指数分布的理解,推导与应用 |
您所在的位置:网站首页 › 相关函数性质推导过程怎么写 › 指数分布的理解,推导与应用 |
指数分布的理解,推导与应用
|
指数分布的定义
在浙大版的教材中,指数分布的定义如下: 若连续型的随机变量 X X X的概率密度为: f ( x ) = { 1 θ e − x θ , x>0 0 , 其他 f(x) = \begin{cases} \frac{1}{\theta} e^{-\frac{x}{\theta}}, & \text{x>0}\\ 0, & \text{其他} \end{cases} f(x)={θ1e−θx,0,x>0其他 其中 θ > 0 \theta>0 θ>0为常数,则称 X X X服从参数为 θ \theta θ的指数分布,其中 θ \theta θ的含义是事件发生的时间间隔 需要特别注意的是在考研大纲中的形式如下: f ( x ) = { λ e − λ x , x ≥ 0 0 , 其他 f(x) = \begin{cases} \lambda e^{-\lambda{x}}, & x \geq 0\\ 0, & \text{其他} \end{cases} f(x)={λe−λx,0,x≥0其他 其中 λ \lambda λ为每单位时间发生该事件的次数,这种形式更加常见,服从的是参数为 1 λ \frac{1}{\lambda} λ1的指数分布 指数分布分布的理解与公式推导在之前的文章中我们说过泊松分布https://blog.csdn.net/qq_42692386/article/details/125916391,可以知道泊松分布其实是描述一段时间内事情发生了多少次(例子中就是营业时间内卖了多少个馒头)的概率分布,而现在我们想研究一下事件与事件之间间隔时间(卖两个馒头之间的间隔时间)的服从什么分布呢? 假如某一天没有卖出馒头,比如说周三吧,这意味着,周二最后卖出的馒头,和周四最早卖出的馒头中间至少间隔了一天: 当然也可能运气不好,周二也没有卖出馒头。那么卖出两个馒头的时间间隔就隔了两天,但无论如何时间间隔都是大于一天的: P ( X = 0 ) = λ 0 0 ! e − λ = e − λ P(X=0)=\frac{\lambda^0}{0!}e^{-\lambda}=e^{-\lambda} P(X=0)=0!λ0e−λ=e−λ 根据上面的分析,卖出两个馒头之间的时间间隔要大于一天,那么必然要包含没有卖出馒头的这天,所以两者的概率是相等的。如果假设随机变量为: Y = 卖出两个馒头之间的时间间隔 Y=卖出两个馒头之间的时间间隔 Y=卖出两个馒头之间的时间间隔 那么就有: P ( Y > 1 ) = P ( X = 0 ) = e − λ P(Y > 1)=P(X=0)=e^{-\lambda} P(Y>1)=P(X=0)=e−λ 但是现在问题出现了:之前求出的泊松分布实在限制太大,只告诉了我们每天卖出的馒头数。而两个馒头卖出的事件间隔可能是大于一天,也有可能只间隔了几分钟,所以我们想知道任意的事件间隔里卖出的馒头数量的概率分布,比如半天卖出的馒头数的分布,一小时卖出的馒头数的分布。 稍微扩展下可以得到新的函数: P ( X = k , t ) = ( λ t ) k k ! e − λ t P(X=k,t)=\frac{({\lambda}{t})^k}{k!}e^{-\lambda{t}} P(X=k,t)=k!(λt)ke−λt 扩展后得到的这个函数称为泊松过程,具体的推导过程比较复杂,可以自行搜索学习,这里不再赘述。 通过新的这个函数就可知不同的时间段 t t t内卖出的馒头数的分布了( t = 1 t=1 t=1时就是泊松分布):
根据之前的分析,两次卖出馒头之间的时间间隔大于 t t t的概率,等同于 t t t时间内没有卖出一个馒头的概率,而后者的概率可以由泊松过程给出。还是一样假设随机变量 Y = 卖出两个馒头之间的时间间隔 Y=卖出两个馒头之间的时间间隔 Y=卖出两个馒头之间的时间间隔 则随机变量 Y Y Y的概率: P ( Y > t ) = P ( X = 0 , t ) = ( λ t ) 0 0 ! e − λ t = e − λ t , t ≥ 0 P(Y > t)=P(X=0,t)=\frac{({\lambda}{t})^0}{0!}e^{-\lambda{t}}=e^{-\lambda{t}},t \geq 0 P(Y>t)=P(X=0,t)=0!(λt)0e−λt=e−λt,t≥0 进而有: P ( Y ≤ t ) = 1 − P ( Y > t ) = 1 − e − λ t P(Y \leq t)=1-P(Y > t)=1-e^{-\lambda{t}} P(Y≤t)=1−P(Y>t)=1−e−λt 这其实已经得到了 的累积分布函数了: F ( y ) = P ( Y ≤ y ) = { 1 − e − λ y , y ≥ 0 0 , y < 0 F(y)=P(Y \leq y)= \begin{cases} 1-e^{-\lambda{y}}, & y\geq 0 \\ 0, & ys+t \mid X>s)=P(X>t), \quad \ \ s, t \geq 0 P(X>s+t∣X>s)=P(X>t), s,t≥0 指数分布的无记忆性证明如下: P ( X > s + t ∣ X > s ) = P { ( X > s + t ) ∩ ( X > s ) } P ( X > s ) = P ( X > s + t ) P ( X > s ) = 1 − F ( s + t ) 1 − F ( s ) = e − λ ( s + t ) e − λ ( s ) = e − λ t = P ( X > t ) P(X>s+t \mid X>s)=\frac{P\{(X>s+t) \cap ( X>s)\}}{ P( X>s)} \\ =\frac{P(X>s+t)}{ P( X>s)} =\frac{1-F(s+t)}{ 1-F(s)} \\ =\frac{e^{-\lambda(s+t)}}{e^{-\lambda(s)}}=e^{-\lambda{t}}=P(X>t) P(X>s+t∣X>s)=P(X>s)P{(X>s+t)∩(X>s)}=P(X>s)P(X>s+t)=1−F(s)1−F(s+t)=e−λ(s)e−λ(s+t)=e−λt=P(X>t) 在浙大教材中有个例子:如果X是某一个电器的使用寿命,在使用过 s 小时后,它还能再使用 t 小时的概率,和它一开始算寿命就是 t 小时的概率是一样的。 很多人觉得日常生活中的电子元件用了十年之后不可能还能和新的有一样的预期寿命,实际上这个例子应该要加上一个条件的:如果将电器考虑作理想的电器,器件不会老化。 此时,电器的寿命是随机的。可以视为电器内部彷佛每秒钟都在扔硬币(扔硬币很好理解,不管前面扔了多少次,再扔一次硬币正反面的概率仍是二分之一),扔到了正面,电器就坏了。在这种情况下,我们认为电器的寿命服从指数分布。现实中是不会有理想电器的,但是如果只考虑短时间内的电器寿命,那么就可以将之视作理想电器,认为它的寿命服从指数分布。 指数分布应用实例假设银行平均每 10 分钟接到一个新电话。客户致电后,确定下一个客户在之后 10 到 15 分钟内致电的可能性。 λ = 1 10 = 0.1 λ =\frac{1}{10}=0.1 λ=101=0.1 则新客户在 10-15 分钟内致电的概率: P ( 10 < X ≤ 15 ) = P ( X ≤ 15 ) − P ( X ≤ 10 ) = ( 1 – e − 0.1 × 15 ) – ( 1 – e − 0.1 × 10 ) = 0.7769 – 0.6321 = 0.1448 P(10 < X ≤ 15) =P( X ≤ 15)-P(X ≤ 10)= (1 – e^{ -0.1\times15} )– (1 – e^{ -0.1\times10 })= 0.7769 – 0.6321= 0.1448 P(10 |
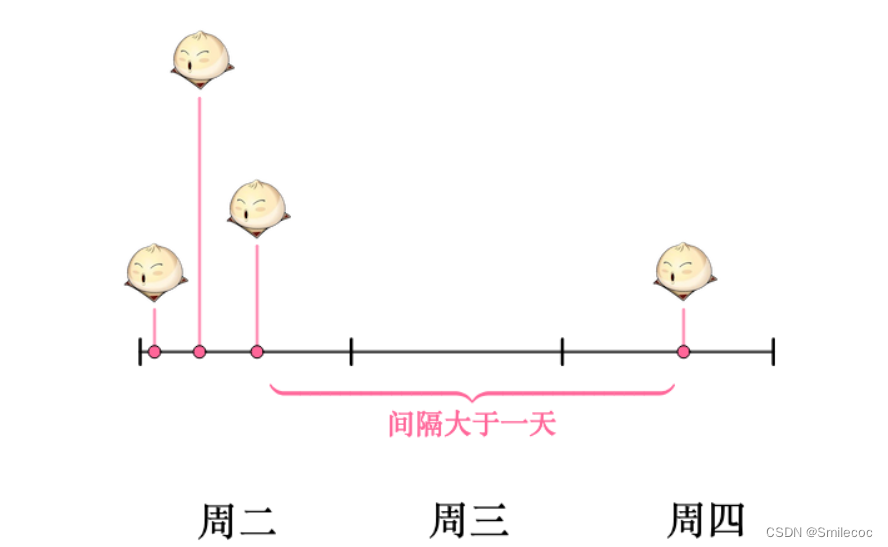
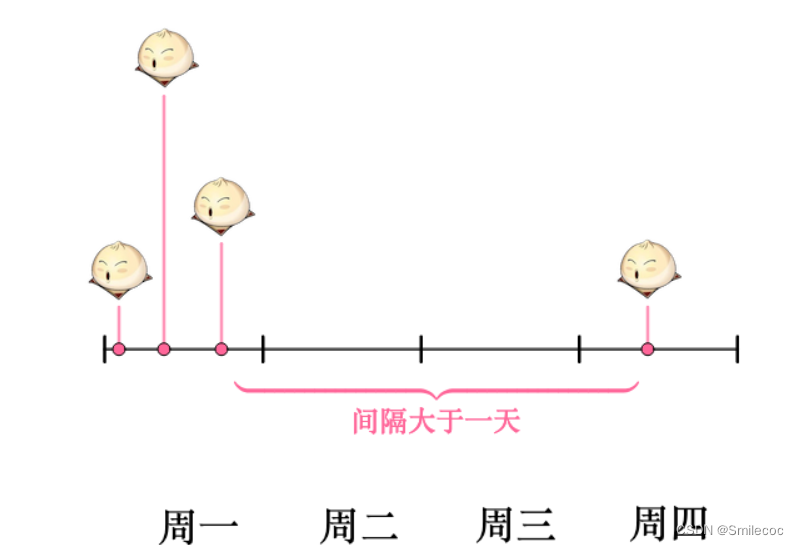 而某一天没有卖出馒头的概率可以由泊松分布得出:
而某一天没有卖出馒头的概率可以由泊松分布得出: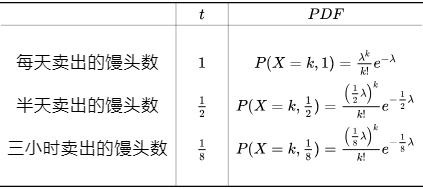
【本文地址】
今日新闻 |
推荐新闻 |