使用Python分析《水浒传》里面人物出现次数并生成词云图 |
您所在的位置:网站首页 › 用水浒传人物取游戏名 › 使用Python分析《水浒传》里面人物出现次数并生成词云图 |
使用Python分析《水浒传》里面人物出现次数并生成词云图
|
《水浒传》相信大家都不陌生吧,作为四大名著之一,读完之后无不为108个英雄的悲惨命运扼腕叹息,今天我们不讨论英雄们的悲惨命运,只对108条好汉在原著《水浒传》中出现的次数进行一个排名。 程序的思路很简单,分为以下几个步骤: 【第一步】获取108个好汉的名字【第二步】对原著《水浒传》进行分词统计【第三步】将《水浒传》中多余的词语删除后剩余108个好汉的出现次数【第四步】对108个好汉出现次数进行词云展示现在分步骤逐个击破 【第一步】提取108个好汉的名字 一个一个从网上复制粘贴?No,如果那样的话我们学习Python干什么?不如不学了。我从网上复制了一段含有108人绰号和名字的文本保存在本机,然后通过一段代码,逐个抽取出了108人的名字。代码及效果如下。 # coding:utf-8 name_lst = [] f = open('names.txt', 'r') for item in f.readlines(): if item != "\n": name_lst.append(item.split(' ')[-1].strip()) f.close() f = open('name_lst.txt', 'w') f.writelines('\n'.join(name_lst)) f.close() 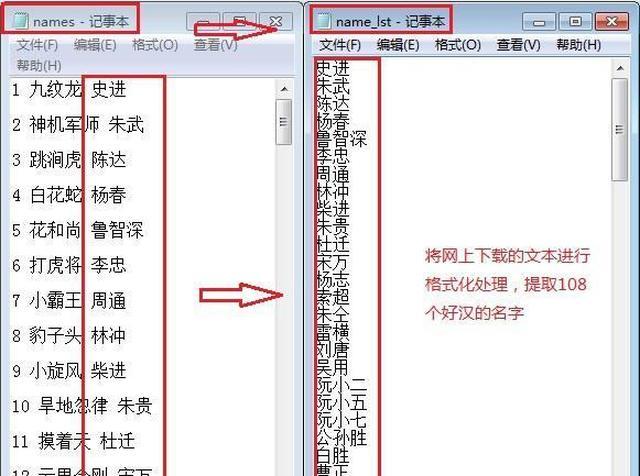 我们将108人名字存储在本地name_lst.txt文件中。 【第二步】对原著《水浒传》进行分词统计操作 这一段不再赘述,上面已经讨论了很多篇幅,有疑问的童鞋请查看本人的其他博文,有不少相关讨论内容,我们直接分步骤上代码。需要提醒的是,在获取《水浒传》全文内容之后,建议在使用jieba分词前,添加上108个人的名字,以提高匹配度。之前,我做了几次实验(其中,乐和、呼延灼、李衮三个人没有匹配上)。添加自定义分词的方法是jieba.add_word(‘名字’)。 首先获得《水浒传》文件,并替换掉多余的标点符号 # 打开《水浒传》文件 #text_temp = codecs.open('水浒传.txt', 'r', encode='utf-8', errors='ignore') text_temp = open("水浒传.txt", 'r', encoding='gbk', errors='ignore').read() # 构造要替换的正则表达式字符 pattern= re.compile(u'\t|\n|\.|-|\”|;|\)|\(|\?|\“|。|;|,|、|\ |\ |\(|\)|\∶') # 去除文本中无效字符 text_temp = re.sub(pattern, '', text_temp)  2.获取108人的名字,并存储在列表内 name_lst=[] try: with open('name_lst.txt', 'r') as f: for line in f.readlines(): name_lst.append(line.strip()) except Exception as e: print('Error') 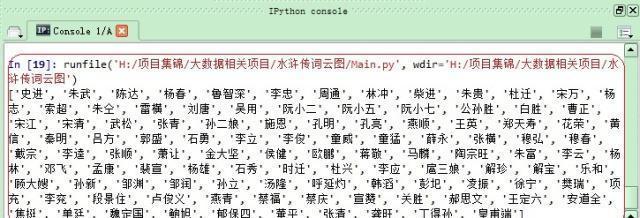 3.将108个名字逐个添加到jieba自定义词中以便增加名字的匹配度 for item in name_lst: jieba.add_word(item.strip()) 4.进行分词处理,因为先前添加了人名,这时就能匹配全部任务名字 cut_text = jieba.cut(text_temp) print(cut_text) 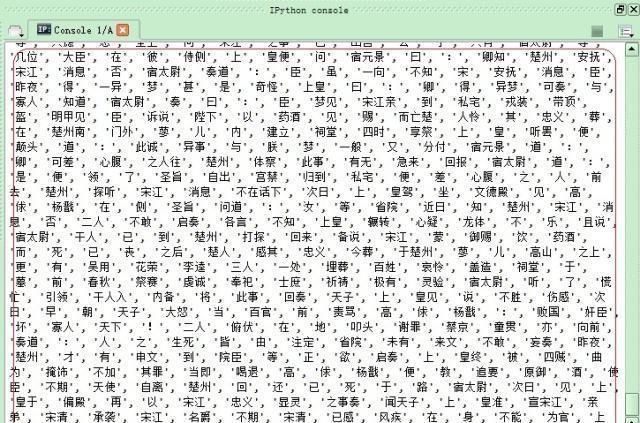 5.统计词数 text_dict = collections.Counter(list(cut_text)) 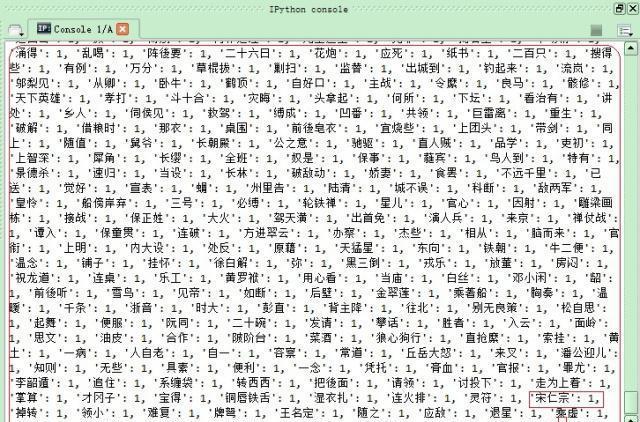 【第三步】将《水浒传》中多余的词语删除后剩余108个好汉的出现次数 result_dict = {} for item in text_dict.keys(): if item in name_lst: result_dict[item] = text_dict.get(item, '没获取到数据') 最终,我们得到result_dict字典,里面只是保留了人名出现的次数。  【第四步】对108个好汉出现次数进行词云展示 path_image='timg.jpg' font_path="SIMLI.ttf" background_image = np.array(Image.open(path_image)) wd = WordCloud( max_font_size = 500, random_state=10, font_path=font_path, background_color="white", mask=background_image ).generate_from_frequencies(result_dict) wd.to_file('shuihurenwu.png') plt.imshow(wd,interpolation="bilinear") plt.axis("off") plt.show()  原来宋江、李逵、武松、吴用等人出现次数比较多,怎么样,Python处理这些内容是不是很方便? |
【本文地址】
今日新闻 |
推荐新闻 |