Java爬取校内论坛新帖 |
您所在的位置:网站首页 › 爬虫论坛帖子 › Java爬取校内论坛新帖 |
Java爬取校内论坛新帖
|
Java爬取校内论坛新帖
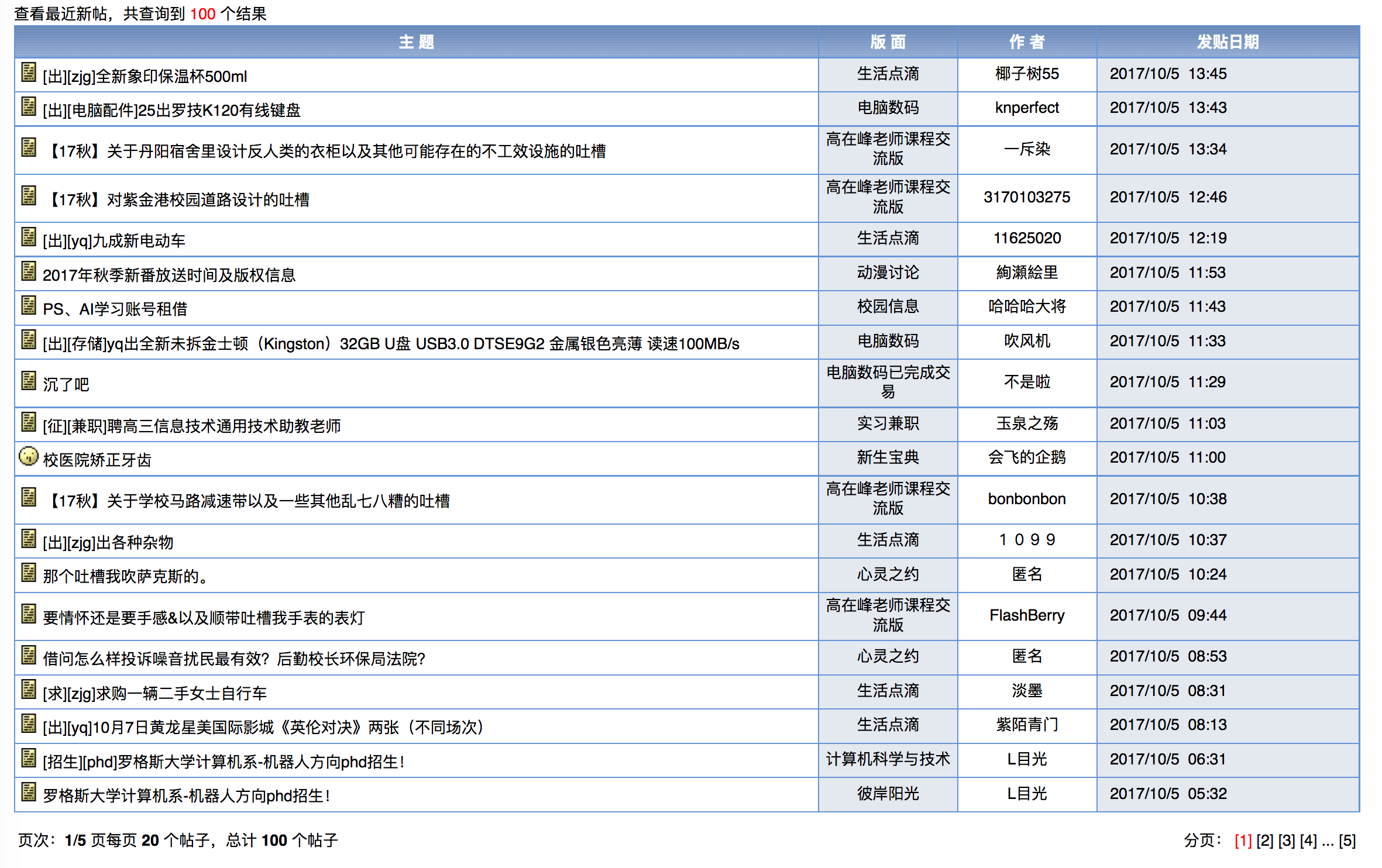
为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法。 嗯,这次就选Java。 第三方库准备 JsoupJsoup是一款比较好的Java版HTML解析器。可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 mysql-connector-javamysql-connector-java是java JDBC的MySQL驱动,可以提供方便统一的接口来操纵MySQL数据库 爬虫步骤 目标分析 爬取网页 解析网页 存储数据 目标分析博主爬取的是浙大的cc98论坛,需要内网才能上,新帖会在其中一个版面内出现,界面大概是这样:
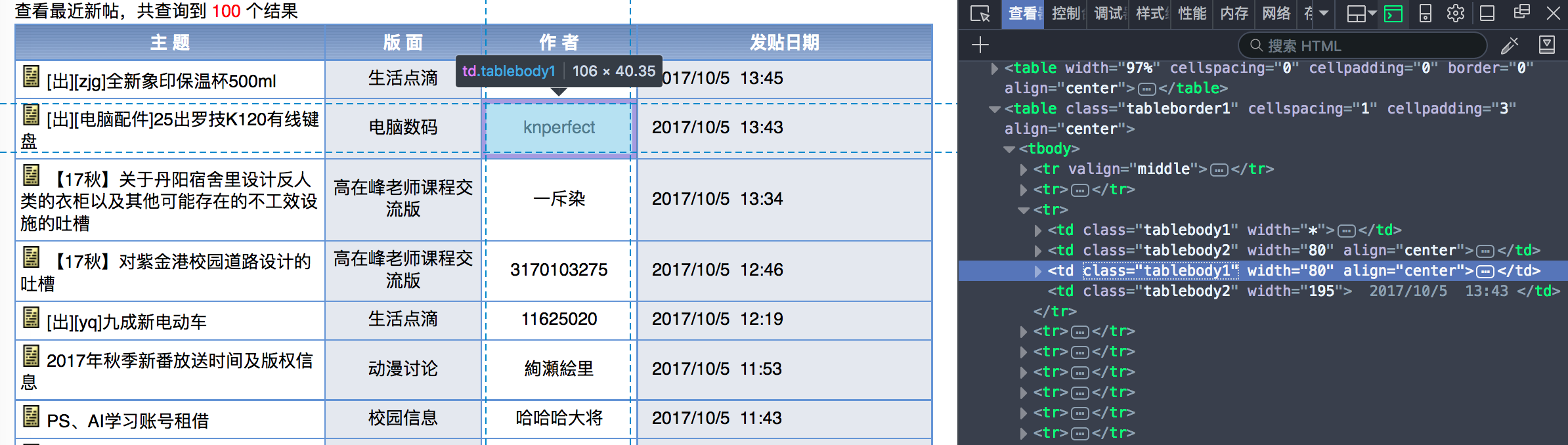
分析一下之后,发现100条新帖一共有5页,内容呈现在一张表格上。 再用Firefox分析一下页面,发现是一个class="tableborder1"的table下有20行记录,每一行有4个td,爬虫只要获取这四个td数据就可以了。
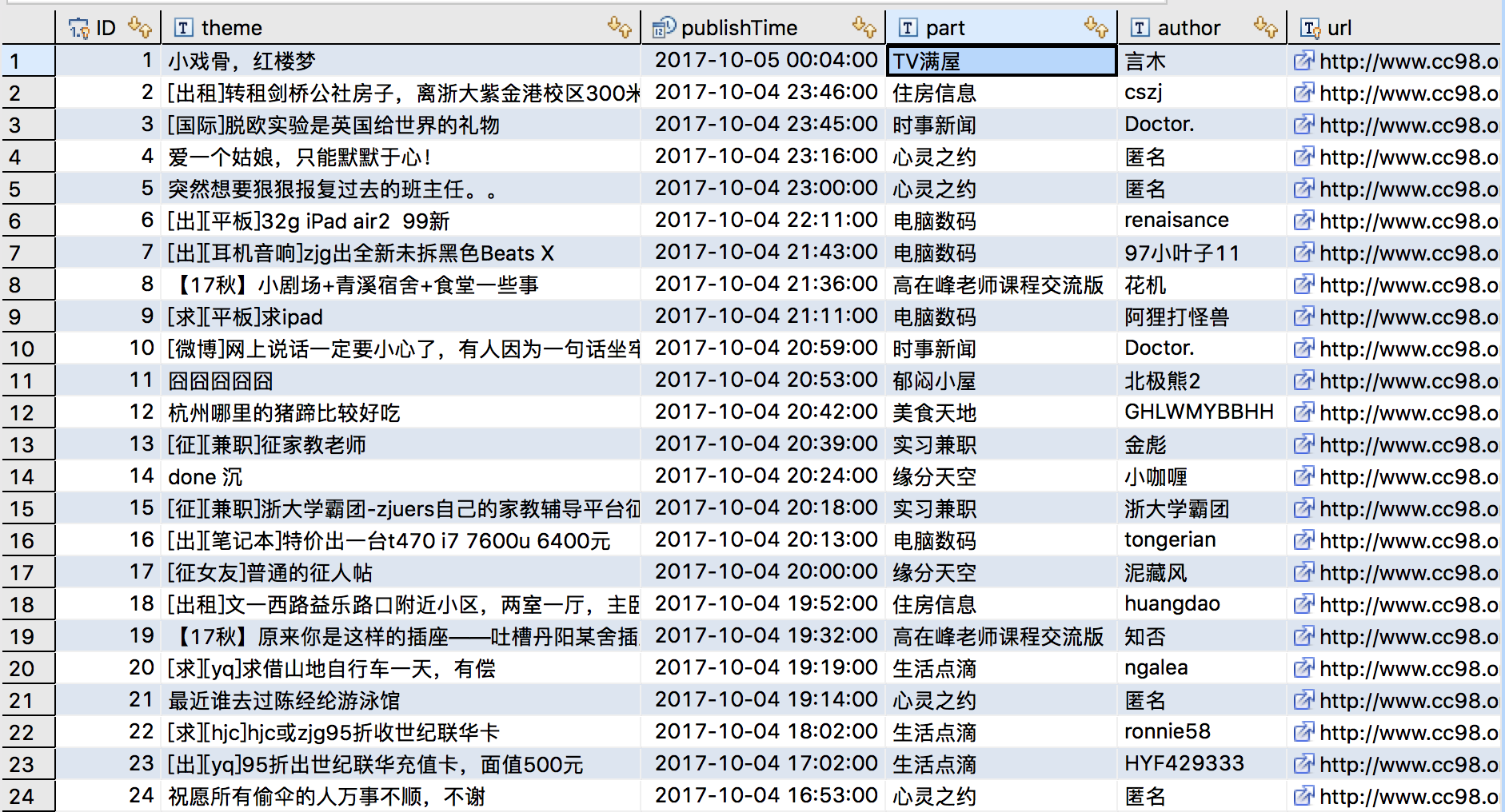
由于这个网站是要用用户名和密码登录的,博主一开始都在使用POST方法,后来用Firefox抓包分析之后,才发现可以使用带cookies的GET方法登录。 private void getDoc(String url, String page) { try { //获取网页 this.doc = Jsoup.connect(url) .cookie("aspsky", "***") .cookie("BoardList","BoardID=Show") .cookie("owaenabled","True") .cookie("autoplay","True") .cookie("ASPSESSIONIDSSCBSSCR","***") .data(" stype","3") .data("page",page) //Page就是1-5页 .get(); } catch (IOException e) { e.printStackTrace(); throw new RuntimeException(); } }这里使用到的Jsoup很强大,其实还可以添加header之类的作修饰,但博主发现只要加了cookies之后就能成功访问了。 解析网页根据目标分析的结果,我们可以开始解析HTML文档,同样地,Jsoup允许使用JQuery方法来解析,十分方便 private void parse() { //采用JQuery CSS选择 Elements rows = doc.select(".tableborder1 tr"); //去掉表头行 rows.remove(0); for(Element row : rows) { String theme = row.select("td:eq(0) a:eq(1)").text().trim(); String url = "http://www.cc98.org/" + row.select("td:eq(0) a:eq(1)").attr("href"); String part = row.select("td:eq(1) a").text().trim(); String author = row.select("td:eq(2) a").text().trim(); if(author.length()==0) { author = "匿名"; } String rawTime = row.select("td:eq(3)").text(). replace("\n","") .replace("\t",""); try { Date publishTime = sdf.parse(rawTime); System.out.println(publishTime+" "+theme); System.out.println("---------------------------------------------------------"); storage.store(theme,publishTime,part,author,url); } catch (ParseException e) { e.printStackTrace(); } } } 存储数据为了方便日后的分析(博主还打算偶尔分析一下各个版面的活跃情况),我们要把数据存储到硬盘上,这里选用了jdbc连接MySQL public void store(String theme, Date publishTime, String part, String author, String url) { try { String sql = "INSERT INTO news (theme," + "publishTime,part,author,url)VALUES(?,?,?,?,?)"; //使用预处理的方法 PreparedStatement ps = null; ps = conn.prepareStatement(sql); //依次填入参数 ps.setString(1,theme); java.sql.Time time = new java.sql.Time(publishTime.getTime()); //这里使用数据库的时间戳 ps.setTimestamp(2,new Timestamp(publishTime.getTime())); ps.setString(3,part); ps.setString(4,author); ps.setString(5,url); ps.executeUpdate(); } catch (SQLException e) { //主要是重复的异常,在MySQL中已经有约束unique // e.printStackTrace(); } }我们可以通过MySQL可视化工具查看结果,由于MySQLworkbench不太好用,博主使用了DBeaver,结果如下:
结果非常令人满意。 完整代码Spider.java package com.company; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; public class Spider { private Document doc; //定义时间格式 private SimpleDateFormat sdf = new SimpleDateFormat( " yyyy/MM/dd HH:mm " ); Storage storage = new Storage(); private void getDoc(String url, String page) { try { //获取网页 this.doc = Jsoup.connect(url) .cookie("aspsky", "***") .cookie("BoardList","BoardID=Show") .cookie("owaenabled","True") .cookie("autoplay","True") .cookie("ASPSESSIONIDSSCBSSCR","***") .data(" stype","3") .data("page",page) .get(); } catch (IOException e) { e.printStackTrace(); throw new RuntimeException(); } } private void parse() { //采用JQuery CSS选择 Elements rows = doc.select(".tableborder1 tr"); //去掉表头行 rows.remove(0); for(Element row : rows) { String theme = row.select("td:eq(0) a:eq(1)").text().trim(); String url = "http://www.cc98.org/" + row.select("td:eq(0) a:eq(1)").attr("href"); String part = row.select("td:eq(1) a").text().trim(); String author = row.select("td:eq(2) a").text().trim(); if(author.length()==0) { author = "匿名"; } String rawTime = row.select("td:eq(3)").text(). replace("\n","") .replace("\t",""); try { Date publishTime = sdf.parse(rawTime); System.out.println(publishTime+" "+theme); System.out.println("---------------------------------------------------------"); storage.store(theme,publishTime,part,author,url); } catch (ParseException e) { e.printStackTrace(); } } } public void run(String url) { for (Integer i = 1; i |
【本文地址】
今日新闻 |
推荐新闻 |