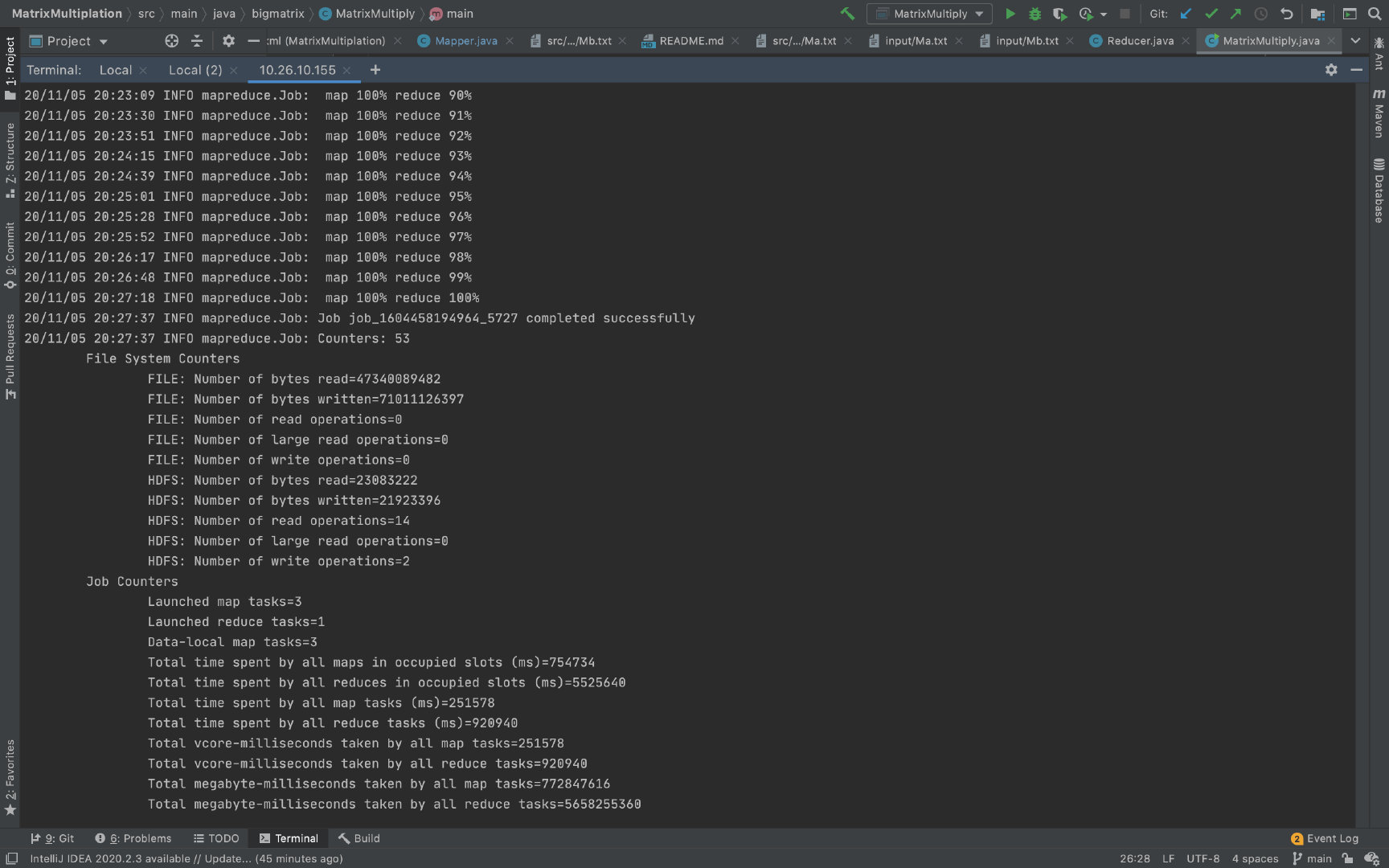
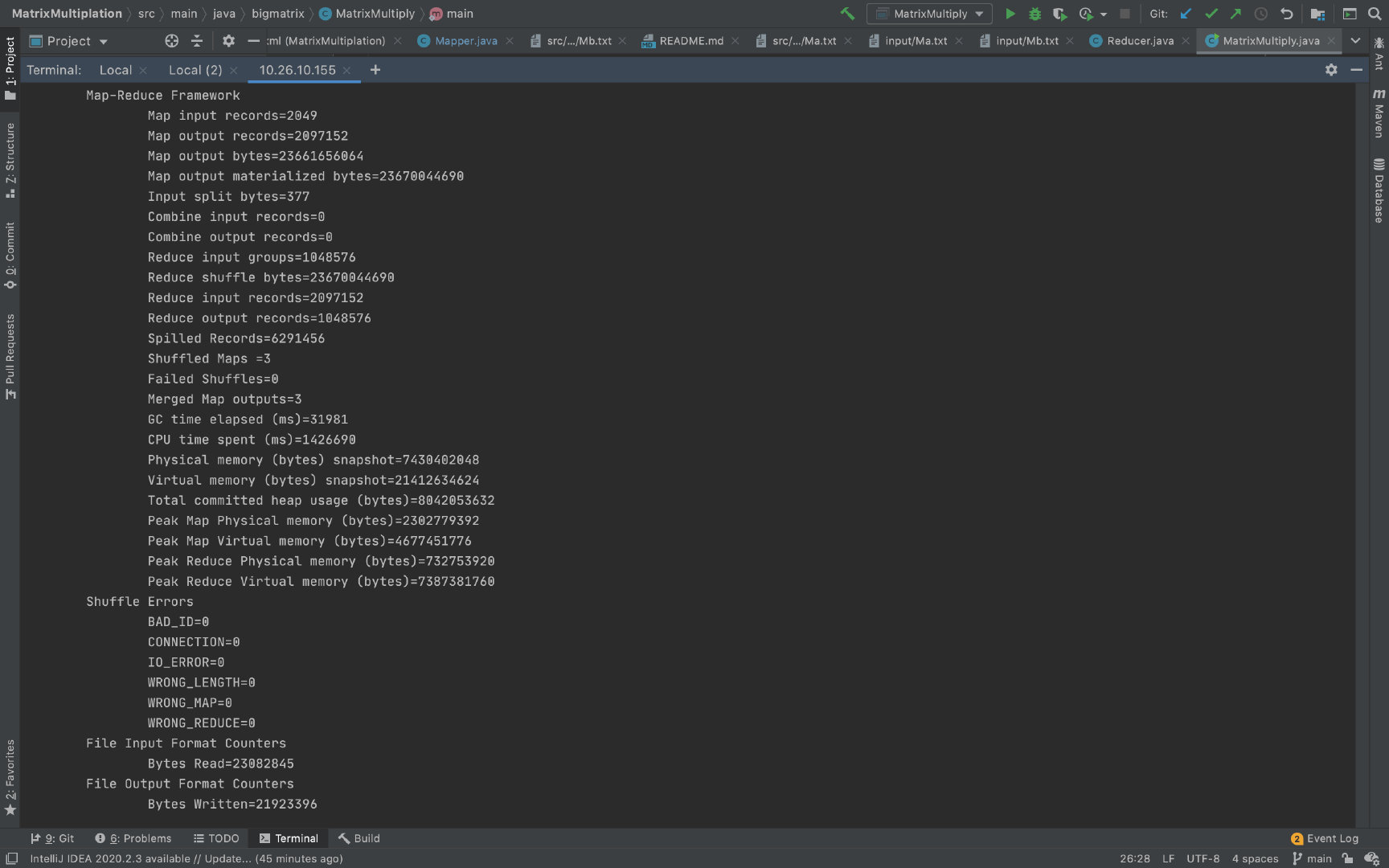
这个数据文件是已经转置过的矩阵 B,方便进行数据读取与操作。因此这里每一行即代表矩阵 B 的每一列。 R 作为矩阵 B 的标识,数字是列号 j j j, 列出一些主要的代码: Mapper: public class Mapper extends org.apache.hadoop.mapreduce.Mapper{ private Logger logger = Logger.getLogger(Mapper.class); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { Configuration conf = context.getConfiguration(); int m = Integer.parseInt(conf.get("m")); int p = Integer.parseInt(conf.get("p")); String line = value.toString(); String[] indicesAndValue = line.split(" ", 3); Text outputKey = new Text(); Text outputValue = new Text(); for (int i = 0; i try { for (int k = 1; k logger.error(e.getMessage()); logger.error("--------Left--------"); logger.error(indicesAndValue); } } else { try { for (int i = 1; i logger.error(e.getMessage()); logger.error("--------Right--------"); logger.error(indicesAndValue); } } } }Reducer: public class Reducer extends org.apache.hadoop.mapreduce.Reducer{ @Override protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { String[] value; HashMap hashA = new HashMap(); HashMap hashB = new HashMap(); for (Text val : values) { value = val.toString().split(","); if (value[0].equals("L")) { // hashA: (i,k),[] hashA.put(key.toString(), value[2]); } else { // hashB: (i,k),[] hashB.put(key.toString(),value[2]); } } int result = 0; if (hashA.containsKey(key.toString()) && hashB.containsKey(key.toString())) { String Row = hashA.get(key.toString()); String Column = hashB.get(key.toString()); String[] row = Row.replaceAll("\\[", "").replaceAll("\\]", "").split(" "); String[] column = Column.replaceAll("\\[", "").replaceAll("\\]", "").split(" "); for (int i = 0; i System.out.printf("%d\n", result); // key 应该是 (i, k) context.write(null, new Text(key.toString() + "," + Float.toString(result))); } } }代码地址 结果分析以下运行结果是在分布式集群上运行获得。 在 mapper 数量为 3,reducer 数量为 1 时,实验结果如下图: CPU 消耗的时间为 1426690ms = 142.669s 由于将 reducer 数量设为 1,所以在 reduce阶段并没有进行并行操作。 Map 所消耗的总时间为:251578ms = 251.578s Reducer 所消耗的总时间为:920940ms = 920.94s 由于我们将矩阵的乘法和加法操作都分配给 reducer,mapper 主要负责进行矩阵行列的对应,所以 reducer花费的时间较多。
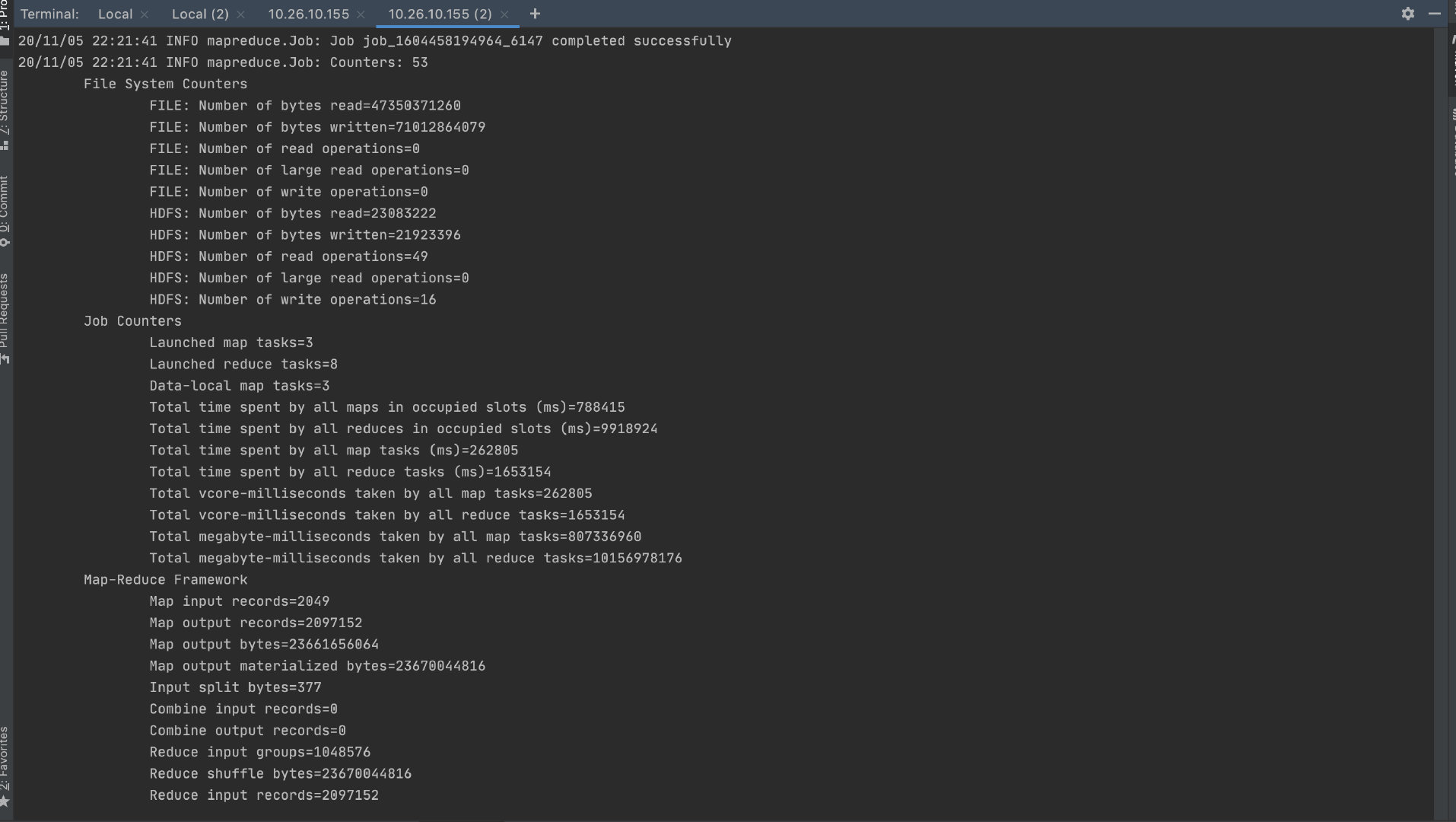
采用mapper 数量为 3,reducer 数量为 8 时,实验结果如下图:
Map 所消耗的总时间为:262805 = 262.805s Reducer 所消耗的总时间为:1653154ms = 1653.154s 增加 reducer 数量并没有增加执行速度。原因可能是,数据量较小的情况下,一个 reducer就可以完成所有的工作。增加 reducer 反而增加了不同 reducer 之间的协同工作以及同步所有数据块的时间消耗。 一些杂杂碎碎 Hex 与 bytes 与 Int 的转换如何读取数据文件中类似 16 进制格式的ASCII数据? Python 的方式: Val = int(struct.unpack("I", binascii.a2b_hex(Matrix[i][k][2:]))[0])通过将 hex 转为二进制,然后使用unpack 方法进行二进制数据的解读。 Java 的方式: byte[] bytes = parseHexBinary(row[i]); ByteBuffer wrapped = ByteBuffer.wrap(bytes); // big-endian by default int r = wrapped.getInt();读取字节流,然后利用 ByteBuffer 转为整数。 Hadoop 环境配置 本地调试假如想要在把程序部署到云上之前,在本地上运行 mapreduce 程序。直接在 Idea中新建 maven 包,然后导入依赖,确定好输入输出文件的路径并运行即可。(具体参考) 本地安装 hadoop厦门大学数据实验室 其实没必要,即使装了,在任务较大时,本地也跑不起来。 如何修改 mapper,reducer 数量参考 注意,不建议主动修改 mapper 数量。 Number of mappers set to run are completely dependent on 1) File Size and 2) Block Size The MapReduce framework in Hadoop allows us only to 1)suggest the number of Map tasks for a job 2)demand that it provide n reducers. 参考资料http://dblab.xmu.edu.cn/blog/820-2/ https://www.geeksforgeeks.org/matrix-multiplication-with-1-mapreduce-step/ https://github.com/shask9/Matrix-Multiplication-Hadoop https://www.jianshu.com/p/c6c543e4975e https://docs.python.org/zh-cn/3/library/binascii.html https://docs.python.org/zh-cn/3/library/struct.html https://www.journaldev.com/776/string-to-array-java https://stackoverflow.com/questions/6885441/setting-the-number-of-map-tasks-and-reduce-tasks https://stackoverflow.com/questions/28861620/hadoop-map-reduce-total-time-spent-by-all-maps-in-occupied-slots-vs-total-time |


【本文地址】
今日新闻 |
推荐新闻 |