flink学习(scala版) |
您所在的位置:网站首页 › 生桩的种植方法 › flink学习(scala版) |
flink学习(scala版)
|
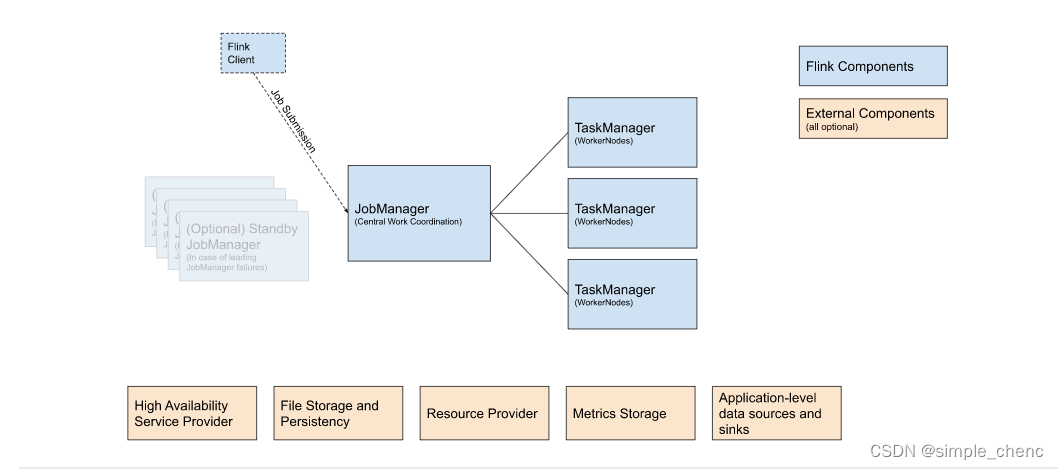
本次介绍flink的部署模式 当我们在本地执行代码的时候,其实是先模拟启动一个Flink集群,然后将作业提交到集群上,创建好要执行的任务等待数据输入。 那么flink内部是怎样进行工作调度的呢? 这里需要提到Flink中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger。所以JobManager就是Flink集群里的“领导者”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。这里的TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,如图 Flink Client将批处理或流式应用程序编译成数据流图,然后将其提交给 JobManagerJobManagerJobManager 是 Flink 的中心工作协调组件的名称。它具有针对不同资源提供者的实现,这些资源提供者在高可用性、资源分配行为和支持的作业提交模式方面有所不同。TaskManagerTaskManager 是实际执行 Flink 作业工作的服务。 3.1 快速启动一个Flink集群 3.1.1 环境配置 Flink是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行Flink安装部署的学习时,需要准备3台Linux机器。具体要求如下: ⚫系统环境为CentOS 7.5版本。 ⚫安装Java8。 ⚫安装Hadoop集群(我的是3.1.3)。 ⚫配置集群节点服务器间时间同步以及免密登录,关闭防火墙。 本书中三台服务器的具体设置如下: ⚫节点服务器1,IP地址为192.168.42.102,主机名为hadoop102。 ⚫节点服务器2,IP地址为192.168.42.103,主机名为hadoop103。 ⚫节点服务器3,IP地址为192.168.42.104,主机名为hadoop104。 注意:服务器ip根据自己机器的真实ip设定 3.1.2 本地启动 最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。 具体安装步骤如下: 1. 下载安装包 进入Flink官网,下载1.13.0版本安装包flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对应scala版本为scala2.12的安装包。 2. 解压 在hadoop102节点服务器上创建安装目录/opt/module,将flink安装包放在该目录下,并执行解压命令,解压至当前目录。 tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/3. 启动 进入解压后的目录,执行启动命令,并查看进程。 cd flink-1.13.0/&&bin/start-cluster.sh # 等待启动完毕,jps查看进程 jps4. 访问Web UI 启动成功后,访问http://hadoop102:8081,可以对flink集群和任务进行监控管理。 5. 关闭集群 如果想要让Flink集群停止运行,可以执行以下命令: bin/stop-cluster.sh3.1.3 集群启动 单个节点本地启动很简单,如果想要扩展成集群,其实启动命令是不变的,主要是需要指定节点之间的主从关系。 Flink是典型的Master-Slave架构的分布式数据处理框架,其中Master角色对应着JobManager,Slave角色则对应TaskManager。我们对三台节点服务器的角色分配如表所示。
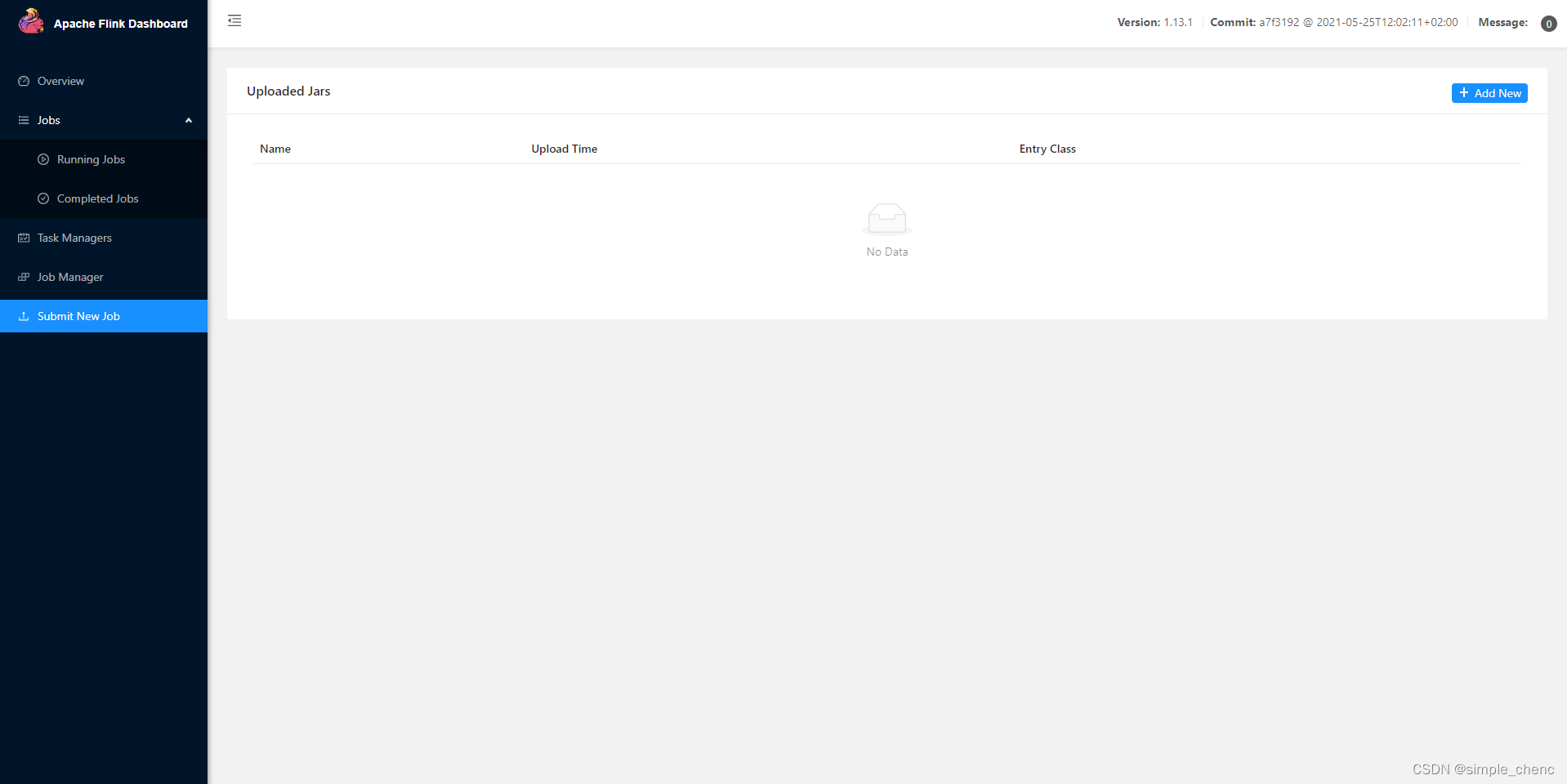
具体安装部署步骤如下: 1. 下载并解压安装包具体操作与上节相同。 2. 修改集群配置 (1)进入conf目录下,修改flink-conf.yaml文件,修改jobmanager.rpc.address参数为hadoop102,如下所示: # JobManager节点地址. jobmanager.rpc.address: hadoop102这就指定了hadoop102节点服务器为JobManager节点。 (2)修改workers文件,将另外两台节点服务器添加为本Flink集群的TaskManager节点,具体修改如下: $ vim workers hadoop103 hadoop104这样就指定了hadoop103和hadoop104为TaskManager节点。 (3)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下: ⚫jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。 ⚫taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。 ⚫taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的slots数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓slots就是TaskManager中具体运行一个任务所分配的计算资源。 ⚫parallelism.default:Flink任务执行的默认并行度配置,优先级低于代码中进行的并行度配置和任务提交时使用参数进行的并行度数量配置。 3. 将安装目录同步到其他节点 $ scp -r /opt/module/flink-1.13.0 atguigu@hadoop103:/opt/module $ scp -r /opt/module/flink-1.13.0 atguigu@hadoop104:/opt/module4. 启动集群 (1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群: $ bin/start-cluster.sh(2)jps查看三个节点的进程情况(如下): # 主节点 14367 Jps 16859 StandaloneSessionClusterEntrypoint # workers节点 11254 Jps 11397 TaskManagerRunner5. 访问Web UI 启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理 这里可以明显看到,当前集群的TaskManager数量为2;由于默认每个TaskManager的slots数量为1,所以总slots数和可用slots数都为2。 3.1.4 向集群提交作业 在上,我们已经编写了词频统计的批处理和流处理的示例程序,并在开发环境的模拟集群上做了运行测试。现在既然已经有了真正的集群环境,那接下来我们就要把作业提交上去执行了。 以流处理的程序为例,演示如何将任务提交到集群中进行执行。具体步骤如下。 1. 程序打包 (1)为方便自定义结构和定制依赖,我们可以引入插件maven-assembly-plugin进行打包。在FlinkTutorial项目的pom.xml文件中添加打包插件的配置,具体如下: org.apache.maven.plugins maven-assembly-plugin 3.0.0 jar-with-dependencies make-assembly package single( 2)插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。 打包完成后,在target目录下即可找到所需jar包,jar包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar和FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以此处使用FlinkTutorial-1.0-SNAPSHOT.jar。 2. 在WebUI上提交作业 (1)任务打包完成后,打开Flink的WEB UI页面,在右侧导航栏点击“SubmitNewJob”,然后点击按钮“+AddNew”,选择要上传运行的jar包,如图所示。
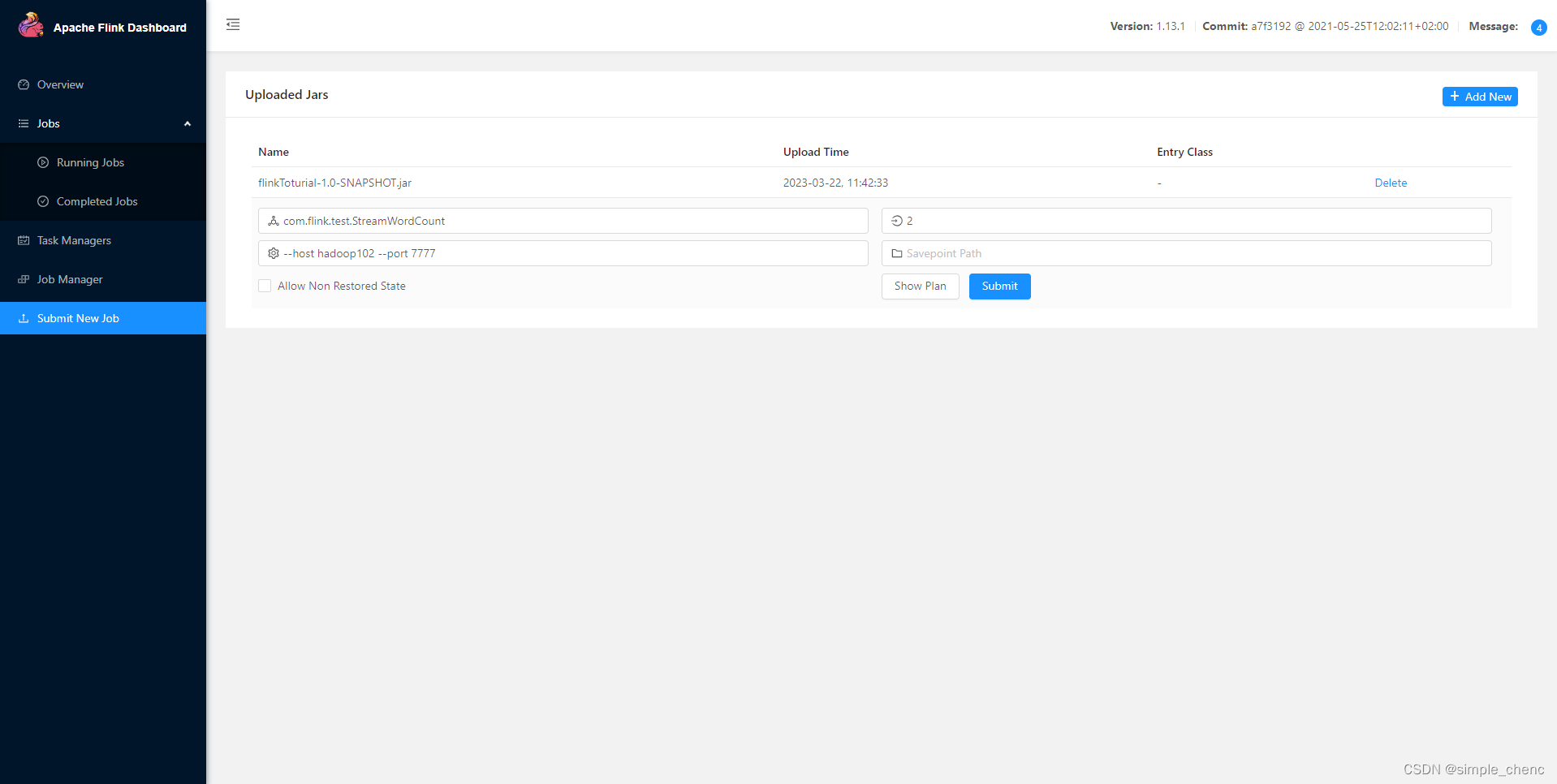
(2)上传完成后,点击该jar包,出现任务配置页面,进行相应配置。 主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如图,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
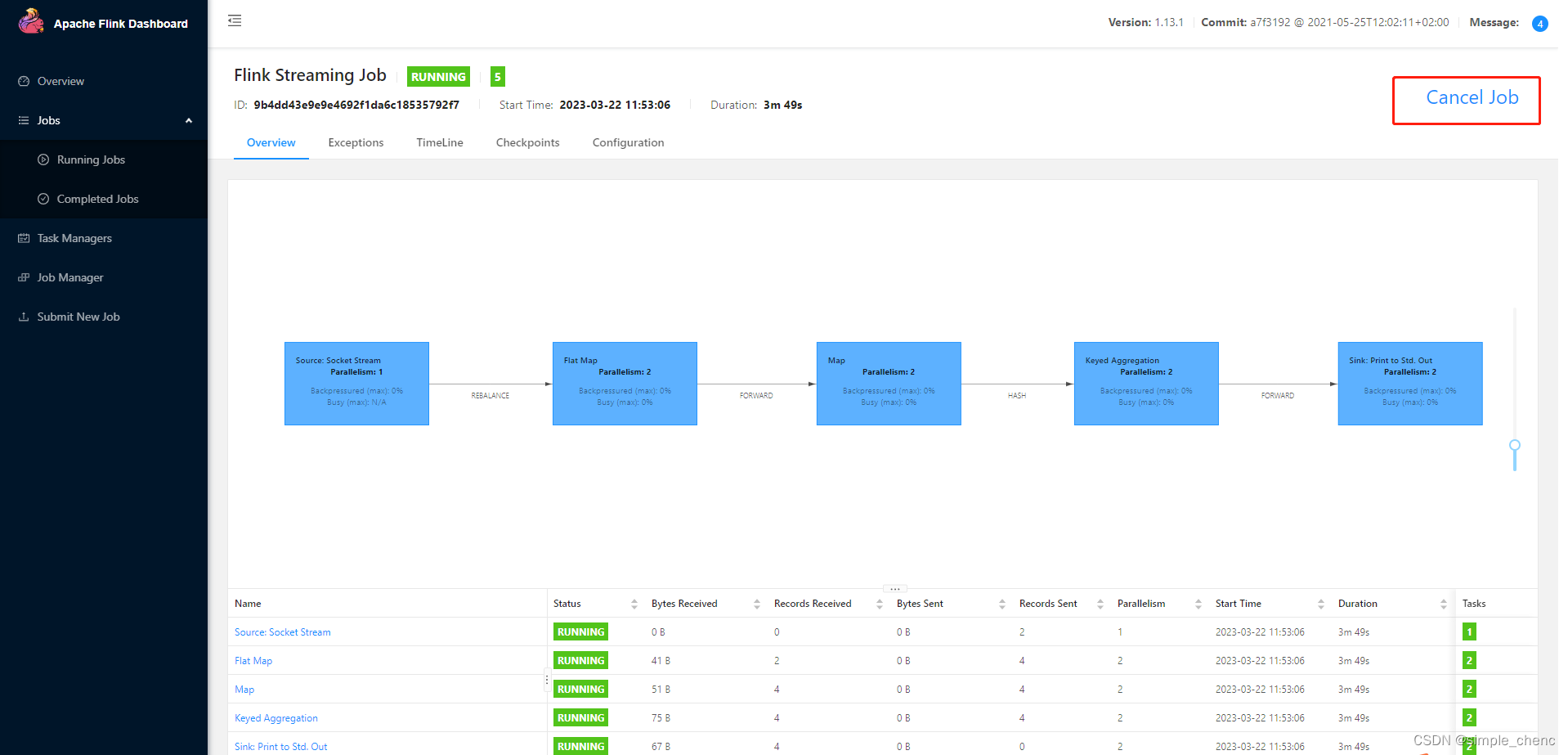
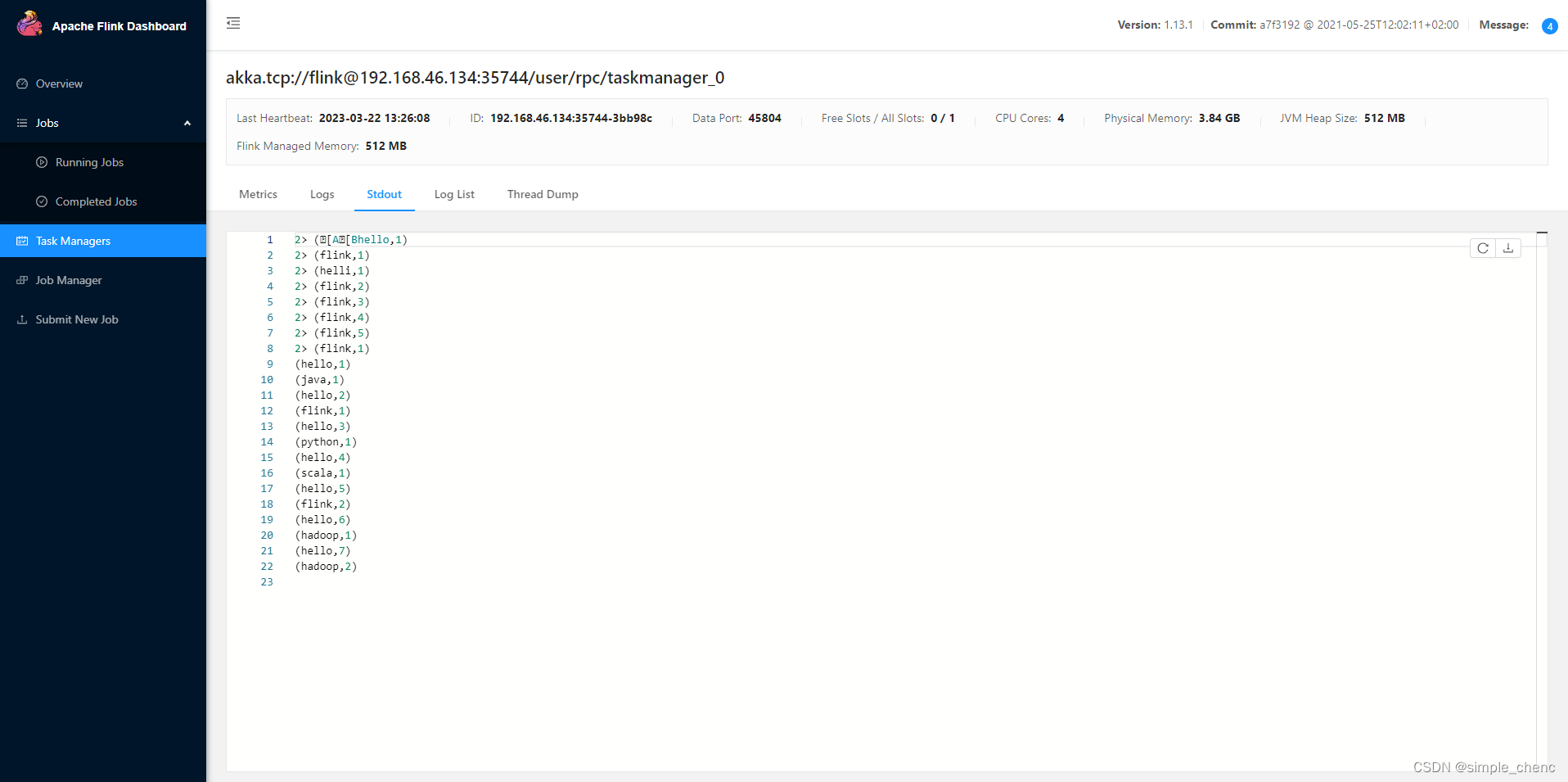
注意:提交任务之前,要先在hadoop102节点启动nc -lk 7777 (4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行 3. 命令行提交作业 除了通过WEB UI界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,可以先把jar包直接上传到目录flink-1.13.0下 (1)首先需要启动集群。 (2)在hadoop102中执行以下命令启动netcat nc -lk 7777 (3)进入到Flink的安装路径下,在命令行使用flink run命令提交作业。 ./bin/flink run -m hadoop102:8081 -c com.flink.test.StreamWordCount ./flinkToturial-1.0-SNAPSHOT.jar --host hadoop102 --port 7777这里的参数–m指定了提交到的JobManager,-c指定了入口类。并且制定了数据输入的host和port (4)在浏览器中打开Web UI,http://hadoop102:8081查看应用执行情况,用netcat输入数据,可以在TaskManager的标准输出(Stdout)看到对应的统计结果。
以上就是flink启动集群和提交任务的过程。 如有疑问,欢迎评论,如果帮到你,就点赞关注一下,手动blingbling。。。。。。 |

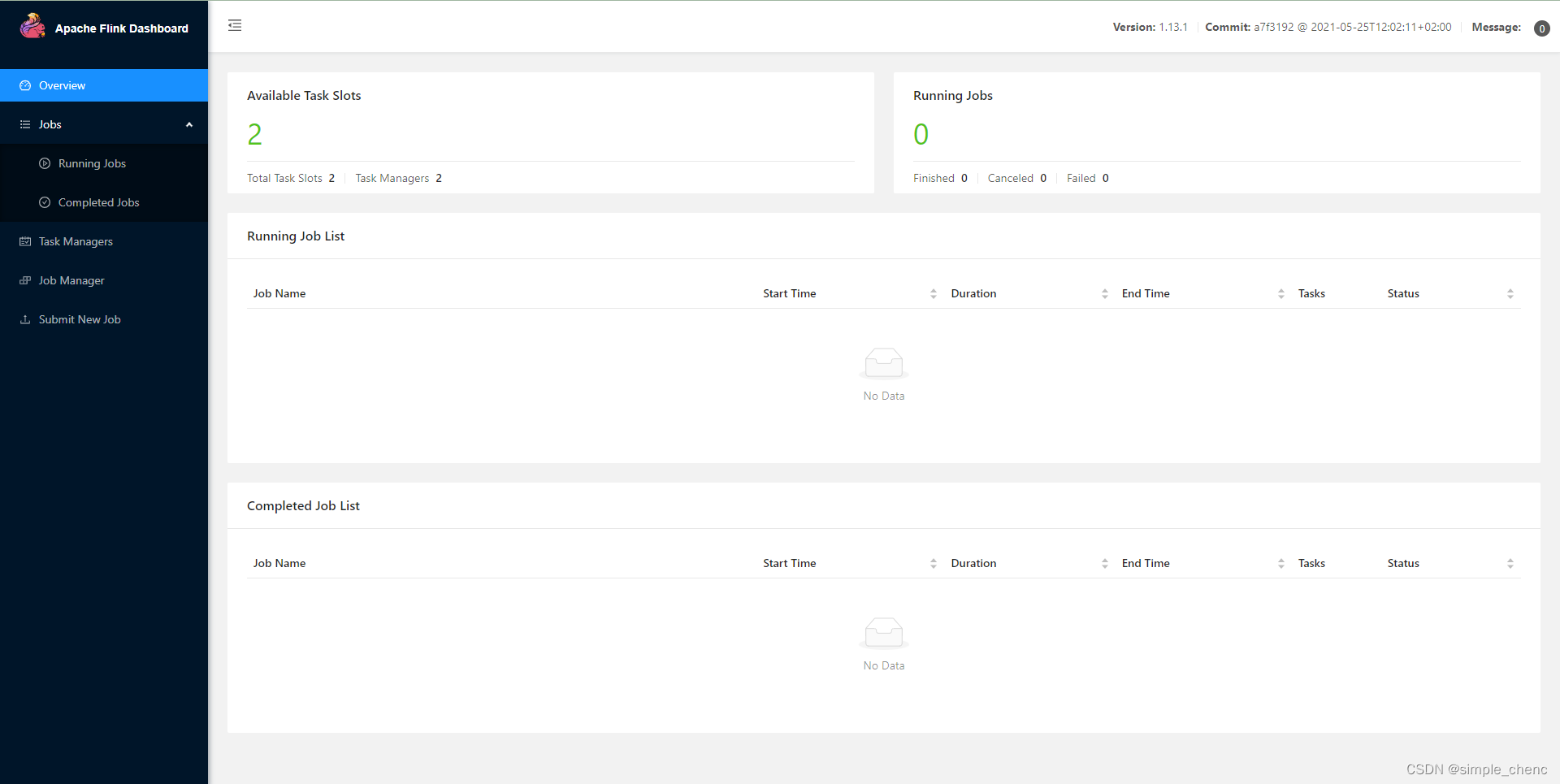

 (3)任务提交成功之后,可点击左侧导航栏的“RunningJobs”查看程序运行列表情况,如图所示。
(3)任务提交成功之后,可点击左侧导航栏的“RunningJobs”查看程序运行列表情况,如图所示。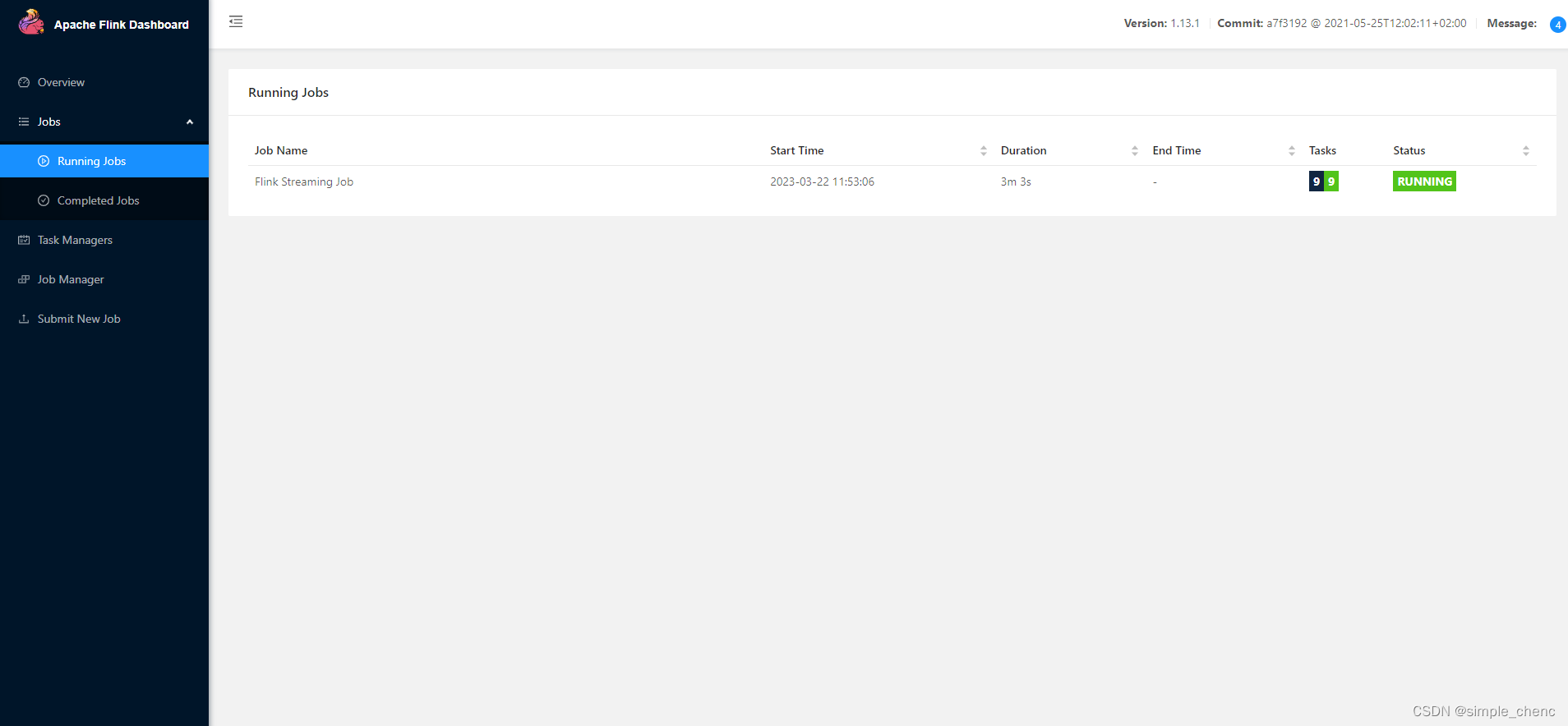
【本文地址】
今日新闻 |
推荐新闻 |