大数据分析 |
您所在的位置:网站首页 › 电影票房信息 › 大数据分析 |
大数据分析
|
一 概要
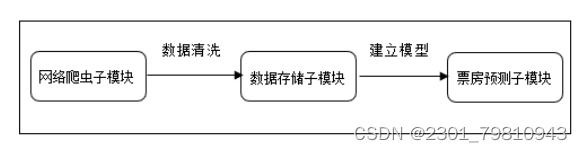
近些年来,随着电影行业变得越来越热门,也为影院带来不小的票房收入。传统的影院都是依靠个人经验进行排片,但是由于影片的票房收入可能受多种因素的影响,排片多的电影最后的票房会远低于预期值,导致影院因安排失误而导致大量的票房损失。 基于此背景下,众多的影院希望有一个票房预测系统能够预测电影的票房,为影院的排片进行指导,所以本文在了解了国内外研究现状后,在python语言的基础上,通过爬虫技术爬取中国电影网的各历史票房数据,利用多项式曲线拟合算法作为票房预测算法,实现了可对电影票房进行预测的python系统。 通过应用本系统,能够为国内的影院提供点映过一段时间的电影的预测票房,为影院排片提供有一定影响的参考依据,减少因人为因素对电影排片而导致票房损失的事情发生。同时本系统能够进行票房数据预处理以及模型训练等功能,因为目前电影的票房是用户选择观看电影的重要指标,所以系统还能够及时的变更票房的实时数据和预测数据,具有非常好的应用前景和使用价值。 关键词:多项式曲线拟合;电影票房预测;爬虫;python 二、基于MAAP评级的电影票房预测模型在二十世纪八十年代,电影票房的研究也进入到了第二阶段,第二阶段的研究在第一阶段的前提下转变为发现更多的影响电影票房的因素。代表第二阶段研究的开始有很多,斯格特.苏凯提出的预测模型是真正的能够代表研究开始的标志。此预测模型基于第一阶段票房预测,增加了两个因素分别是是否获得奥斯卡奖项和MAAP评级,而建模方法上也有改变,主要是用回归分析的这一模型来构造电影票房的影响因子与收入之间的联系。 乔治盖洛普的模型被斯格特苏凯进行了改进,但是票房数据的获取并不是一件容易的事,所以苏凯找到了代替电影票房数据的方法——电影租金变量,苏凯的模型预测的范围更广,例如电影租金、电影的持续放映时间也称为放映周数。苏凯在选取电影票房影响因子上设置了22个影响因子,把市场集中度列入了影响因子之一是最重要的改变。我们一般把不同放映时期的市场竞争度称为市场集中度,它的计算公式是:市场集中度=上映时期排名前四或排名前十电影的一周票房/本周所有电影总票房,当最后得到的数值越大时,市场集中度相应的越高也就意味着本周内上映的电影市场竞争力越大。回归方程对观测值的拟合程度我们称为拟合优度,其中判定系数R2是度量拟合优度的统计量的依据,它是回归平方和与总偏差平方和之间的比值,当判定系数越大时,则离平方和中能够由回归平方和解释的比例就越大,对模型的预测相应的就越精确,回归效果就更好。从数值方面当R2大于0小于等于1时,回归拟合的效果就越好,模型的拟合优度R2大于0.8时属于拟合度较好。 三、 基于python的电影票房预测算法设计 (一)数据来源 本文主要使用了电影基本和电影票房两个数据,数据均来源于中国票房网,主要包括电影基本信息,电影发行时间以及历史票房数据,从表3-1中可以直观看到具体数据所示: 表3-1 初始数据表 通过对斯格特苏凯的基于MAAP评级的电影票房预测模型学习,本文提出算法:对历史票房数据进行多项式曲线拟合,建立一个票房走势的“模型”,再把现有的票房套进模型里做计算。 多项式函数拟合是把给定数据是由M次多项式函数生成的作为一个假设,M次多项式函数并不是都会产生给定数据,这需要我们进行选择,应当选择的是一个不管是对已知数据还是未知数据都有较好预测能力的函数。 最小二乘法是在数学上命名为曲线拟合,它寻找数据的最佳函数匹配是运用最小化误差的平方和,最小二乘法的优点是对于求出未知数据更加的方便,而且这些求得的数据与实际数据之间误差的平方和是最小的。最小二乘法对于曲线拟合的具体原理如下: 假设训练数据集是: 是属于输入x的观测值,而则是相应的输出y的观测值,其中i=1,2,⋯,N 设M次的多项式是 其中,x是单变量的输入,是M+1个参数。 当损失函数(即最小二乘法)是平方函数时,系数的意义是为了使计算更加简便,把模型与训练数据代入可以得到: 对wj求偏导并令其为0 以上公式最后一步存在一处错误:等式左边x指数为(j+k) 必须对多项式系数进行拟合,解线性方程组,得到下面的求和符号上下限都是i=1到N,为了直观所以直接省略书写步骤。 通过计算,得出: 把上面的值带入线性方程组求解即可得出答案。 将数据代入上述研究方程即为:将某一对比电影历史票房和预测票房电影的前期票房作为输入,通过图像显示处理,利用多项式曲线拟合与预测票房电影训练模型,最后预测出票房。具体代码如下: #多项式拟合 def draw_fit(data): x = np.array(range(len(data))) z = np.poly1d(np.polyfit(x, data, 10)) plt.plot(x, z(x), 'r-') return z plt.figure(figsize=(22, 12)) func_fits = [] for i in range(9): plt.subplot(3, 3, i+1) y = data[title[i]].dropna().tolist() x = [i for i in range(len(y))] plt.title(title[i], fontproperties=font) #图标题 plt.plot(x, y) #绘图 z = draw_fit(y) #绘制拟合曲线 func_fits.append(z) plt.show() 四、 硬件设计五、 电影票房预测系统实现 本章是对电影票房预测系统中的整体架构以及其部分关键模块的详细实现进行一个介绍,主要分为三个模块,网络爬虫子模块、数据存储子模块和电影票房预测子模块。该流程中特别注意的是,电影票房预测的最终功能模块是以多项式曲线拟合算法为基础实现。
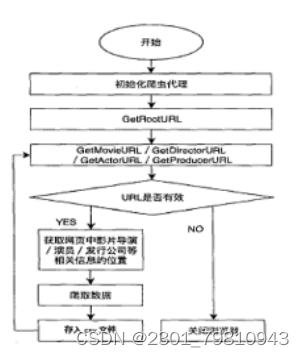
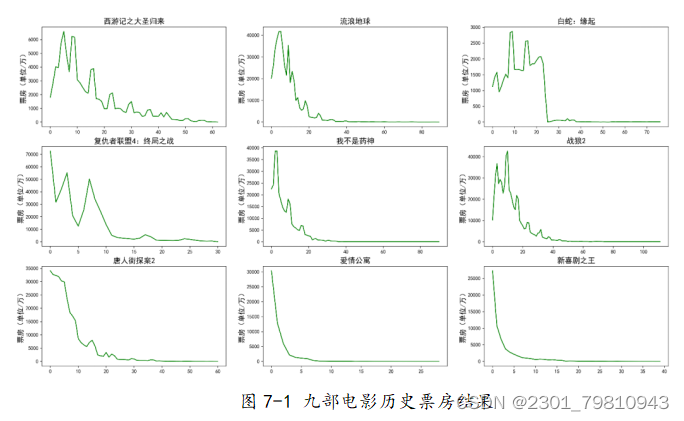
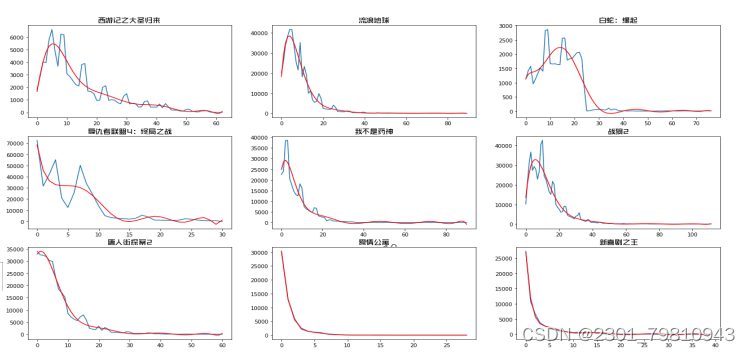
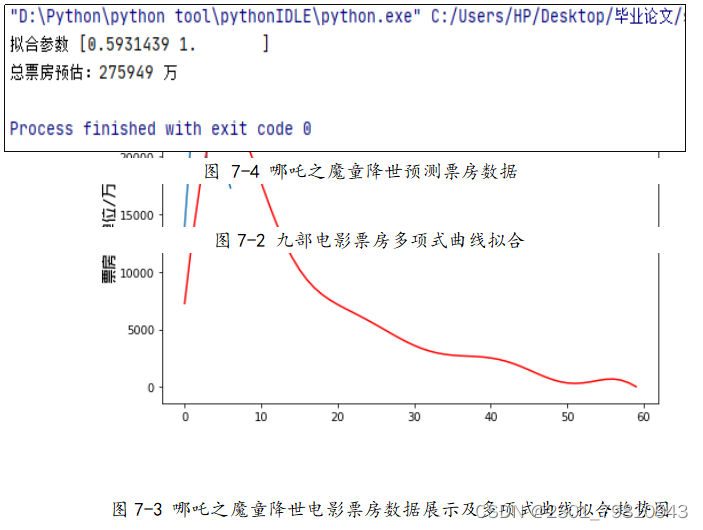
图6-1电影票房预测系统整体流程图 上图6-1展示了电影票房预测系统的整体流程图,上图给出的预测系统中有网络爬虫子模块、数据存储模块以及电影票房预测子模块。其中网络爬虫子模块主要完成对中国票房网爬取和预处理,由于数据可能重复或没有任何作用,为了使系统预测更加准确,于是必须要对数据预处理;数据存储子模块的作用是清理后的数据进行特殊处理,使数据可以成为预测模型的合理输入,存储的文件为csv文件;电影票房预测子模块是本文阐述以及研究的重要部分,该模块是运用多项式曲线拟合算法的基本框架,把数据存储子模块的输出作为输入,最后通过预先训练好的模型来输出票房的预测值。因为前面已经对票房预测模块进行了解释,因此下面只对网络爬虫和数据存储这两个功能模块的实现进行详细的介绍。 (二)网络爬虫子模块如图6-1: 图6-2网络爬虫子模块流程图 由6-2可以得到流程如下: (1)当系统初始化爬虫代理后可以操作浏览器令其模拟人类行为,得到目标网址的root,进入到本文的数据主要来源的中国电影网。其中虫代理设置包括浏览器支持的MIME类型(ACCEPT)、用户代理(USER_AGENT)两个部分,具体设置如下: def getMovieURL(url): headers = { ' Chrome/67.0.3396.62 Safari/537.36' try: r = requests.get(url, headers=headers) except requests.RequestException as e: print('error', e) def main(): uinfo = [] for i in range(11): urls = {"http://58921.com/daily/wangpiao?page= " + str(i)} for url in urls: html = getHTMLText(url) fillUnivList(uinfo, html) printHtml_csv(uinfo)(2)在ROOT_URL页面中循环的按页根据展示位置来获取所有的movieURL存入到MovieUrlList栈中,接下来使用GetMovieUrl函数令桟顶元素取出,判断它的有效性,当无效时栈为空,爬取结束,跳转到第4步…;当有效时,直接进入某电影的页面,如下获取特定电影展示页面中影片名与历史票房的信息,存储在数据结构ulist.append([tds[1].string,tds[6].string])中,从而定位到需要爬取的数据。 def MovieUrlList (ulist, printHtml_csv(ulist): with open('data.csv', 'w', encoding='utf-8-sig', newline='') as csvfile: fieldnames = ['电影名称','票房'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for i in ulist: writer.writerow( {'电影名称': i[0], '票房': re.findall('/^\d*(.)?\d+$/', i[1])}) (三)数据存储子模块通过Python中Pandas库中的DataFrame函数设置列名columns与行名index,分别用于存储电影名与历年票房,然后转置并存储为csv文件作为预测模型的输入。 数据储存 edf = pd.DataFrame.from_dict(mo, orient='index') edf = edf.T # 转置 edf.to_csv(os.path.abspath('.') + r'/boxoffice.csv', sep=',', encoding='utf_8_sig', index=False) # 保存到 csv (四)预测结果展示 本次预测的电影为哪吒之魔童降世,建立的模型采用大圣归来等9部电影,并最终选取大圣归来作为预测结果拟合值。 1.电影历史票房结果展示 测试过程中,通过爬虫技术获得电影数据票房信息并经过数据清洗后,保存为csv文件,并且如图7-1所示通过matplotlib库的plt函数对csv文件中的九部电影票房数据进行可视化展示,其中横轴表示时间,纵轴为票房,图表中绿色的曲线表示的就是票房数据的变化趋势。 2.电影票房多项式曲线拟合结果展示 获得票房数据后,通过numpy库中的polyfit方法对数据进行多项式曲线拟合,如图7-2所示7-2所示,蓝线为电影历史票房趋势图,红线为多项式曲线拟合后的模型变化趋势。 3.电影预测票房结果展示 如图7-3和7-4所示,蓝线表示前10天哪吒之魔童降世电影票房的数据展示趋势,红线为西游记之大圣归来的多项式曲线拟合趋势图,并得到该趋势的拟合参数为0.5931,将哪吒之魔童降世的数据代入此模型计算,最终预测出总票房为275949万元。
目 录 一、绪论 1 (一)研究背景 1 (二)国内外研究现状 1 二、相关技术 1 (一)电影票房预测的相关方法 2 1.基于人口统计学的研究方法 2 2.基于MAAP评级的电影票房预测模型 2 (二)网络爬虫介绍 3 1.网络爬虫概述 3 2.页面爬取 3 3.页面存储 4 三、基于python的电影票房预测算法设计 4 (一)数据来源 4 (二)票房预测算法——多项式曲线拟合 4 四、电影票房预测系统需求分析 6 (一)电影票房预测系统总体概述 6 (二)电影票房预测系统功能性需求 6 1.网络爬虫子模块 6 (三)电影票房预测系统非功能性需求 7 五、电影票房预测系统设计 7 (一) 电影票房预测系统整体架构 7 (二) 数据的爬取与清洗子模块 8 (三)数据存储子模块 9 (三) 票房预测子模块 9 六、电影票房预测系统实现 9 (一)系统整体架构实现 9 (二)网络爬虫子模块 10 (三)数据存储子模块 12 七、电影票房预测系统测试 12 (一)硬件环境配置 12 (二)软件环境配置 12 (三)Numpy库与Scipy库 12 (四)预测结果展示 13 1. 电影历史票房结果展示 13 2.电影票房多项式曲线拟合结果展示 13 3.电影预测票房结果展示 14 参考文献 15 |

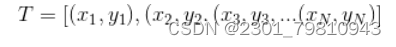
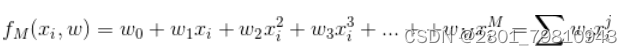
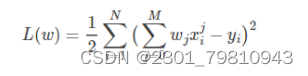
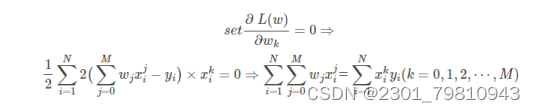
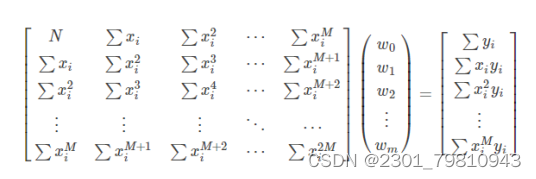
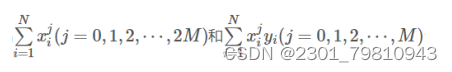
【本文地址】