【矩阵分解八】矩阵分解的优缺点及其高级演化 |
您所在的位置:网站首页 › 爱立方课程的优缺点 › 【矩阵分解八】矩阵分解的优缺点及其高级演化 |
【矩阵分解八】矩阵分解的优缺点及其高级演化
|
矩阵分解推荐算法的优点
矩阵分解结合了隐语义和机器学习的特性,能够挖掘更深层的用户和物品间的联系,因此预测的精度比较高,预测准确率要高于基于邻域的协同过滤以及基于内容的推荐算法;比较容易编程实现,随机梯度下降法和交替最小二乘法均可训练出模型。同时矩阵分解具有比较低的时间和空间复杂度,高维矩阵映射为两个低维矩阵节省了存储空间,训练过程比较费时,但是可以离线完成;评分预测一般在线计算,直接使用离线训练得到的参数,可以实时推荐;矩阵分解具有非常好的扩展性,改进后的矩阵分解如 SVD++、TimeSVD 等可以很方便在用户特征向量和物品特征向量中添加其它因素,用户属性信息和隐式反馈、时间上下文等都可以用来加强模型的预测效果。
矩阵分解推荐算法的缺点
模型训练比较费时;因为将用户和物品隐射到了隐因子空间,使得这些隐含特征无法使用现实生活中的概念来解释,因此推荐出的见过解释性并不好。
矩阵分解的一些高级演化
基于内容的推荐算法、基于近邻的协同过滤以及基于矩阵分解的协同过滤算法可以说是三大基础推荐算法,它们的算法思想构建了整个推荐算法大厦的基石,后面高级算法的不断演化,底层的基本假设和原理大都基于这三大基础推荐算法。 1)embeding矩阵分解的一大特点便是隐语义的学习,这使得该算法能够挖掘出更深的用户和物品之间的联系,从而提高预测准确率。而恰好词嵌入(Word Embedding)也可以通过浅层神经网络学到这样的隐语义,而且这种嵌入式表达往往更加简单、快速、有效,因此很快被人们应用到推荐系统中。 Embedding 在推荐中的一些用法: 获得用户和物品的隐语义表达作为深度神经网络的输入根据物品映射得到的特征向量去找相似的物品Embedding 本质上也是体现物品关联,但是比协同过滤的覆盖度高。 由此,Embedding 几乎成为高级推荐算法的必用技术,Embedding 的特征预处理可以带来更好的效果,又能降维又能挖掘深层关联信息,何乐而不为呢?与矩阵分解类似,其核心思想就是同时构建用户和物品的嵌入式表示,使得多种实体的嵌入式表示存在于同一个隐含空间内, 进而挖掘实体之间的关联信息 (非端到端),以及实体和最终目标任务之间的关联信息(端到端)。 2)FM一句话总结:在求解二阶交叉特征的参数时,借鉴矩阵分解的思想进行参数求解。 详见本篇 分解机 FM(Factorization Machine)也称因子分解机。是由 Konstanz 大学 Steffen Rendle 于 2010 年最早提出的,旨在解决稀疏数据下的特征组合问题。FM 设计灵感来源于广义线性模型和矩阵分解。 在线性模型中,我们会单独考察每个特征对 Label 的影响,一种策略是使用 One-hot 编码每个特征,然后使用线性模型来进行回归,但是 one-hot 编码后,一者,数据会变得稀疏,二者,很多时候,单个特征和 Label 相关性不够高。最终导致模型性能不好。为了引入关联特征,可以引入二阶项到线性模型中进行建模。
𝑥𝑖、𝑥𝑗 是经过 One-hot 编码后的特征,取 0 或 1。只有当二者都为 1 时,𝑤𝑖𝑗 权重才能得以学习。然后由于稀疏性的存在,满足 𝑥𝑖,𝑥𝑗 都非零的样本很少,导致组合特征权重参数缺乏足够多的样本进行学习。 矩阵分解思想此时发挥作用。借鉴协同过滤中,评分矩阵的分解思想,我们也可以对 𝑤𝑖𝑗 组成的二阶项参数矩阵进行分解,所有二次项参数 𝑤𝑖𝑗 可以组成一个对称阵 𝑊,那么这个矩阵就可以分解为 𝑊=𝑉𝑇𝑉,𝑉 的第 𝑗 列便是第 𝑗 维特征的隐向量。换句话说,每个参数 𝑤𝑖𝑗=〈𝑣𝑖,𝑣𝑗〉,这就是 FM 模型的核心思想。 3)张量分解一句话总结:对N维关系建模,不再是二维关系。比如将时间维拆分出来,单独作为一个维度,在某个时间下,user和item的关系。 矩阵分解还有一个演化算法是张量分解(Tensor Factorization),我们来看看它的基本思想是什么。 我们还是要从矩阵分解说起。矩阵分解的核心思想,是用矩阵这种数据结构来表达用户和物品的相互关系。这里,我们一般谈论的都是一些最简单的关系,例如评分、点击、购买等(本小节我们只是讨论评分)。在这种二元的模式下,矩阵就是最好的表达用户和物品之间关系的数据结构。 然而,在真实的场景中,用户和物品的关系以及产生这种关系的周围环境是复杂的。一个矩阵并不能完全描述所有的变量。例如,用户对于某个物品的评分是发生在某个地点、某个时间段内的。这种所谓的 “上下文关系”(Context)往往会对评分产生很大影响。遗憾的是,一个矩阵无法捕捉这样的上下文关系。 我们之前讨论过的 “SVD++” 和 “FM”,本质上都是在某种程度上绕开这个问题。采用的方法就是,依然用矩阵来表达二元关系,但是把其他信息放进隐变量中,或者是采用基于信息的推荐系统的思路来得到相关信息的建模。 除了这种思路,还有没有别的方法,可以把上下文关系融入到对用户和物品的建模中去呢? 这时 “张量” 就该上场了。 从本质上来说,张量就是矩阵的推广。我们可以这么理解,矩阵是对二维关系建模的一种工具;而张量,就是对 N 维关系的一种建模。在二维关系中,用户和物品的评分是唯一能够被建模的变量;而到了 N 维关系中,理论上,我们可以对任意多种上下文关系进行建模。 比如,我们刚才提到的时间,就可以组成一个三维的张量,分别为用户、物品和时间。然后,在这个三维的张量中,每一个单元代表着某一个用户对于某一个物品在某一个时间段的评分。 那么,如何使用张量来进行推荐模型的建模呢? 我们还是用刚才所说的 “用户、物品和时间” 作为例子。在这个三维的张量里,每一个元素代表的是用户对于物品在某个时间段上的评分。那么,根据矩阵分解的思路,我们怎么来对这个张量进行分解呢? 遗憾的是,张量的分解要比矩阵分解更为复杂。与矩阵分解不同,张量分解至少有两种不同的形式,这两种形式会引导出不同的分解模型和算法。
|
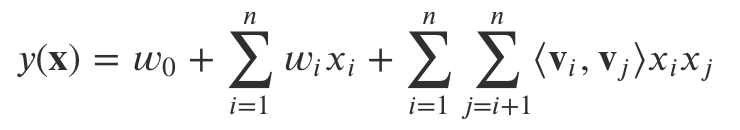
【本文地址】
今日新闻 |
推荐新闻 |