python3APP爬虫 |
您所在的位置:网站首页 › 王者荣耀照片人物照片 › python3APP爬虫 |
python3APP爬虫
|
文章目录
一.准备工作1.工具
二.思路1.整体思路2.爬虫思路
三.获取数据1.抓包2.分析json
四.撰写爬虫五.得到数据六.总结
之前有写过抖音app用户信息爬虫,因为当时是第一次写,可能有些思路不清楚,本次爬取王者荣耀盒子,使用抓包工具抓取数据,用python解析,最后将图片保存下来。
一.准备工作
1.工具
本次爬取的时王者荣耀盒子app,我将源文件放在了这里,密码:8jjg。 (1)安卓手机模拟器,夜神模拟器,下载地址:https://www.yeshen.com/,用于模拟安卓动作。 (2)抓包工具 Fiddler ,用于抓取app数据,5.0中文版下载地址:https://wws.lanzous.com/iQs1Siqxzif ,其中Fiddler配置方法可以参考这篇博文: https://www.jianshu.com/p/724097741bdf 在此不做赘述。 (3)python 3.7 官方下载地址:https://www.python.org/,用于编写爬虫代码。 二.思路思路分为整体思路和爬虫思路两个部分。 1.整体思路
首先打开模拟器和Fiddler抓包工具,直接打开 王者荣耀盒子 切换到英雄一栏 http://gamehelper.gm825.com/wzry/hero/list?channel_id=90014a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=27CAA72472821A3268EFB77990882F6B&ovr=5.1.1&device=HUAWEI_TAS-AN00&net_type=1&client_id=Vvv73yHNVErIOODKyaU8mw%3D%3D&info_ms=J%2Fb43lXS%2FZhfnmVx%2BFScew%3D%3D&info_ma=pvFtYLtm3bGAcOZu9lObNE6mnEceOtOWrDuxeljFGEg%3D&mno=0&info_la=KFyGmkUcTI6dmSrV%2BYE2bg%3D%3D&info_ci=KFyGmkUcTI6dmSrV%2BYE2bg%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=pvFtYLtm3bGAcOZu9lObNE6mnEceOtOWrDuxeljFGEg%3D&os_level=22&os_id=509a4c2c79e16125&resolution=1080_1920&dpi=320&client_ip=172.17.100.15&pdunid=c2c79e16125509a4 2.分析json这个请求url地址很长,可以通过切割,切割出简短的url,通过分析发现,全部参数都能直接切割,即地址为: http://gamehelper.gm825.com/wzry/hero/list
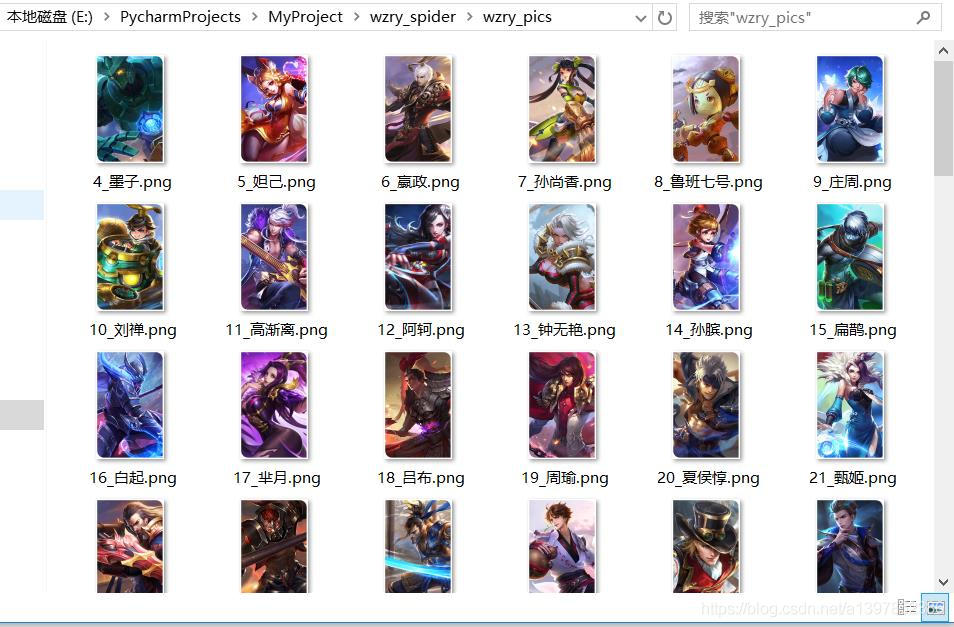
使用Josnhandle查看这个json所有结构就更清楚了。 所有英雄信息都包含在这个list中,英雄的id是英雄的唯一身份标识,cover为英雄图片,这些都是我们需要的内容。 做到这一步,大家就能够发现,这和处理ajax请求的数据操作是一样的,找到了请求的url接口就很容易进行提取了,接下来撰写爬虫。 四.撰写爬虫 import requests import json import os class Wzry_Hero_Spider(object): #初始化目录,请求头等 def __init__(self): self.base_url='http://gamehelper.gm825.com/wzry/hero/list'#使用简短url self.base_dir='./wzry_pics/' self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'} #解析出文件名和图片地址,命名格式:英雄id+英雄名字 def get_filename_and_link(self): try: r=requests.get(self.base_url,headers=self.headers) json_data=json.loads(r.text) data=json_data.get('list') for hero in data: hero_id=hero.get('hero_id') hero_name=hero.get('name') hero_pic_link=hero.get('cover') filename = hero_id +'_'+ hero_name+hero_pic_link[-4:]#切割字符串拼接文件名 yield filename,hero_pic_link except: pass #下载图片函数 def download_pics(self,filename,link): try: os.mkdir(self.base_dir) except: pass try: r=requests.get(link,headers=self.headers) with open(self.base_dir+filename,'wb')as f: f.write(r.content) print(f"\033[35;46m----------------------------{filename}下载完成----------------------------\033[0m") except: pass def main(): hero_spider = Wzry_Hero_Spider() for file, link in hero_spider.get_filename_and_link(): hero_spider.download_pics(file, link) if __name__ == '__main__': main()程序正常执行,直到结束。 所有的图片都在这里了。 |
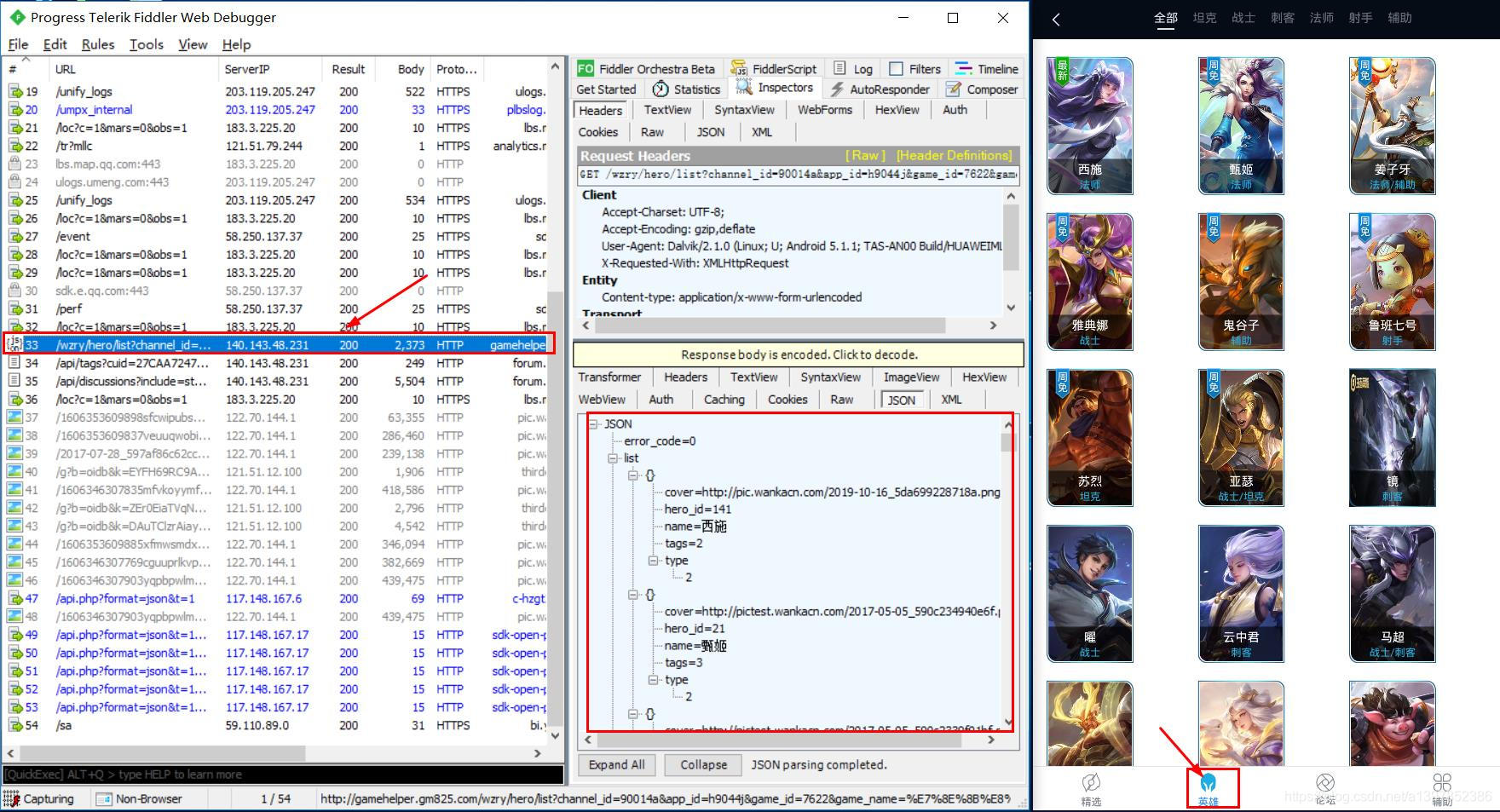 发现Fiddler中产生了很多请求,通过分析发现所有英雄信息(包括id,名字,图片)都在这个json响应体中。 点击上面的raw查看整个请求网址地址,将它复制下来。
发现Fiddler中产生了很多请求,通过分析发现所有英雄信息(包括id,名字,图片)都在这个json响应体中。 点击上面的raw查看整个请求网址地址,将它复制下来。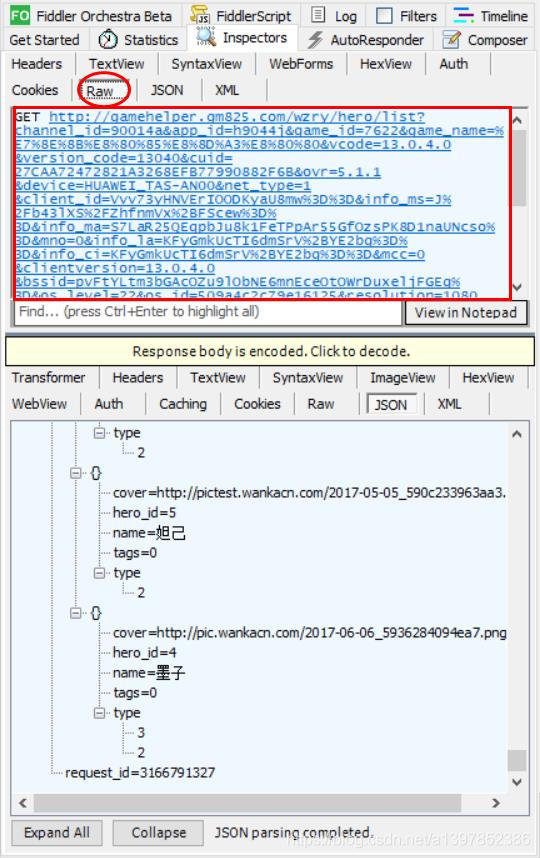 地址为:
地址为: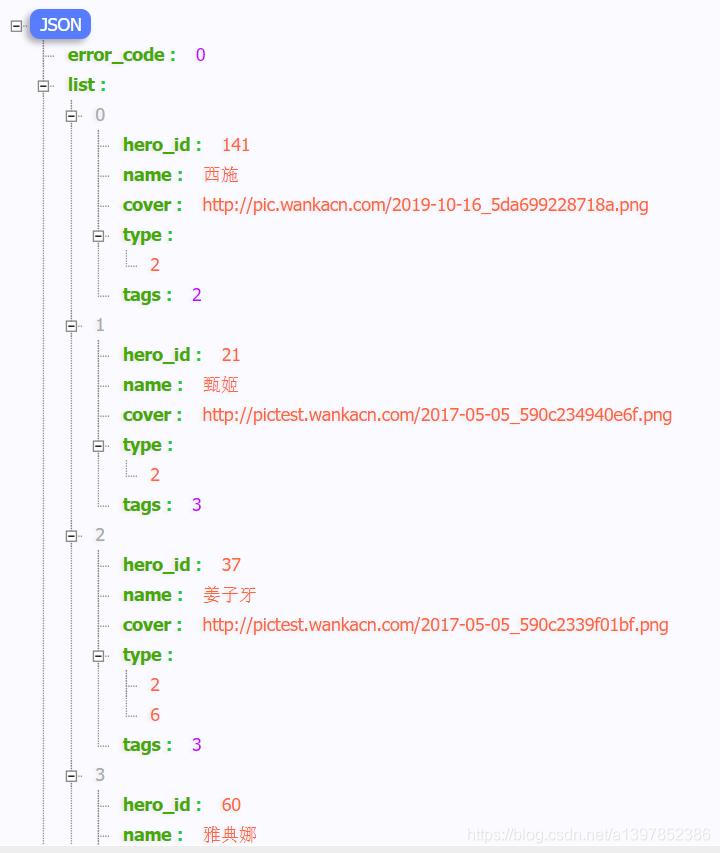

【本文地址】
今日新闻 |
推荐新闻 |