|
热榜榜单一直以来都是比较重金的数据,但是有很多的引擎页已经做好了热榜的汇总接下来几天会多找几个热榜汇总网站进行各个源热榜榜单爬虫分享,今天先采集爱寻匿网站。
话不多说直接开始,网站地址
还是先分析网页结构,打开网站之后可以看见这里有百度,知乎,抖音,微博热榜,通过网页响应速度可以首页数据是先响应的榜单源名称同时响应,各个榜单源里面的数据是后响应的,由此盲猜这些榜单数据是在接口中的,而不是html.
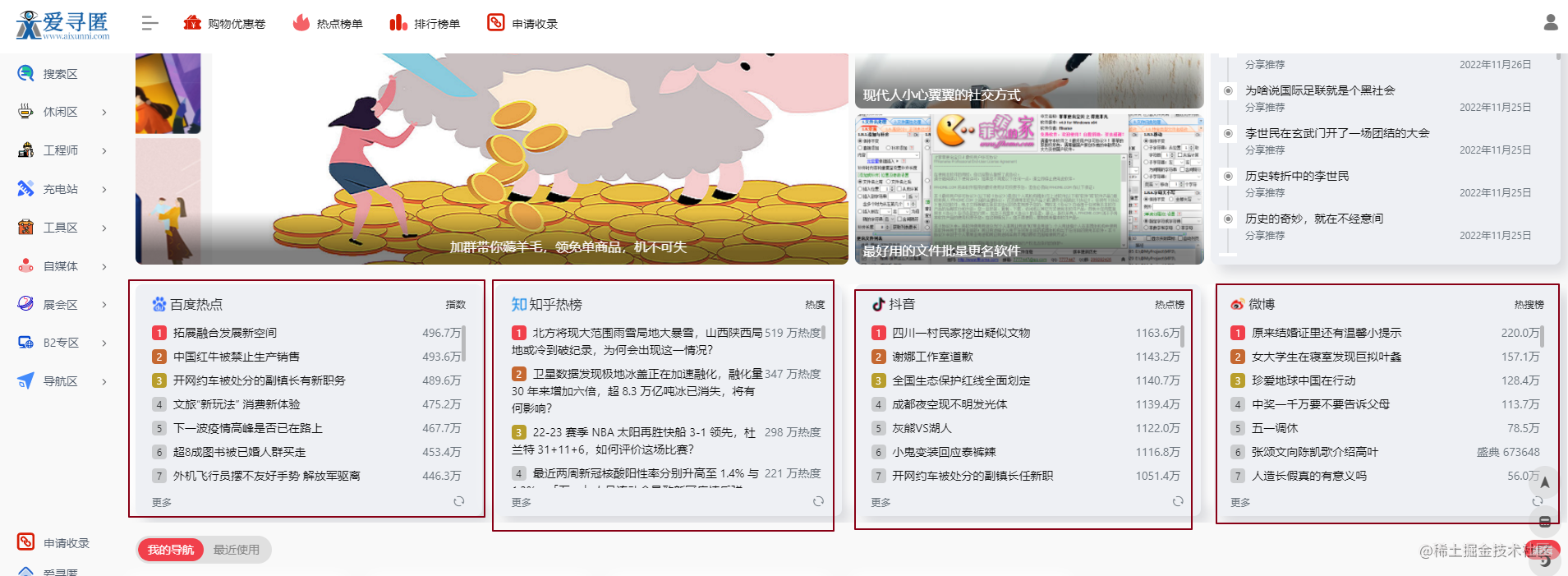 接着F12抓一下包看看
接着F12抓一下包看看
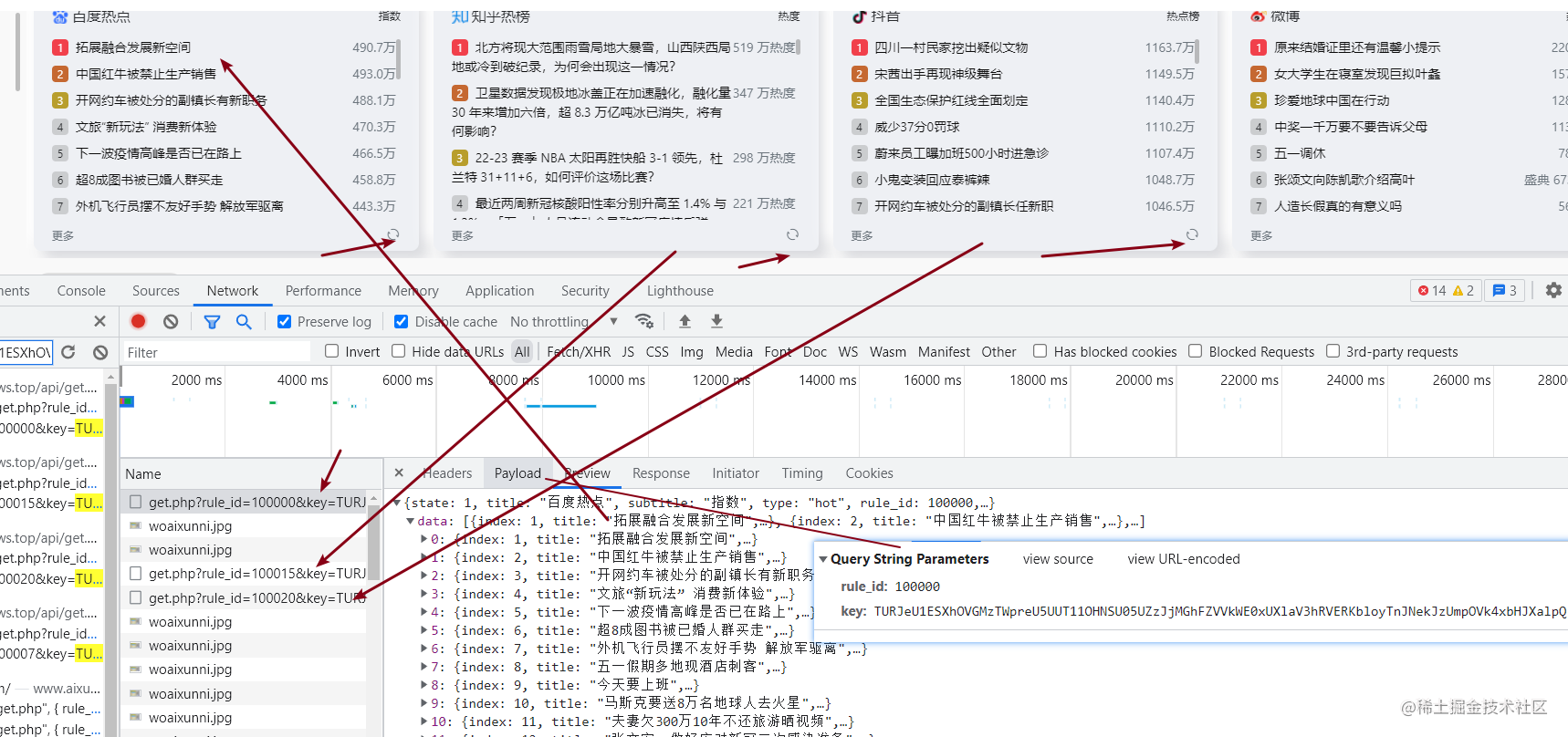 通过点击刷新按钮成功抓到了数据接口,请求参数中有一个key是加密的,rule_id是源的编号,每一个源的编号都不一样。key是一样的,这里猜测一下这个key要么是首页请求里面传出来的,要么是生成的。那么先判断是不是首页中生成了,清除cookies,抓一下首页的包以及热榜数据的包,看看key是否是从首页中返回出来的
通过点击刷新按钮成功抓到了数据接口,请求参数中有一个key是加密的,rule_id是源的编号,每一个源的编号都不一样。key是一样的,这里猜测一下这个key要么是首页请求里面传出来的,要么是生成的。那么先判断是不是首页中生成了,清除cookies,抓一下首页的包以及热榜数据的包,看看key是否是从首页中返回出来的
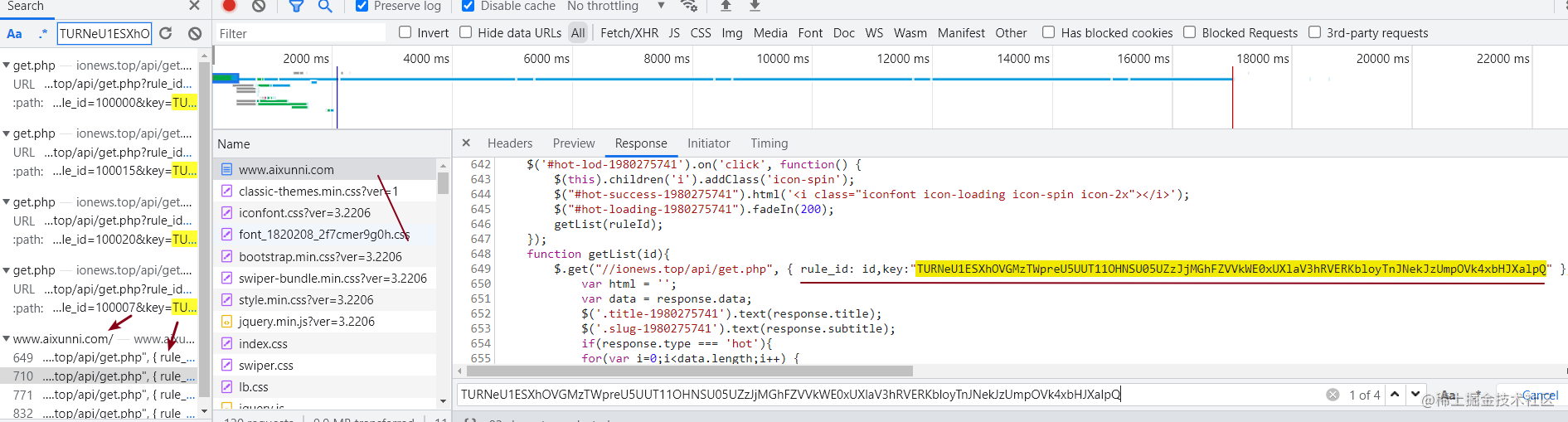 可见这个key参数就是从首页中生成了,但是好像是在js中的那就需要正则来提取了。到这里就明了了,先请求首页取到key,再去请求各个源的接口就ok了
2. 请求首页使用正则提取key的值
可见这个key参数就是从首页中生成了,但是好像是在js中的那就需要正则来提取了。到这里就明了了,先请求首页取到key,再去请求各个源的接口就ok了
2. 请求首页使用正则提取key的值
headers = {
'authority': 'www.aixunni.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
response = requests.get('https://www.aixunni.com/', headers=headers)
key_list = re.findall(r'key:"(.*?)"',response.text,re.S)
print(key_list)
复制代码
这里返回四个值应该是四个源的,但是都一样,只取一个就可以了
 然后再遍历四个源请求热榜数据的接口
然后再遍历四个源请求热榜数据的接口
headers = {
'authority': 'ionews.top',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'origin': 'https://www.aixunni.com',
'pragma': 'no-cache',
'referer': 'https://www.aixunni.com/',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'cross-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
for rule_id in [100000,100015,100020,100007]:
params = {
'rule_id': f'{rule_id}',
'key':f'{key}',
}
response = requests.get('https://ionews.top/api/get.php', params=params, headers=headers).json()['data']
for res in response:
print(res)
input()
复制代码
 ok
ok
|