|
目录
需求分析
选型
设计与流程
实现过程
结果展示
1 需求分析
在一些业务场景中需要拿到IM上的通信记录来做一些数据分析,例如对QQ平台中的消息进行领域分类等。
2 选型
环境与工具:
python 2.7
Ubuntu 16.04
ElasticSearch 5.5.2
Kibana 5.5.2
Firefox 57.0.1 (64-bit)
Python第三方依赖:
pypcap(1.2.0)【捕包】
dpkt(1.9.1)【解析包】
elasticsearch(6.0.0) 【es的python客户端】
tgrocery(0.1.3)【短文本分类】
3 分析与设计
为了降低嗅探的难度,避免使用https的连接,从连接http://w.qq.com/ 抓取消息。
观察业务逻辑
使用火狐浏览器的前端工具(F12)来观察我们的研究对象

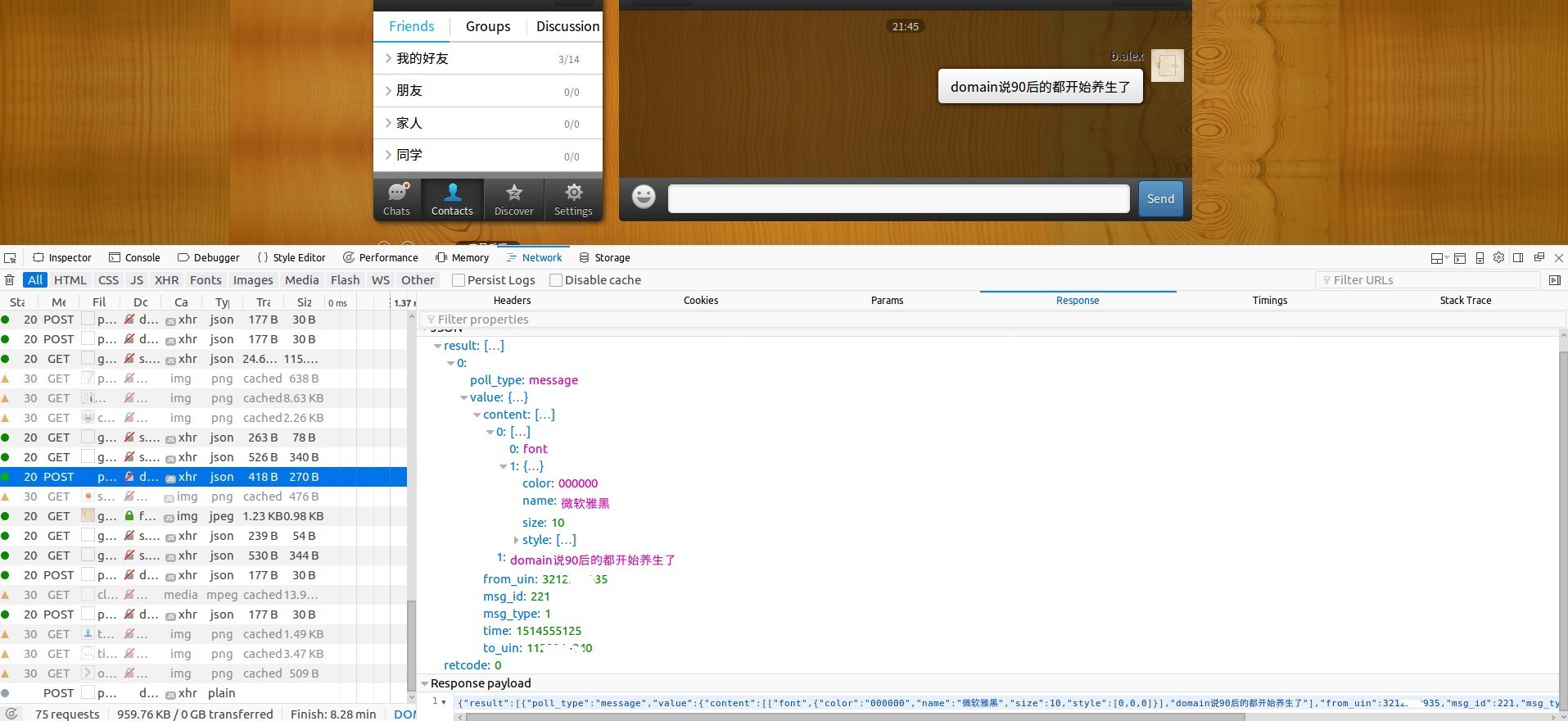
发现前端不断查询是否有新的消息产生以便获取到页面中,如果当前没有新消息,则返回一个特定的JSON。如图所示。
当有发言产生时,返回一个有意义的结果如下图所示。
流程设计
登录了QQ账号
使用pypcap自动嗅探收到的网络包
使用dpkt解析收到的网络包并过滤出有消息内容的数据包
对消息进行分类,将发言时间、发送方ID号,接收方ID号、发言内容、发言分类结果和置信度这几个信息索引到Elasticsearch中
使用Kibana进行可视化
4 实现过程
4.1 包嗅探与包解析
import pcap
import dpkt
def captData():
pc=pcap.pcap('wlp5s0') #参数可为网卡名,可以使用ifconfig命令查看
pc.setfilter('tcp port 80') #设置监听过滤器
for ptime,pdata in pc: #ptime为收到时间,pdata为收到数据
pkt = dpkt.ethernet.Ethernet(pdata)
if pkt.data.data.__class__.__name__ != 'TCP':
continue
ip_data=pkt.data
tcp_data=ip_data.data
app_data=tcp_data.data#向上层层解析直到应用层的内容
if app_data.find('poll_type')!=-1:#以特定字符串作为有消息的标识
process(app_data)
4.2 短文本分类
from tgrocery import Grocery
def labelmaker(self):
result=[]
grocery = Grocery('11c_20k_20171226')#参数是分类模型的名称
grocery.load()
label_confidence=sorted(grocery.predict(self.shorttext).dec_values.items(), lambda x, y: cmp(x[1], y[1]), reverse=True)[0]
result.append(label_confidence[0])#置信度最高的分类结果
result.append(label_confidence[1])# 置信度
return result
4.3 将数据索引到ES
from elasticsearch import Elasticsearch
import hashlib
class Index2ES:
def __init__(self,index,doctype,response_body):
self.body=response_body
self.index=index
self.doctype=doctype
self.id=hashlib.md5(str(response_body['time'])).hexdigest()
self.es = Elasticsearch()
def putdoc(self):
self.es.index(index=self.index,doc_type=self.doctype,id=self.id,body=self.body)
4.4 新建并配置Kibana图表
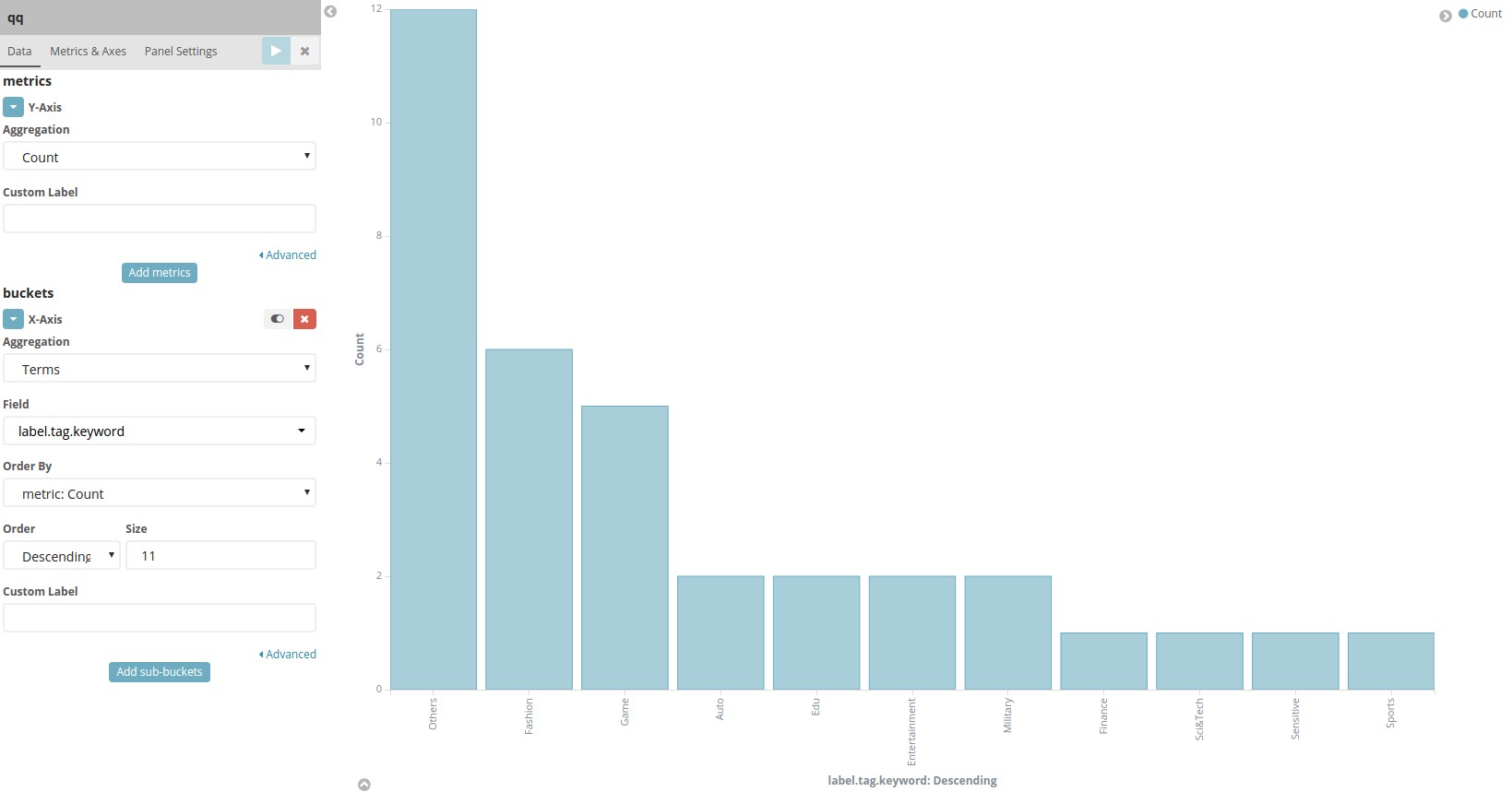
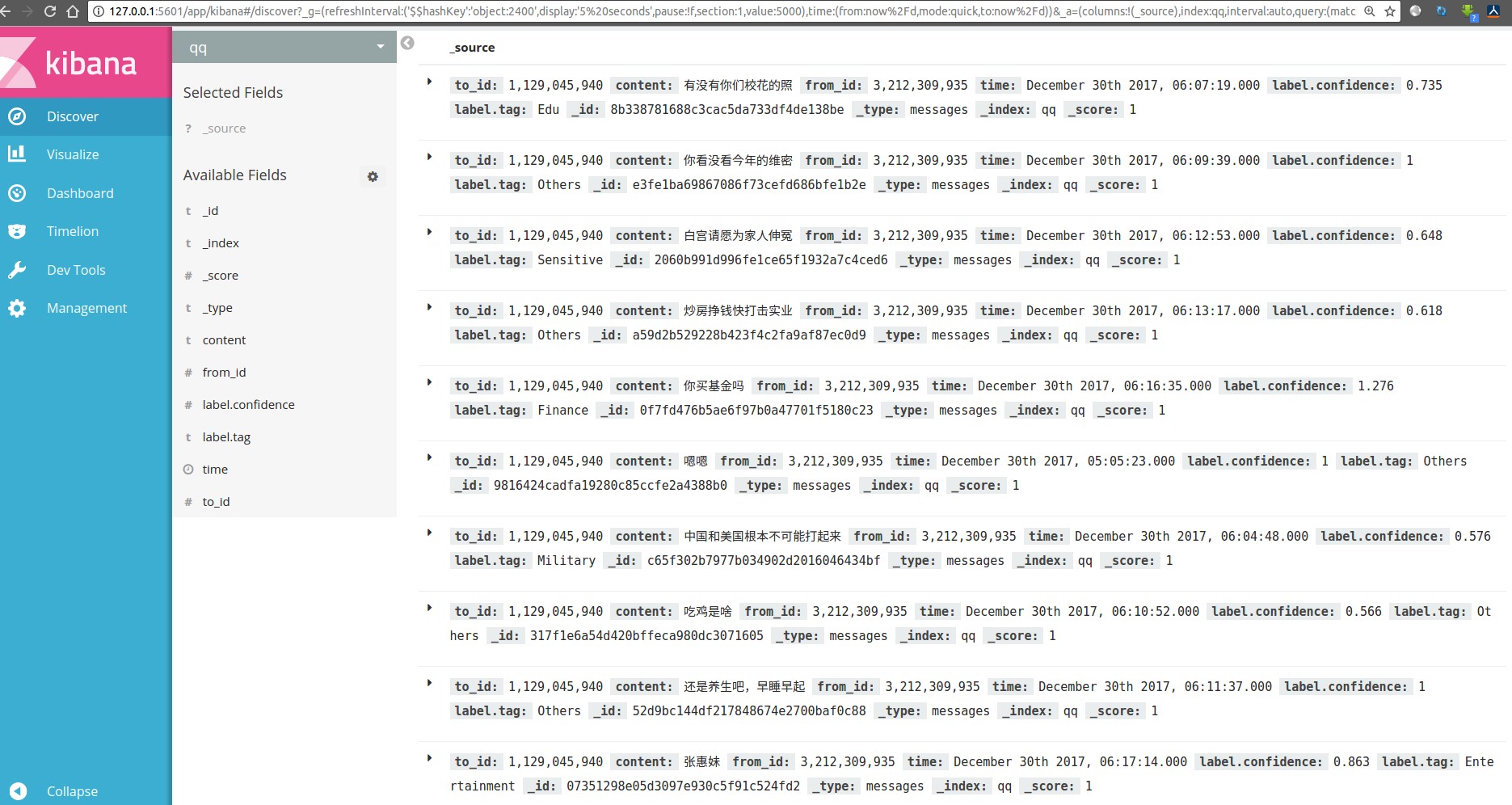
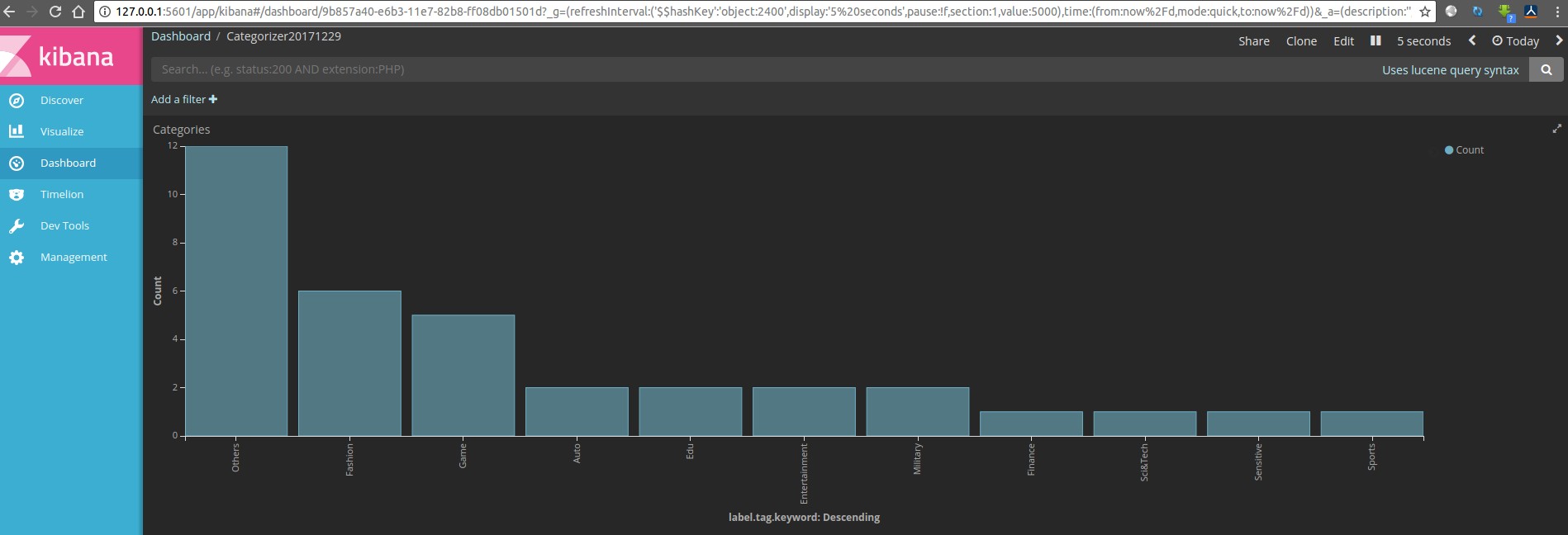
5 结果展示
源码
Github:qqSnifferAndClassifier
|