【python机器学习课程设计】狗的品种识别 |
您所在的位置:网站首页 › 狗狗品种识别扫脸app › 【python机器学习课程设计】狗的品种识别 |
【python机器学习课程设计】狗的品种识别
|
一、选题背景
近年来,随着生活水平的提高,狗作为常见的宠物慢慢步入了中国千万家庭中。而狗的品种识别可以帮助我们了解狗品种的差异特征,并使用机器学习技术来分析这些差异特征,从而提高对狗狗品种的识别能力。这对于狗养成有很大的帮助:狗的品种识别案例可以提高人们对狗狗的了解,并帮助人们更好地预防狗的疾病和保护狗狗健康、可以帮助人们对狗狗品种进行更准确的识别,进而更好地进行狗狗的饲养和繁殖,从而帮助相关行业发展。 二、机器学习案例设计方案从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件进行划分,对数据进行预处理,利用keras,构建神经网络,训练模型,导入图片测试模型。 数据来源:斯坦福大学狗的数据集,网址:Stanford Dogs dataset for Fine-Grained Visual Categorization 数据集包含了120种狗的品种分类,一共有20580张图像数据。 三、机器学习的实验步骤 1.下载数据集
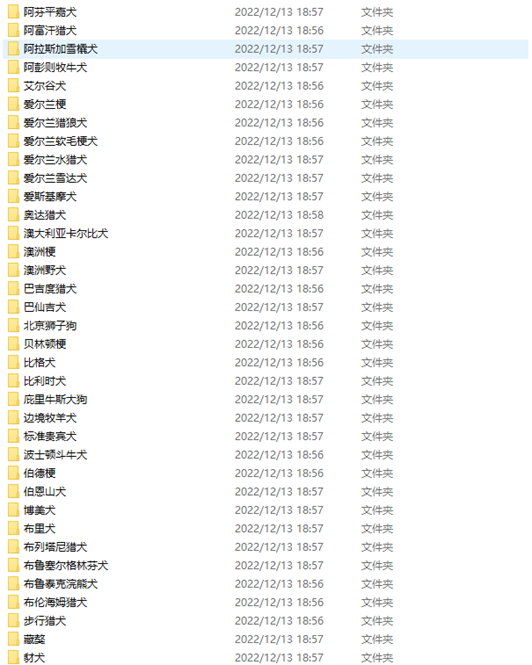
3.将数据集中的数据按品种分类、重命名、预处理 DogType = ['阿芬平嘉犬','阿富汗猎犬','阿拉斯加雪橇犬','阿彭则牧牛犬','艾尔谷犬','爱尔兰梗','爱尔兰猎狼犬', '爱尔兰软毛梗犬','爱尔兰水猎犬','爱尔兰雪达犬','爱斯基摩犬','奥达猎犬','澳大利亚卡尔比犬', '澳洲梗','澳洲野犬','巴吉度猎犬','巴仙吉犬','北京狮子狗','贝林顿梗','比格犬','比利时犬', '庇里牛斯大狗','边境牧羊犬','标准贵宾犬','波士顿斗牛犬','伯德梗','伯恩山犬','博美犬','布里犬', '布列塔尼猎犬','布鲁塞尔格林芬犬','布鲁泰克浣熊犬','布伦海姆猎犬','步行猎犬','藏獒','豺犬', '纯种古代牧羊犬','大丹犬','大瑞士山地犬','大型雪纳瑞犬','丹地丁蒙梗','德国短毛向导猎犬', '德国牧羊犬','斗牛獒犬','斗牛拳师犬','杜宾犬','俄罗斯狼犬','恩特雷布赫山地犬','法国斗牛犬', '非洲豺犬','弗莱特寻回犬','佛兰德牧牛狗','刚毛猎狐梗','戈登塞特犬','哈巴狗','荷兰卷尾狮毛狗', '黑褐猎浣熊犬','蝴蝶犬','吉娃娃','金毛寻回犬','卷毛寻回犬','凯恩梗','凯利蓝梗','柯利牧羊犬', '可卡犬','可蒙犬','拉布拉多猎犬','拉克兰梗','拉萨犬','莱昂贝格','罗得西亚脊背犬','罗威纳犬', '玛尔济斯犬','玛伦牧羊犬','美国斯塔福梗','迷你贵宾犬','迷你型雪纳瑞犬','墨西哥无毛狗','纽芬兰犬', '挪威猎麋犬','诺福克梗','诺里奇梗','彭布洛克威尔斯柯基犬','切萨皮克海湾寻回犬','日本狆犬','瑞德朋猎浣熊犬', '萨路基犬','萨摩耶犬','圣伯纳犬','史奇派克犬','斯坦福斗牛梗','松狮犬','苏格兰梗','苏格兰猎鹿犬', '苏塞克斯猎犬','玩具贵宾犬','玩具猎鹬犬','威尔士柯基犬','威尔士跳猎犬','威玛猎犬','维希拉猎犬', '西班牙猎犬','西伯利亚雪橇犬','西藏梗犬','西高地白梗','西里汉梗','西施犬','喜乐蒂牧羊犬','小灵狗', '小鹿犬','匈牙利白狗','雪梨犬','雪纳瑞犬','寻血猎犬','依比沙猎犬','意大利灰狗','英国蹲猎犬', '英国猎狐犬','英国史宾格犬','约克夏梗'] #修改名字 FilePath='train_data/' type_counter = 0 for type in DogType: file_counter = 0 subfolder = os.listdir(FilePath+type) for subclass in subfolder: file_counter +=1 print (file_counter) print ('Type_counter',type_counter) print (subclass) os.rename(FilePath+type+'/'+subclass, FilePath+type+'/'+str(type_counter)+'_'+str(file_counter)+'_'+subclass.split('.')[0]+'.jpg') type_counter += 1 #修改尺寸 Output_folder='train_img/' for type in DogType: for i in os.listdir(FilePath + type): img_open = Image.open(FilePath + type + '/' + i) conv_RGB = img_open.convert('RGB') Resized_img = conv_RGB.resize((100, 100), Image.BILINEAR) Resized_img.save(os.path.join(Output_folder, os.path.basename(i)))
 4.将图像数据转换为数组
train_folder='train_img/'
train_img_list = []
train_label_list = []
for file in os.listdir(train_folder):
img = Image.open(train_folder + file)
files_img_in_array = np.array(img)#将图像转化为数组
train_img_list.append(files_img_in_array) #图像列表相加
train_label_list.append(int(file.split('_')[0])) #标签列表汇总
train_img_list = np.array(train_img_list)
train_label_list = np.array(train_label_list)
train_label_list = np_utils.to_categorical(train_label_list,120) #格式为二进制 [0,0,0,0,1,0,0]
train_img_list = train_img_list.astype('float32')#将图像数组转化为浮点类型
train_img_list /= 255#归一化 4.将图像数据转换为数组
train_folder='train_img/'
train_img_list = []
train_label_list = []
for file in os.listdir(train_folder):
img = Image.open(train_folder + file)
files_img_in_array = np.array(img)#将图像转化为数组
train_img_list.append(files_img_in_array) #图像列表相加
train_label_list.append(int(file.split('_')[0])) #标签列表汇总
train_img_list = np.array(train_img_list)
train_label_list = np.array(train_label_list)
train_label_list = np_utils.to_categorical(train_label_list,120) #格式为二进制 [0,0,0,0,1,0,0]
train_img_list = train_img_list.astype('float32')#将图像数组转化为浮点类型
train_img_list /= 255#归一化
5.构建神经网络 #-- 创建CNN神经网络 model = Sequential() #CNN 1层 model.add(Convolution2D( filters=32, #Output (100,100,32) kernel_size= (5,5) , #卷积核 padding= 'same', #边距处理方法 padding method input_shape=(100,100,3) , #input shape )) model.add(Activation('relu')) model.add(MaxPooling2D( pool_size=(2,2), #Output (50,50,32) strides=(2,2), padding='same', )) #CNN 2层 model.add(Convolution2D( filters=64, #Output (50,50,64) kernel_size=(2,2), padding='same', )) model.add(Activation('relu')) model.add(MaxPooling2D( #Output(25,25,64) pool_size=(2,2), strides=(2,2), padding='same', )) #全连层 Layer -1 model.add(Flatten()) model.add(Dense(1024)) model.add(Activation('relu')) # 全连层 Layer -2 model.add(Dense(512)) model.add(Activation('relu')) #全连层 Layer -3 model.add(Dense(256)) model.add(Activation('relu')) #全连层 Layer -4 model.add(Dense(120))#添加120个节点的连接层 model.add(Activation('softmax'))#添加激活层,softmax将输入的一个向量转换为概率分布 # 定义优化器 adam = Adam(lr = 0.0001) #编译模型 model.compile( optimizer=adam, loss="categorical_crossentropy", metrics=['accuracy'] ) model.summary()
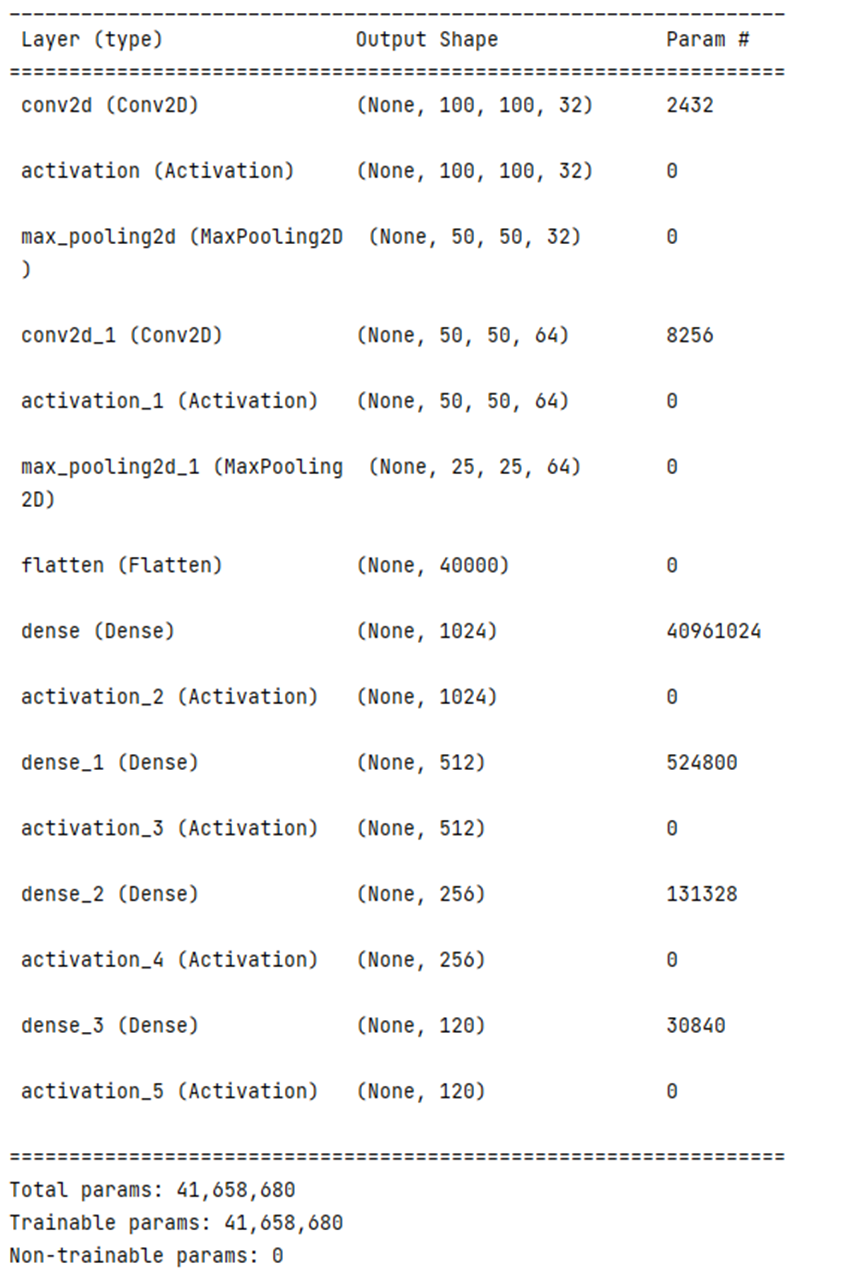 6.训练并保存模型
# 训练
model.fit(
train_img_list,
train_label_list,
epochs=30,
batch_size=64,
verbose=1,
)
#保存模型
model.save('./2103840129.h5')
6.训练并保存模型
# 训练
model.fit(
train_img_list,
train_label_list,
epochs=30,
batch_size=64,
verbose=1,
)
#保存模型
model.save('./2103840129.h5')
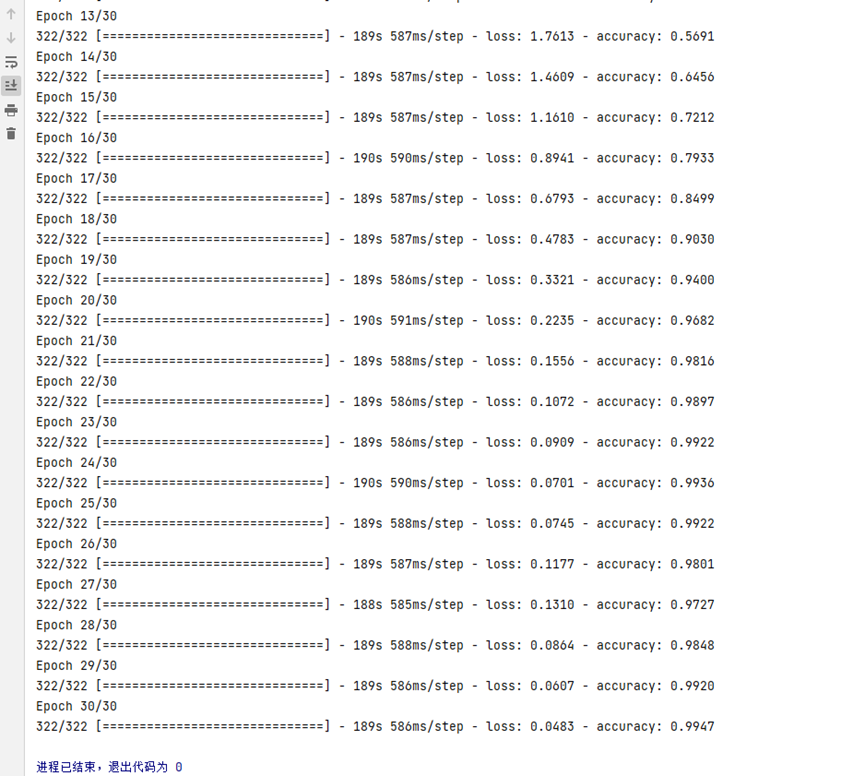 7.进行预测
PredictFile='./test_data/test.jpg'
# 图象处理
model = load_model('2103840129.h5')
img_open = Image.open(PredictFile)
conv_RGB = img_open.convert('RGB')
new_img = conv_RGB.resize((100, 100), Image.BILINEAR)
new_img.save(PredictFile)
# 图片重塑
image = processimage.imread(PredictFile)
image_to_array = np.array(image) / 255.0
image_to_array
= image_to_array.reshape(-1, 100, 100, 3)
prediction = model.predict(image_to_array)
#比较结果
count = 0
probability = 0
prDtype = ''
for i in prediction[0]:
# print (i)
# percentage = '%.2f%%' % (i * 100)
# print (DogType[count],'概率:' ,percentage)
if (probability
7.进行预测
PredictFile='./test_data/test.jpg'
# 图象处理
model = load_model('2103840129.h5')
img_open = Image.open(PredictFile)
conv_RGB = img_open.convert('RGB')
new_img = conv_RGB.resize((100, 100), Image.BILINEAR)
new_img.save(PredictFile)
# 图片重塑
image = processimage.imread(PredictFile)
image_to_array = np.array(image) / 255.0
image_to_array
= image_to_array.reshape(-1, 100, 100, 3)
prediction = model.predict(image_to_array)
#比较结果
count = 0
probability = 0
prDtype = ''
for i in prediction[0]:
# print (i)
# percentage = '%.2f%%' % (i * 100)
# print (DogType[count],'概率:' ,percentage)
if (probability |
【本文地址】
今日新闻 |
推荐新闻 |