大数据课程综合实验案例:网站用户行为分析 |
您所在的位置:网站首页 › 用户行为分析技术 › 大数据课程综合实验案例:网站用户行为分析 |
大数据课程综合实验案例:网站用户行为分析
|
大数据课程综合实验案例
1 案例简介
1.1 案例目的
1.2 适用对象
1.3 时间安排
1.4 预备知识
1.5 硬件要求
1.6 软件工具
1.7 数据集
1.8 案例任务
1.9 实验步骤
2 本地数据上传到数据仓库Hive
2.1 实验数据集的下载
2.2 数据集的预处理
(1)删除文件第一行记录,即字段名称
(2)对字段进行预处理
(3)导入数据库
3 Hive数据分析
3.1 操作Hive
3.2 简单查询分析
3.3 查询条数统计分析
3.4 关键字条件查询分析
3.4.1 以关键字的存在区间为条件的查询
3.4.2 关键字赋予给定值为条件,对其他数据进行分析
3.5 根据用户行为分析
3.5.1 查询一件商品在某天的购买比例或浏览比例
3.5.2 查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)
3.5.3 给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
3.6 用户实时查询分析
4 Hive、MySQL、HBase数据互导
4.1 准备工作
4.2 使用Java API将数据从Hive导入MySQL
4.3 查看MySQL中user_action表数据
4.4 使用HBase Java API把数据从本地导入HBase中
4.4.1 启动Hadoop集群、HBase服务
4.4.2 数据准备
4.4.3 编写数据导入程序
4.4.4 数据导入
5 利用R进行数据可视化分析
5.1 安装R
5.2 可视化分析
1 案例简介
大数据课程实验案例:网站用户行为分析,由厦门大学数据库实验室团队开发,旨在满足全国高校大数据教学对实验案例的迫切需求。本案例涉及数据预处理、存储、查询和可视化分析等数据处理全流程所涉及的各种典型操作,涵盖Linux、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用方法。案例适合高校(高职)大数据教学,可以作为学生学习大数据课程后的综合实践案例。通过本案例,将有助于学生综合运用大数据课程知识以及各种工具软件,实现数据全流程操作。各个高校可以根据自己教学实际需求,对本案例进行补充完善。 1.1 案例目的熟悉Linux系统、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用; 了解大数据处理的基本流程; 熟悉数据预处理方法; 熟悉在不同类型数据库之间进行数据相互导入导出; 熟悉使用R语言进行可视化分析; 熟悉使用Elipse编写Java程序操作HBase数据库。 1.2 适用对象高校(高职)教师、学生 大数据学习者 1.3 时间安排本案例可以作为大数据入门级课程结束后的“大作业”,或者可以作为学生暑期或寒假大数据实习实践基础案例,完成本案例预计耗时7天。 1.4 预备知识需要案例使用者,已经学习过大数据相关课程(比如入门级课程《大数据技术原理与应用》),了解大数据相关技术的基本概念与原理,了解Windows操作系统、Linux操作系统、大数据处理架构Hadoop的关键技术及其基本原理、列族数据库HBase概念及其原理、数据仓库概念与原理、关系型数据库概念与原理、R语言概念与应用。 不过,由于本案例提供了全部操作细节,包括每个命令和运行结果,所以,即使没有相关背景知识,也可以按照操作说明顺利完成全部实验。 1.5 硬件要求本案例在集群环境下完成。 1.6 软件工具本案例所涉及的系统及软件 Linux系统(Ubuntu16.04或14.04或18.04) MySQL(版本无要求) Hadoop(3.0以上版本) HBase(1.1.2或1.1.5,HBase版本需要和Hadoop版本兼容) Hive(1.2.1,Hive需要和Hadoop版本兼容,不要安装Hive3.0以上版本) R(版本无要求) Eclipse(版本无要求) 不需要Sqoop,因为Sqoop无法支持Hadoop3.0以上版本 1.7 数据集网站用户购物行为数据集2000万条记录。 1.8 案例任务安装Linux操作系统 安装关系型数据库MySQL 安装大数据处理框架Hadoop 安装列族数据库HBase 安装数据仓库Hive 安装Sqoop 安装R 安装Eclipse 对文本文件形式的原始数据集进行预处理 把文本文件的数据集导入到数据仓库Hive中 对数据仓库Hive中的数据进行查询分析 使用Java API将数据从Hive导入MySQL 使用Java API将数据从MySQL导入HBase 使用HBase Java API把数据从本地导入到HBase中 使用R对MySQL中的数据进行可视化分析 1.9 实验步骤步骤零:实验环境准备 步骤一:本地数据集上传到数据仓库Hive 步骤二:Hive数据分析 步骤三:Hive、MySQL、HBase数据互导 步骤四:利用R进行数据可视化分析 2 本地数据上传到数据仓库Hive本节介绍数据集的下载、数据集的预处理和导入数据库。 2.1 实验数据集的下载本案例采用的数据集为user.zip,包含了一个大规模数据集raw_user.csv(包含2000万条记录),和一个小数据集small_user.csv(只包含30万条记录)。小数据集small_user.csv是从大规模数据集raw_user.csv中抽取的一小部分数据。之所以抽取出一少部分记录单独构成一个小数据集,是因为,在第一遍跑通整个实验流程时,会遇到各种错误,各种问题,先用小数据集测试,可以大量节约程序运行时间。等到第一次完整实验流程都顺利跑通以后,就可以最后用大规模数据集进行最后的测试。 在个人电脑中打开百度云网盘页面进行数据集的下载:https://pan.baidu.com/s/1nuOSo7B 。在个人电脑终端使用scp将个人电脑中的数据集上传到服务器/home/hadoop/Download路径。
raw_user和small_user中的第一行都是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行。 cd /usr/local/bigdatacase/dataset //下面删除raw_user中的第1行 sed -i '1d' raw_user.csv //1d表示删除第1行,同理,3d表示删除第3行,nd表示删除第n行 //下面删除small_user中的第1行 sed -i '1d' small_user.csv //下面再用head命令去查看文件的前5行记录,就看不到字段名称这一行了 head -5 raw_user.csv head -5 small_user.csv
下面对数据集进行一些预处理,包括为每行记录增加一个id字段(让记录具有唯一性)、增加一个省份字段(用来后续进行可视化分析),并且丢弃user_geohash字段(后面分析不需要这个字段)。 下面我们要建一个脚本文件pre_deal.sh,请把这个脚本文件放在dataset目录下,和数据集small_user.csv放在同一个目录下: cd /usr/local/bigdatacase/dataset vim pre_deal.sh上面使用vim编辑器新建了一个pre_deal.sh脚本文件,请在这个脚本文件中加入下面代码: #!/bin/bash #下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称 infile=$1 #下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称 outfile=$2 #注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面 awk -F "," 'BEGIN{ srand(); id=0; Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市"; Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南"; Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北"; Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川"; Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾"; } { id=id+1; value=int(rand()*34); print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value] }' $infile > $outfile
在上面的pre_deal.sh代码的处理逻辑部分,srand()用于生成随机数的种子,id是我们为数据集新增的一个字段,它是一个自增类型,每条记录增加1,这样可以保证每条记录具有唯一性。我们会为数据集新增一个省份字段,用来进行后面的数据可视化分析,为了给每条记录增加一个省份字段的值,这里,我们首先用Province[]数组用来保存全国各个省份信息,然后,在遍历数据集raw_user.csv的时候,每当遍历到其中一条记录,使用value=int(rand()*34)语句随机生成一个0-33的整数,作为Province省份值,然后从Province[]数组当中获取省份名称,增加到该条记录中。 substr($6,1,10)这个语句是为了截取时间字段time的年月日,方便后续存储为date格式。awk每次遍历到一条记录时,每条记录包含了6个字段,其中,第6个字段是时间字段,substr($6,1,10)语句就表示获取第6个字段的值,截取前10个字符,第6个字段是类似”2014-12-08 18″这样的字符串(也就是表示2014年12月8日18时),substr($6,1,10)截取后,就丢弃了小时,只保留了年月日。 另外,在 print id”\t”\$1″\t”\$2″\t”\$3″\t”\$5″\t”substr(\$6,1,10)”\t”Province[value]这行语句中,我们丢弃了每行记录的第4个字段,所以,没有出现$4。我们生成后的文件是“\t”进行分割,这样,后续我们去查看数据的时候,效果让人看上去更舒服,每个字段在排版的时候会对齐显示,如果用逗号分隔,显示效果就比较乱。 最后,保存pre_deal.sh代码文件,退出vim编辑器。 下面就可以执行pre_deal.sh脚本文件,来对raw_user.csv进行数据预处理,命令如下: cd /usr/local/bigdatacase/dataset bash ./pre_deal.sh small_user.csv user_table.txt可以使用head命令查看生成的user_table.txt,不要直接打开,文件过大,会出错,下面查看前10行数据: 下面要把user_table.txt中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把user_table.txt上传到分布式文件系统HDFS中,然后,在Hive中创建一个外部表,完成数据的导入。 a.启动HDFS HDFS是Hadoop的核心组件,因此,需要使用HDFS,必须安装Hadoop。这里假设你已经安装了Hadoop,安装目录是“/usr/local/hadoop”。 下面,请登录Linux系统,打开一个终端,执行下面命令启动Hadoop: cd /usr/local/hadoop ./sbin/start-all.sh然后,执行jps命令看一下当前运行的进程: 然后,把Linux本地文件系统中的user_table.txt上传到分布式文件系统HDFS的“/bigdatacase/dataset”目录下,命令如下: cd /usr/local/hadoop ./bin/hdfs dfs -put /usr/local/bigdatacase/dataset/user_table.txt /bigdatacase/dataset下面可以查看一下HDFS中的user_table.txt的前10条记录,命令如下: cd /usr/local/hadoop ./bin/hdfs dfs -cat /bigdatacase/dataset/user_table.txt | head -10
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。由于前面我们已经启动了Hadoop,所以,这里不需要再次启动Hadoop。下面,在这个新的终端中执行下面命令进入Hive: cd /usr/local/hive ./bin/hive //启动Hive
|
 下面需要把user.zip进行解压缩,我们需要首先建立一个用于运行本案例的目录bigdatacase,请执行以下命令:
下面需要把user.zip进行解压缩,我们需要首先建立一个用于运行本案例的目录bigdatacase,请执行以下命令:
 现在你就可以看到在dataset目录下有两个文件:raw_user.csv和small_user.csv。
现在你就可以看到在dataset目录下有两个文件:raw_user.csv和small_user.csv。  我们执行下面命令取出前面5条记录看一下:
我们执行下面命令取出前面5条记录看一下:  可以看出,每行记录都包含5个字段,数据集中的字段及其含义如下:
可以看出,每行记录都包含5个字段,数据集中的字段及其含义如下: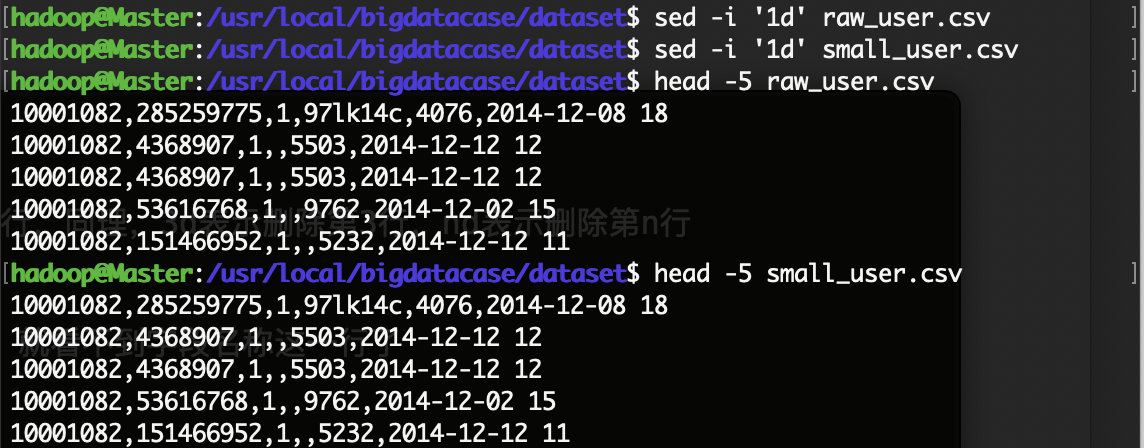
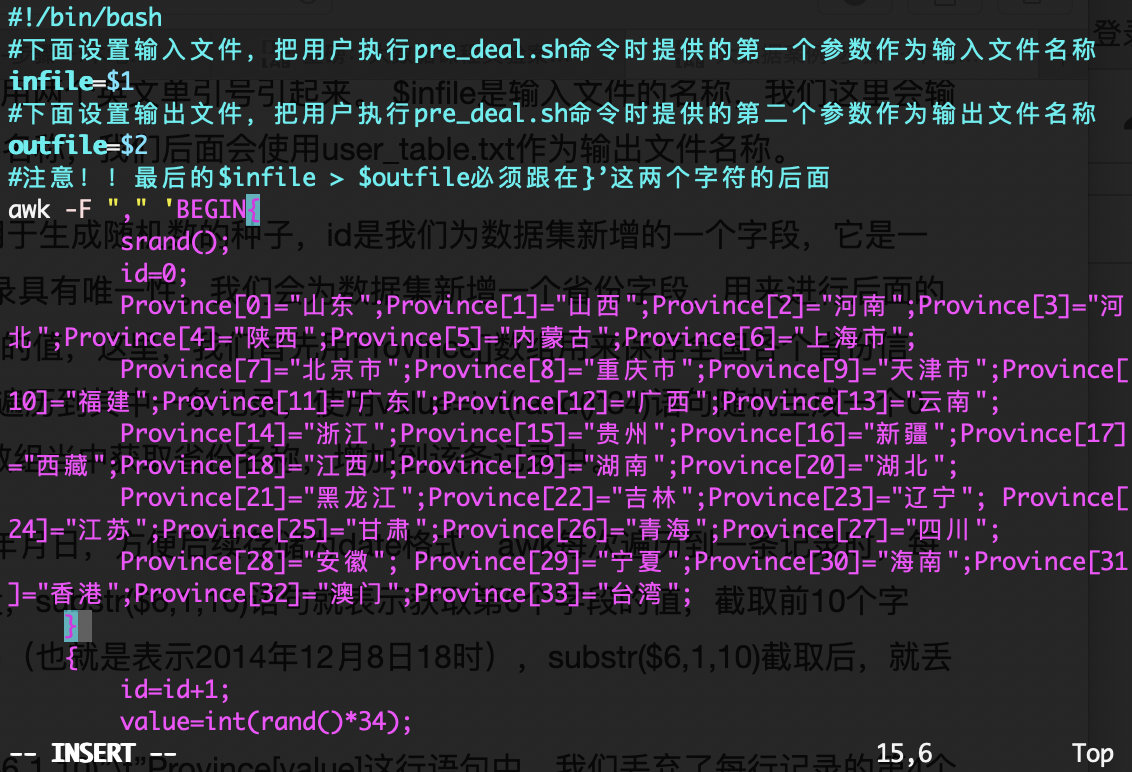 使用awk可以逐行读取输入文件,并对逐行进行相应操作。其中,-F参数用于指出每行记录的不同字段之间用什么字符进行分割,这里是用逗号进行分割。处理逻辑代码需要用两个英文单引号引起来。 $infile是输入文件的名称,我们这里会输入raw_user.csv,$outfile表示处理结束后输出的文件名称,我们后面会使用user_table.txt作为输出文件名称。
使用awk可以逐行读取输入文件,并对逐行进行相应操作。其中,-F参数用于指出每行记录的不同字段之间用什么字符进行分割,这里是用逗号进行分割。处理逻辑代码需要用两个英文单引号引起来。 $infile是输入文件的名称,我们这里会输入raw_user.csv,$outfile表示处理结束后输出的文件名称,我们后面会使用user_table.txt作为输出文件名称。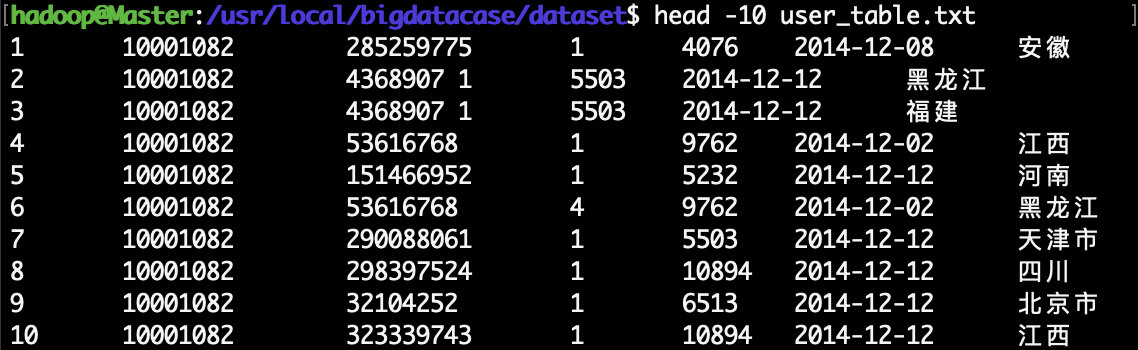
 说明hadoop启动成功。
说明hadoop启动成功。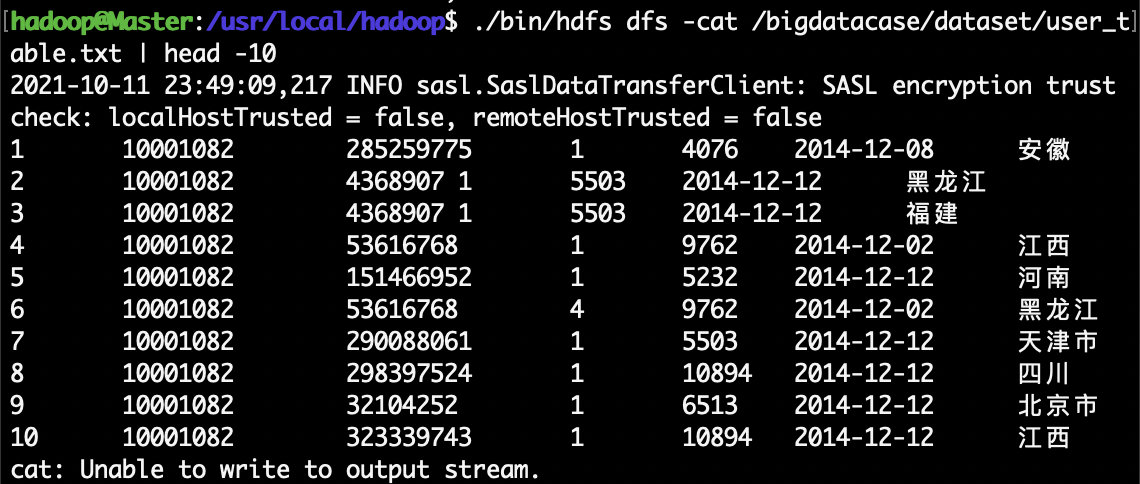
 下面,我们要在Hive中创建一个数据库dblab,命令如下:
下面,我们要在Hive中创建一个数据库dblab,命令如下:【本文地址】
今日新闻 |
推荐新闻 |