知识图谱入门 (六) 知识融合 |
您所在的位置:网站首页 › 知识图谱实体相似度计算 › 知识图谱入门 (六) 知识融合 |
知识图谱入门 (六) 知识融合
|
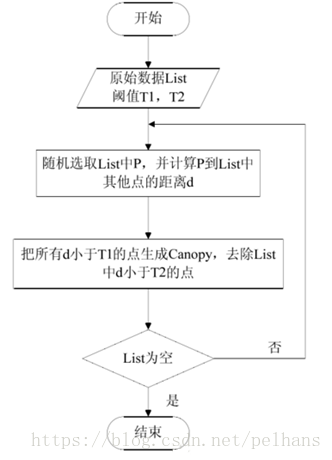
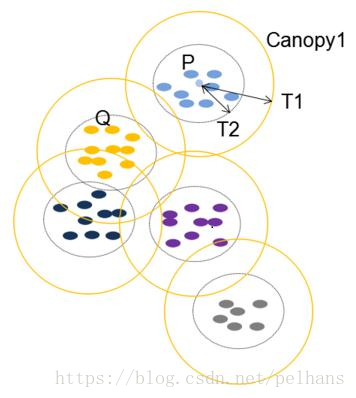
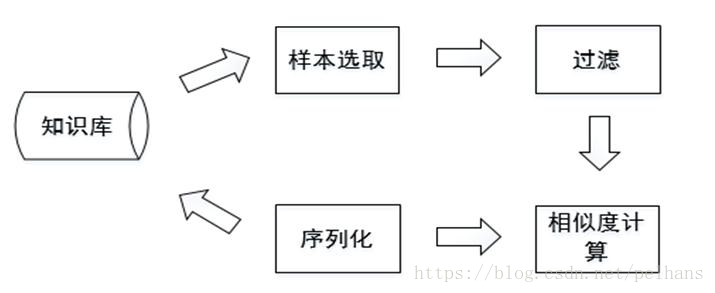
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~ 本节主要介绍知识融合相关技术,首先介绍了什么是知识融合,其次对知识融合技术的流程做一个介绍并对知识融合常用工具做一个简单介绍。 知识融合简介知识融合,即合并两个知识图谱(本体),基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来。需要确认的是: 等价实例 等价类/子类 等价属性/子属性一个例子如上图所示,图中不同颜色的圆圈代表不同的知识图谱来源,其中在dbpedia.org中的Rome 和geoname.org的roma是同一实体,通过两个sameAs链接。不同知识图谱间的实体对齐是KG融合的主要工作。 除了实体对齐外,还有概念层的知识融合、跨语言的知识融合等工作。 这里值得一提的是,在不同文献中,知识融合有不同的叫法,如本体对齐、本体匹配、Record Linkage、Entity Resolution、实体对齐等叫法,但它们的本质工作是一样的。 知识融合的主要技术挑战为两点: 数据质量的挑战: 如命名模糊,数据输入错误、数据丢失、数据格式不一致、缩写等。 数据规模的挑战: 数据量大(并行计算)、数据种类多样性、不再仅仅通过名字匹配、多种关系、更多链接等。 知识融合的基本技术流程知识融合一般分为两步,本体对齐和实体匹配两种的基本流程相似,如下: 数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。 常用的数据预处理有: 语法正规化: 语法匹配: 如联系电话的表示方法 综合属性: 如家庭地址的表达方式 数据正规化: 移除空格、《》、“”、-等符号 输入错误类的拓扑错误 用正式名字替换昵称和缩写等 记录连接假设两个实体的记录x 和y, x和y在第i个属性上的值是 xi,yi x i , y i , 那么通过如下两步进行记录连接: 属性相似度: 综合单个属性相似度得到属性相似度向量: [sim(x1,y1),sim(x2,y2),…,sim(xN,yN)] [ s i m ( x 1 , y 1 ) , s i m ( x 2 , y 2 ) , … , s i m ( x N , y N ) ] 实体相似度: 根据属性相似度向量得到一个实体的相似度。 属性相似度的计算属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等。 编辑距离: Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps 集合相似度计算: Jaccard系数, Dice 基于向量的相似度计算: Cosine相似度、TFIDF相似度 …… 编辑距离计算属性相似度 Levenshtein DistanceLevenshtein 距离,即最小编辑距离,目的是用最少的编辑操作将一个字符串转换成另一个.举个例子,计算Lvensshtain 与 Levenshtein 间的编辑距离: Lvensshtain→insert"e"→Levensshtain L v e n s s h t a i n → i n s e r t " e "→ L e v e n s s h t a i n Levenshtain→delete"s"→Levenshtain L e v e n s h t a i n → d e l e t e " s "→ L e v e n s h t a i n Levenshtain→sub"a"to"e"→Levenshtein L e v e n s h t a i n → s u b " a " t o " e "→ L e v e n s h t e i n上述讲 Lvensshtain转换为Levenshtein ,总共操作3次,编辑距离也就是3。 Levenstein Distance 是典型的动态规划问题,可以通过动态规划算法计算,具体公式如下: ⎧⎩⎨⎪⎪D(0,0)D(i,0)D(0,j)===0D(i−1,0)+1D(0,j−1)+1 1 T i对于分类器等机器学习方法,最大的问题是如何生成训练集合,对于此可采用无监督/半监督训练,如EM、生成模型等。或主动学习如众包等方案。 聚类聚类又可分为层次聚类、相关性聚类、Canopy + K-means等。 层次聚类层次聚类 (Hierarchical Clustering) 通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构。 底层的原始数据可以通过相似度函数计算,类之间的相似度有如下三种算法: SL(Single Linkage)算法: SL算法又称为最邻近算法 (nearest-neighbor),是用两个类数据点中距离最近的两个数据点间的相似度作为这两个类的距离。 CL (Complete Linkage)算法: 与SL不同的是取两个类中距离最远的两个点的相似度作为两个类的相似度。 AL (Average Linkage) 算法: 用两个类中所有点之间相似度的均值作为类间相似度。举个例子, 有下图的数据,用欧氏距离和SL进行层次聚类。 这样结果就变成: 如此往复就得到最终的分类表: rxy r x y 表示x,y被分配在同一类中, pxy p x y 代表x,y是同一类的概率 (x,y之间的相似度), w+xy(=pxy) w x y + ( = p x y ) 和 w−xy(=1−pxy) w x y − ( = 1 − p x y ) 分别是切断x,y之间的边的代价和保留边的代价。相关性聚类的目标就是使用最小的代价找到一个聚类方案。 minΣrxyw−xy+(1−rxy)w+xy min Σ r x y w x y − + ( 1 − r x y ) w x y +是一个NP-Hard问题,可用贪婪算法近似求解。 Canopy + K-means与K-means不同,Canopy聚类最大的特点是不需要事先指定k值 (即clustering的个数),因此具有很大的实际应用价值,经常将Canopy和K-means配合使用。 用图形表达流程如下图所示: 文字表述为:初始时有一个大的list,其中list中每个点都是一个canopy,设置阈值T1,T2。随机玄奇List中的点P,并计算list中其他的点到点P的距离d,把所有距离d小于T1的点生成Canopy,去除list中d小于T2的点。如此往复这个过程就得到了聚类结果。生成Canopy的过程就像以T2为中心扣下来一块,然后剩下的环就是Canopy。这样一块一块的扣就知道最终list为空。 将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。 将两个知识图谱映射到同一空间的方法有很多种,它们的桥梁是预连接实体对(训练数据),具体可以看详细论文。 完成映射后如何进行实体链接呢?KG向量训练达到稳定状态之后,对于KG1每一个没有找到链接的实体,在KG2中找到与之距离最近的实体向量进行链接,距离计算方法可采用任何向量之间的距离计算,例如欧式距离或Cosine距离。 分块分块 (Blocking)是从给定的知识库中的所有实体对中,选出潜在匹配的记录对作为候选项,并将候选项的大小尽可能的缩小。这么做的原因很简单,因为数据太多了。。。我们不可能去一一连接。 常用的分块方法有基于Hash函数的分块、邻近分块等。 首先介绍基于Hash函数的分块。对于记录x,有 hash(x)=hi h a s h ( x ) = h i ,则x映射到与关键字 hi h i 绑定的块 Ci C i 上。常见的Hash函数有: 字符串的前n个字 n-grams 结合多个简单的hash函数等邻近分块算法包含Canopy聚类、排序邻居算法、Red-Blue Set Cover等。 负载均衡负载均衡 (Load Balance)来保证所有块中的实体数目相当,从而保证分块对性能的提升程度。最简单的方法是多次Map-Reduce操作。 典型知识融合工具简介 本体对齐-Falcon-AOFalcon-AO是一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。编程语言为Java。其结构如下图所示: 此处主要介绍它的匹配算法库,其余部分可查看官方文档。 匹配算法库包含V-Doc、I-sub、GMO、PBM四个算法。其中V-Doc即基于虚拟文档的语言学匹配,它是将实体及其周围的实体、名词、文本等信息作一个集合形成虚拟文档的形式。这样我们就可以用TD-IDF等算法进行操作。I-Sub是基于编辑距离的字符串匹配,这个前面我们有详细介绍。可以看出,I-Sub和V-Doc都是基于字符串或文本级别的处理。更进一步的就有了GMO,它是对RDF本体的图结构上做的匹配。PBM则基于分而治之的思想做。 计算相似度的组合策略如下图所示: 首先经由PBM进行分而治之,后进入到V-Doc和 I-Sub ,GMO接收两者的输出做进一步处理,GMO的输出连同V-Doc和I-Sub的输出经由最终的贪心算法进行选取。 Limes 实体匹配Limes是一个基于度量空间的实体匹配发现框架,适合于大规模数据链接,编程语言是Java。其整体框架如下图所示: 该整体流程用文字表述为: 给定源数据集S,目标数据集T,阈值 θ θ ; 样本选取: 从T中选取样本点E来代表T中数据,所谓样本点,也就是能代表距离空间的点。应该在距离空间上均匀分布,各个样本之间距离尽可能大。; 过滤: 计算 s∈S s ∈ S 与 e∈E e ∈ E 之间的距离m(s, e),利用三角不等式进行过滤; 相似度计算: 同上; 序列化: 存储为用户指定格式; 三角不等式过滤给定 (A,m),m是度量标准,相当于相似性函数,A中的点x,y和z相当于三条记录,根据三角不等式有: m(x,y)≤m(x,z)+m(z,y) m ( x , y ) ≤ m ( x , z ) + m ( z , y )上式通过推理可以得到: m(x,y)−m(y,z)>θ→m(x,z)>θ m ( x , y ) − m ( y , z ) > θ → m ( x , z ) > θ上式中y相当于样本点。因为样本点E的数量是远小于目标数据集T的数量,所以过滤这一步会急剧减少后续相似性比较的次数,因而对大规模的web数据,这是非常高效的算法。 Cite王昊奋知识图谱教程 |







【本文地址】
今日新闻 |
推荐新闻 |