|
今天来说说豆瓣网书评数据采集,说到说大家都读什么书呢,有没有像我一样的买好几本书之后就放在家里吃灰貌似有几本书买来之后都没有打开过,书中自有黄金屋,书中自有颜如玉。

话不多说来是今天的爬虫之旅,网站地址
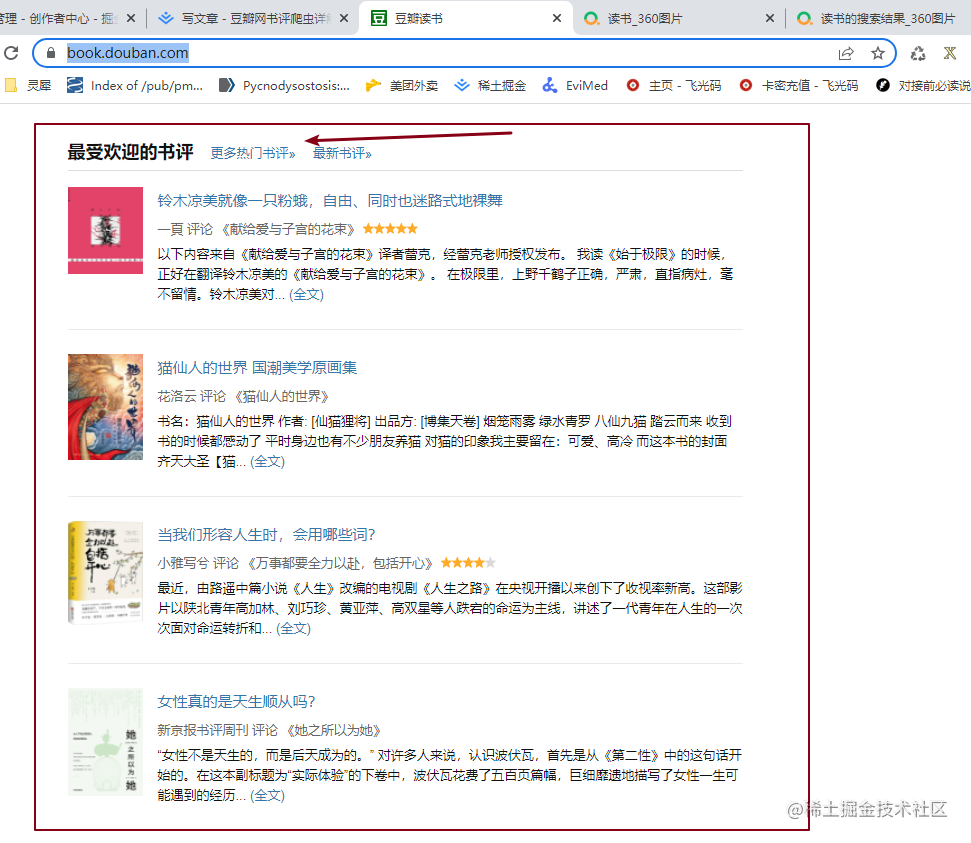 是忙碌还是懒惰不管,决定是否用心读一本书主要还是看书评。先进到列表页,点击更多热门书评
是忙碌还是懒惰不管,决定是否用心读一本书主要还是看书评。先进到列表页,点击更多热门书评
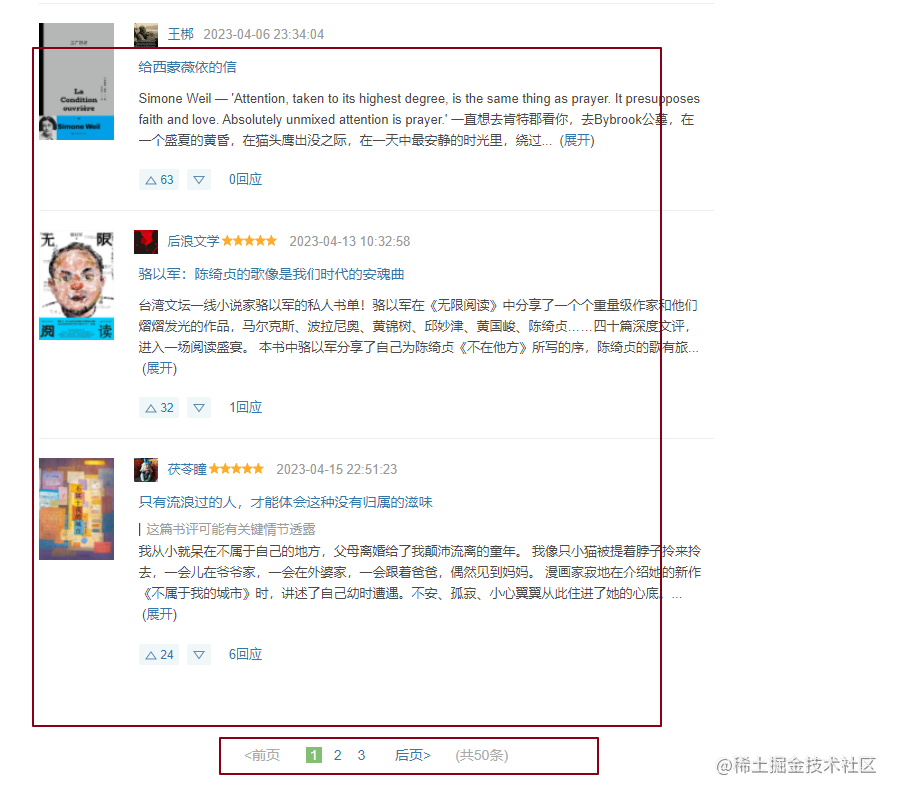 可见翻页和列表都在这里了,然后就是抓个包看看接口
可见翻页和列表都在这里了,然后就是抓个包看看接口
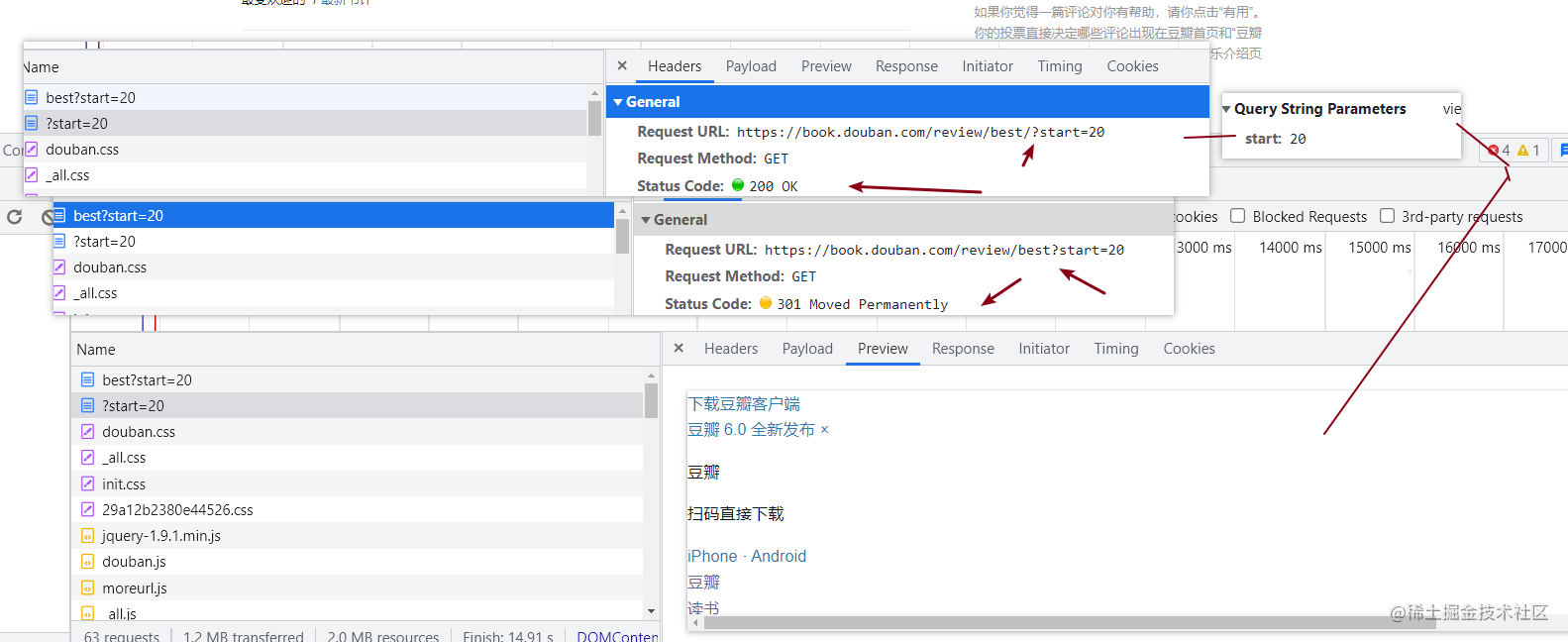 请求经过了一次301跳转到了book.douban.com/review/best…
这个连接连接,继续翻页start变成了40那就是每20翻一页,可见数据也是在接html当中的
请求经过了一次301跳转到了book.douban.com/review/best…
这个连接连接,继续翻页start变成了40那就是每20翻一页,可见数据也是在接html当中的
列表页搞清楚了接着向下走看一下详情页,从这里进去
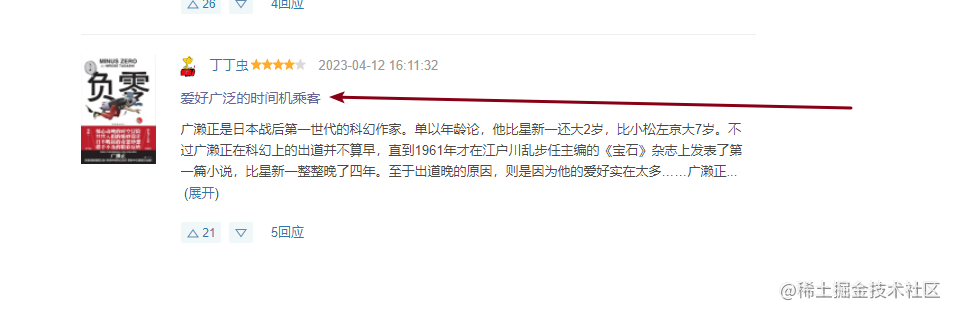
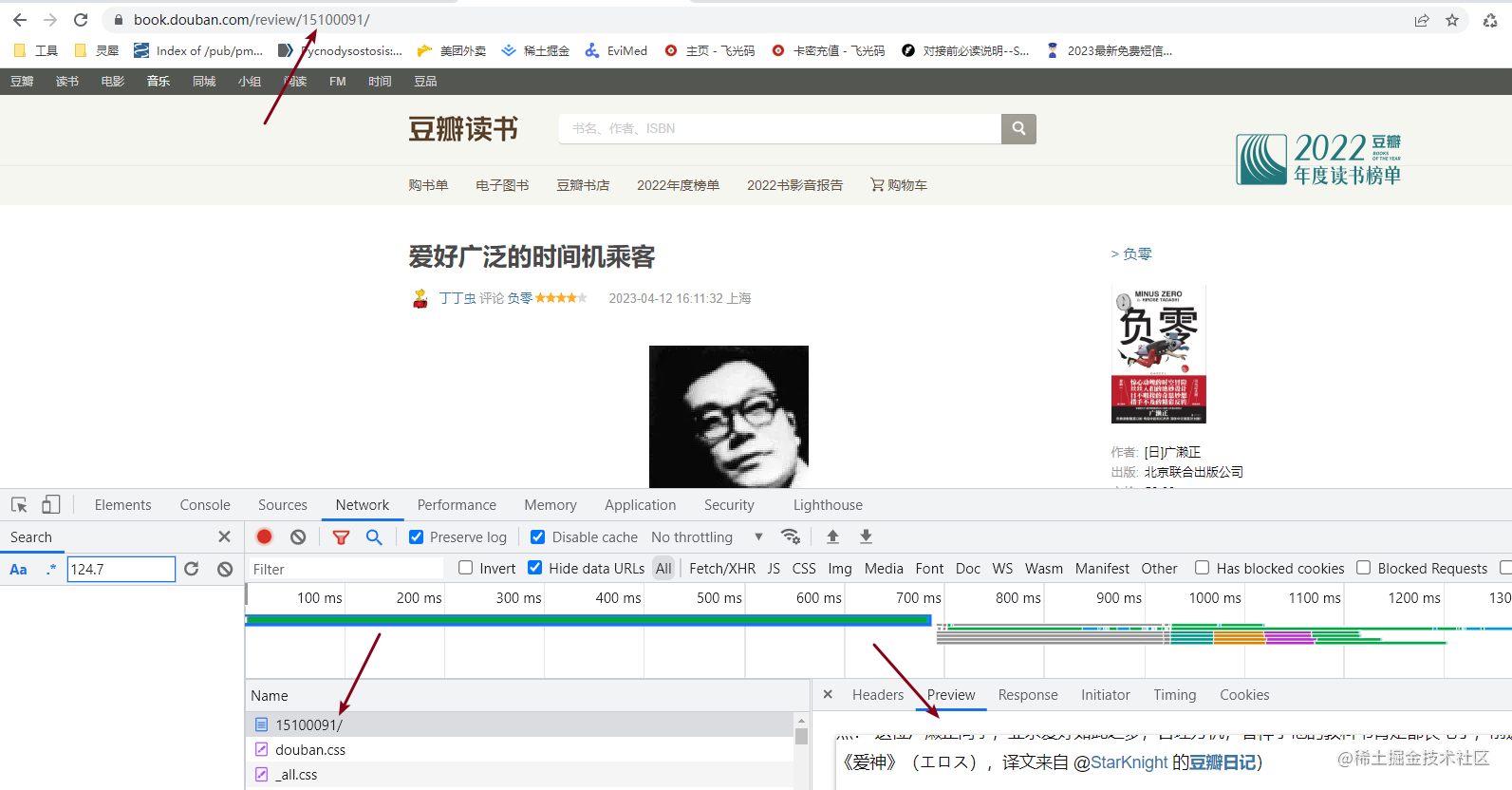 数据也是在html中的,这里15100091应该就是这条数据的id了,那么这个id必然也是在列表页的接口中的,但这里就明了了!
数据也是在html中的,这里15100091应该就是这条数据的id了,那么这个id必然也是在列表页的接口中的,但这里就明了了!
先请求列表页获取基础信息
params = {
'start': '0',
}
response = requests.get('https://book.douban.com/review/best/', params=params, headers=headers)
response.encoding = response.apparent_encoding
res = etree.HTML(response.text)
data_list = res.xpath("//div[@class='review-list chart ']/div")
for data in data_list:
book_name = data.xpath("./div/a/img/@alt")[0]
datatime = data.xpath("./div/header/span[@class='main-meta']/text()")
if len(datatime) ==1:
datatime = datatime[0]
else:
datatime = ''
title = data.xpath("./div/div/h2/a/text()")[0]
url = data.xpath("./div/div/h2/a/@href")[0]
item = {
'book_name':book_name,
'datatime':datatime,
'title':title,
'url':url,
}
print(item)
复制代码
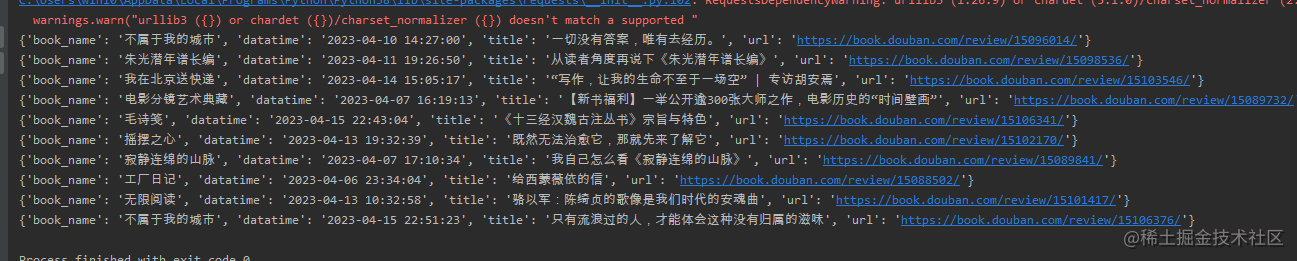 再请求详情页对解析一下正文部分
再请求详情页对解析一下正文部分
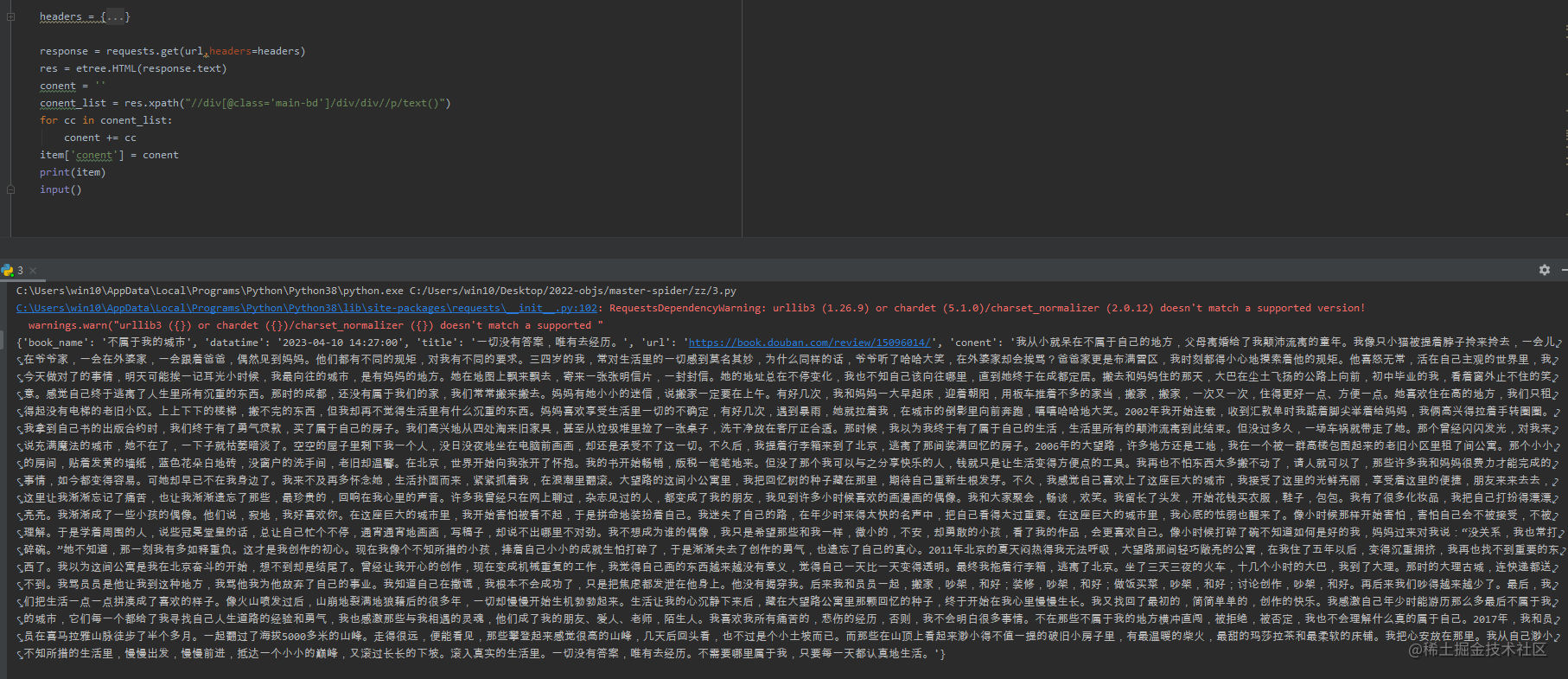
response = requests.get(url,headers=headers)
res = etree.HTML(response.text)
conent = ''
conent_list = res.xpath("//div[@class='main-bd']/div/div//p/text()")
for cc in conent_list:
conent += cc
复制代码
|