爬虫demo |
您所在的位置:网站首页 › 爬虫下载视频犯法吗 › 爬虫demo |
爬虫demo

之前闹的沸沸扬扬的新闻“上亿简历大数据公司被警方一锅端”,因为其公司内部大部分数据是通过使用爬虫来抓取到的,属于违法行为,所以被警方给一锅端了! 马上就会有小伙伴问了:“爬虫,违法吗?” 我认为:爬虫不犯法! 但是爬虫要讲究规则和方法的,一定要善用爬虫,慎用爬虫,爬虫虽好,但是一定不要侵权,尤其是盗取别人的原创内容和知识,更不要传播具有版权的内容和产品。 下面我们来具体谈一谈爬虫吧! //爬虫是什么? 如果我们把互联网比作一张大的蜘蛛网,蜘蛛网的各个节点代表就是数据,而爬虫就是一只小蜘蛛,沿着蜘蛛网来抓取自己的猎物(数据) 
爬虫:本质上是一个程序,向网站发起请求,获取资源,然后分析并提取有用的数据。 具体:通过程序模拟浏览器请求站点的行为,把站点返回来的html代码/json数据/二进制数据(图片,视频)爬到本地,进而提取自己需要的数据,存放起来使用。 //爬虫的基本流程 发送请求---->获取相应内容--->解析内容---->保存数据 01 发起请求 使用http库向目标站点发送请求,即发送一个Request Request包含:请求头/请求体等 Request模块缺陷:不能执行js和css代码 02 获取相应内容 如果服务器能正常相应,则会得到一个Response Reponse包含:html/json/图片/视频等 03 解析内容 解析html数据:正则表达式(RE模块),第三方解析库Beautifulsoup/pyquery等 解析json数据:json模块 解析二进制数据:以wb的方式写入文件 04 保存数据 数据库/文件 
// 爬取数据 01 爬取网页内容,保存到本地文件 导入urllib模块 import urllib 发送请求 方法一:发送一个get请求到指定页面,返回http响应 reponse = urllib.request.urlopen(url) 方法二:模拟浏览器发送get请求(有些服务器会检查头信息,用来判断是否是浏览器发送的请求) 创建request对象 req= urllib.request.Request(url) 在request中添加头信息 req.add_header('User-Agent':'Mozilla/6.0') 发送请求 reponse = urllib.request.urlopen(req) 方法三:模拟浏览器发送post请求 获取状态码,如果是200表示成功 reponse.status 调用网页对象的read()方法读取网页源码 html_code = page.read() 02 网页解析 获取网页的编码格式 使用chardet模块 import chardet char_dic = chardet.detect(html_code) 结果: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''} 编码格式: char_dic['encoding'] html = html_code.decode(char_dic['encoding']) 使用正则解析 省略 BeautifulSoup4解析 BeautifulSoup4是一个可以从HTML或XML文件中提取数据的Python库 1)简介html文档对象模型 省略 2)使用BeautifulSoup4解析过程 创建BeautifulSoup4对象-->搜索节点(按名称/属性/文本)-->访问节点(名称/属性/文本) 核心代码: #导入模块 from bs4 import BeautifulSoup #创建BeautifulSoup4对象 soup = BeautifulSoup4(html_doc,"html.parser") #搜索节点 find_all(name,attrs,string) a_nodes = soup.find_all("a") #搜索标签名为a的所有节点 a_nodes = soup.find_all("a",class="abc") #搜索标签名为a,class值为abc的所有节点 #访问节点:获取节点的标签名 node.name #获取节点的属性值 node.get(attr) #获取节点的文本内容 node.get_text() 03 保存数据 使用I/O流保存在本地文件中
//实例分析 爬取图片 url: http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%9B%BE%E7%89%87 代码: 
结果: 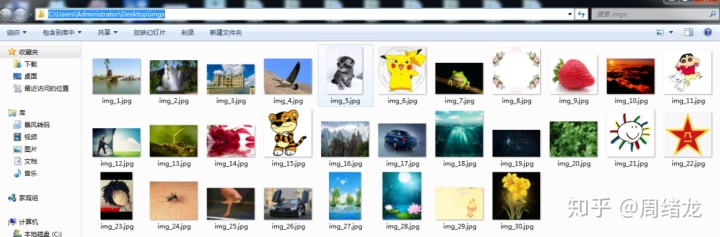
以上就是今天关于爬虫的相关内容! 最后想问问大家认为爬虫违法么?认为如何正确使用爬虫呢?认为爬虫什么不会违法? 欢迎大家在文章底下留言,一起交流自己的看法和观点。 |
【本文地址】
今日新闻 |
推荐新闻 |