|
目录
网络模型及网络结构
网络结构详情
代码的整体目录
代码detect.py测试
各个模块
整体结构
其他资料
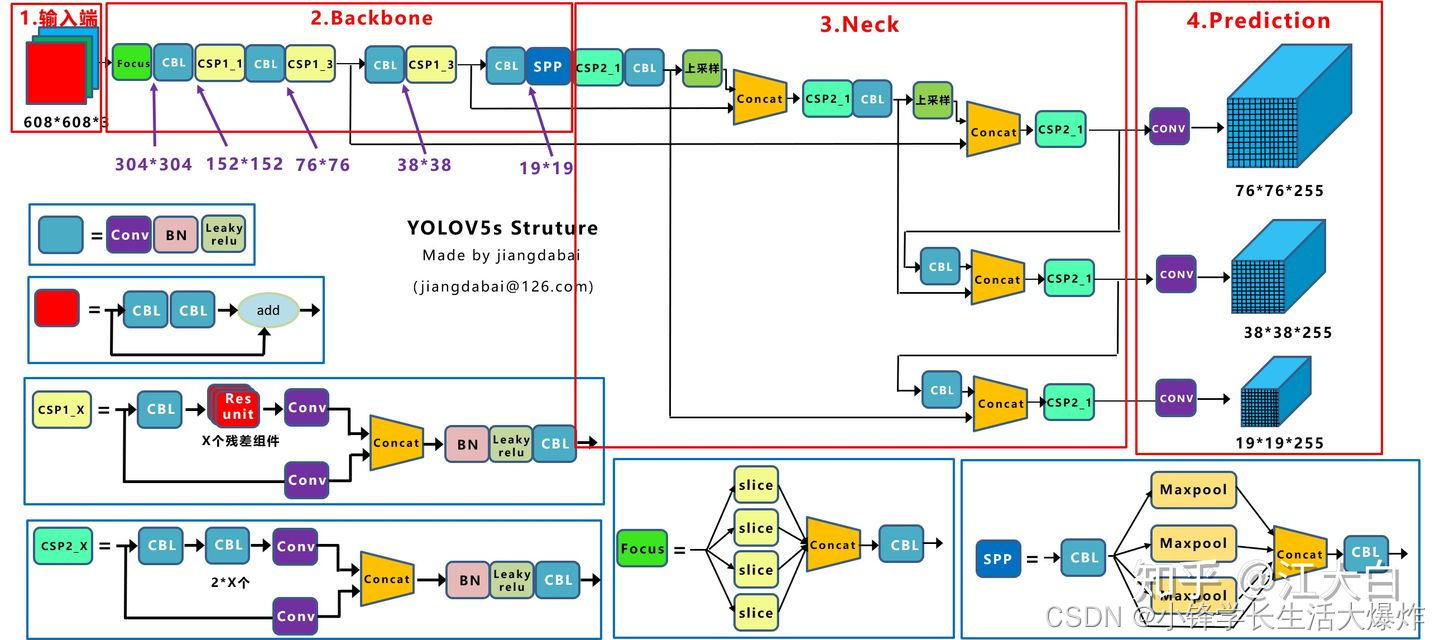
4种网络的宽度
yolov5各个网络模型性能比较
yolov5结构
yolov5四种网络的深度
yolov5网络结构图
一些工具代码
voc2yolo.py
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。YOLOv5融合了数千小时研发过程中学到的经验教训和最佳实践。
官方文档:Quick Start - YOLOv5 Documentation (ultralytics.com)
代码仓库:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
另外,腾讯云的这款云GPU用于模型训练还不错,1元/天,详情可见:云产品特惠专区
这里还可以领云产品免费试用;需要选购的进:轻量应用服务器专场;不清楚怎么操作的可以看教程:腾讯云产品免费试用教程
网络模型及网络结构
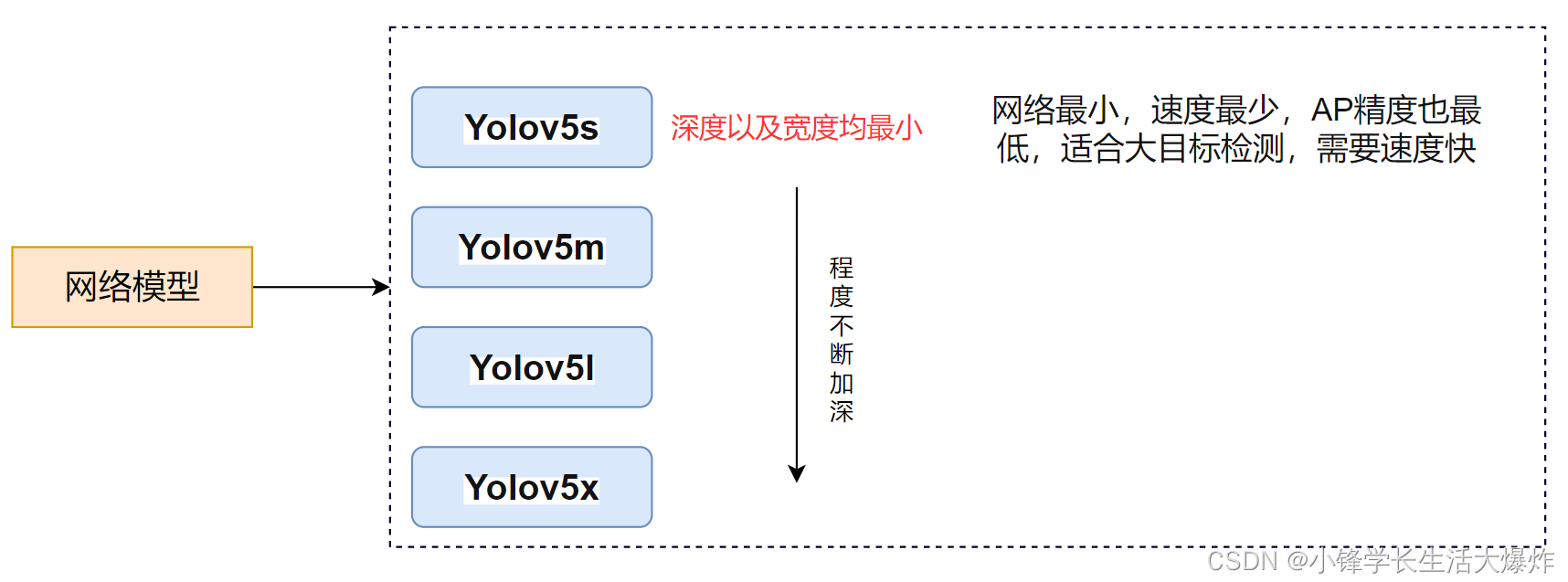

网络结构详情


代码的整体目录

代码detect.py测试

各个模块
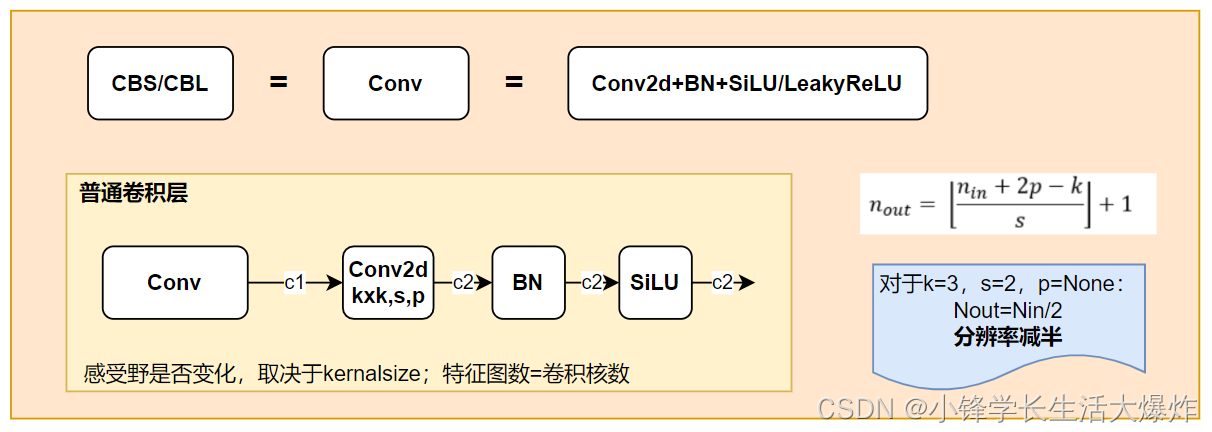
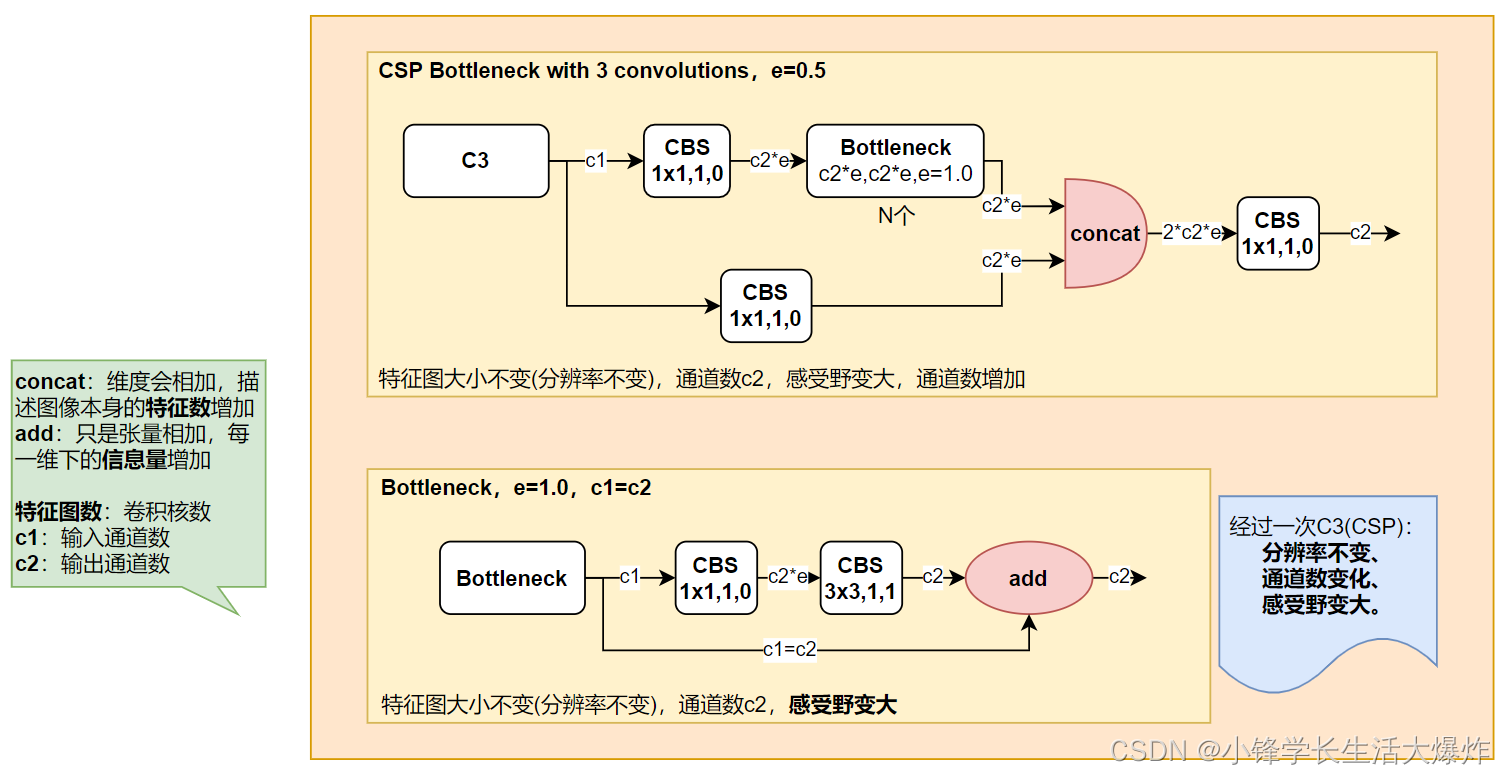

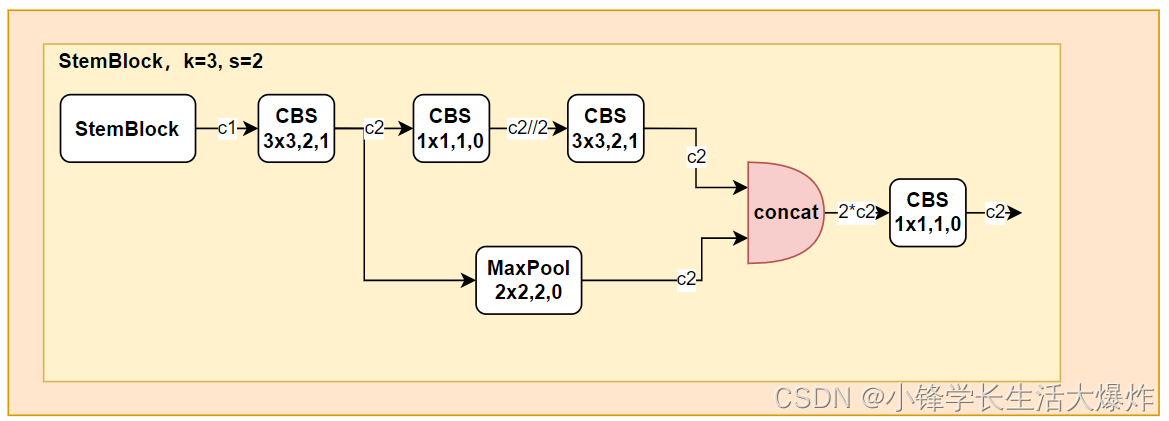
整体结构
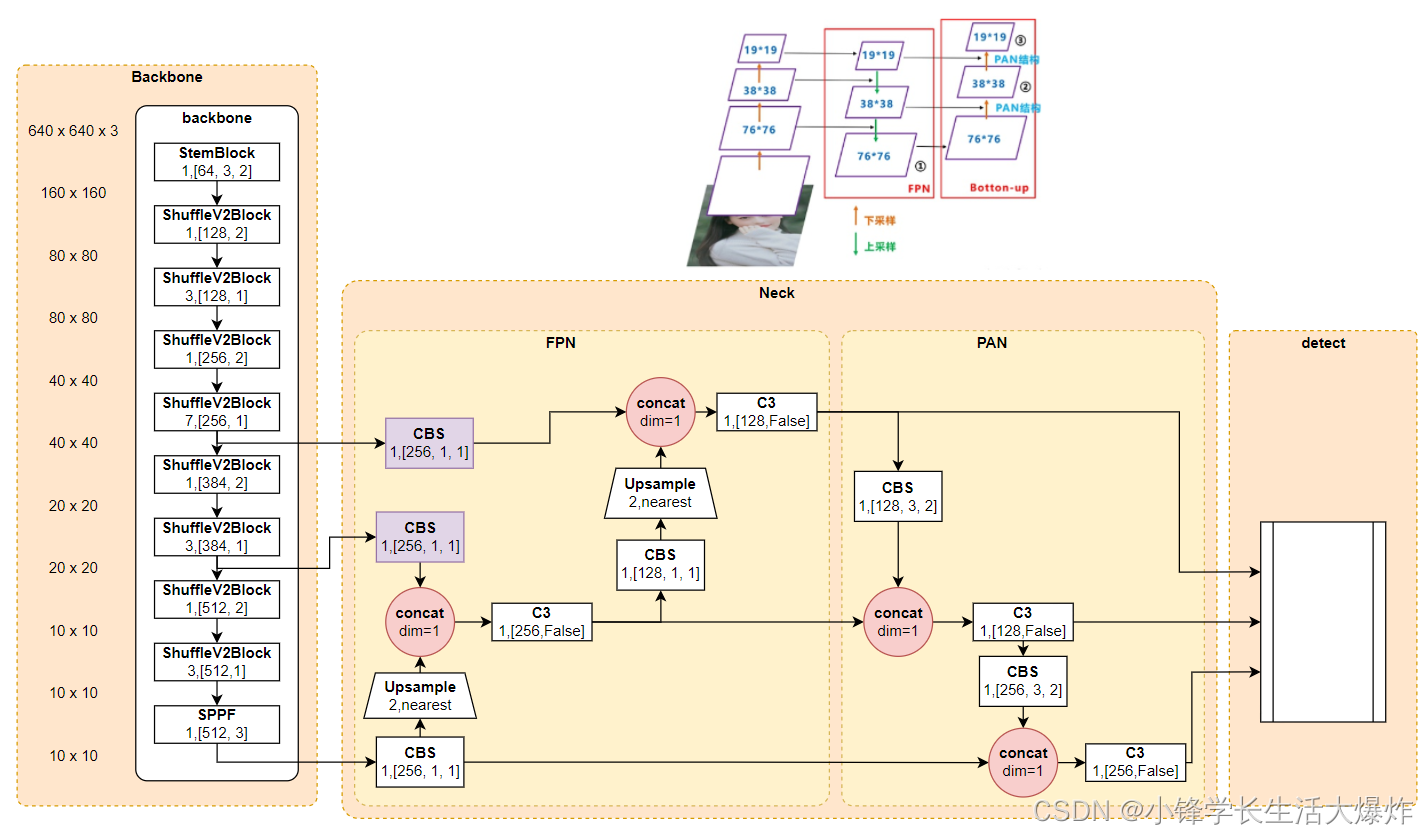
其他资料
来着江大白(官方一直在更新,图不一定准)和yolov5官方
4种网络的宽度

yolov5各个网络模型性能比较
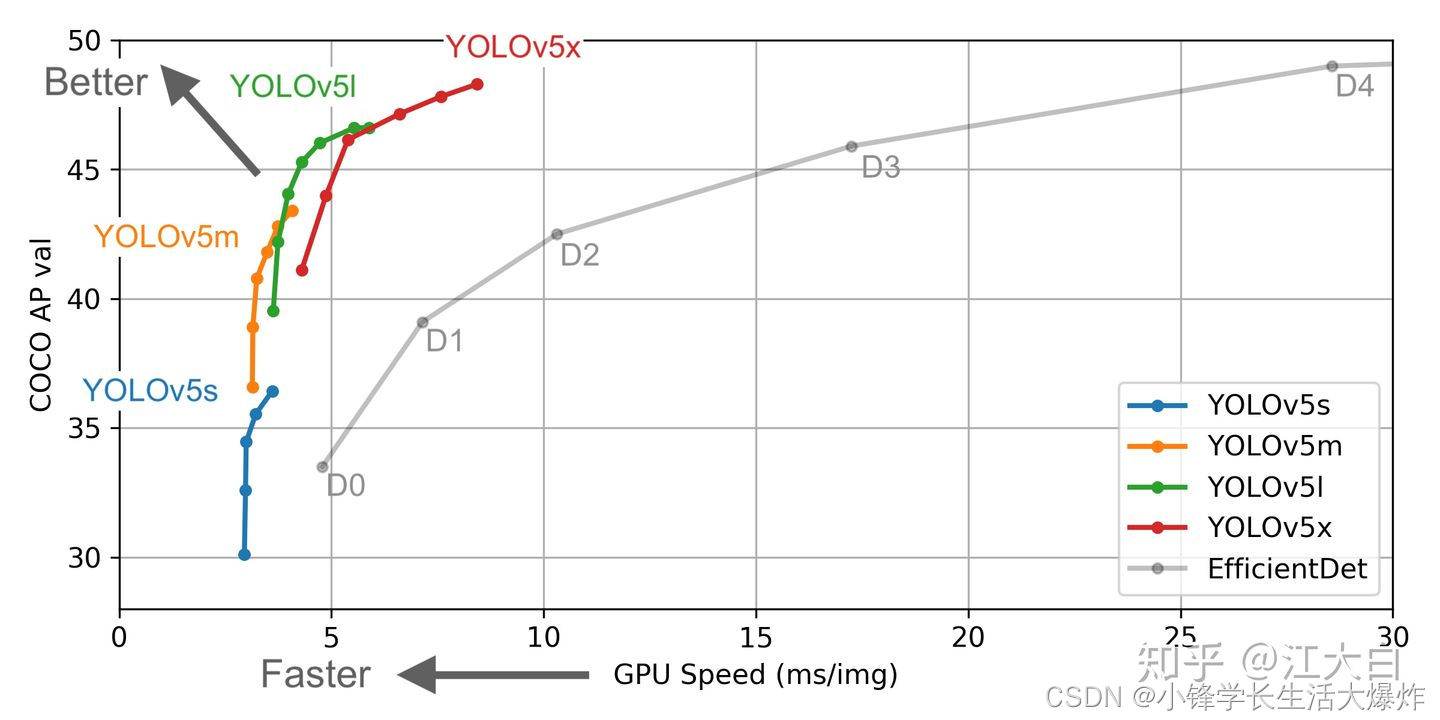
yolov5结构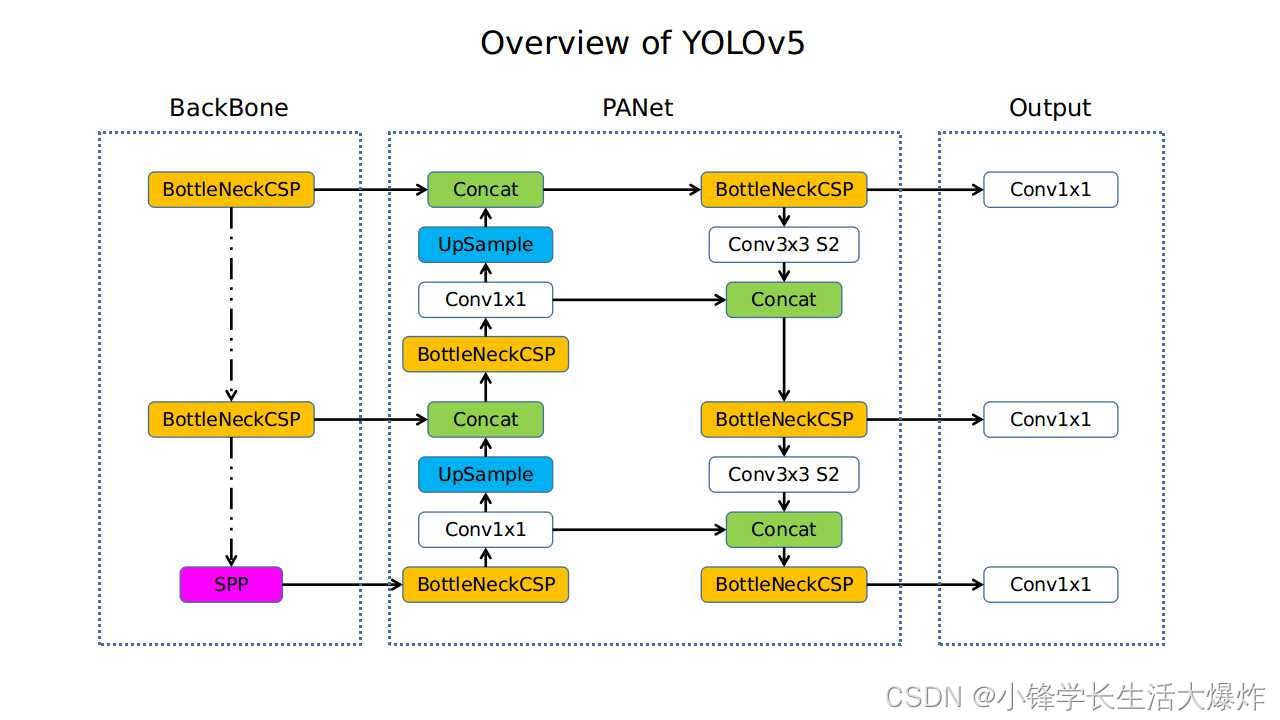 yolov5四种网络的深度
yolov5四种网络的深度
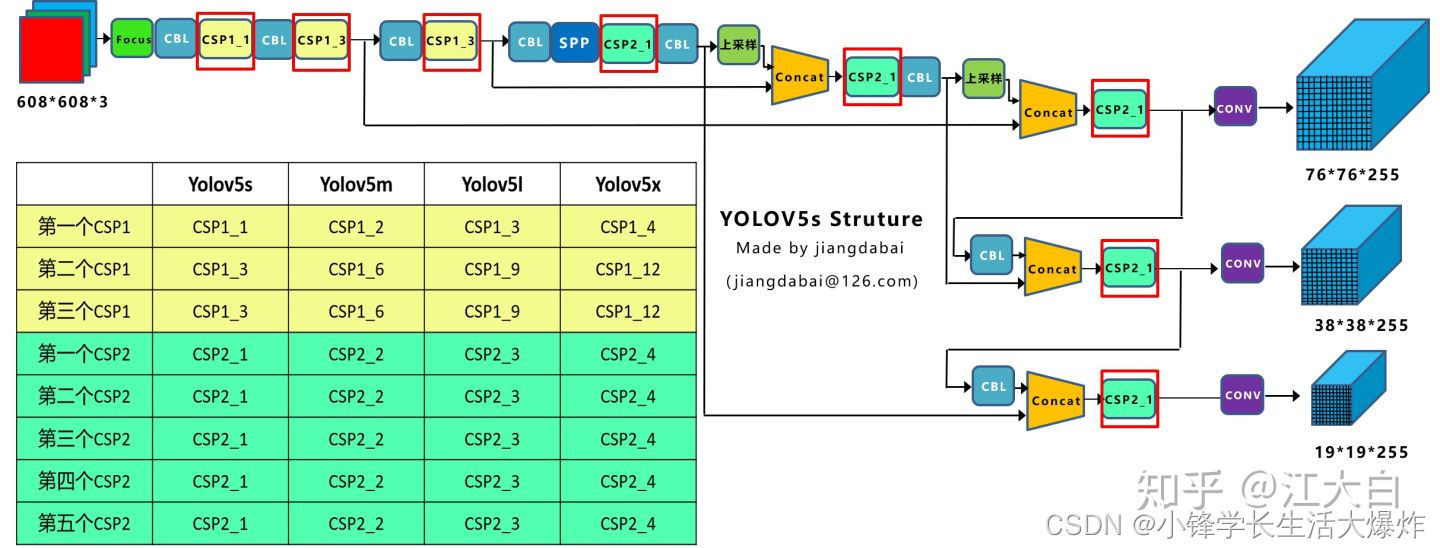
yolov5网络结构图
一些工具代码
voc2yolo.py
from os import getcwd
import glob
classes = ["face", "face_mask"]
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_name):
in_file = './val/xmls/' + image_name[:-3] + 'xml' # xml文件路径
out_file = open('./val/labels/' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
with open(in_file) as f:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
tree = ET.parse(f) #
root = tree.getroot() # 获取根节点
#
# xml_text = f.read()
# root = ET.fromstring(xml_text)
size = root.find('size')
if size is not None:
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
# print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
if w != 0 and h != 0:
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./val/images/*.jpg"): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径
image_name = image_path.split('\\')[-1]
convert_annotation(image_name)
|