Speech and Language Processing之Logistic Regression |
您所在的位置:网站首页 › 生成模型和判别模型有哪些 › Speech and Language Processing之Logistic Regression |
Speech and Language Processing之Logistic Regression
|
生成分类器和判别分类器:朴素贝叶斯和逻辑回归之间最重要的区别是逻辑回归是判别分类器,而朴素贝叶斯是生成分类器。简单来讲,生成式模型就是要学习label的特征,比如猫和狗的分类,他要去学习猫和狗有什么不同,猫什么样子,狗什么样子;但是判别模型他不学习这个,他只需要找到特征能把二者区分即可,比如如果所有的狗都带着围脖,而猫没有,那么只需要围脖这一个特征就完成了学习,并且是一个很棒的模型。 二元逻辑回归的目标是训练一个分类器,该分类器可以对新输入观测值的类别做出二元决策。在这里,我们介绍将帮助我们做出这个决定的sigmoid。
如上,对于输入x其实最终计算的就是俩概率,y=1和y=0。 逻辑回归通过从训练集中学习权重向量和偏置项来解决这个问题。每个权重wi都是一个实数,并且与一个输入特征xi相关联。权重wi表示输入特征对分类决策的重要性,可以是正的(意味着特征与类相关)也可以是负的(意味着特征与类不相关)。因此,我们可能期望在情感任务中,单词awesome具有很高的正权重,而单词abyss具有非常负的权重。偏置项,也叫截距,是另一个实数加到加权输入上 。
如上,最终结果z是通过wi和xi相乘并累加然后加上截距b后得到的结果,然后可以简化为点积。
上面得到的z是一个数,这个数可能是正的也可能是负的,但是我们需要得到一个概率,数值在0~1之间,这就需要一个sigmoid函数,通过他来映射,然后就可以推导label=1 和label=0的概率如下:
模型的参数,权重w和偏置b,是如何学习的?逻辑回归是监督分类的一个实例,其中我们知道每个观察x的正确标签y(0或1)。系统产生的是y^,即系统对真实y的估计。我们希望学习使每个训练观察的y ^尽可能接近真实y的参数(含义w和b)。 这需要两个组件,我们在本章的引言中已经预示了。第一个是衡量当前标签(y +)与真实黄金标签y的接近程度。我们通常不衡量相似度,而是谈论与之相反的东西:系统输出和黄金输出之间的距离,我们称之为距离损失函数或者代价函数。在下一节中,我们将介绍通常用于逻辑回归和神经网络的损失函数,即交叉熵损失。我们需要的第二件事是迭代更新权重的优化算法,以最小化这个损失函数。标准算法是梯度下降法;我们将在下一节中介绍随机梯度下降算法。
上面就是交叉墒的推理过程,后面继续介绍其他的。
|

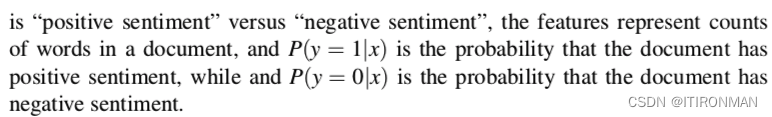
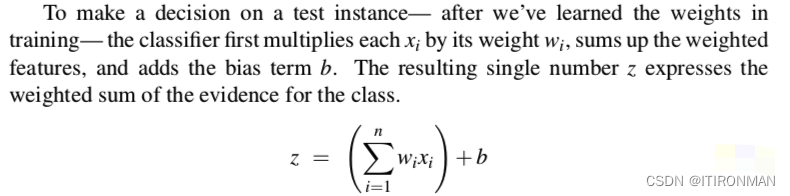
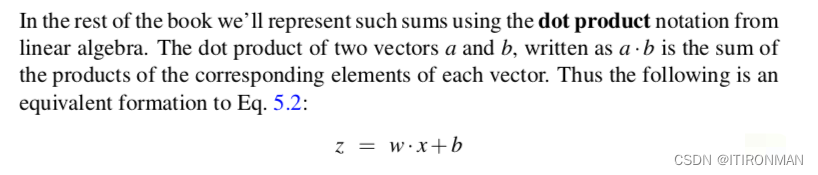

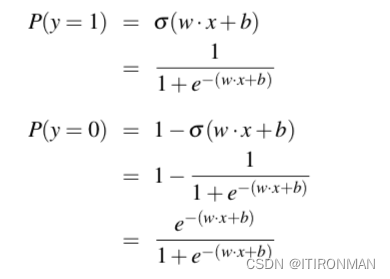
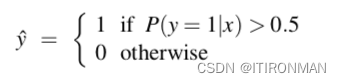


【本文地址】
今日新闻 |
推荐新闻 |