ELK日志分析系统搭建 |
您所在的位置:网站首页 › 电脑日志路径 › ELK日志分析系统搭建 |
ELK日志分析系统搭建
|
一、基础环境(node1和node2 4G内存,apache 1G内存)
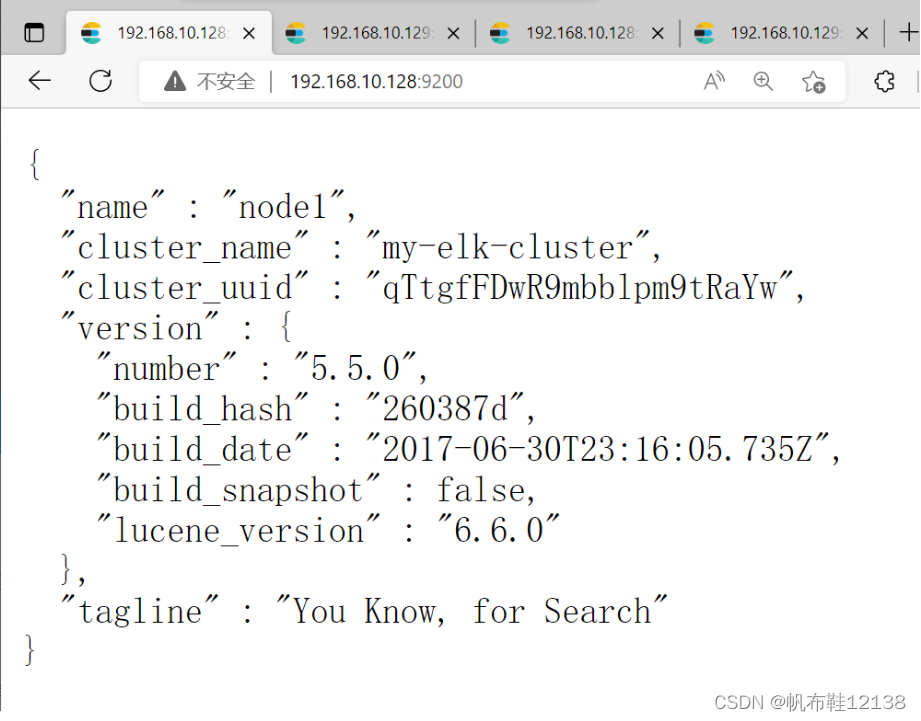
最低 配置 IP地址 主机名 所用源码包 192.168.10.128 node1 elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz phantomjs-2.1.1-linux-x86_64.tar.bz2 elasticsearch-head.tar.gz kibana-5.5.1-x86_64.rpm 192.168.10.129 node2 elasticsearch-5.5.0.rpm 192.168.10.130 apache logstash-5.5.1.rpm 二.案例需求 配置 ELK 日志分析群集。 使用 Logstash 收集日志。 使用 Kibana 查看分析日志。 三.环境准备 1)三台虚拟机配置IP地址并联网 2)三台虚拟机配置网络yum[root@localhost ~]# cd /etc/yum.repos.d/ [root@localhost yum.repos.d]# yum clean all && yum makecache 3)三台虚拟机关闭防火墙和内核安全机制[root@localhost ~]# systemctl stop firewalld [root@localhost ~]# setenforce 0 4)三台虚拟机分别修改主机名[root@localhost ~]# hostnamectl set-hostname node1 [root@localhost ~]# hostnamectl set-hostname node2 [root@localhost ~]# hostnamectl set-hostname apache 5)三台虚拟机分别修改hosts文件[root@localhost ~]# vim /etc/hosts 192.168.10.128 node1 192.168.10.129 node2 192.168.10.130 apache 6)三台虚拟机时间同步[root@localhost ~]# ntpdate ntp.aliyun.com 二、部署ES服务 (node1和node2同步) 1)检查java环境[root@node1 ~]# java -version 2)部署 Elasticsearch 软件在 Node1 和 Node2 节点上都需要部署 Elasticsearch 软件,下面以 Node1 节点为例进 行讲解,Node2 节点的配置与 Node1 节点相同。 -- 安装 Elasticsearch 软件。Elasticsearch 软件可以通过 RPM 安装、YUM 安装或者源码包安装,生产环境中用户 可以根据实际情况进行安装方式的选择。本章将通过 RPM 进行安装。 [root@node1 ~]# rpm -ivh elasticsearch-5.5.0.rpm 3)加载系统服务[root@node1 ~]# systemctl daemon-reload [root@node1 ~]# systemctl enable elasticsearch 4)修改elasticsearch主配置文件 [root@node1 ~]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak [root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml 17/ cluster.name: my-elk-cluster #集群名字 23/ node.name: node1 #节点名字 33/ path.data: /data/elk_data #数据存放路径 37/ path.logs: /var/log/elasticsearch/ #日志存放路径 43/ bootstrap.memory_lock: false #启动的时候不锁定内存 55/ network.host: 0.0.0.0 #提供服务绑定的IP地址,0.0.0.0代表所有地址 59/ http.port: 9200 #侦听端口为9200 68/ discovery.zen.ping.unicast.hosts: ["node1", "node2"] #集群发现通过单播实现注:前面数字是文件行数 5)创建数据存放路径并授权[root@node1 ~]# mkdir -p /data/elk_data [root@node1 ~]# chown elasticsearch:elasticsearch /data/elk_data/ 6)启动elasticsearch下面的命令启动 Elasticsearch 并查看是否成功开启 [root@node1 ~]# systemctl start elasticsearch.service [root@node1 ~]# netstat -antp |grep 9200 tcp6 0 0 :::9200 :::* LISTEN 32763/java 7)查看节点信息打开浏览器,输入地址:http://192.168.10.128:9200,则看到node1节点信息; { "name": "node1", "cluster_name": "my-elk-cluster", "cluster_uuid": "iJE8xqH0TviOe8aOb_ytIg", "version": { "number": "5.5.0", "build_hash": "260387d", "build_date": "2017-06-30T23:16:05.735Z", "build_snapshot": false, "lucene_version": "6.6.0" }, "tagline": "You Know, for Search" }
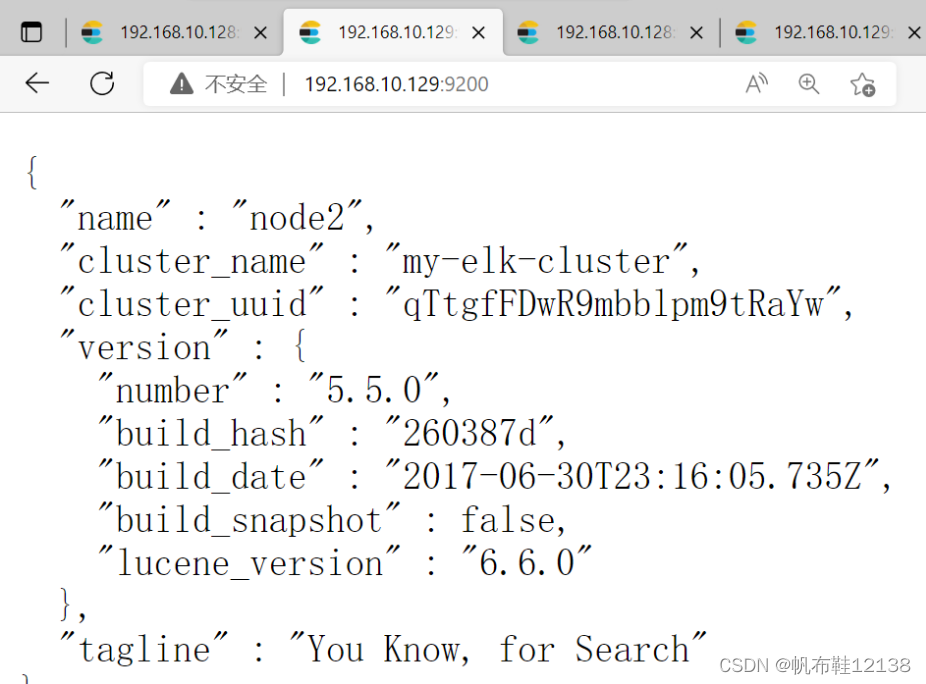
打开浏览器,输入地址:http://192.168.10.129:9200,则看到node2节点信息; { "name": "node2", "cluster_name": "my-elk-cluster", "cluster_uuid": "iJE8xqH0TviOe8aOb_ytIg", "version": { "number": "5.5.0", "build_hash": "260387d", "build_date": "2017-06-30T23:16:05.735Z", "build_snapshot": false, "lucene_version": "6.6.0" }, "tagline": "You Know, for Search" }
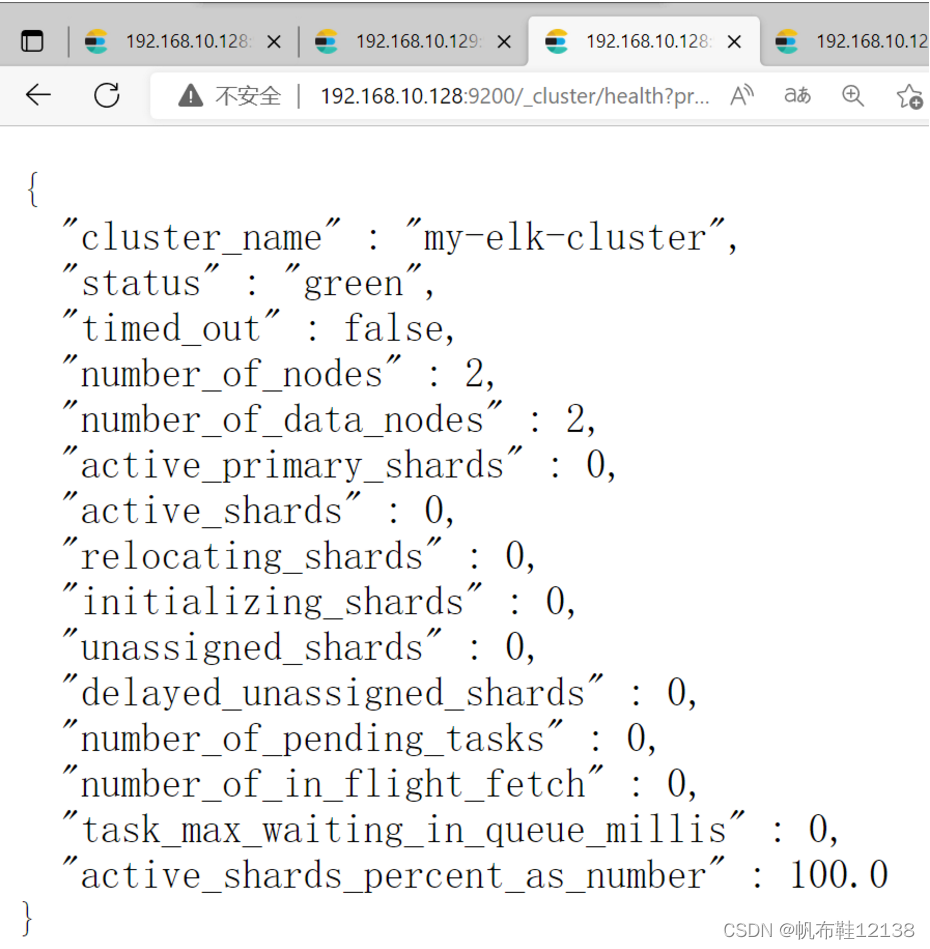
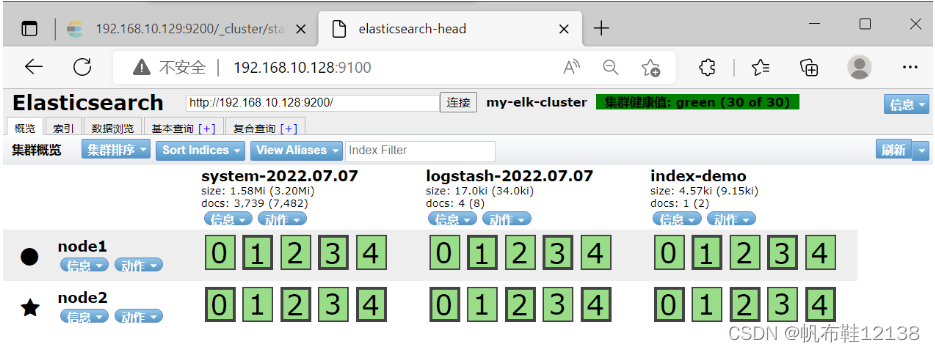
8)查看集群健康和状态 1)打开浏览器,输入地址:http://192.168.10.128:9200/_cluster/health?pretty ,查看集群健康状态,status值为green(绿色),表示节点健康运行。 2)打开浏览器,输入地址:http://192.168.10.128:9200/_cat/health? 查看集群健康状态; node.total :节点数,这⾥是2,表示该集群有2个节点。 node.data :数据节点数,存储数据的节点数,这⾥是2。 shards :表示我们把数据分成多少块存储。 pri :主分⽚数,primary shards active_shards_percent :激活的分⽚百分⽐,这⾥可以理解为加载的数据分⽚数,只有加载所有的分⽚数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个⻚⾯,我们会发 现这个百分⽐会不断加⼤,一直到100%。 绿色,最健康的状态,表示集群一切正常; 黄色,表示集群不可靠但可用;部分分片故障 红色,表示集群不可用,有故障 灰色,未连接到elasticsearch服务; { "cluster_name": "my-elk-cluster", "status": "green", "timed_out": false, "number_of_nodes": 2, "number_of_data_nodes": 2, "active_primary_shards": 15, "active_shards": 30, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0, "delayed_unassigned_shards": 0, "number_of_pending_tasks": 0, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 0, "active_shards_percent_as_number": 100.0 }
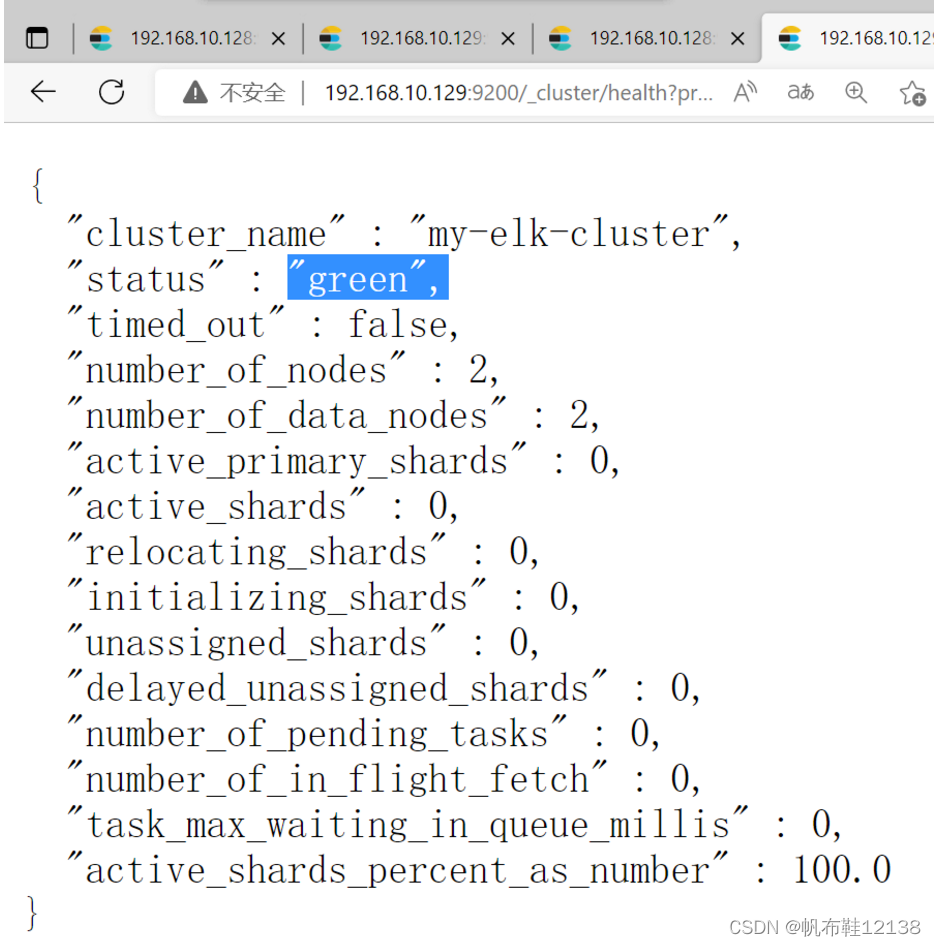
同理,打开浏览器,输入地址:http://192.168.10.129:9200/_cluster/health?pretty ,查看集群健康状态,status值为green(绿色),表示节点健康运行。 { "cluster_name": "my-elk-cluster", "status": "green", "timed_out": false, "number_of_nodes": 2, "number_of_data_nodes": 2, "active_primary_shards": 15, "active_shards": 30, "relocating_shards": 0, "initializing_shards": 0, "unassigned_shards": 0, "delayed_unassigned_shards": 0, "number_of_pending_tasks": 0, "number_of_in_flight_fetch": 0, "task_max_waiting_in_queue_millis": 0, "active_shards_percent_as_number": 100.0 }
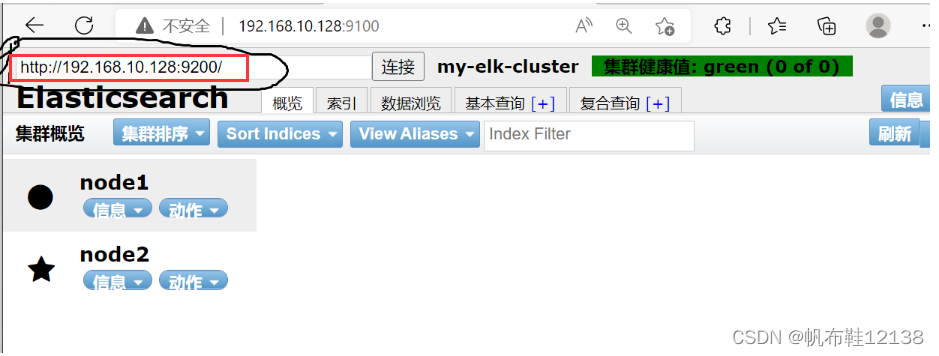
打开浏览器,输入地址:http://192.168.10.129:9200/_cluster/state?pretty,检查群集状态信息 Elasticsearch-head 插件,是集群管理工具、数据可视化、可以对数据增删改查,可以更方便 地管理群集。 三、部署Elasticsearch-head插件(node1节点) Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需 要 npm 命令。安装 Elasticsearch-head 需要提前安装 node 和 phantomjs。其中,前者是一 个基于 Chrome V8 引擎的 JavaScript 运行环境,而 phantomjs 是一个基于 webkit 的 JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可 以做到。 1)部署node软件编译安装 node 耗时较长,大约 10min,根据机器的配置可能略有不同 [root@node1 ~]# yum install gcc gcc-c++ make -y [root@node1 ~]# tar xzvf node-v8.2.1.tar.gz -C /usr/src/ [root@node1 ~]# cd /usr/src/node-v8.2.1/ [root@node1 node-v8.2.1]# ./configure [root@node1 node-v8.2.1]# make -j4 ##开启4个线程,加快编译 [root@node1 node-v8.2.1]# make install [root@node1 node-v8.2.1]# cd 2)部署phantomjs软件 [root@node1 ~]# tar xjvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/src/ [root@node1 ~]# cd /usr/src/phantomjs-2.1.1-linux-x86_64/bin [root@node1 bin]# cp phantomjs /usr/local/bin [root@node1 bin]# cd 3)安装elasticsearch-head软件 #数据可视化工具 [root@node1 ~]# tar xzvf elasticsearch-head.tar.gz -C /usr/src/ [root@node1 ~]# cd /usr/src/elasticsearch-head/ [root@node1 elasticsearch-head]# npm install #安装依赖包 [root@node1 elasticsearch-head]# cd 4)修改配置文件(node1和node2) [root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml #末尾添加# http.cors.enabled: true ##开启跨域访问支持,默认为false http.cors.allow-origin: “*” ## 跨域访问允许的域名地址 5)重启Elasticsearch服务(node1和node2)[root@node1 ~]# systemctl restart elasticsearch 6)启动elasticsearch-head[root@node1 ~]# cd /usr/src/elasticsearch-head/ #必须在解压目录下启动服务 [root@node1 elasticsearch-head]# npm run start & #后台运行,否则服务启动失败 7)查看es和es-head服务端口[root@node1 ~]# netstat -lnupt |grep 9100 [root@node1 ~]# netstat -lnupt |grep 9200 8)通过 Elasticsearch-head查看 Elasticsearch信息打开浏览器,输入地址 http://192.168.10.128:9100, 可以看见群集很健康,颜色是绿色(green)。 若看不到群集健康状态,在Elasticsearch 后面的栏目中输入 http://192.168.10.128:9200;
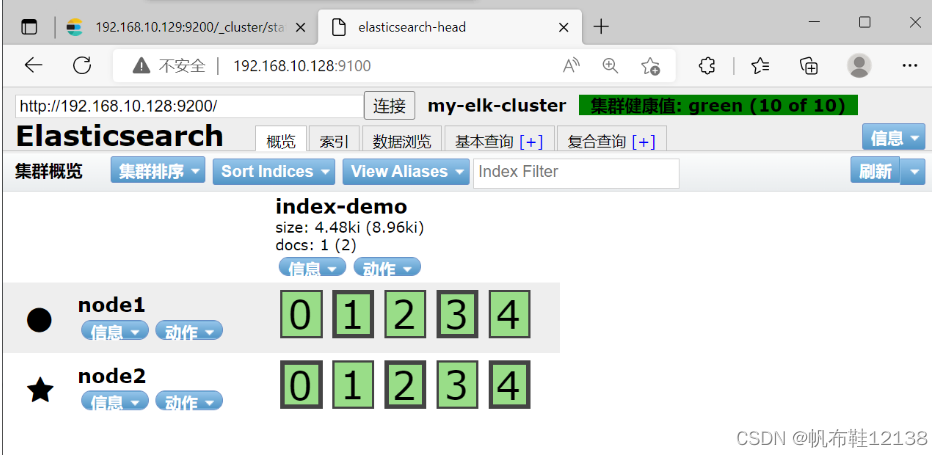
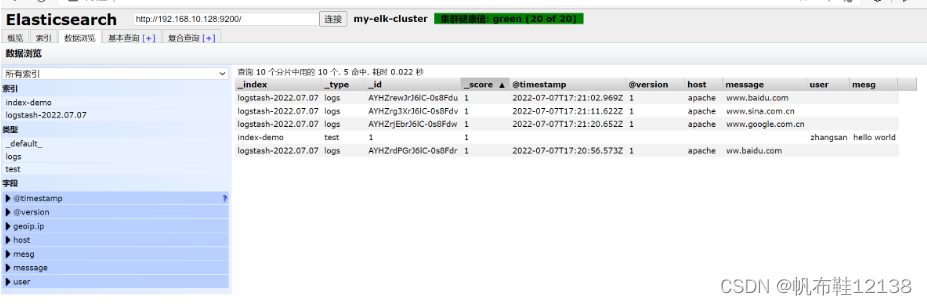
9)插入一条测试索引(node1) [root@node1 ~]# curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}' //输出结果如下: { "_index" : "index-demo", "_type" : "test", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "created" : true } 10)刷新浏览器,可以看到成功创建的索引下图可以看见索引默认被分片5个,并且有一个副本,点击数据浏览,会发现在node1上创建的索引为index-demo,类型为test等相关信息;
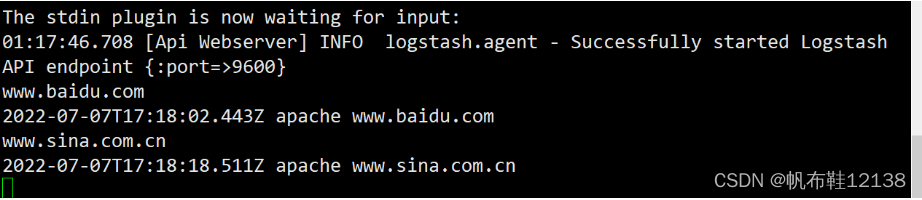
四、部署logstash(apache节点) Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。在正式部署之前, 先在 Node1 上部署 Logstash,以熟悉 Logstash 的使用方法。Logstash 也需要 Java 环境, 所以安装之前也要检查当前机器的 Java 环境是否存在。 按下面的步骤完成 Logstash 的安装和使用。 1)安装Apahce服务 [root@apache ~]# yum -y install httpd [root@apache ~]# systemctl start httpd [root@apache ~]# systemctl enable httpd 2)安装Java环境[root@apache ~]# java -version 3)安装logstash [root@apache ~]# rpm -ivh logstash-5.5.1.rpm [root@apache ~]# systemctl start logstash [root@apache ~]# systemctl enable logstash [root@apache ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ #建立软链接 4)测试logstashLogstash 命令行中常用的命令选项: -f:通过这个选项可以指定 Logstash 的配置文件, 根据配置文件配置 Logstash。 -e: 后面跟着字符串, 该字符串可以被当作 Logstash 的配置(如果是“”,则默认使用 stdin 作为输入,stdout 作为输出)。 -t:测试配置文件是否正确, 然后退出。 Logstash 命令的使用方法如下所示 采用标准输入,标准输出 [root@apache ~]# logstash -e 'input { stdin{} } output { stdout{} }' ...................................................... 10:08:54.060 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started 2018-10-12T02:08:54.116Z apache 10:08:54.164 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600} www.baidu.com ####标准输入www.baidu.com 2018-10-12T02:10:11.313Z apache www.baidu.com ##标准输出 www.sina.com.cn ####标准输入www.sina.com.cn 2018-10-12T02:10:29.778Z apache www.sina.com.cn ##标准输出 //执行 ctrl+c 退出
使用rubydebug显示详细输出,codec为一种编解码器 [root@apache ~]# logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }' ...................................................... 10:15:07.804 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600} www.baidu.com ###标准输入www.baidu.com { “@timestamp” => 2018-10-12T02:15:39.136Z, “@version” => “1”, “host” => “apache”, “message” => “www.baidu.com” } //执行 ctrl+c 退出
5)使用logstash将信息写入elasticsearch中 [root@apache ~]# logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.10.128:9200"] } }' .................................................... The stdin plugin is now waiting for input: 10:40:06.558 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600} www.baidu.com ###输入内容 www.sina.com.cn ###输入内容 www.google.com.cn ###输入内容//结果不在屏幕输出显示,而是发送至 Elasticsearch 中。
6)查看新增加的索引 打开浏览器,输入地址:http://192.168.10.128:9100 ###查看新增加的索引信息
查看索引对应的内容
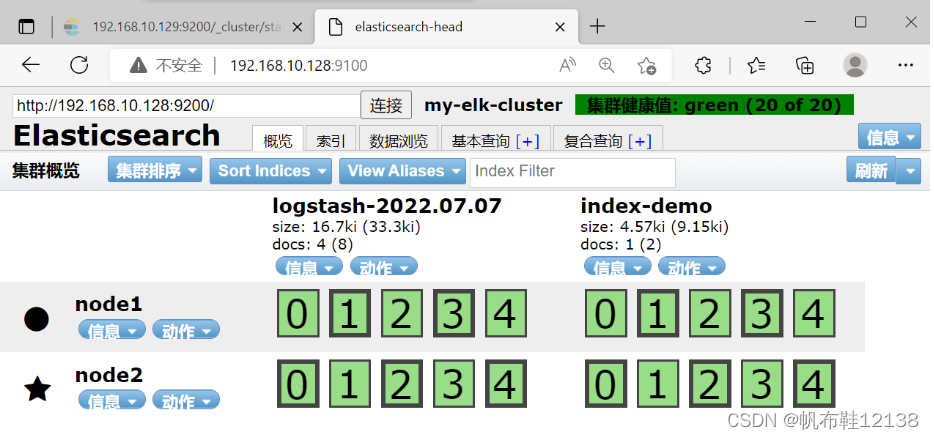
7)使用logstash收集apache节点系统日志 Logstash 配置文件基本由三部分组成:input、output 以及 filter(根据需要)。因此标 准的配置文件格式如下所示。 [root@apache ~]# chmod o+r /var/log/messages ###让Logstash可以读取日志 [root@apache ~]# ll /var/log/messages [root@apache ~]# vim /etc/logstash/conf.d/system.conf ###创建logstash配置文件 input { file{ path => "/var/log/messages" type => "system" start_position => "beginning" } } output { elasticsearch { hosts => ["192.168.10.128:9200"] index => "system-%{+YYYY.MM.dd}" } } 8)重启logstash服务[root@apache ~]# systemctl restart logstash 9)查看索引信息打开浏览器,输入地址:http://192.168.10.128:9100 ###查看索引信息 //多出system-2022.07.07
查看索引下的日志信息
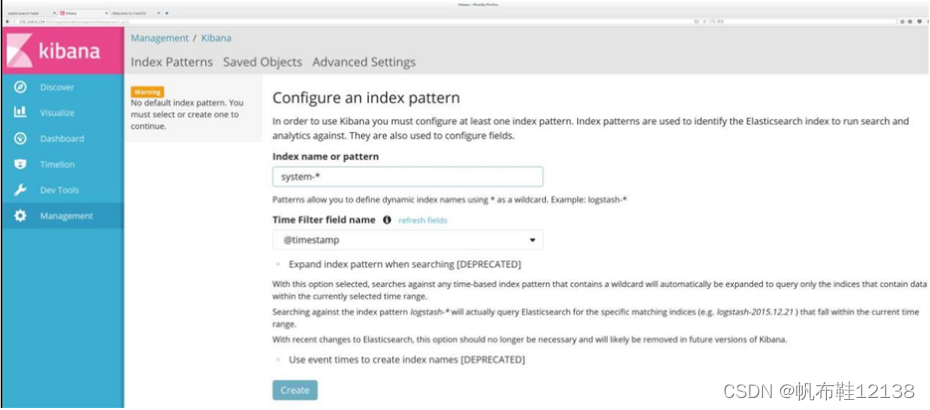
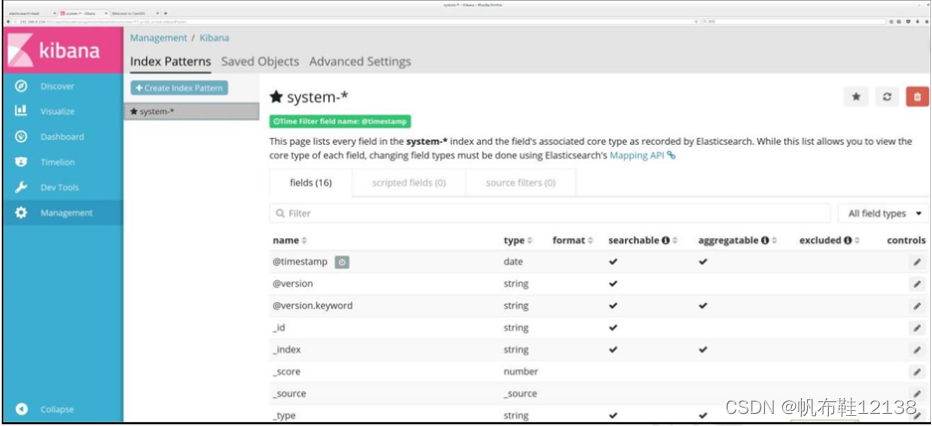
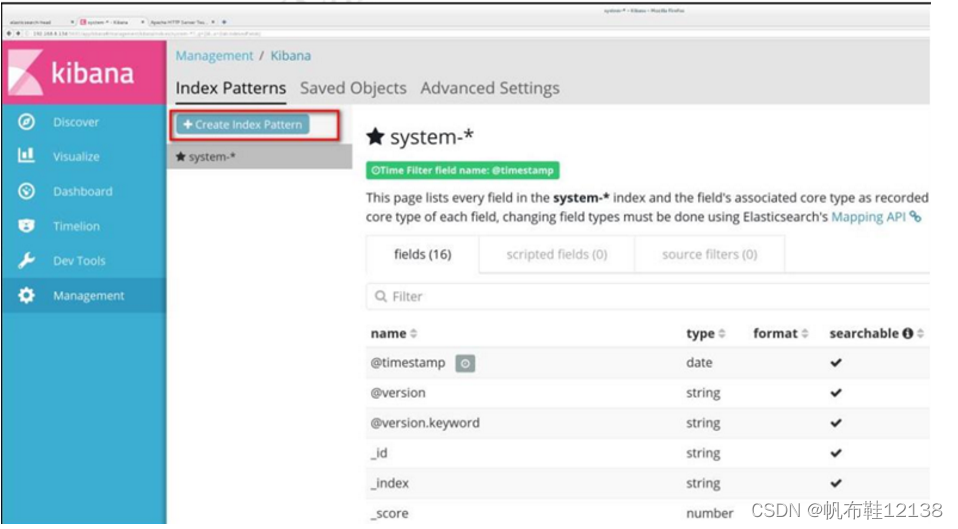
五、部署kibana服务(node1节点) 1)安装kibana 1)在 node1 服务器上安装 Kibana,并设置开机启动。 [root@node1 ~]# rpm -ivh kibana-5.5.1-x86_64.rpm [root@node1 ~]# cd /etc/kibana/ [root@node1 kibana]# cp kibana.yml kibana.yml.bak 2)修改配置文件 设置 Kibana 的主配置文件/etc/kibana/kibana.yml。 在主配置文件/etc/kibana/kibana.yml 中设置 Kibana 的命令如下: [root@node1 ~]# vim /etc/kibana/kibana.yml 2/ server.port: 5601 ####kibana打开的端口 7/ server.host: "0.0.0.0" ####kibana侦听的地址 21/ elasticsearch.url: "http://192.168.10.128:9200" ####和elasticsearch建立联系 30/ kibana.index: ".kibana" ####在elasticsearch中添加.kibana索引注:前面数字为行号 3)启动kibana服务[root@node1 ~]# systemctl start kibana [root@node1 ~]# systemctl enable kibana 4)查看kibana打开浏览器,输入地址:192.168.10.128:5601 第一次登录,需要一个索引名字:system-* ##对接系统日志文件 然后点最下面的出面的create 按钮创建 然后点最左上角的Discover按钮 会发现system-*信息 然后点下面的host旁边的add 会发现右面的图只有 Time 和host 选项了 这个比较友好。
查看索引的默认字段
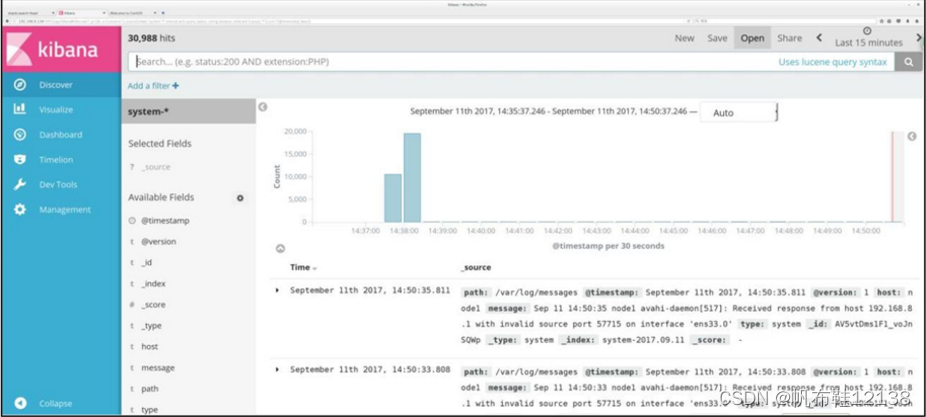
单击“Discover”按钮查看图表信息及日志信息,
数据展示可以分类显示
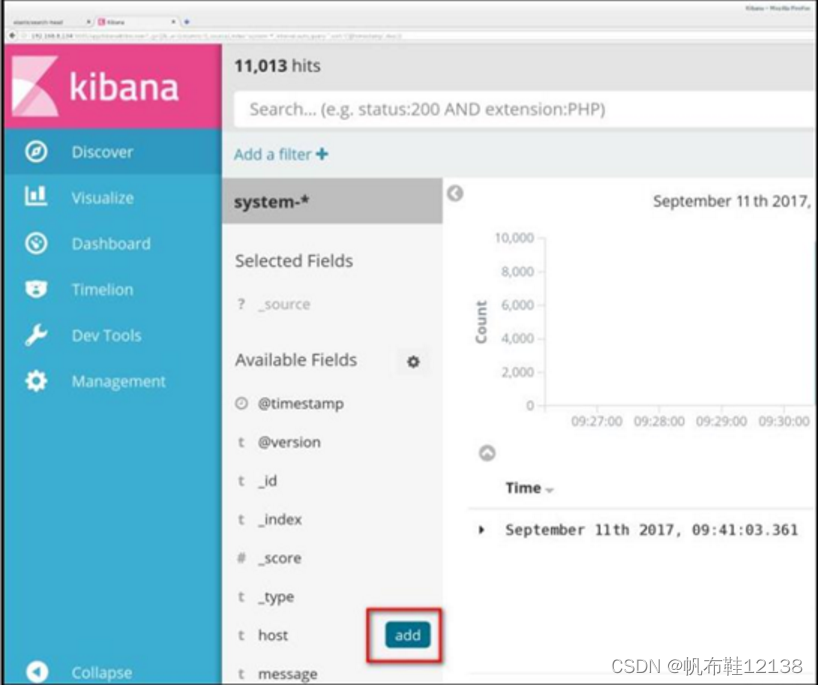
使鼠标指针悬停在“Available Fields”中的“host”, 然后单击 “add”按钮,可以看到按照“host”筛选后的结果,
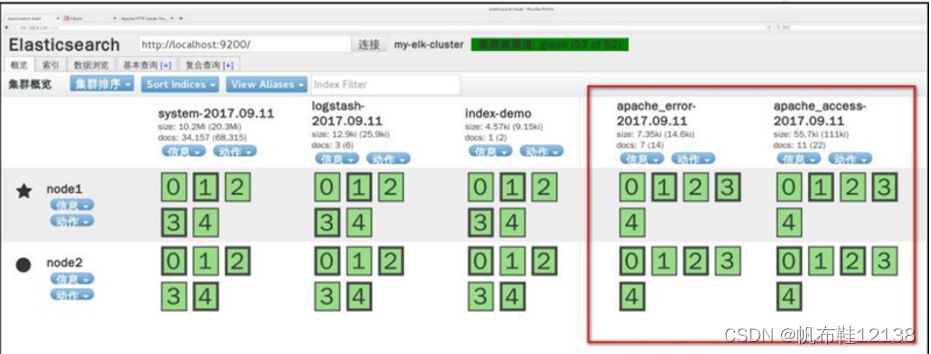
六、收集Apache 日志文件(apache节点) 1)新建logstash配置文件 [root@apache ~]# cd /etc/logstash/conf.d/ [root@apache conf.d]# vim apache_log.conf input { file{ path => "/var/log/httpd/access_log" type => "access" start_position => "beginning" } file{ path => "/var/log/httpd/error_log" type => "error" start_position => "beginning" } } output { if [type] == "access" { elasticsearch{ hosts => ["192.168.10.128:9200"] index => "apache_access-%{+YYYY.MM.dd}" } } if [type] == "error" { elasticsearch{ hosts => ["192.168.10.128:9200"] index => "apache_error-%{+YYYY.MM.dd}" } } }input { file{ path => "/etc/httpd/logs/access_log" //收集apache访问日志 type => "access" //日志类型为access start_position => "beginning" //从此处开始收集 } file{ path => "/etc/httpd/logs/error_log" //收集apache错误日志 type => "error" / /日志类型为error start_position => "beginning" //从此处开始收集 } } output { if [type] == "access" { //若日志类型为access,则输出到es中 elasticsearch { hosts => ["192.168.10.128:9200"] index => "apache_access-%{+YYYY.MM.dd}" //指定索引格式 } } if [type] == "error" { //若日志类型为error,则输出到es中 elasticsearch { hosts => ["192.168.10.128:9200"] index => "apache_error-%{+YYYY.MM.dd}" //指定索引格式 } } [root@apache conf.d]# logstash -f apache_log.conf //收集日志 input { file{ path => "/var/log/messages" type => "system" start_position => "beginning" } } output { elasticsearch{ hosts => ["192.168.10.128:9200"] index => "system-%{+YYYY.MM.dd}" } } 2)查看索引信息打开浏览器 输入http://192.168.10.128:9100,查看新增的索引信息; //能发现apache_access-2022.07.07 和apache_error-2022.07.07
3)kibana查看apache日志 打开浏览器 输入http://192.168.10.128:5601,新增apache索引; 点击左下角management选项—index patterns—create index pattern ----分别创建apache_error-* 和 apache_access-* 的索引;
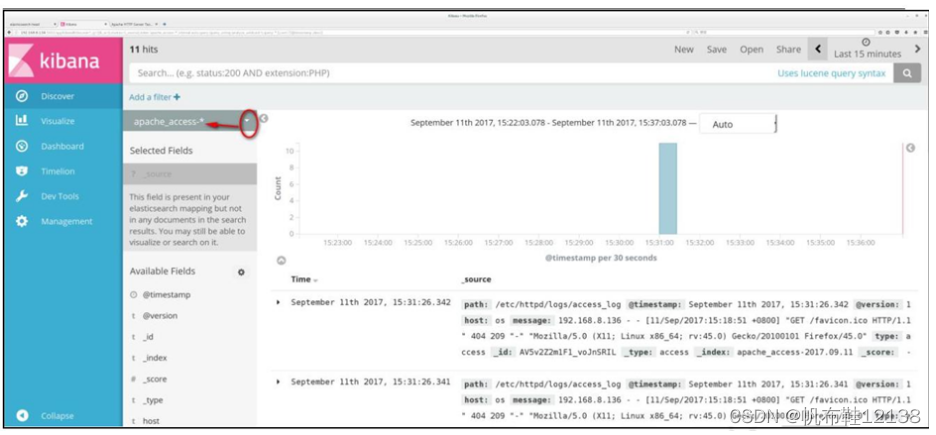
最后找到左侧 Discover选项,在中间下拉列表选择刚添加的“apache_access_*”索引,可以看到相应的图表和日志信息; 同理,在中间下拉列表选择刚添加的“apache_error_*”索引,可以看到相应的图表和日志信息;
|





【本文地址】
今日新闻 |
推荐新闻 |