matplotlib绘制直方图之基本配置 |
您所在的位置:网站首页 › 直方图的绘制例题及答案 › matplotlib绘制直方图之基本配置 |
matplotlib绘制直方图之基本配置
|
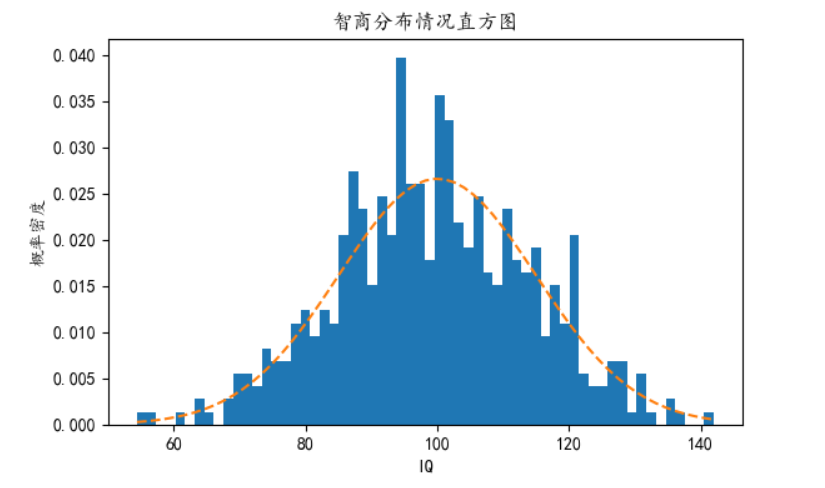
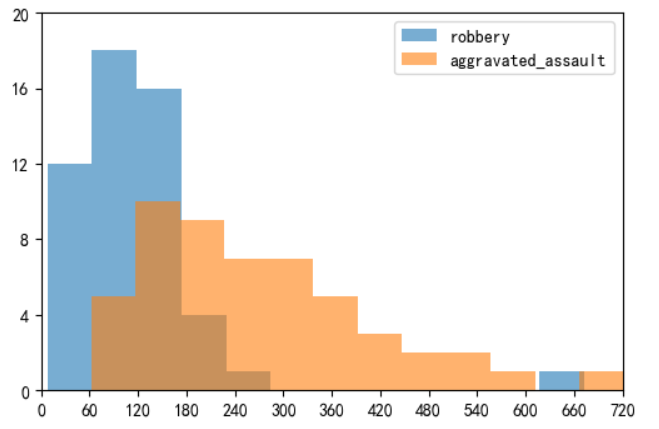
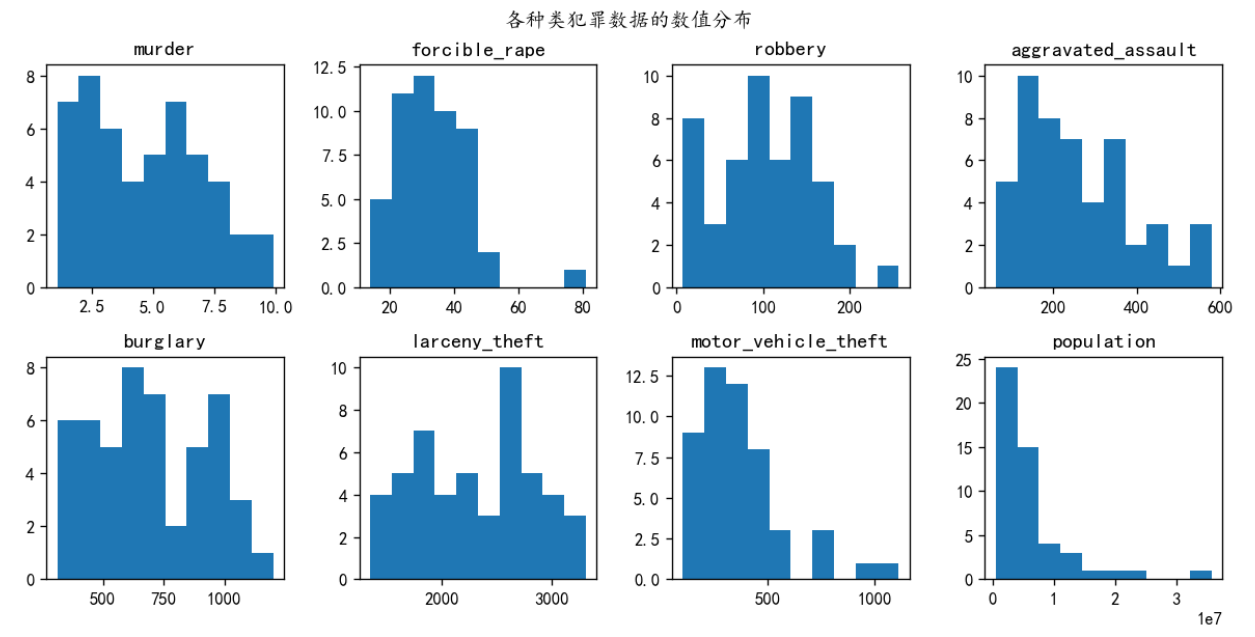
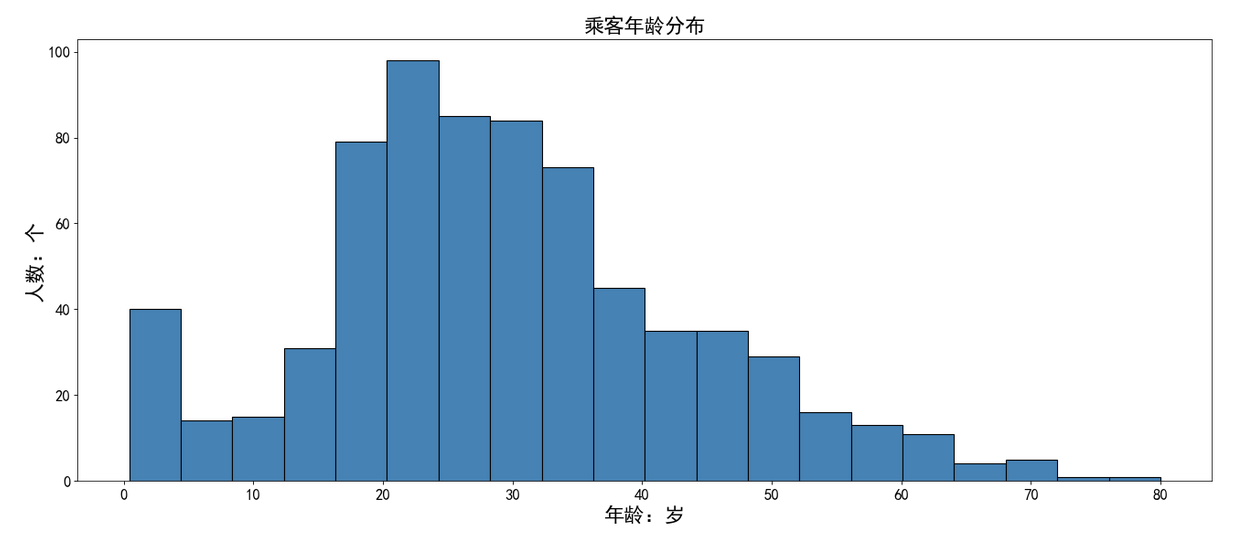
目录 直方图介绍 绘制直方图的参数(plt.hist()) 连接数据库进行直方图绘制案例 使用dataframe里面的plot函数进行绘制(万能模板) 绘制多个子图(多子图直方图案例模板) 概率分布直方图(统计图形) 直方图内显示折线图分布 堆叠面积直方图 在不同的子图中绘制各种类犯罪数据的数值分布 其他案例 乘客年龄分布频数直方图 男女乘客直方图(二维数据) 电影时长分布直方图 每文一语 直方图介绍直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。 直方图是数值数据分布的精确图形表示。 这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。 为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。 这些值通常被指定为连续的,不重叠的变量间隔。 间隔必须相邻,并且通常是(但不是必须的)相等的大小。 直方图也可以被归一化以显示“相对”频率。 然后,它显示了属于几个类别中的每个案例的比例,其高度等于1。 绘制直方图的参数(plt.hist())
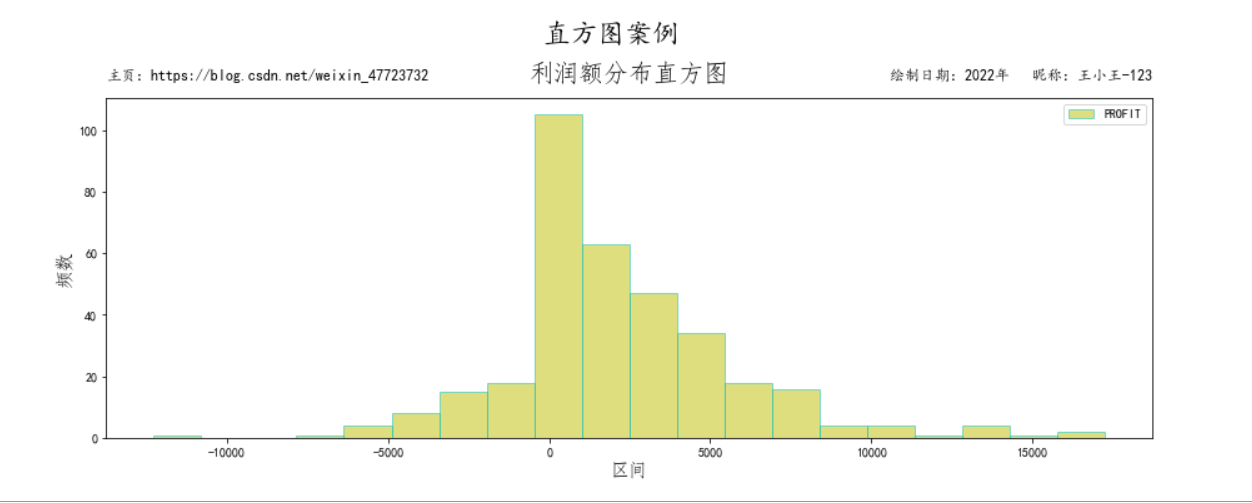
通常而言,绘制直方图有很多种方法,比如采用matplotlib里面的模块进行绘制,也可以是pandas里面的图形进行绘制,也可以使用Python里面其他的统计绘图模块进行绘制图形,总而言之,想要图形展示的美观,那么就需要自己配置,也就是说模板固然重要,但是如果不懂原理的进行搬运和借用,反而效果不是很好! 连接数据库进行直方图绘制案例 # -*- coding: utf-8 -*- import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties mpl.rcParams['font.sans-serif']=['SimHei'] #显示中文 plt.rcParams['axes.unicode_minus']=False #正常显示负号 import pymysql #连接MySQL数据库 v1 = [] v2 = [] db = pymysql.connect(host='127.0.0.1', port=3306, database='mydb',user='root',password='root') cursor = db.cursor() #读取订单表数据,统计每日利润额 sql_str = "SELECT order_date,ROUND(SUM(profit)/10000,2) FROM orders WHERE FY=2019 GROUP BY order_date" cursor.execute(sql_str) result = cursor.fetchall() for res in result: v1.append(res[0]) # order_date v2.append(res[1]) # sum_profit_by_order_date 每日利润额 plt.figure(figsize=(10,5)) #设置图形大小 cs,bs,bars = plt.hist(v2, bins=20, density=False, facecolor="cyan", edgecolor="black", alpha=0.7) width = bs[1]-bs[0] for i,c in enumerate(cs): plt.text(bs[i]+width/3,c,round(c)) # 返回一个counts数组,一个bins数组和一个图形对象 # 显示横轴标签 plt.xlabel("区间",fontdict={'family':'Fangsong','fontsize':15}) # 显示纵轴标签 plt.ylabel("频数",fontdict={'family':'Fangsong','fontsize':15}) # 显示图标题 plt.title("利润额分布直方图",fontdict={'family':'Fangsong','fontsize':20}) plt.show() 使用dataframe里面的plot函数进行绘制(万能模板)一般而言,我们导入数据的时候,大概率都是基于表数据进行可视化的,很少使用那些自主独立的数据进行绘制,如果是那种数据,很多人都会去使用origin这个绘图软件了,程序绘图最大的好处就是不需要对数据结果进行输出,输入,这样在很大程度上减少了我们的时间,提高了我们的工作效率。 # 使用DataFrame的plot函数画图 import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties mpl.rcParams['font.sans-serif']=['SimHei'] #显示中文 plt.rcParams['font.sans-serif'] = 'KaiTi' # 设置全局字体为中文 楷体 plt.rcParams['axes.unicode_minus']=False #正常显示负号 plt.figure(dpi=130) datafile = r'../data/orders.csv' data = pd.read_csv(datafile).query("FY==2019").groupby('ORDER_DATE')[['PROFIT']].sum() data.plot(kind='hist',bins=20,figsize=(15,5),color='y',alpha=0.5,edgecolor='c',histtype='bar') plt.xlabel("区间",fontdict={'family':'Fangsong','fontsize':15}) plt.ylabel("频数",fontdict={'family':'Fangsong','fontsize':15}) plt.title("利润额分布直方图",fontdict={'family':'Fangsong','fontsize':20},y=1.03) # 设置图形上的各类主题值 plt.suptitle('直方图案例',size=22,y=1.05) plt.title("绘制日期:2022年 昵称:王小王-123", loc='right',size=12,y=1.03) plt.title("主页:https://blog.csdn.net/weixin_47723732", loc='left',size=12,y=1.03) plt.show()
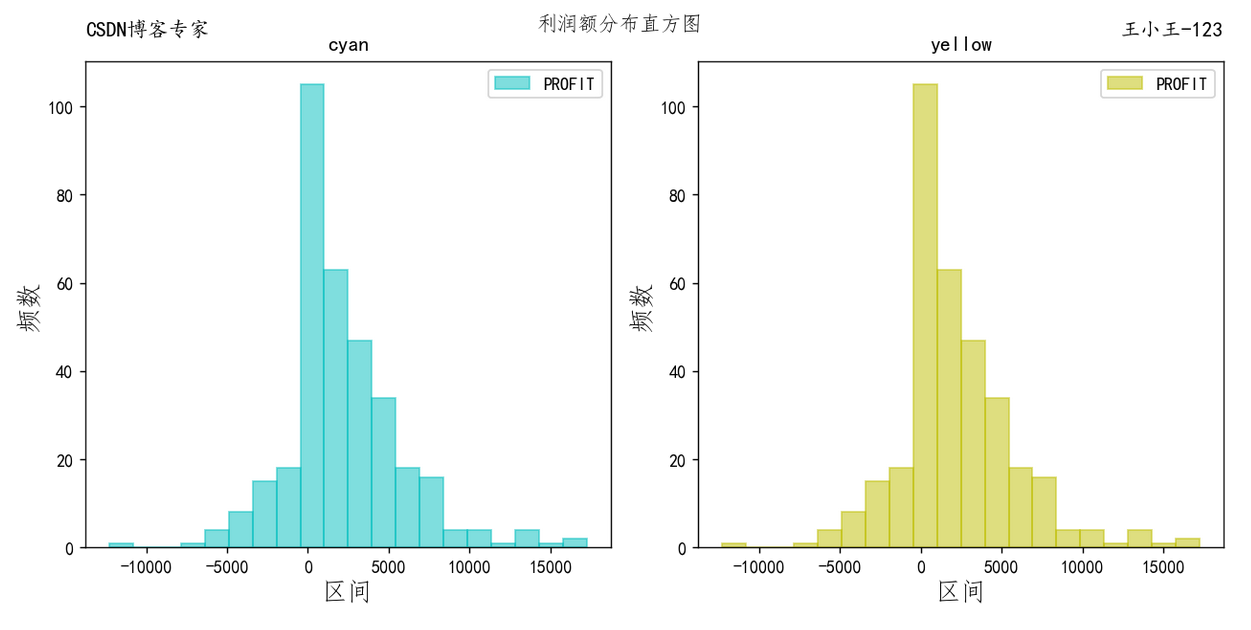
plt.tight_layout() # 自动紧凑布局,避免遮挡 是很重要的一个参数,一般是在结尾出添加这个参数 import pandas as pd datafile = r'../data/orders.csv' data = pd.read_csv(datafile).query("FY==2019").groupby('ORDER_DATE')[['PROFIT']].sum() fig = plt.figure(figsize=(10,5),dpi=130) # 生成画布 # 生成子图1 ax1 = plt.subplot(121) # 1行2列中的第1个 plt.title("CSDN博客专家", loc='left',size=12,y=1.03) #添加备注 # 生成子图2 ax2 = plt.subplot(122) # 1行2列中的第2个 # 设置图形上的各类主题值 plt.title("王小王-123", loc='right',size=12,y=1.03)#添加备注 #df.plot使figure级别的绘图函数,默认会生成新的figure,可以通过ax参数指定绘图的坐标子图 data.plot(kind='hist',bins=20,color='c',alpha=0.5,edgecolor='c',histtype='bar',ax=ax1,figure=fig) # 指定这个图画到ax1中 #plt.xlabel("区间",fontdict={'family':'Fangsong','fontsize':15}) ax1.set_xlabel("区间",fontdict={'family':'Fangsong','fontsize':15}) #plt.ylabel("频数",fontdict={'family':'Fangsong','fontsize':15}) ax1.set_ylabel("频数",fontdict={'family':'Fangsong','fontsize':15}) ax1.set_title("cyan") #print(ax1.get_xticks()) data.plot(kind='hist',bins=20,color='y',alpha=0.5,edgecolor='y',histtype='bar',ax=ax2,figure=fig) # 指定这个图画到ax2中 # plt.xlabel = plt.gca().set_xlabel() plt. 获取“当前”的坐标子图,需要小心执行的位置 plt.xlabel("区间",fontdict={'family':'Fangsong','fontsize':15}) plt.ylabel("频数",fontdict={'family':'Fangsong','fontsize':15}) plt.title("yellow") # subplot的标题 plt.suptitle("利润额分布直方图",fontdict={'family':'Fangsong','size':22}) # figure的标题 plt.tight_layout() # 自动紧凑布局,避免遮挡 plt.show()
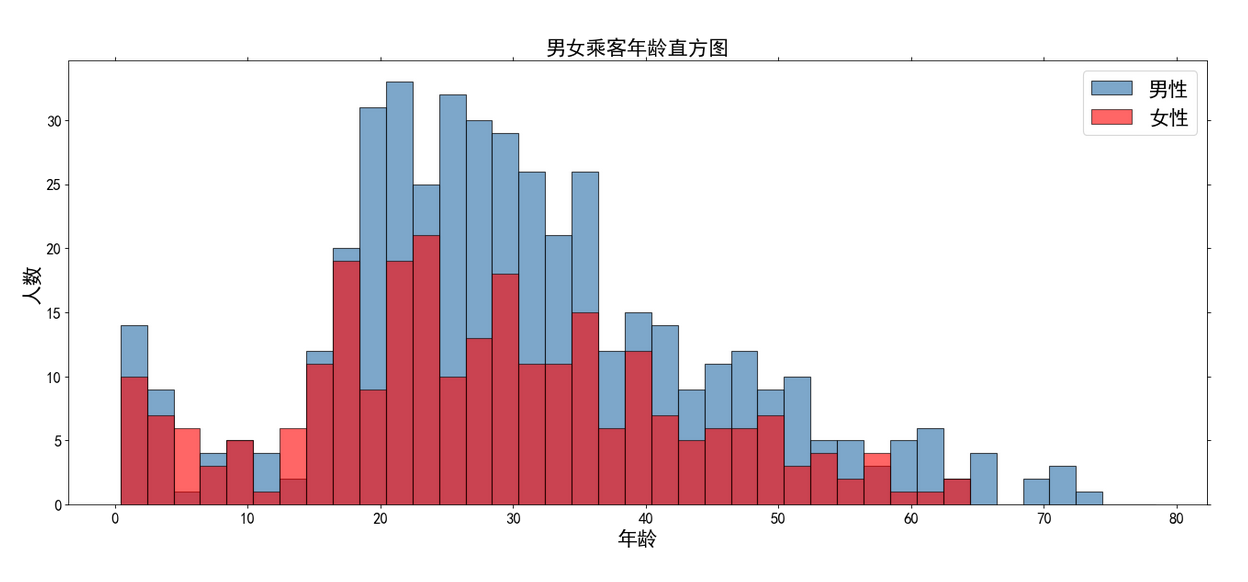
设置了组距和其他的参数 # 导入库 import matplotlib.pyplot as plt import numpy as np # 设置字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 创建图形 plt.figure(figsize=(20,8),dpi=80) # 提取不同性别的年龄数据 age_female = titanic.Age[titanic.Sex == 'female'] age_male = titanic.Age[titanic.Sex == 'male'] # 设置直方图的组距 bins = np.arange(titanic.Age.min(), titanic.Age.max(), 2) # 男性乘客年龄直方图 plt.hist(age_male, bins = bins, label = '男性',edgecolor = 'k', color = 'steelblue', alpha = 0.7) # 女性乘客年龄直方图 plt.hist(age_female, bins = bins, label = '女性',edgecolor = 'k', alpha = 0.6,color='r') # 调整刻度 plt.xticks(fontsize=15) plt.yticks(fontsize=15) # 设置坐标轴标签和标题 plt.title('男女乘客年龄直方图',fontsize=20) plt.xlabel('年龄',fontsize=20) plt.ylabel('人数',fontsize=20) # 去除图形顶部边界和右边界的刻度 plt.tick_params(top='off', right='off') # 显示图例 plt.legend(loc='best',fontsize=20) # 显示图形 plt.show()
坚持下去的动力来源于不断地发现新的事物! |

【本文地址】
今日新闻 |
推荐新闻 |