【知识图谱】知识融合 |
您所在的位置:网站首页 › 知识图谱实体消岐 › 【知识图谱】知识融合 |
【知识图谱】知识融合
|
文章目录
一、知识融合1、基本概念2、数据层的知识融合(1)不同KG的知识融合(2)不同知识库的知识融合(3)不同来源数据的知识融合(4)知识在线融合
3、Schema层的知识融合4、技术及其挑战5、相关比赛——OAEI
二、知识融合的基本技术流程1、基本技术流程2、数据预处理3、记录链接(1)属性相似度① 编辑距离② 基于集合相似度③ 基于向量的相似度
(2)实体相似度① 基于聚合的方法② 基于聚类的方法③ 基于知识表示学习
4、分块(Blocking)5、负载均衡6、结果评估
三、典型知识融合工具1、本体匹配(本体对齐)工具——Falcon-AO2、实体匹配工具——Dedupe(1)指定谓词集合&相似度函数(2)训练Blocking(3)训练逻辑回归 (LR)模型
3、实体匹配工具——Limes4、实体匹配工具——Silk
一、知识融合
1、基本概念
知识融合目标是融合各个层面(概念层、数据层)的知识,在合并两个知识图谱(本体)时,需要确认: 等价实例(数据层面)等价类/子类等价属性/子属性相关的术语:(不同维度的描述) 知识融合 (Knowledge Fusion):最为全面Schema层面: 属性和概念 本体对齐 (Ontology Alignment)本体匹配 (Ontology Matching) 数据层面: Record Linkage (传统数据库领域)Entity Resolution (传统数据库领域)实体对齐 (Entity Alignment) 2、数据层的知识融合数据层的知识融合主要强调实体的知识融合 最主要的工作:实体对齐,即找出等价实例 (1)不同KG的知识融合下图是将猫王从YAGO和ElvisPedia进行融合的例子。 最主要的工作:实体对齐,即找出等价实例,图中的sameAs就是融合的关键步骤。 来源于不同知识库的“自由女神像”
示例:实体——扑热息痛 此外,还有跨语言等的知识融合。 3、Schema层的知识融合Schema层的融合主要强调概念和属性等的融合。 示例:医疗知识图谱——如将中文医疗知识图谱与UMLS体系结构概念等的融合 知识融合需要: 确定哪些会对齐在一起;从不同地方抽取出来的数据的置信度是多少;这些置信度如何随着融合而合理的聚合。注意:知识融合并不是合并两个知识图谱,而是发现两个知识图谱之间的等价实例、等价或为包含关系等概念或属性。 知识融合的主要技术挑战: 数据质量的挑战 命名模糊,数据输入错误,数据丢失,数据格式不一致,缩写等 数据规模的挑战: 数据量大 (并行计算),数据种类多样性,不再仅仅通过名字匹配,多种关系,更多链接等 5、相关比赛——OAEIOAEI (Ontology Alignment Evaluation Initiative)本体对齐竞赛:用来评估各种本体对齐算法,以达到评估、比较、交流以及促进本体对齐工作的目的。 OAEI每年举办一次,结果公布在官网上。 Tracks: 知识融合一般分为两步:本体对齐 和 实体匹配,因为两者相关性,方法思路如下: ==》Pipeline方法、Joint方法 它们的基本流程相似,如下:
数据预处理阶段:原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化处理是提高后续链接精确度的重要步骤。 数据预处理相关技术: 语法正规化 语法匹配:联系电话的表示方法综合属性:家庭地址的表达方式 数据正规化 移除空格,《》,“”,-,等符号输入错误类的拓扑错误用正式名字替换昵称和缩写等 3、记录链接假设两个实体的记录 x x x 和 y y y , x x x 和 y y y 在第 i i i 个属性上的值是 x i , y i x_i,y_i xi,yi,那么通过如下两步进行记录链接: 属性相似度: 综合单个属性相似度得到属性相似度向量 [ s i m ( x 1 , y 1 ) , s i m ( x 2 , y 2 ) , … , s i m ( x N , y N ) ] [sim(x_1,y_1),sim(x_2,y_2),…,sim(x_N,y_N)] [sim(x1,y1),sim(x2,y2),…,sim(xN,yN)] 实体相似度: 根据属性相似度向量得到一个实体的相似度 (1)属性相似度计算属性相似度的方法:编辑距离(基于字符)、集合相似度计算 和 基于向量的相似度计算。 ① 编辑距离Levenshtein distance (最小编辑距离): 目的:用最少的编辑操作将一个字符串转换成另一个。示例:将 Lvensshtain 转换成Levenshtein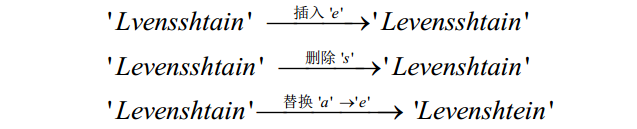 上述将 Lvensshtain 转换成Levenshtein,总共的操作 3 次,编辑距离也就是 3。求解:Levenshtein distance是一个典型的动态规划问题,可以使用动态规划算法计算:
{
D
(
0
,
0
)
=
0
D
(
i
,
0
)
=
D
(
i
−
1
,
0
)
+
1
1
;
i
≤
N
D
(
0
,
j
)
=
D
(
0
,
j
−
1
)
+
1
1
;
j
≤
M
\left\{ \begin{aligned} D(0,0);=0 \\ D(i,0);=D(i-1,0)+1;1;i\le{N}\\ D(0,j);=D(0,j-1)+1;1;j\le{M} \end{aligned} \right.
⎩⎪⎨⎪⎧D(0,0)D(i,0)D(0,j)=0=D(i−1,0)+1=D(0,j−1)+11θ 其中,
y
y
y 相当于样本点。因为样本点
E
E
E 的数量是远小于目标数据集
T
T
T 的数量,所以过滤这一步会急剧减少后续相似性比较的次数,因而对大规模的Web数据,这是非常高效的算法。 推理式说明
m
(
x
,
z
)
;
θ
m(x, z) ; \theta
m(x,z)>θ 的计算可以省去。
(3)相似度计算:相似度计算见上(4)序列化:存储为用户指定格式
4、实体匹配工具——Silk 上述将 Lvensshtain 转换成Levenshtein,总共的操作 3 次,编辑距离也就是 3。求解:Levenshtein distance是一个典型的动态规划问题,可以使用动态规划算法计算:
{
D
(
0
,
0
)
=
0
D
(
i
,
0
)
=
D
(
i
−
1
,
0
)
+
1
1
;
i
≤
N
D
(
0
,
j
)
=
D
(
0
,
j
−
1
)
+
1
1
;
j
≤
M
\left\{ \begin{aligned} D(0,0);=0 \\ D(i,0);=D(i-1,0)+1;1;i\le{N}\\ D(0,j);=D(0,j-1)+1;1;j\le{M} \end{aligned} \right.
⎩⎪⎨⎪⎧D(0,0)D(i,0)D(0,j)=0=D(i−1,0)+1=D(0,j−1)+11θ 其中,
y
y
y 相当于样本点。因为样本点
E
E
E 的数量是远小于目标数据集
T
T
T 的数量,所以过滤这一步会急剧减少后续相似性比较的次数,因而对大规模的Web数据,这是非常高效的算法。 推理式说明
m
(
x
,
z
)
;
θ
m(x, z) ; \theta
m(x,z)>θ 的计算可以省去。
(3)相似度计算:相似度计算见上(4)序列化:存储为用户指定格式
4、实体匹配工具——Silk
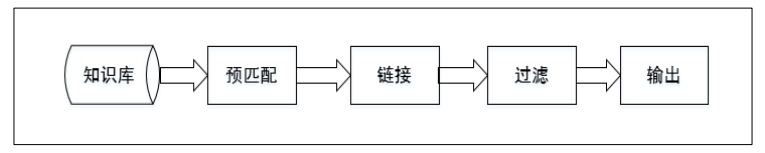
Silk:An open source framework for integrating heterogeneous data sources. 整体框架 |







【本文地址】
今日新闻 |
推荐新闻 |