Potsdam,Vaihingen数据集(附百度网盘下载地址) |
您所在的位置:网站首页 › 百度云地址是什么 › Potsdam,Vaihingen数据集(附百度网盘下载地址) |
Potsdam,Vaihingen数据集(附百度网盘下载地址)
|
遥感数据集Potsdam,Vaihingen 的分享及处理
1. Potsdam,Vaihingen数据集下载地址(百度网盘)2. 数据集分割处理1)分割图片2)保存为.mat格式
1. Potsdam,Vaihingen数据集下载地址(百度网盘)
对于做遥感图像处理的同学来说,Potsdam,Vaihingen是两个常用的数据集。如果想下载,一般需要搭梯子下载,并且下载过程经常中断,百度相关文章,排名靠前的文章也没有给出国内相关下载链接,因此将自己下载的数据集分享出来,为大家提供方便。 Potsdam数据集:链接:https://pan.baidu.com/s/13rdBXUN_ZdelWNlQZ3Y1TQ?pwd=6c3y 提取码:6c3y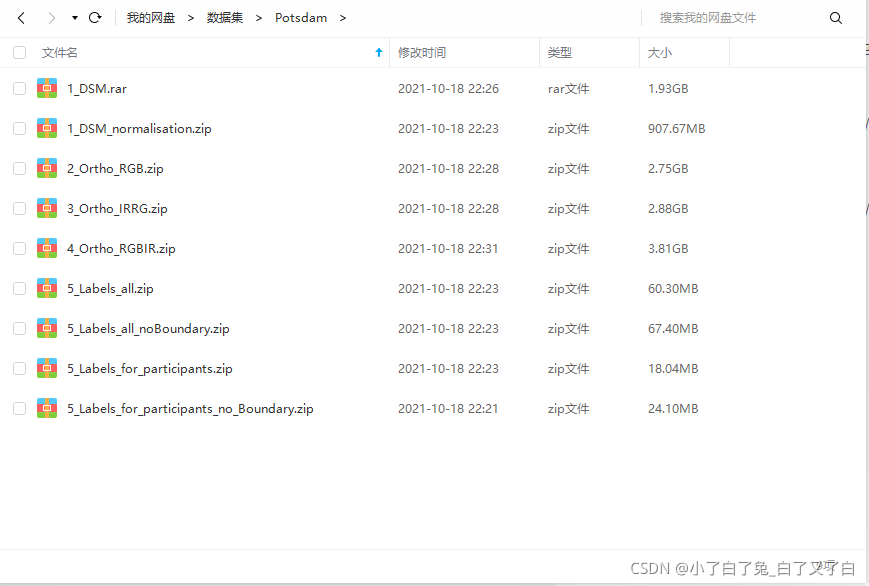 Vaihingen数据集 链接:https://pan.baidu.com/s/1EShNi22VfuIu3e6VygMb8g?pwd=3gsr 提取码:3gsr Vaihingen数据集 链接:https://pan.baidu.com/s/1EShNi22VfuIu3e6VygMb8g?pwd=3gsr 提取码:3gsr 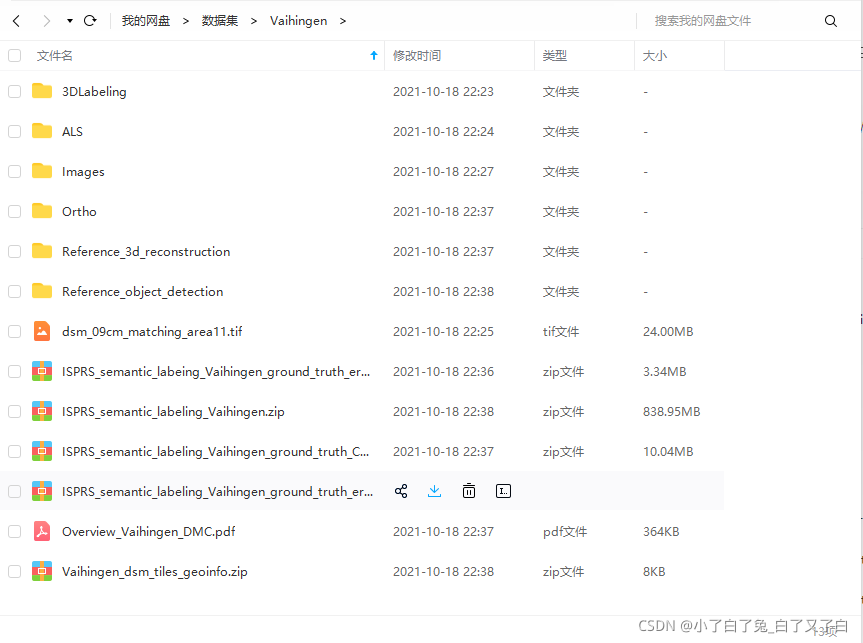 2. 数据集分割处理
1)分割图片
2. 数据集分割处理
1)分割图片
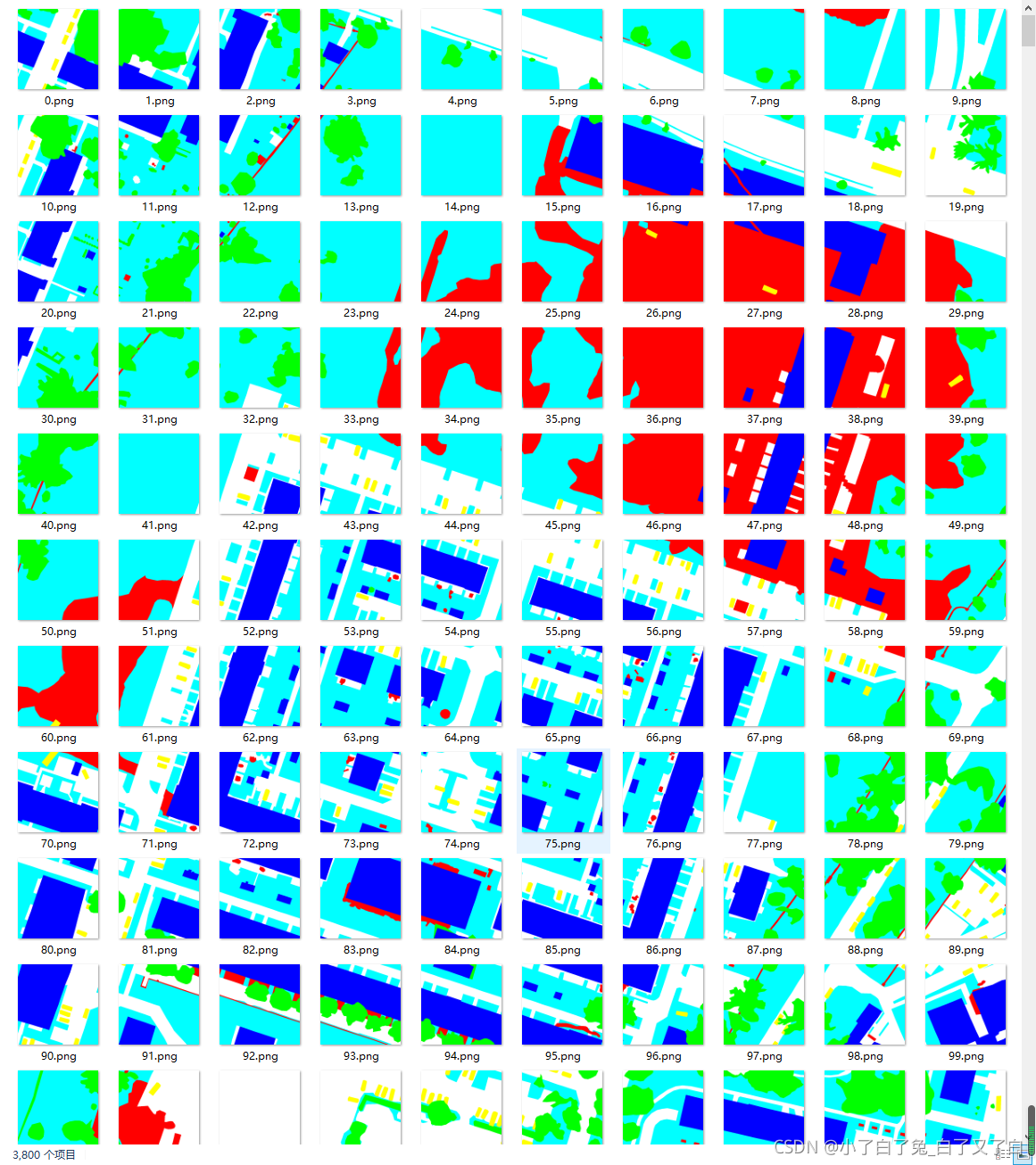
以Potsdam数据集为例,其中包含38张6000x6000尺寸的遥感图片,对于一般的训练机器来说,其尺寸有点大,因此需要对原始图片进行分割。这里我将每张原始图片分割为100张600x600的小尺寸图片,程序如下: #Python程序 import cv2 import numpy for k in range(7,14): img1 = cv2.imread('/user-data/GNN_RemoteSensor/2_Ortho_RGB/top_potsdam_7_' + str(k) + '_RGB.tif') #读取RGB原图像 img2 = cv2.imread('/user-data/GNN_RemoteSensor/5_Labels_all/top_potsdam_7_' + str(k) + '_label.tif') #读取Labels图像 # 因为数据集中图片命名不规律,所以需要一批一批的分割 # cv2.imread函数会把图片读取为(B,G,R)顺序,一定要注意!!! # cv2.imwrite函数最后会将通道调整回来,所以成对使用cv2.imread与cv2.imwrite不会改变通道顺序 #因为6000/10 = 600,所以6000x6000的图像可以划分为10x10个600x600大小的图像 for i in range(10): for j in range(10): img1_ = img1[600*i : 600*(i+1), 600*j : 600*(j+1), : ] img2_ = img2[600*i : 600*(i+1), 600*j : 600*(j+1), : ] #注意下面name的命名,2400 + k * 100需要一批一批的调整,自己看到数据集中的图片命名就能知道什么意思了 name = i*10 + j + 2400 + k * 100 #让RGB图像和标签图像的文件名对应 name = str(name) cv2.imwrite('./datasets/images/'+ name + '.jpg', img1_) #所有的RGB图像都放到jpg文件夹下 cv2.imwrite('./datasets/labels/'+ name + '.png', img2_) #所有的标签图像都放到png文件夹下分割后的图片和标签图片如下所示: 我自己的程序中,每次是访问.mat数据集,进行训练和预测,所以需要将上述图片和标签保存为.mat格式。如果有同样需求,可以参考下面的程序: #Python程序 import glob import numpy as np import cv2 import os from scipy.io import savemat array_of_img = [] for filename in os.listdir(r"./datasets/images"): img = cv2.imread("datasets/images/" + filename) #使用cv2.iread,将图片通道顺序为(BGR),所以需要在下面对通道进行调整 img2 = img[:, :, (2,1,0)] array_of_img.append(img2) array_of_lab = [] for filenames in os.listdir(r"./datasets/labels"): lab = cv2.imread("datasets/labels/" + filenames) #label没有进行通道调整,是因为在下面for循环的判断条件中,对通道顺序进行了调整,所以此处不需要调整 array_of_lab.append(lab) name_for_txt = array_of_lab.shape[0] # 3800 Width = 600 Height = 600 '''创建空矩阵,用于存放一张图片每个像素的分类数据''' self.Empty_array = np.zeros((name_for_txt, Width, Height), dtype=np.uint8) for ii in range(name_for_txt): row_Frame = self.label_images[ii] # 将一张图片的数据单独保存 for w in range(Width): for h in range(Height): '''判断属于哪一类,不一样的类有不同的颜色''' if row_Frame[w, h, 2] == 255 and row_Frame[w, h, 1] == 0 and row_Frame[w, h, 0] == 0: # 红色 self.Empty_array[ii, w, h] = 1 elif row_Frame[w, h, 2] == 255 and row_Frame[w, h, 1] ==255 and row_Frame[w, h, 0] == 0: # 黄色 self.Empty_array[ii, w, h] = 2 elif row_Frame[w, h, 2] == 0 and row_Frame[w, h, 1] == 255 and row_Frame[w, h, 0] == 255: # 青色 self.Empty_array[ii, w, h] = 3 elif row_Frame[w, h, 2] == 0 and row_Frame[w, h, 1] == 255 and row_Frame[w, h, 0] == 0: # 绿色 self.Empty_array[ii, w, h] = 4 elif row_Frame[w, h, 2] == 0 and row_Frame[w, h, 1] == 0 and row_Frame[w, h, 0] == 255: # 蓝色 self.Empty_array[ii, w, h] = 5 elif row_Frame[w, h, 2] == 255 and row_Frame[w, h, 1] == 255 and row_Frame[w, h, 0] == 255: # 白色 self.Empty_array[ii, w, h] = 6 else: # 白色 self.Empty_array[ii, w, h] = 0 savemat('./datasets/data/labels-images.mat', {'labels': Empty_array, 'images': array_of_img}, '-v7')现在数据集准备好了,可以开始训练啦。 附:上述数据集的介绍 |

【本文地址】
今日新闻 |
推荐新闻 |