|
在淘宝中搜索python查看一共显示100页  点击下一页时头标的url数值并未改变此时断定这是一个动态网页所有此时我们需要找到它的json数据,在点击下一页的同时查看XHR中的数据变化 点击下一页时头标的url数值并未改变此时断定这是一个动态网页所有此时我们需要找到它的json数据,在点击下一页的同时查看XHR中的数据变化 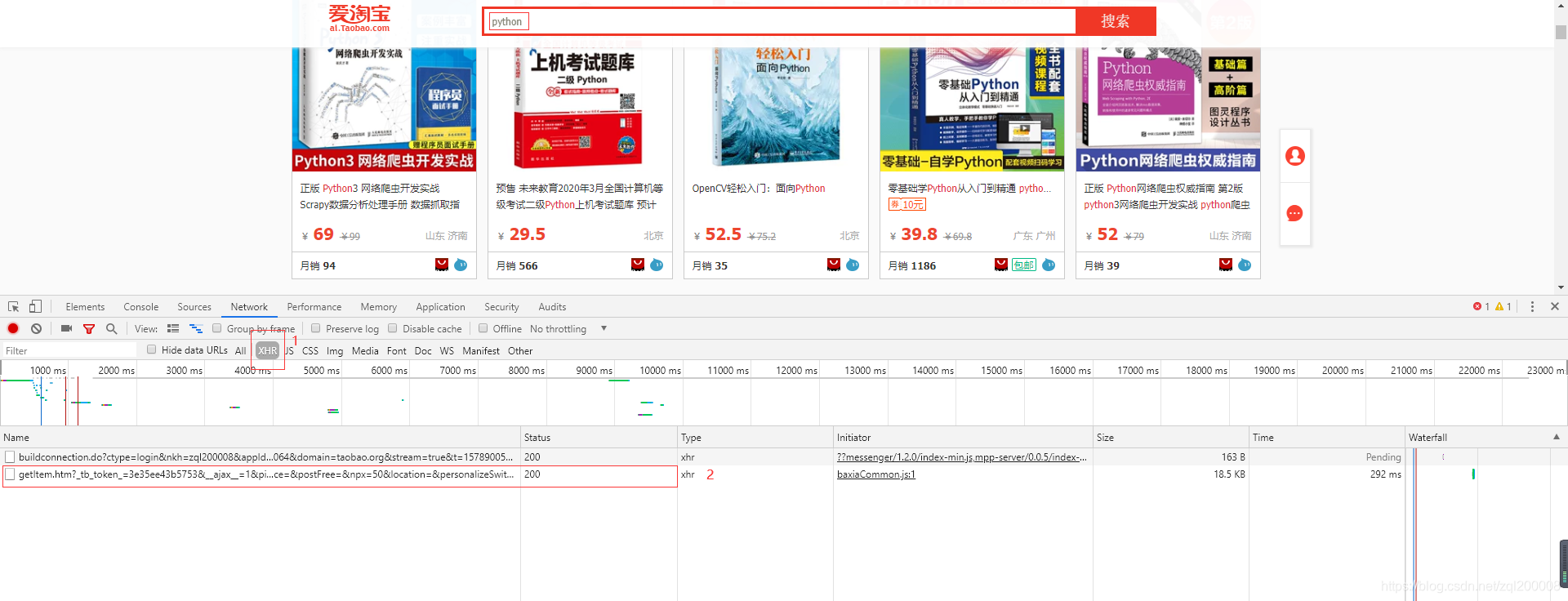 发现这些便是我们所需要的数据 发现这些便是我们所需要的数据 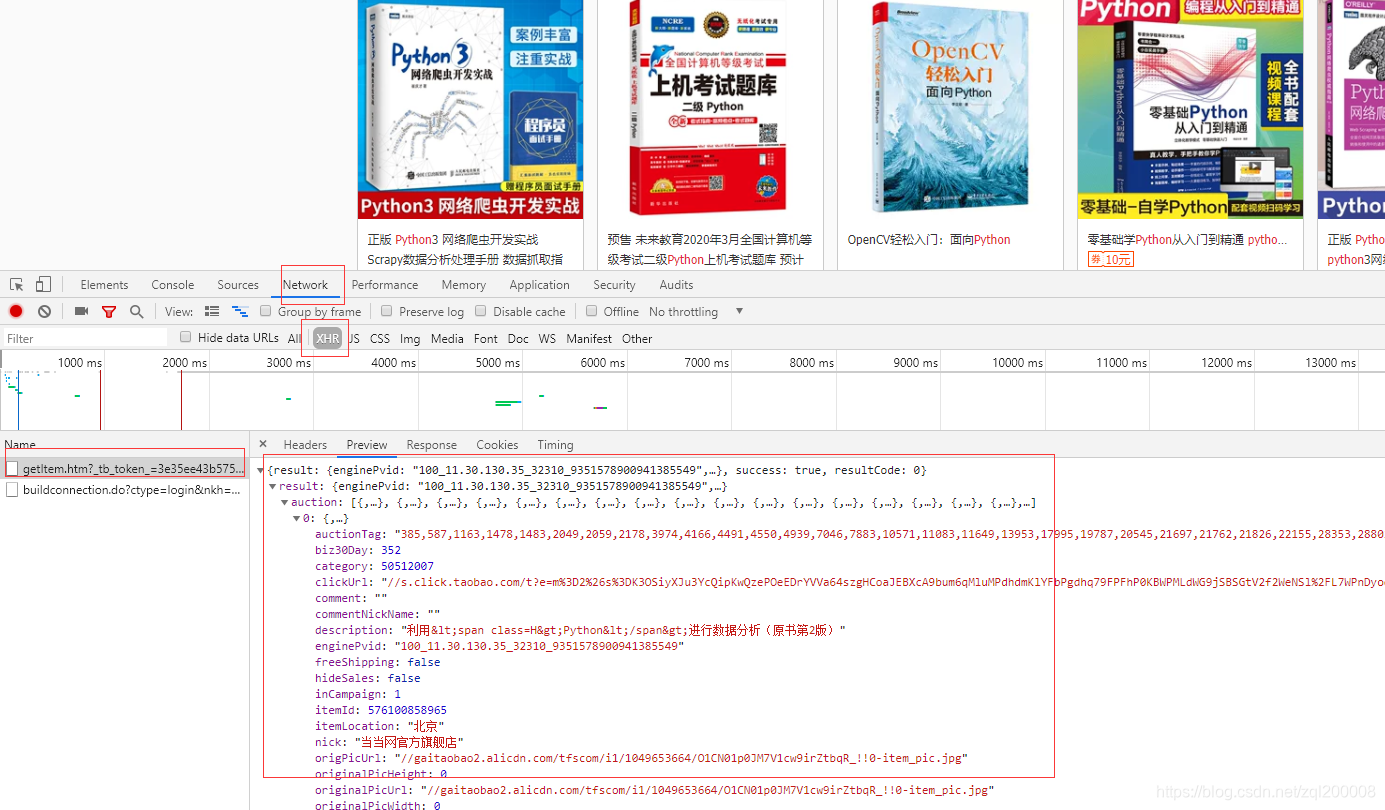 并找到了它循环的规律page所有我们只需用一个for循环就可以将所有的数据得到,再看到pagesize=60得知每页中有60个商品 并找到了它循环的规律page所有我们只需用一个for循环就可以将所有的数据得到,再看到pagesize=60得知每页中有60个商品 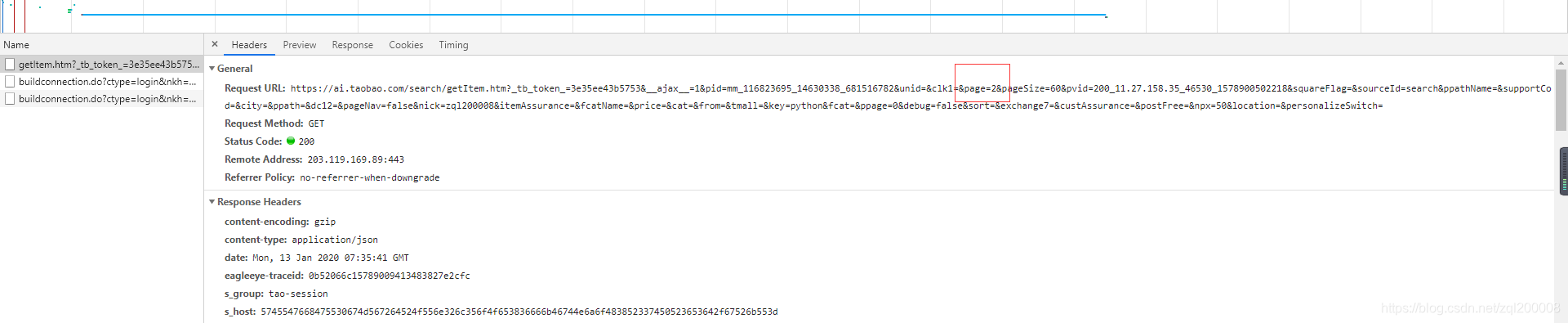
for i in range(0,6000,60): #共100页每页爬取数是60
url = 'https://ai.taobao.com/search/getItem.htm?_tb_token_=3e35ee43b5753&__ajax__=1&pid=mm_116823695_14630338_681516782&unid=&clk1=&page='+str(i)+'&pageSize=60&pvid=200_11.27.158.35_46530_1578900502218&squareFlag=&sourceId=search&ppathName=&supportCod=&city=&ppath=&dc12=&pageNav=false&nick=zql200008&itemAssurance=&fcatName=&price=&cat=&from=&tmall=&key=python&fcat=&ppage=0&debug=false&sort=&exchange7=&custAssurance=&postFree=&npx=50&location=&personalizeSwitch='
下面我们就开始编写代码: 先导入我们所需要的包
import requests
import time #控制爬取的速度
import random #同上
import csv #保存到CSV
淘宝跟其他网址一样都存在反爬虫所有我们爬取的速度不能太快,但同样也不能太慢因为它的cookie更新的时间很快这边的代码写完下一次就需要重新更改cookie
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
#这边的cookie需要自行更换
'cookie': 't=896dfc2c34e69edad53901df497fc083; cna=rLd3FqAYJBYCAd0Ga+uLfiuH; lgc=zql200008; tracknick=zql200008; tg=0; thw=cn; enc=bGtbz3DXeHvOjjATa5dkVuiLGr5CGbCCERhMM1SE9mKdTWWSoOegEfeubDb89QXqy9QVO1%2BurgqFfHnLv0NKsA%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; UM_distinctid=16f3584101b2ce-04669cbf5bc4a1-3a65420e-1fa400-16f3584101cbce; uc3=nk2=Gdl%2FLMzD6Ult&vt3=F8dByuqh4OaNl%2FeWsMk%3D&id2=UNGTq9IN%2FbKzXQ%3D%3D&lg2=UIHiLt3xD8xYTw%3D%3D; uc4=nk4=0%40GxDlHaa6W%2FymFIGyK%2FMbBtG23J4%3D&id4=0%40UgbrBRNaMDZe8204lMK1waahvzom; _cc_=UtASsssmfA%3D%3D; miid=122644171006844692; mt=ci=-1_0; __wpkreporterwid_=ce842df4-36b9-4f23-ba54-7a519a1c6273; _m_h5_tk=16bc179a7c251df60bafa5cc98737414_1578882763244; _m_h5_tk_enc=1a36cef7414f1e415bf4123e6facbdbb; cookie2=54f578b6ef1f77adefeed2d725c59438; v=0; _tb_token_=3e35ee43b5753; ctoken=fPp-cBcld5opog9X1PCHTVNT; CNZZDATA30076816=cnzz_eid%3D1418668747-1577156649-https%253A%252F%252Fai.taobao.com%252F%26ntime%3D1578888148; x5sec=7b2279656c6c6f7773746f6e653b32223a223634313366623336646339306436303462303566326137306432333838646233434b6e6b372f4146454f664834717a57693575516a77456144444d784e5449344e546b304f5455374d513d3d227d; JSESSIONID=B9F7D179F12AAB0971C1B4DF4146770C; uc1=cookie14=UoTbldrI5nWmcg%3D%3D; l=dBT-AJt4QQwOgWc3BOfahurza779ZIOb4sPzaNbMiICP9wf62-NVWZDMXX8BCnGVHsCyR3u14VQUBeYBqsxJe0h7X2uPI4kSndC..; isg=BAcHbmkyFYXWk5Lp2f8-aE9QlrteAtvucX9I_9n1Yhb6SCcK4dyIPrZO6kizoLNm'
}
response = requests.get(url,headers=headers)
time.sleep(random.randint(0,2)) #0~2秒爬取数据够爬取完数据
response.json() #查看爬取到的json数据
可以得到我们爬取的json数据如下,但是发现开头并不是我们想要的东西而是淘宝中最上方勾选的内容  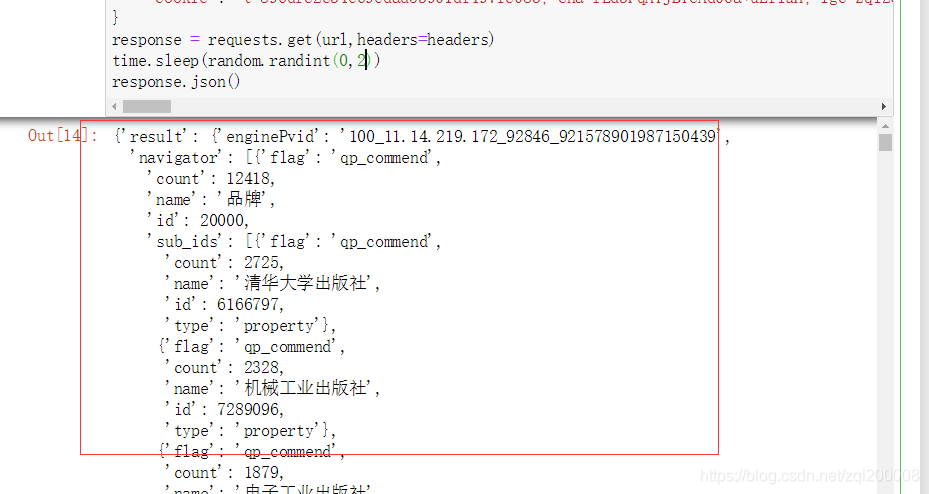 此时我们不要急继续往下查看json的内容发现下面出现的数据正是我们所想要的 此时我们不要急继续往下查看json的内容发现下面出现的数据正是我们所想要的 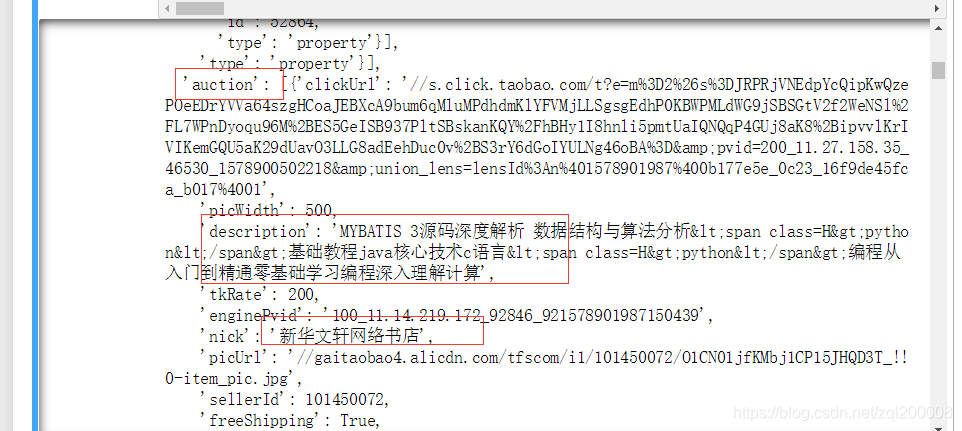 所有我们要将json中数据提取出来看json内容在result,auction下面所有我们编写一个for循环将它取出 所有我们要将json中数据提取出来看json内容在result,auction下面所有我们编写一个for循环将它取出
res = response.json()
for i in res['result']['auction']:
description = i['description'].replace(';span class=H;', '').replace(';/span;', '') #商品详细名 用replace出去杂质
nick = i['nick'] #书出处
try:
price = i['price'] #价格
except:
price = ''
realPrice = i['realPrice'] #现真实价格
itemLocation = i['itemLocation'] #地区
biz30Day = i['biz30Day'] #30天销量
print(description, tkRate, nick, price, realPrice, itemLocation, biz30Day)
这样我们就提取出所有我们想要的数据  最后我们需要保存到CSV中如下代码 最后我们需要保存到CSV中如下代码
with open('python.csv','a',encoding='utf-8',newline='')as file:
writer = csv.writer(file)
try:
writer.writerow(item)
except Exception as e:
print('writer error',e)
爬取的部分内容如下:  最后用函数将所有的代码结合起来,完整代码如下: 最后用函数将所有的代码结合起来,完整代码如下:
import requests
import time #控制爬取的速度过快会被反爬
import random #同上
import csv #存入CSV需要组件
#给CSV添加头
with open('python.csv','a',encoding='gbk',newline='')as file:
writer = csv.writer(file)
writer.writerow(['description','tkRate','nick','price','realPrice','itemLocation','biz30Day'])
def csv_write(item):
with open('python.csv','a',encoding='gbk',newline='')as file: #打开python文件写入内容newline=''不空行写入
writer = csv.writer(file)
try:
writer.writerow(item)
except Exception as e:
print('writer error',e)
def start_request(url_):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'cookie': 't=896dfc2c34e69edad53901df497fc083; cna=rLd3FqAYJBYCAd0Ga+uLfiuH; lgc=zql200008; tracknick=zql200008; tg=0; thw=cn; enc=bGtbz3DXeHvOjjATa5dkVuiLGr5CGbCCERhMM1SE9mKdTWWSoOegEfeubDb89QXqy9QVO1%2BurgqFfHnLv0NKsA%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; UM_distinctid=16f3584101b2ce-04669cbf5bc4a1-3a65420e-1fa400-16f3584101cbce; uc3=nk2=Gdl%2FLMzD6Ult&vt3=F8dByuqh4OaNl%2FeWsMk%3D&id2=UNGTq9IN%2FbKzXQ%3D%3D&lg2=UIHiLt3xD8xYTw%3D%3D; uc4=nk4=0%40GxDlHaa6W%2FymFIGyK%2FMbBtG23J4%3D&id4=0%40UgbrBRNaMDZe8204lMK1waahvzom; _cc_=UtASsssmfA%3D%3D; miid=122644171006844692; mt=ci=-1_0; __wpkreporterwid_=ce842df4-36b9-4f23-ba54-7a519a1c6273; cookie2=54f578b6ef1f77adefeed2d725c59438; v=0; _tb_token_=3e35ee43b5753; ctoken=fPp-cBcld5opog9X1PCHTVNT; _m_h5_tk=4faaf40f05b72b40532bd80f4439ed79_1578904038298; _m_h5_tk_enc=5a0ac67fe7c8a9019b19fd3020a164e4; CNZZDATA30076816=cnzz_eid%3D1418668747-1577156649-https%253A%252F%252Fai.taobao.com%252F%26ntime%3D1578898948; uc1=cookie14=UoTbldsEfRYflw%3D%3D; JSESSIONID=315ABD192CB01490A20C80F97F5FD5BD; x5sec=7b2279656c6c6f7773746f6e653b32223a2263303937643733303238656132366237383064393233343938316161306362314349765338504146454a44746e36616b79767a7a7377456144444d784e5449344e546b304f5455374d513d3d227d; l=dBT-AJt4QQwOgAGvBOCwIJXfbM7TpIRAguu3zoa6i_5Bl1p4GHQOov35Bep6cjWfGB8B4VsrWwy9-etksMp-2bZt84WGnxDc.; isg=BOTkVs8FZktThJFgvi4NscCxteJZcwjnjj6Ltv4FSq8QqYRzJoz0d_IHaUEUcUA_'
}
response = requests.get(url_,headers=headers)
time.sleep(random.randint(0,2)) #隔0~2秒爬取一次
return response
def parse_detail(list_url):
res = start_request(list_url) #获取编写headers的函数赋值到此函数
res_ = res.json() #查看json
for i in res_['result']['auction']: #循环出json中需要的内容
description = i['description'].replace(';span class=H;', '').replace(';/span;', '') #商品详细名
tkRate = i['tkRate']
nick = i['nick'] #书出处
try:
price = i['price'] #价格
except:
price = ''
realPrice = i['realPrice'] #最终价格
itemLocation = i['itemLocation'] #地区
biz30Day = i['biz30Day'] #30天的销量
item = [description, tkRate, nick, price, realPrice, itemLocation, biz30Day]
csv_write(item)
for i in range(0,6001,60):
url = 'https://ai.taobao.com/search/getItem.htm?_tb_token_=3e35ee43b5753&__ajax__=1&pid=mm_116823695_14630338_681516782&unid=&clk1=&page='+str(i)+'&pageSize=60&pvid=200_11.24.49.55_345_1578902493489&squareFlag=&sourceId=search&ppathName=&supportCod=&city=&ppath=&dc12=&pageNav=false&nick=zql200008&itemAssurance=&fcatName=&price=&cat=&from=&tmall=&key=python&fcat=&ppage=0&debug=false&sort=&exchange7=&custAssurance=&postFree=&npx=50&location=&personalizeSwitch='
parse_detail(url)
|