Python大作业:分析当当网书籍价格、出版社、电子书版本占比数据 |
您所在的位置:网站首页 › 电子书出版价格 › Python大作业:分析当当网书籍价格、出版社、电子书版本占比数据 |
Python大作业:分析当当网书籍价格、出版社、电子书版本占比数据
|
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
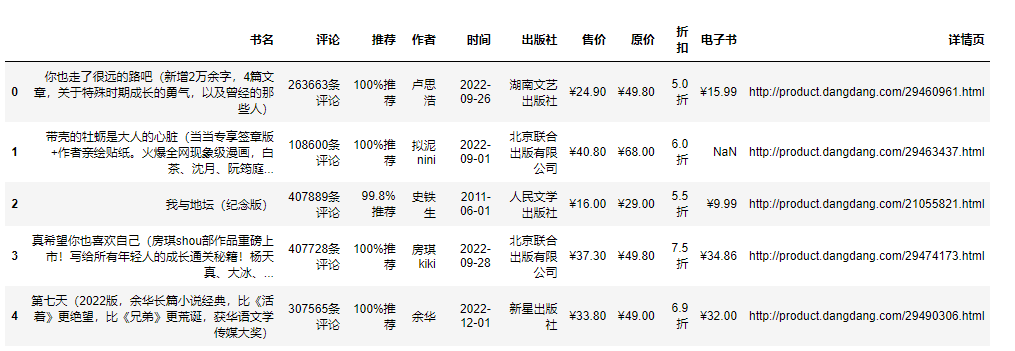
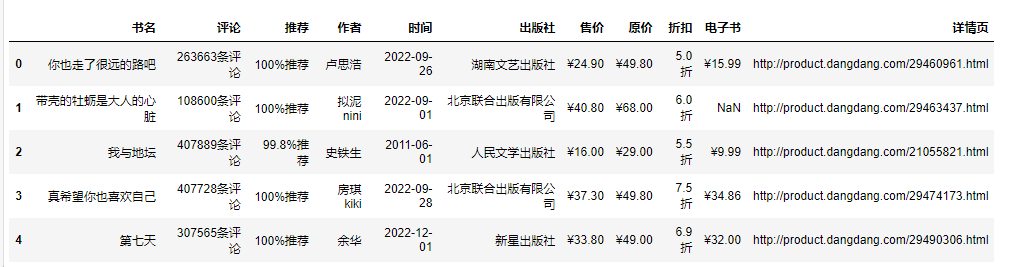
首先我们先来安装一下写代码的软件(对没安装的小白说) 版 本: python 3.8 编辑器: pycharm 2022.3.2 专业版 模块使用:requests >>> pip install requests 数据请求 parsel >>> pip install parsel 数据解析 csv 内置模块 保存数据 第三方模块安装: win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车 在pycharm中点击Terminal(终端) 输入安装命令 代码步骤:发送请求 获取数据 解析数据 保存数据 python资料、源码、教程: 点击此处跳转文末名片获取 采集代码展示: # 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests import requests # 导入数据解析模块 --> 第三方模块, 需要安装 pip install parsel import parsel # 导入csv模块 import csv“”" 发送请求 --> 模拟浏览器对url请求发送请求 响应对象 200 状态码 --> 表示请求成功 多页数据采集: 分析请求链接变化规律 “”" for page in range(1, 26): #请求链接 url = f'http://****m/books/bestsellers/01.00.00.00.00.00-recent30-0-0-1-{page}'伪装 模拟 --> 请求头 字典数据类型 headers = { # User-Agent 用户代理 表示浏览器基本身份信息 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' }发送请求 等号左边都是自定义变量名 response = requests.get(url=url, headers=headers)“”" 获取数据, 获取网页源代码 response.text 获取响应对象文本数据 变量名 --> 见名知意 解析数据, 提取我们想要的内容 使用css选择器 “”" selector = parsel.Selector(response.text) # 第一次提取 获取所有书籍所对应li标签 lis = selector.css('.bang_list_mode li') # for循环遍历 for li in lis:“”" 提取具体数据信息 css选择器 --> 可以直接复制粘贴就好了 get 获取第一个标签数据内容 “”" title = li.css('.name a::attr(title)').get() # 书名 star = li.css('.star a::text').get() # 评论 recommend = li.css('.tuijian::text').get() # 推荐 writer = li.css('.publisher_info a::text').get() # 作者 date = li.css('.publisher_info span::text').get() # 时间 publisher = li.css('div:nth-child(6) a::text').get() # 出版社 price_n = li.css('.price .price_n::text').get() # 售价 price_r = li.css('.price .price_r::text').get() # 原价 price_s = li.css('.price .price_s::text').get() # 折扣 price_e = li.css('.price_e .price_n::text').get() # 电子书 href = li.css('.name a::attr(href)').get() # 详情页 # 创建字典 dit = { '书名': title, '评论': star, '推荐': recommend, '作者': writer, '时间': date, '出版社': publisher, '售价': price_n, '原价': price_r, '折扣': price_s, '电子书': price_e, '详情页': href, } csv_writer.writerow(dit) print(title, star, recommend, writer, date, publisher, price_n, price_r, price_s, price_e, href)“”" 保存数据“”" # 创建表格保存数据 f = open('书籍.csv', mode='a', encoding='utf-8', newline='') csv_writer = csv.DictWriter(f, fieldnames=[ '书名', '评论', '推荐', '作者', '时间', '出版社', '售价', '原价', '折扣', '电子书', '详情页', ]) # 写入表头 csv_writer.writeheader() 可视化代码展示: 1.导入模块 import pandas as pd from pyecharts.charts import * from pyecharts.globals import ThemeType#设定主题 from pyecharts.commons.utils import JsCode import pyecharts.options as opts 2.导入数据 df = pd.read_csv('data.csv', encoding='utf-8', engine='python') df.head()
提取评论数 data = df.apply(lambda x:x['评论'].split('条评论')[0], axis=1) df['评论数'] = data.astype('int64') df.head(1)
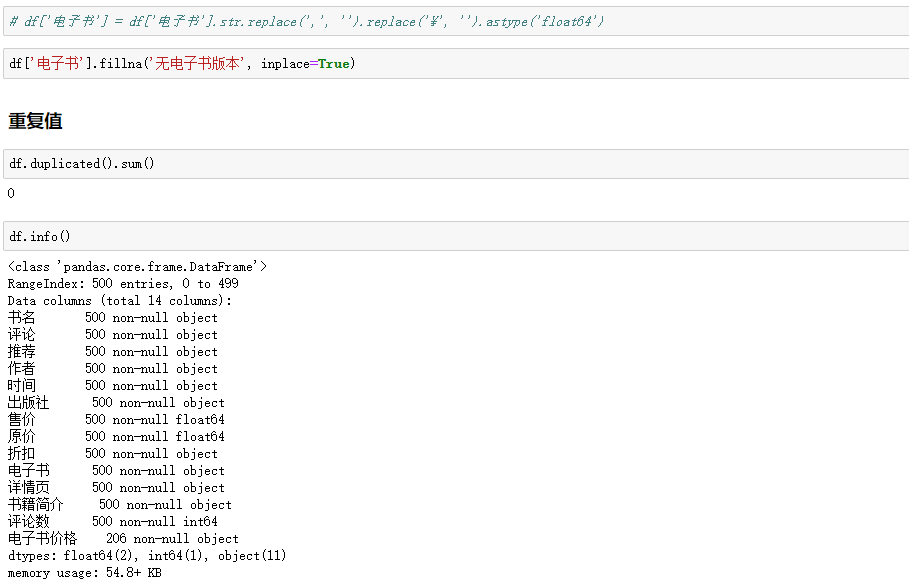
原价、售价、电子书价格 数值化 df['原价'] = df['原价'].str.replace('¥', '') df['售价'] = df['售价'].str.replace('¥', '') df['电子书价格'] = df['电子书'].str.replace('¥', '') df.head(1)
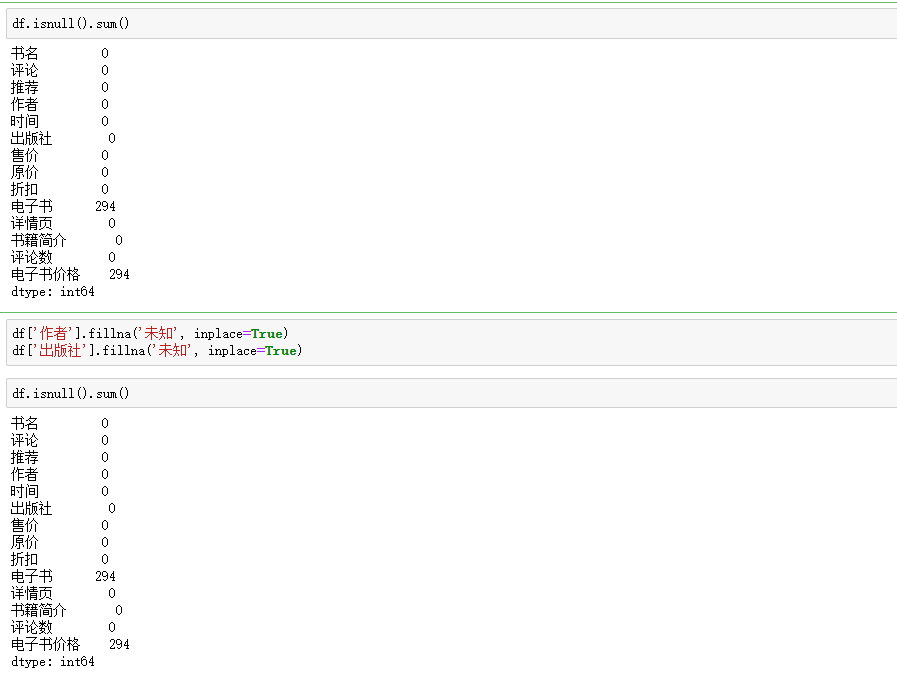
缺失值
电子书价格列额外处理
书籍总体价格区间 def tranform_price(x): if x |




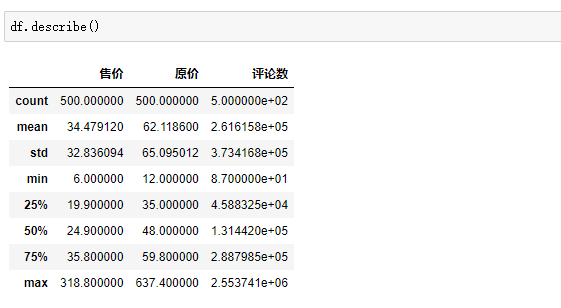
【本文地址】