基于协同过滤算法的电影推荐系统 |
您所在的位置:网站首页 › 电影推荐系统流程图 › 基于协同过滤算法的电影推荐系统 |
基于协同过滤算法的电影推荐系统
|
1. 问题定义
1. 1 背景介绍
随着互联网技术的快速发展,现在已经进入了大数据时代,网络上的信息呈现爆炸式增长,每天都会有数以亿计的数据涌现人们接触各种信息的途径也越来越丰富,但随着信息量增长,人们越来越难获取自身需求的信息,因此自动推荐系统应运而生。 1.2 项目意义然而最初的自动推荐系统是面向广大的用户群体,并未针对每个单独的用户进行推荐。因此,设计一种基于用户的偏好且对所推荐的产品进行属性分析的个性化推荐系统成为必然。个性化推荐系统技术可用于诸如图书网站、视频网站、音乐网站等网站。而现今视频网站上电影和电视剧数量早已破万,在如此庞大的视频数量下,怎样快速帮助用户发掘自己感兴趣的电影在网站运营中显得尤为重要。因此只有靠推荐系统通过分析用户的历史行为以及现下看的电影去分析潜在的用户可能感兴趣的电影。 2. 过程/数据矩阵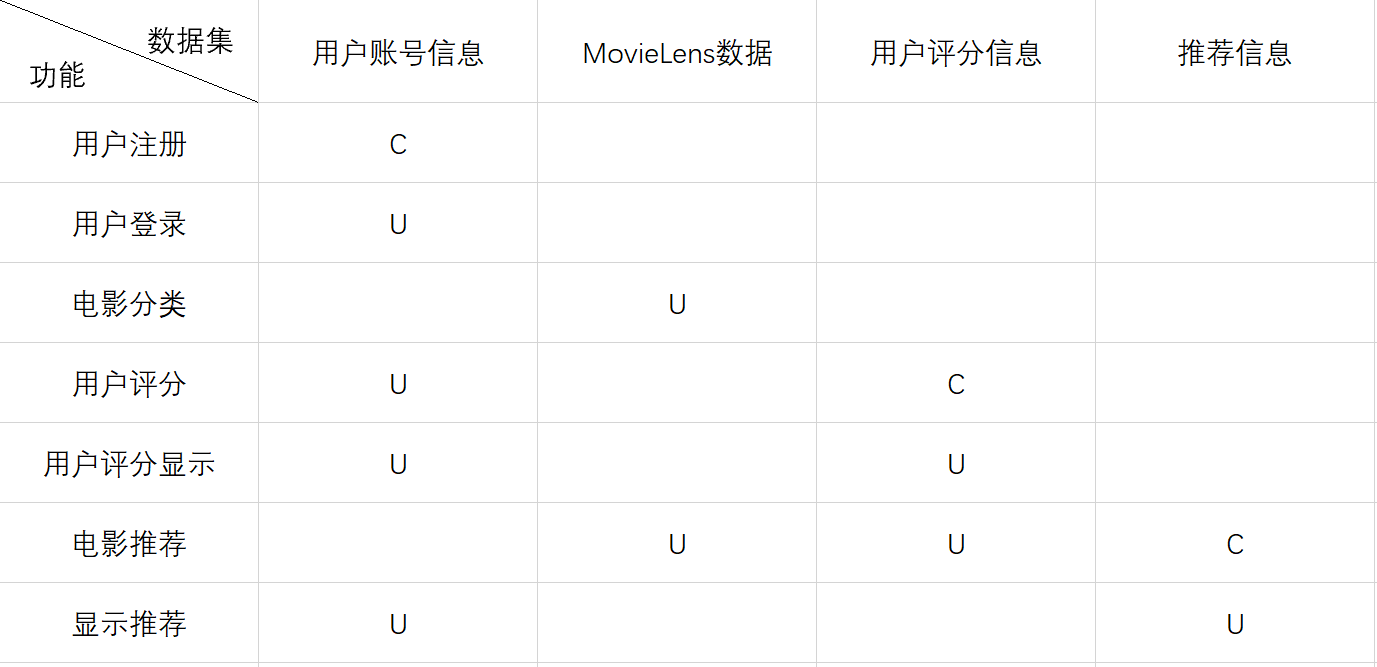 3. 协同过滤算法
3.1 基于用户的协同过滤算法
3. 协同过滤算法
3.1 基于用户的协同过滤算法
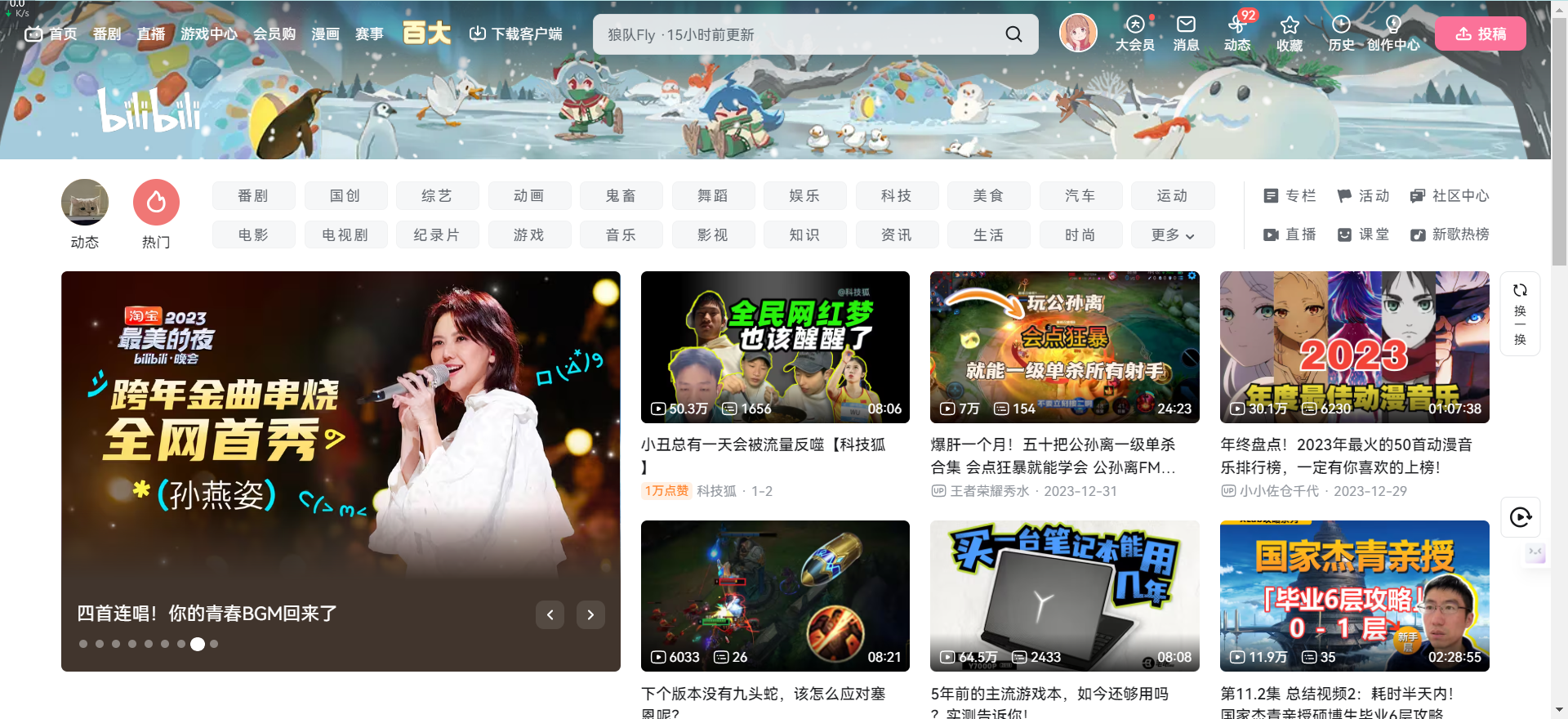
假设给定用户uuu和用户vvv,令N(u)N(u)N(u)表示用户uuu曾经评价过的电影集合,令N(v)N(v)N(v)表示用户vvv曾经评价过的电影集合.通过余弦相似度计算用户uuu和vvv的兴趣相似度: (1)wwv=∑i∈N(u)∩N(v)1log(1+∣N(i)∣)∣N(u)∥N(v)∣\mathrm{w}_{w v}=\frac{\sum i \in N(u) \cap N(v) \frac{1}{\log (1+|N(i)|)}}{\sqrt{|N(u) \| N(v)|}} \tag{1} wwv=∣N(u)∥N(v)∣∑i∈N(u)∩N(v)log(1+∣N(i)∣)1(1) 通过(1)式得到用户之间的相似度之后,推荐算法会给用户推荐与他兴趣最相似的KKK个用户喜欢的电影,(2)式计算了用户uuu对电影jjj的兴趣度。 (2)pui=∑v∈I(i)∩S(u,k)wuvrvi\mathrm{p}_{u \mathrm{i}}=\sum_{\mathrm{v} \in I(i) \cap S(u, k)} w_{u v} r_{v i} \tag{2} pui=v∈I(i)∩S(u,k)∑wuvrvi(2) 式(2)中的I(i)I(i)I(i)是对电影iii打过分的用户集合。S(u,k)S(u,k)S(u,k)是和用户uuu有着相似兴趣爱好的kkk个用户的集合,WUVW_{UV}WUV表示用户uuu和用户vvv之间的相似度,rvir_{vi}rvi衡量了用户vvv对电影iii的兴趣度,在本系统里是指用户vvv对电影iii的评分.最后按对电影的兴趣度从高到低排序,推荐前NNN部电影给用户uuu,属于Top-N推荐。 3.2 基于物品的协同过滤算法基于物品的协同过滤算法是计算物品之间的相似度,然后根据用户之前喜欢的物品来推荐用户可能喜欢的物品。 在基于物品的协同过滤算法中,两个物品之间有相似度是因为它们存在于很多用户的兴趣列表中.但是每个用户的贡献都不相同.活跃用户对物品相似度的贡献应该小于不活跃的用户。本系统采用式(3)计算物品相似度。 (3)wij=∑i∈N(i)∩N(j)1log(1+∣N(u)∣)∣N(i)∥N(j)∣\mathrm{w}_{i j}=\frac{\sum i \in N(i) \cap N(j) \frac{1}{\log (1+|N(u)|)}}{\sqrt{|N(i) \| N(j)|}} \tag{3} wij=∣N(i)∥N(j)∣∑i∈N(i)∩N(j)log(1+∣N(u)∣)1(3) 3.3 相似度计算在协同过滤算法中,相似度的计算至关重要.只有计算了用户或者物品之间的相似度才能得出推荐列表。常用的相似度计算方法有以下几种: (1)余弦相似度 在nnn维空间中,任意两个向量之间的夹角的余弦值大小即代表这两个向量的相似程度. 余弦值的取值范围为[-1,1]。 假设nnn维空间中存在向量iii和向量jjj,式(4)为计算其余弦相似度的公式。 (4)Sim(i,j)=cos(i⃗,j⃗)=i→∙j⃗∥i⃗∥∗∥j⃗∥\operatorname{Sim}(\mathrm{i}, \mathrm{j})=\cos (\vec{i}, \vec{j})=\frac{\overrightarrow{\mathrm{i}} \bullet \vec{j}}{\|\vec{i}\|^*\|\vec{j}\|} \tag{4} Sim(i,j)=cos(i,j)=∥i∥∗∥j∥i∙j(4) (2)欧式距离 欧式距离也称为欧几里得度量,是指在nnn维向量空间中,任意两个向量之间的自然长度。同样的,假设存在向量MMM和NNN,则欧式距离表达公式如式(5)所示。 (5)Dist(M,N)=∑i=1n(mi−ni)2Dist(M, N)=\sqrt{\sum_{i=1}^n\left(m_i-n_i\right)^2} \tag{5} Dist(M,N)=i=1∑n(mi−ni)2(5) (3)皮尔逊(Pearson)相关系数 如果一个推荐算法使用的是皮尔森相关系数来计算相似度,那么该算法将会比使用余弦相似度公式计算相似度的算法的精确度更高.然而这是要建立在两个用户拥有较多共同评分项目的基础上,如果两个用户之间共同评分项目很少,使用皮尔森相关系数进行计算无法反映出真实的相似度. 假设存在两个向量JJJ与KKK,这两个向量间的皮尔森相关系数计算公式如式(6)所示. (6)ρJ,K=∑(J−Jˉ)(K−Kˉ)∑(J−Jˉ)2∑(K−Kˉ)2\rho_{J, K}=\frac{\sum(J-\bar{J})(K-\bar{K})}{\sqrt{\sum(J-\bar{J})^2 \sum(K-\bar{K})^2}} \tag{6} ρJ,K=∑(J−Jˉ)2∑(K−Kˉ)2∑(J−Jˉ)(K−Kˉ)(6) 4. 推荐系统的设计与实现本节首先对国内主流视频网站进行调研,随后进行系统的需求分析,介绍系统架构和数据库,最后展示系统界面效果。 4.1 国内视频网站调研本次调研了国内较大的视频网站Bilibili,图1展示了Bilibili的首页,可以看到其能根据用户近期所看的视频推荐类似的视频如游戏、电脑等。图2展示了Bilibili的用户个人中心,用户可以在用户中心中看到自己最近点赞收藏的视频。
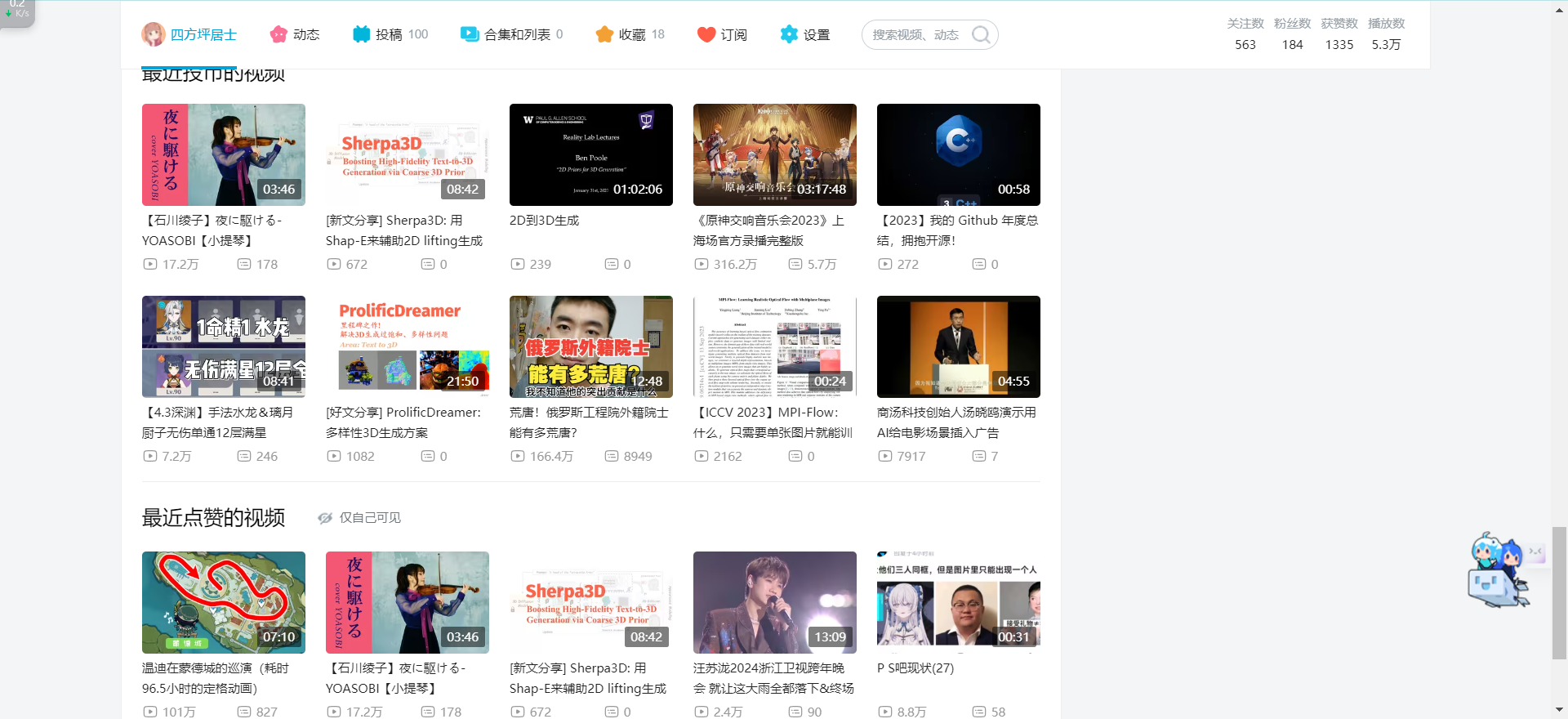 图2. Bilibili用户个人中心
4.2 需求分析
图2. Bilibili用户个人中心
4.2 需求分析
随着电影市场的迅速发展,每天都有大量电影上映.人们都希望可以高效的在海量电影库中找到自己可能会喜欢的电影,以节省寻找电影的时间。电影推荐系统能给用户带来便利.本文要实现的是一个面向用户的个性化电影推荐系统,根据movielens数据集里面大量用户对电影的评分数据,通过计算用户相似性、电影相似性,实现为用户推荐符合其兴趣的电影. 本文实现的个性化电影推荐系统有以下几点基本需求:
(1)数据集:每个用户所评电影数量要多,尽量广泛涉及大量电影
(2)推荐算法:推荐效果要良好
(3)包括用户注册登录在内的整个 web 系统
(4)系统要易于扩展和维护
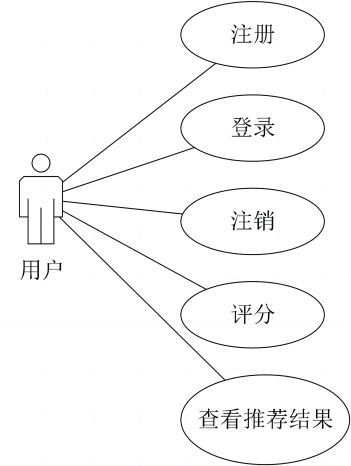
根据上述分析,我们设计了图3所示的用户用例图。
本项目从互联网上下载movielens数据集,经过数据重组和筛选,基于两种推荐算法得出推荐结果保存至 MySQL数据库中,并通过Django框架进行前端展示.本系统采用B/S(浏览器/服务器)体系结构,用户通过浏览器就能和网站上的内容交互。
实现本系统主要需要以下几种编程语言:
(1)Python:进行后台开发,编写推荐算法,实现与 MySQL 数据库交互,将用户的数据存储到数据库中,同时将生成的推荐列表展示到前端页面.。
(2)Html5:进行前端页面的开发。
(3)Css3:美化前端页面,特别是对电影分类板块做处理。
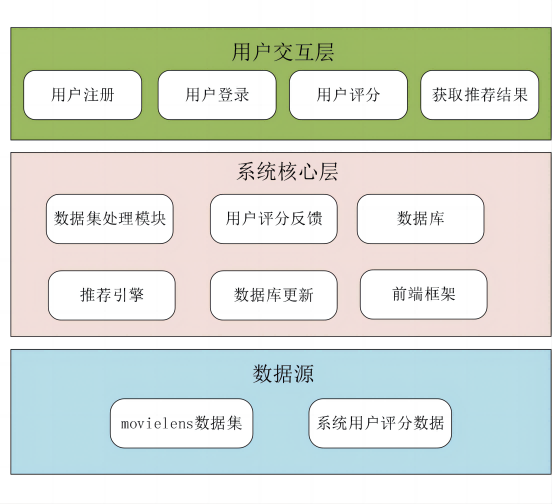
系统整体架构图如图4所示。
数据集处理模块
本项目设计的推荐系统的源数据集来源于movielens的ml-latestl-small,其中包含 671 个
用户的10万条评分数据.对数据集里面的ratings.csv和links.csv文件进行连接处理,只保留 userId、imdbId、rating 三个字段存入数据库中新建好的数据表 users_resulttable 中。
注册登录模块
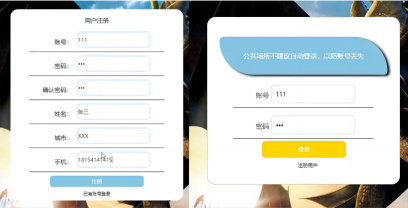
用户需要先注册账号且登录系统之后才能提交对电影的评分,用户注册与登录界面如图5所示。
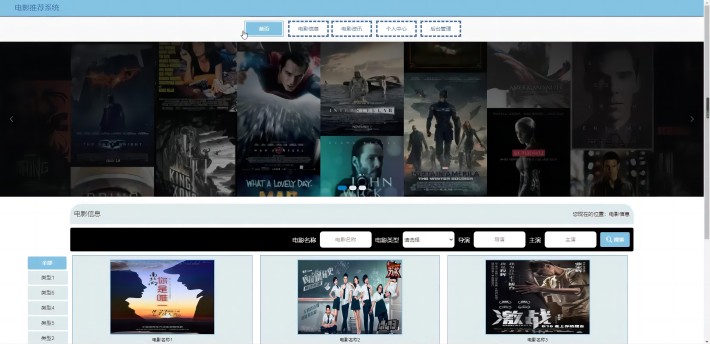
电影分类模块
系统首页展示了6种不同分类的电影,如图6所示。每部电影包括电影海报、电影名称、电影详情、电影评分、电影评论,如图7-9所示。
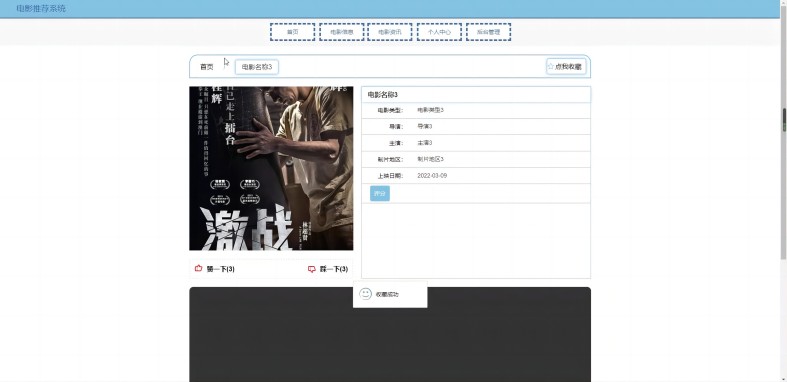 图7. 电影详情
图7. 电影详情
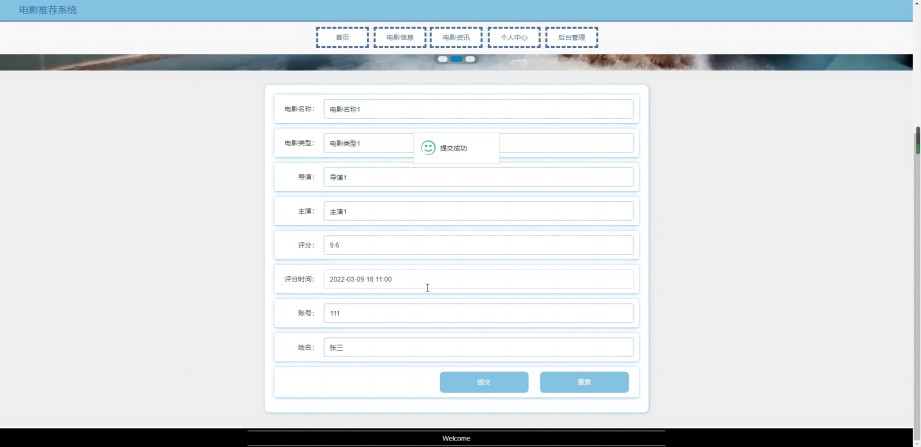 图8. 电影评分
图8. 电影评分
 图9. 电影评论
图9. 电影评论
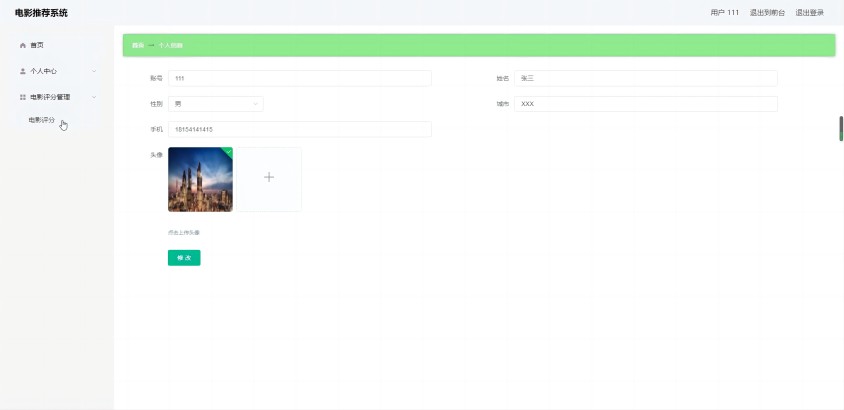
个人信息管理模块
用户可以在该模块查看编辑自己的个人信息,效果如图10所示。
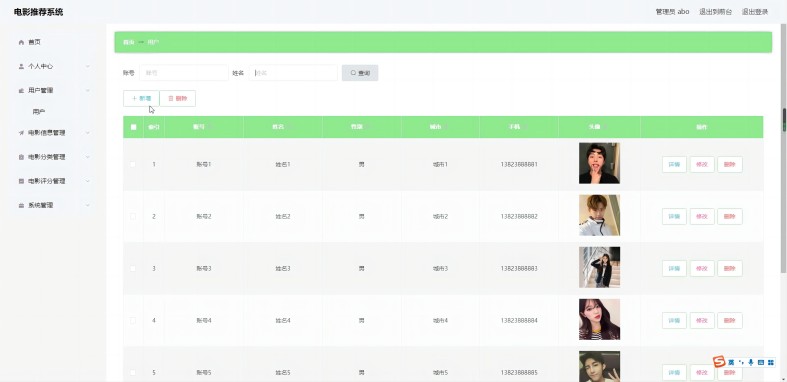
后台管理系统
管理员可进入后台管理系统实现对用户信息、电影信息、电影分类、电影评分的管理,效果如图11所示。
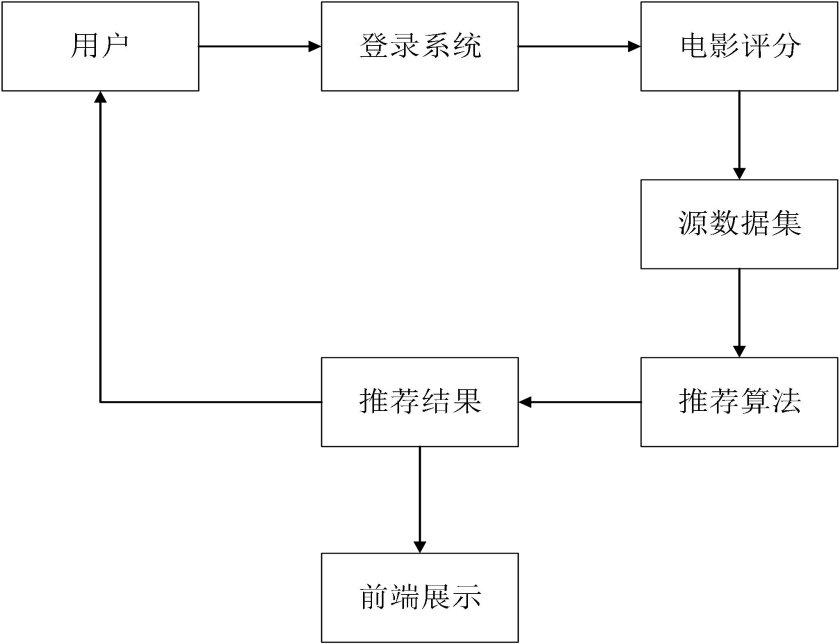
推荐算法模块
本模块是整个系统的核心组成部分,当用户登录进入系统并对电影进行评分之后,系统就记录下了该用户的 id 号,当用户再次登入系统时,系统会将源数据集和该用户之前的评分数据整合成新的数据表作为推荐的依据。整个推荐过程流程图如图12所示。
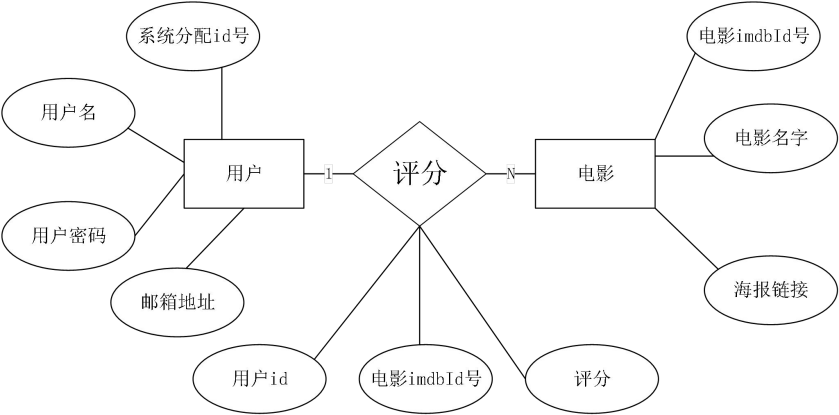
本节归纳了用户、电影、推荐列表、用户评分数据表之间的关系. 用户实体属性如图13所示.每个用户注册系统的时候都必须填写用户名、邮箱地址,设置用户密码,并且系统会自动为其分配一个 id 号。 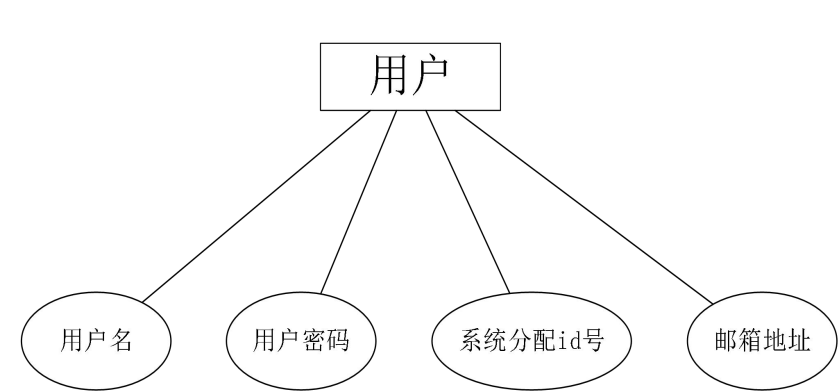 图13. 用户E-R图
图13. 用户E-R图
每部电影的实体属性如图14所示。 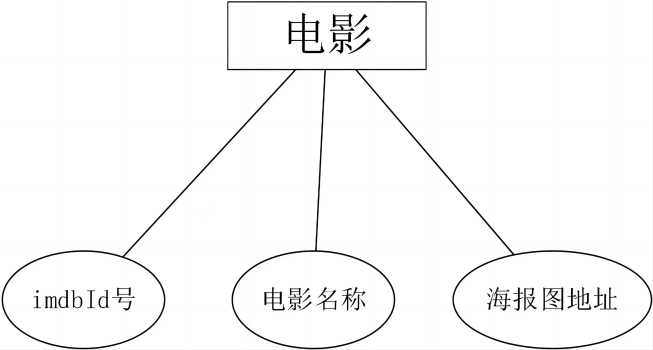 图14. 电影E-R图
图14. 电影E-R图
推荐结果列表信息的实体属性如图 15所示。推荐结果列表中包含电影的海报图地址,这样推荐页面就会展示出电影海报,增加系统美观的同时也提高了用户的可阅读性。 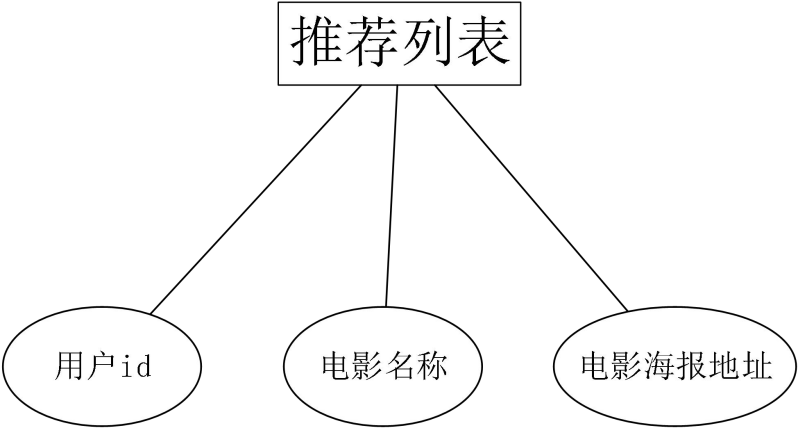 图15. 推荐结果E-R图
图15. 推荐结果E-R图
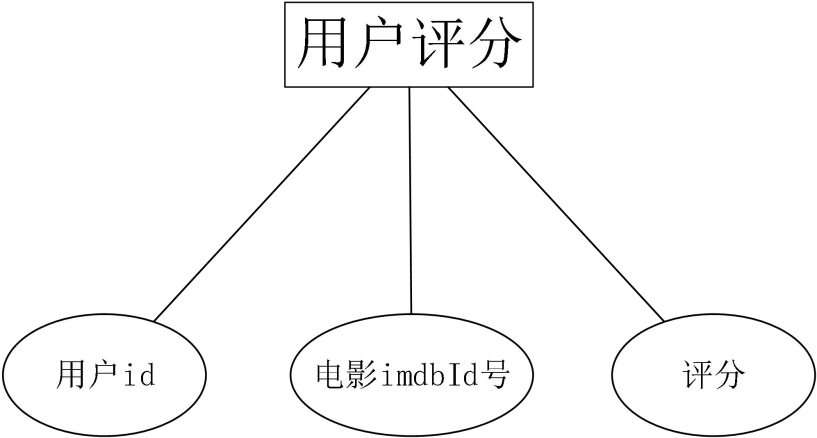
用户对电影的评分实体属性如图16所示。
数据库模型通常包括层次模型、网状模型、关系模型以及 ER 图(实体-联系图)。系统的 E-R 图如图17 所示。
 6. 人员与资源安排
6. 人员与资源安排
胡启滨:负责项目整体管理和进度把控。收集、清洗和处理电影和用户数据。 汤冬骊:选择合适的推荐算法,并进行模型建立。实施推荐系统的开发和测试。 岳云腾:负责推荐系统的测试和性能优化。 7. 可行性分析经济可行性:成本上主要包括服务器购买及运营成本,数据库成本,以及定期维护更新的成本。而系统可以作为付费服务或通过广告获取收益。 管理可行性:项目有足够的技术和管理人员来支持项目的开发和维护,也有明确的项目计划和时间表。另外系统设有数据备份和恢复机制,以防数据丢失或损坏。 技术可行性:Python、MySQL和Django框架在技术成熟稳定,且社区支持良好。UserCF-IIF算法已被证明在推荐系统中有效,且在当前数据量下表现良好。系统架构易于扩展和维护,以适应未来的增长和变化。系统有清晰的代码文档和系统文档,便于开发和维护。 8. 总结本项目主要研究了实现电影推荐系统所需的技术,研究了推荐算法以及推荐系统的一些国内外现状。并以电影推荐系统为实例,对整个推荐系统的架构以及所有功能做了详尽的阐述与分析。从系统的需求分析出发,剖析了用户对功能的需求,然后介绍了系统的各个功能模块,最后充分展示了系统数据库的设计以及数据表的内容。设计的系统包含用户信息模块、电影展示模块、用户评分模块、推荐结果模块.每个模块的介绍都有流程图或者系统截图。 本项目采用两种协同过滤算法:基于用户的协同过滤和基于物品的协同过滤,使用户能从两种不同角度获得推荐,提高用户的可选择性。 本项目结合现有的较热门的Web框架Django,利用Django内置的用户注册表单实现用户注册,编写视图代码进行电影推荐结果的UI前端展示.利用 CSS3 语言对网页进行排版、美化,使系统看上去更加简洁和美观,增加用户的体验。 |
【本文地址】
今日新闻 |
推荐新闻 |