使用python unittest从零构建web应用的自动化测试用例 |
您所在的位置:网站首页 › 用python搭建数据库 › 使用python unittest从零构建web应用的自动化测试用例 |
使用python unittest从零构建web应用的自动化测试用例
|
文章目录
必要性使用pycharm搭建unittest框架selenium下载web driverweb driver的基本使用driver 定位元素driver使用事件处理下拉框处理复选框
sshftp数据库sqlserveroracle安装使用
mongodb
excelpycurl
必要性
大部分团队起始对于要不要投入资源进行UI自动化测试的开发都是持怀疑态度,特别是小型公司,觉得投入的产出比不成正比。 我自己的判断是基于下面几个考虑(基于小软件企业,中大型的另说): 做产品的公司可以考虑,做项目(外包)的公司一般不考虑,除非已经将一些组件抽象的非常high level,相对固定了。产品中相对稳定的固定流程,在整个团队中消耗了较多测试人力的流程可以考虑使用UI测试化来替代。产品最起码还有2-3年或者更长的生命周期,否则也不考虑。投入的测试人力基本上是属于流程化作业。从某个点开始做起,不要一开始就说要覆盖多少多少业务。 使用pycharm搭建unittest框架pycharm环境默认支持unittest项目的创建。 创建一个python项目在项目上右键创建一个python文件,选择Python unit test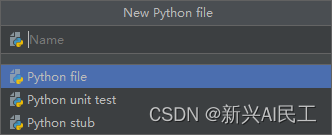 创建出来的文件为:
import unittest
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(True, False)
if __name__ == '__main__':
unittest.main()
- MytestCase为测试类
- test_something为测试用例函数
- self.assertEqual为unittest提供的断言方法,判断两个参数是否相等,自动化测试的逻辑就是判断理论值和实际值是否相同,来判断用例是否通过。 创建出来的文件为:
import unittest
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(True, False)
if __name__ == '__main__':
unittest.main()
- MytestCase为测试类
- test_something为测试用例函数
- self.assertEqual为unittest提供的断言方法,判断两个参数是否相等,自动化测试的逻辑就是判断理论值和实际值是否相同,来判断用例是否通过。
在运行配置里增加一项: 点击运行即可。 如果是上例,结果为用例不通过,结果为false 结果就变成: selenium现在是一套完整的框架,我使用到的就是web driver这个模块,实际上我理解就是一个爬虫引擎: 获取页面解析DOM,可以通过get_element等一系列函数获取DOM中的元素事件驱动,可以对DOM上的一些组件事件进行点击。driver现在支持多种浏览器,包括edge,firefox,chrome等。 我自己用到的是chrome。 下载web driver下载地址: https://chromedriver.storage.googleapis.com/index.html 找到所需浏览器的版本,版本号找一个相近的即可。 web driver的基本使用 from selenium import webdriver driver = webdriver.Chrome(executable_path=‘d:\xxxx.exe’) # 确定driver的地址 driver.get('http://localhost:8080') # 获取http地址 driver.maximize_window() # 窗口最大化 driver.implicitly_wait(10) # 等待时长上面代码中最后一句设置等待时长是很关键的,因为因为网络传输和DOM处理加载都是需要时间的,可能自动化代码执行的时候,某个DOM元素还没有被加载好,driver就会有获取不到的可能,这个数字就是表名在多少秒之内进行等待DOM完成构建。 也可以通过显式的等待来处理: import time driver.get(xxxx) time.sleep(10) driver.find_element() driver 定位元素selenium获取元素可以根据DOM元素的ID,name,class或者精确的XPATH来进行定位。 当然最好的方式是使用ID,但是需要在开发的时候对对应的元素进行“埋点”处理。 在selenium3的时候,定位元素是通过 element = find_element_by_id('xxx') element = find_element_by_name('xxx') element = find_element_by_xpath('xxx')来实现的。 而在selenium4的时候,这几个函数整合成一个函数了: find_element 但是还是需要通过指定参数来确认定位方式: from selenium.webdriver.common.by import By element = find_element(by=By.ID, value='xxx') element = find_element(by=By.NAME, value='xxx') element = find_element(by=By.XPATH, value='xxx') driver使用事件 文本输入 driver.find_element(by=By.XPATH, value=‘xxx’).send_keys('abcde') # 或者 element = find_element(by=By.XPATH, value='xxx') element.send_keys('abcde') 鼠标左键 driver.find_element(by=By.XPATH, value=‘xxx’).click('abcde') # 或者 element = find_element(by=By.XPATH, value='xxx') element.click('abcde') 鼠标右键 from selenium.webdriver.common import action_chains element = driver.find_element(by=By.XPATH, value=‘xxx’) ac_1 = action_chains.ActionChains(driver) ac_1.context_click(element).perform() 下拉框 下拉框实际上就是两次点击 处理下拉框处理下拉框实际上就是两次点击,第一次点击是下拉框组件,第二次点击是其中的内容 driver.find_element(by=By.XPATH, value='dropbox_file').click() # 等待一下 time.sleep(3) # 选择文本 driver.find_element(by=By.XPATH, value='dropbox_txt').click() 处理复选框复选框上也是一个点击动作: driver.find_element(by=By.XPATH, value='item_checkbox').click()自动化框架的基本逻辑就是: 从界面上获取相应组件的信息,然后把这些信息和数据库,分布在各个地方的文件进行比对,如果比对的上,那么就是用例通过。那么在搭建一个完整的用例系统里,就必须用到python的ssh,ftp,各种数据库的库函数。我这里用到了下面几种,我理解基本覆盖了一个web系统能用到的基本组件。ssh,对应的是paramiko库ftp,对应的是ftplib库sqlserver,对应的是pymssql库oracle,对应的是cx_oracle库excel,对应的是openpyxl库seaweed,对应的是pycurl库,因为seaweed对外提供了访问数据的http服务。mongodb,对应的是pymongo库。 ssh我使用的库是paramiko库: 第一步就是初始化ssh连接: import paramiko ssh_conn = paramiko.SSHClient() # 设置信任远程机器,允许访问 # 设置远程服务器没有在know_hosts文件中记录时的应对策略。目前支持三种策略: # AutoAddPolicy 自动添加主机名及主机密钥到本地HostKeys对象,不依赖load_system_host_key的配置。即新建立ssh连接时不需要再输入yes或no进行确认 # WarningPolicy 用于记录一个未知的主机密钥的python警告。并接受,功能上和AutoAddPolicy类似,但是会提示是新连接 # RejectPolicy 自动拒绝未知的主机名和密钥,依赖load_system_host_key的配置。此为默认选项 ssh_conn.set_missing_host_key_policy(paramiko.AutoAddPolicy()) 进行连接 try: # ssh self.ssh_conn.connect(config.ssh_ip, config.ssh_port, config.ssh_username, config.ssh_pwd) # sftp,如果使用sftp协议上传的时候可以使用 transport = paramiko.Transport(config.ssh_ip, config.ssh_port) # 这里一定要使用username=和password=,因为第一个参数是hostkey transport.connect(username=config.ssh_username, password=config.ssh_pwd) self.sftp_conn = paramiko.SFTPClient.from_transport(transport) except: print("Failed to connect to remote server") 通过连接对象执行shell命令,我没有用sftp,用的是ftp协议。 shell_cmd = "mv /home/x.txt /home/y.txt" stdin, stdout, stderr = ssh_conn.exec_command(shell_cmd ) 通过stdout获得执行情况 stdout实际上是一个输出流,就是把服务器上执行shell命令的输出作为字节流输出: print(stdout.read())输出为:b’abc\n’ ftpftp使用的是ftplib库,是python自带的库。 操作和ssh类似: 初始化和连接,多了一个登录操作 from ftplib import FTP conn = FTP() conn.connect(config.ftp_ip, config.ftp_prot) conn.login(config.ftp_user, config.ftp_pwd) 上传文件: buff_size = 1024 * 1024 * 1024 # 默认大小 fp = open(local_file_path, 'rb') try: conn.storbinary('STOR %s' % remote_file_path, fp, buff_size) except Exception as e: print('发送文件error:{}'.format(e))相当于是要打开本地文件,然后读取出来,以字节流的方式向远端的ftp服务器写入。 下载文件,和上传类似 # 切换到目标目录,相当于cd命令 conn.cwd(path_name) tmp_file = open('./temp/temp.txt', 'wb') conn.retrbinary('RETR ' + remote_file_name, tmp_file.write) tmp_file.close()相当于打开一个本地文件,以字节流的方式从远端把文件内容读写到本地文件中。 上传和下载文件夹,这个库中没有直接上传文件夹的api,必须自己写递归,把文件夹中的子文件夹和文件都一次上传或下载。 下面是一个递归上传的函数,下载的类似 def upload_data_dir(self, local_file_path, remote_file_path): files = os.listdir(local_file_path) if remote_file_path: try: self.conn.mkd(remote_file_path) except Exception as e: pass finally: self.conn.cwd(remote_file_path) for file_name in files: print(local_file_path + r'/{}'.format(file_name)) if os.path.isfile(local_file_path + r'/{}'.format(file_name)): self.upload_file_indir(local_file_path, file_name) elif os.path.isdir(local_file_path + r'/{}'.format(file_name)): try: self.conn.mkd(file_name) except Exception as e: pass finally: local_file_path = "%s/%s" % (local_file_path, file_name) remote_file_path = "%s/%s" % (remote_file_path, file_name) self.upload_data_dir(local_file_path, remote_file_path) def upload_file_indir(self, path, file_name, target_dir=None, callback=None): # 记录当前 ftp 路径 cur_dir = self.conn.pwd() if target_dir: try: self.conn.mkd(target_dir) except: pass finally: self.conn.cwd(os.path.join(cur_dir.title(), target_dir)) file = open(os.path.join(path, file_name), 'rb') # file to send self.conn.storbinary('STOR %s' % file_name, file, callback=callback) # send the file file.close() # close file self.conn.cwd(cur_dir) 删除文件和文件夹 try: self.conn.delete(file_name) time.sleep(3) except Exception as e: print(e)同样的,删除文件夹也需要自己写递归,删除文件夹的命令为: conn.rmd("%s/%s" % (remote_dir, dir_name)如果删除的这个文件夹不为空的话,是会失败的,所以需要先递归删除文件夹中的所有内容,最后删除文件夹 最关键的一点,所有的上传,下载,删除都是一个异步操作,也就是说调用之后,ftplib库会直接返回成功,然后再去删除。所以函数执行成功之后,不一定是已经将文件上传了的。 数据库 sqlserversqlserver用的是pymssql库,这个库安装的时候需要安装基础的visual studio运行环境,否则会安装失败。 使用起来比较简单,我暂时只使用了查询功能。 连接: import pymssql self.conn = pymssql.connect(host='xxxx', # 这里的host='_'可以用本机ip或ip+端口号 server="master", # 本地服务器 port="1433", # TCP端口 user="xx", password="xxxx", database="xxxx", charset="GBK" # 这里设置全局的GBK,如果设置的是UTF—8需要将数据库默认的GBK转化成UTF-8 ) if self.conn: print('连接数据库成功!') # 测试是否连接上 else: print('未连接') # 测试是否连接上 查询: # 查询语句 cursor = self.conn.cursor() # 使用cursor()方法获取操作游标 sql_select = "SELECT * FROM " + table_name + " where colName = \'" \ + queryValue + "\'" # 数据库查询语句 cursor.execute(sql_select) # 执行语句 results = cursor.fetchall() # 获取所有记录列表 for result in results: dosomething() oracle 安装我使用的是cx_oracle库,这个库底层是调用的oci的库,所以最好本地安装了pl-sql这样的软件。或者单独下载oracle的客户端运行环境进行安装,然后把安装目录中的一些dll(windows的开发环境)拷贝到python环境的根目录下: 使用的是pymongo库 连接 import pymongo mongo_url = 'mongodb://ip:27017/' self.conn = pymongo.MongoClient(mongo_url) self.db = self.conn[config.mongo_db_name] self.config_table = self.db['collectionName'] 查询 dblist = self.config_table.find({'key': keyValue}) 更新 self.config_table.update_one({'key': key}, {'$set': {'value': value}}) excel使用的是openpyxl 库 from openpyxl import load_workbook wb = load_workbook(file_name) ws = wb.active # I2就是单元格的索引 print(ws['I2'].value)还有很多操作,我在用例里没有用到,就不一一介绍了,网上内容一搜一大把。 pycurl相当于执行curl命令的库,我们系统中使用到了seaweed,seaweed提供了http服务,用于上传文件: 访问ip:port/dir/assign地址可以获得一个id使用这个ID,通过另外一个url上传一个文件。使用pycurl实现第一步: def write_func_for_file_id(self, buffer): self.result = eval(buffer) self.file_id_url = 'http://' + self.result['url'] + '/' + self.result['fid'] self.file_id = self.result['fid'] c = pycurl.Curl() c.setopt(pycurl.URL, "http://ip:port/dir/assign") ## 在opt中设置pycurl.WRITEFUNCTION,需要提供一个回调函数,这个函数就负责处理http返回的response c.setopt(pycurl.WRITEFUNCTION, write_func_for_file_id) c.setopt(pycurl.FOLLOWLOCATION, 1) c.perform()pycurl实现第二步: file = open(path) c = pycurl.Curl() c.setopt(pycurl.URL, self.file_id_url) # opt设置pycurl.UPLOAD c.setopt(pycurl.UPLOAD, 1) # opt设置pycurl.READDATA c.setopt(pycurl.READDATA, file) # 同样需要一个回调,但是这里我不需要处理response c.setopt(pycurl.WRITEFUNCTION, self.write_func_for_upload) c.setopt(pycurl.FOLLOWLOCATION, 1) c.perform() file.close() |
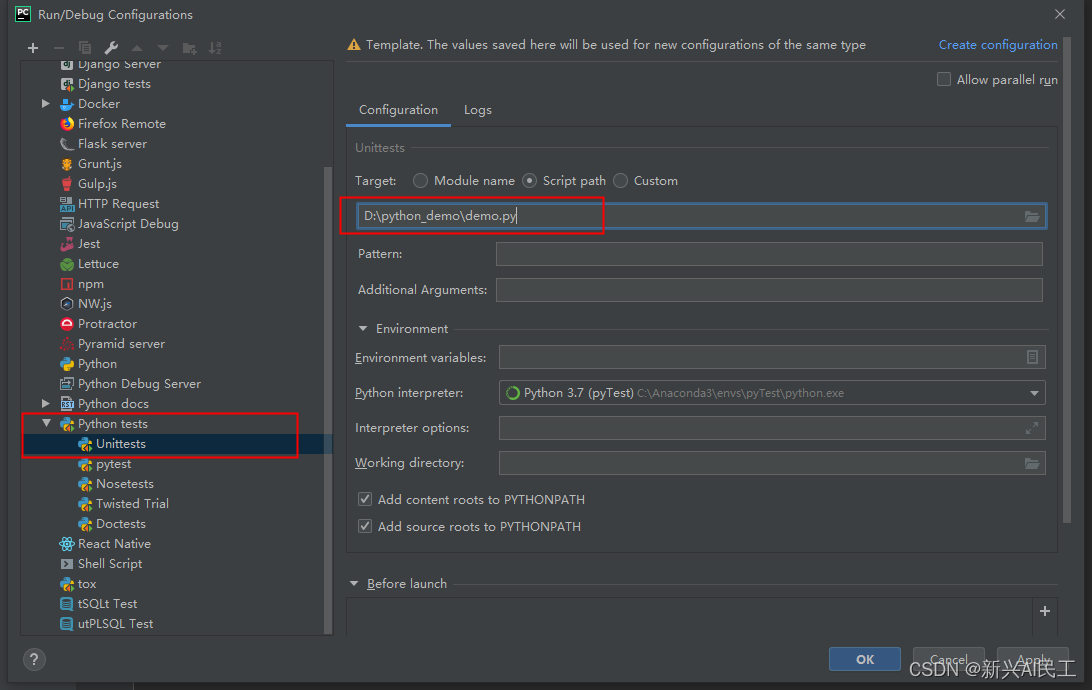
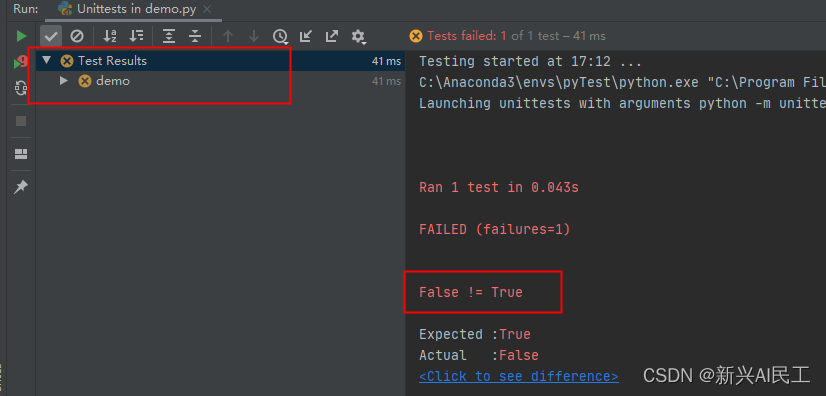 如果把断言改成:
如果把断言改成: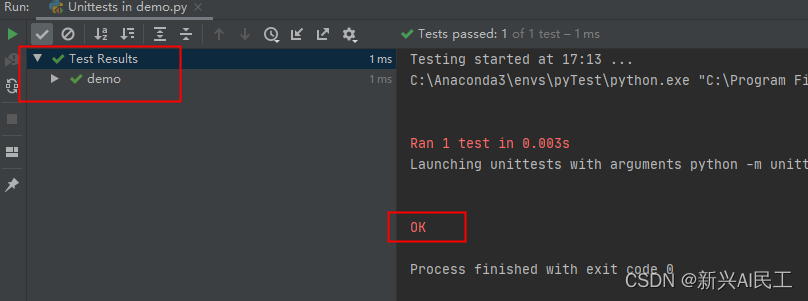
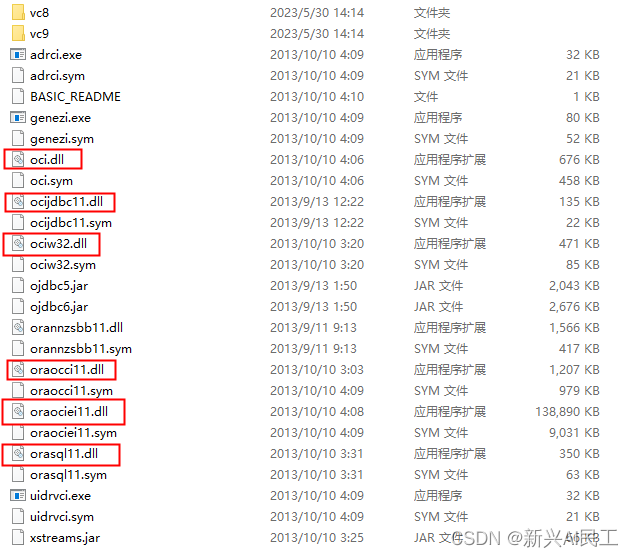
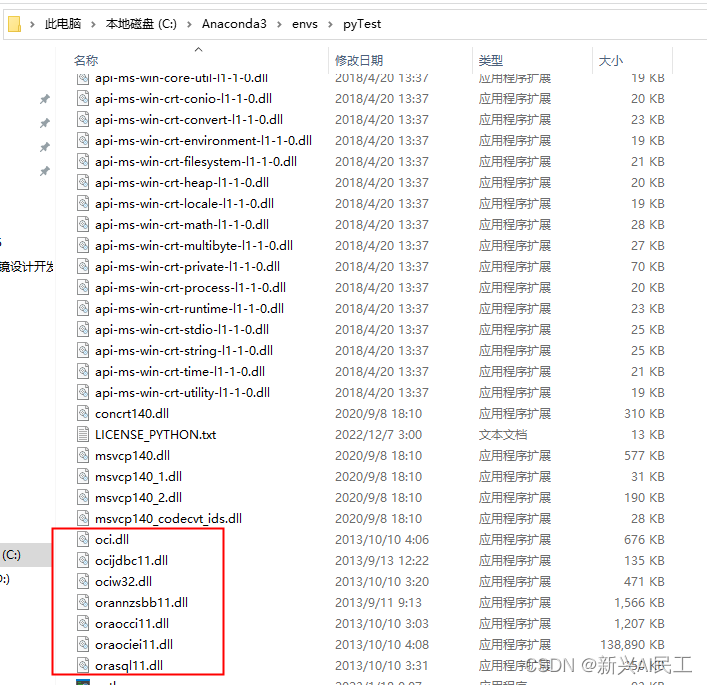 我用的是anaconda工具。
我用的是anaconda工具。【本文地址】
今日新闻 |
推荐新闻 |